

🔥 作者主页:疯狂行者🔥 💖✌java领域优质创作者,专注于Java技术领域技术交流✌💖
💖文末获取源码💖
精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
文章目录
*
– Java精彩实战项目案例
– Java精彩新手项目案例
– Python精彩新手项目案例
* 前言
* 一、研究目的及工作内容
* 二、大学生就业数据处理与预测
*
– 2.1 爬虫大学生就业数据之保存
– 2.2 数据清洗
– 2.3 大学生就业地区和平均薪资统计
– 2.4 大学生就业行业统计
– 2.5 大学生词云统计
– 2.6 大学生就业之线性回归预测
* 总结
*
– Java精彩实战项目案例
– Java精彩新手项目案例
– Python精彩新手项目案例
前言
高校毕业生的就业方向和就业选择一直是社会各阶层和企业共同关注的热点问题,在一定程度上反应了学校和政府部门领导能力。利用大数据和人工智能对就业情况进行数据分析和预测对高校的专业设置和政府决策部门具有重要的参考价值。本文基于Python技术和MySQL,针对高校毕业生就业方向和就业情况建立了网络爬虫的大学生就业数据分析与预测。系统是为了通过大数据对学生的就业信息进行分析,为了最终实现要求,本系统以PyCharm为开发平台。经过细心的调研和衡量,以Python技术为核心去编写后台和实现各业务接口,以matplotlib作为数据的展示和操作。根据现在软件编程行业的发展,为了达到快速敏捷的开发系统环境中使用了scikit-learn(线性回规算法)框架来对源数据进行训练并保存结果模型。
一、研究目的及工作内容
针对现在学生就业问题信息收集和分析的工作仍然比较大,可能还需要聘请对应的就业指导老师或者在原有的基础上给班主任增加工作量,这对于学校来说是不好的,加大了人力资源资金的投入,需要本着低成本高效率的管理模式,我们需要对这一方面进行改革,我需要改变传统的用记事本登记就业信息记录,就业的吞吐量需要很长时间才能知道。为了解决这些难点和痛点,开发基于Python+MySQL大学生就业数据分析系统刻不容缓。主要的工作内容包括第一确认要抓取的数据源站点;第二写爬虫抓取,并保存到本地MySQL;第三数据清洗,即把有异常的数据进行剔除;第四数据特征提取:即把不可直接使用的数据进行转换,一般是把要进行训练的维度转成对应的数字;第五源数据图表展示;第六数据集训练,即用线性回规算法对源数据进行训练并保存结果模型;第七数据预测,并用图表展示结果等。该系统为学生就业管理员提供了安全高效的服务同时,切实的解决了学生就业分析管理的烦恼。
二、大学生就业数据处理与预测
2.1 爬虫大学生就业数据之保存
首先通过data_ana/gaode_map.py文件进行爬虫,对于爬虫的网站是x.597.com;爬虫的实现首先通过python中的requests.get请求当前地址,此基础项是为了得到大学生就业的数据,数据库主要包含(id,省,市区,公司名称,最少薪资,最多薪资,薪资水平、工作年限,学历,年龄最小值,年龄最大值,需要的人数)等多项数据,是整个功能完成的基础,得到此大学生就业数据后保存在MySQL中,作为后面功能分析的基石数据爬取结果如下。
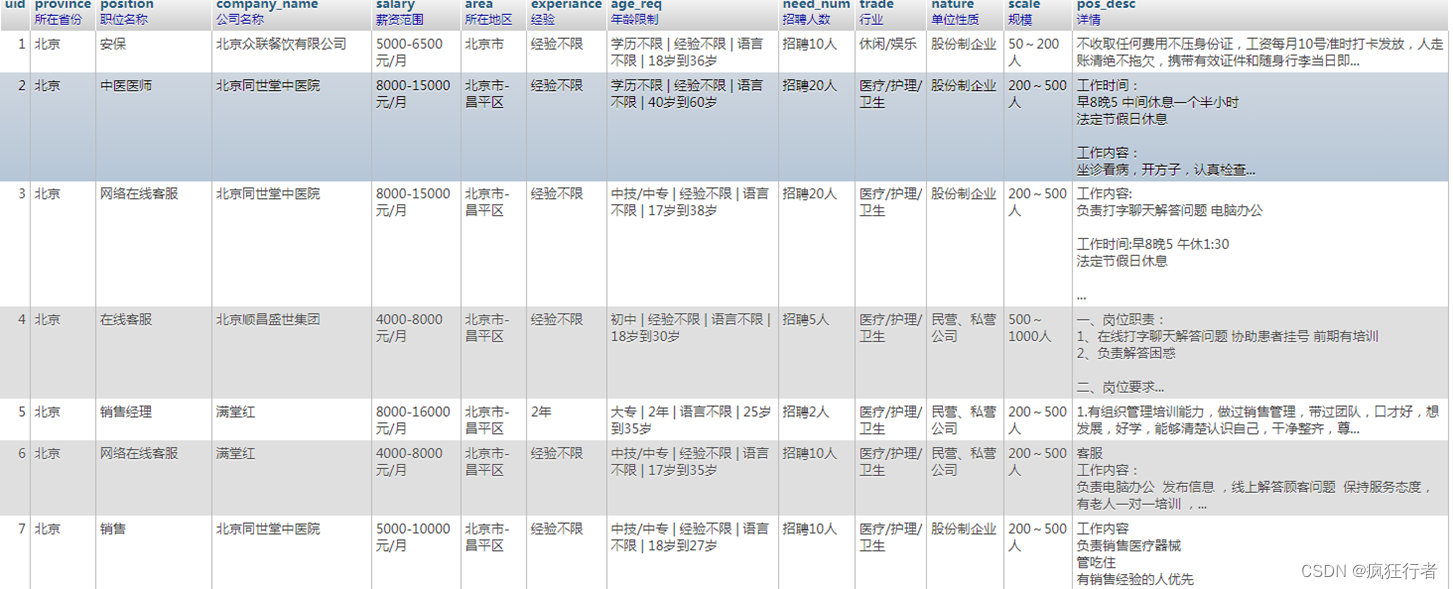

; 2.2 数据清洗
从爬虫得到数据后,第二步就是对数据进行清洗和整理,使用Python内置csv模块,来提取整个URL中的数据,把没有作用的、无效的、不完整的数据完全剔除掉。主要实现方式是通过pyMySQL模块对数据进行合并,保存在MySQL中主要的数据有id、地区、行业,数据清洗代码如下图所示:
2.3 大学生就业地区和平均薪资统计
该功能分析主要是通过柱状图展示,横坐标代表每个省份,纵坐标代表大学生就业数量,柱状图蓝色代表大学生的平均薪资、黄色代表招聘人数,该数据主要是为了分析每个省份的公司招聘人数和平均薪资,对于大学生就业来说招聘人数和薪资的统计代表了不同地区人才需求和薪资水平,其中统计的技术是matplotlib和numpy,代码和统计图如下所示。
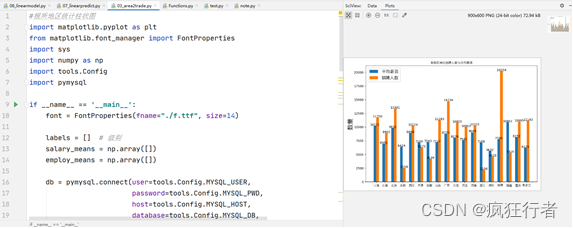
; 2.4 大学生就业行业统计
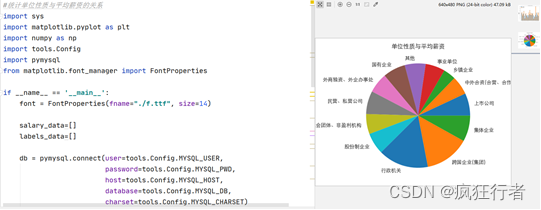
该功能分析主要是通过扇形图展示,不同颜色的区块代表着不同的单位性质,从这个数据可以得知通过对大学生就业的单位/企业进行统计,目的是为了给大学生对于毕业时地区、行业、单位性质、期望值的指导作用,大学生就业单位性质统计和代码如下图所示。
2.5 大学生词云统计
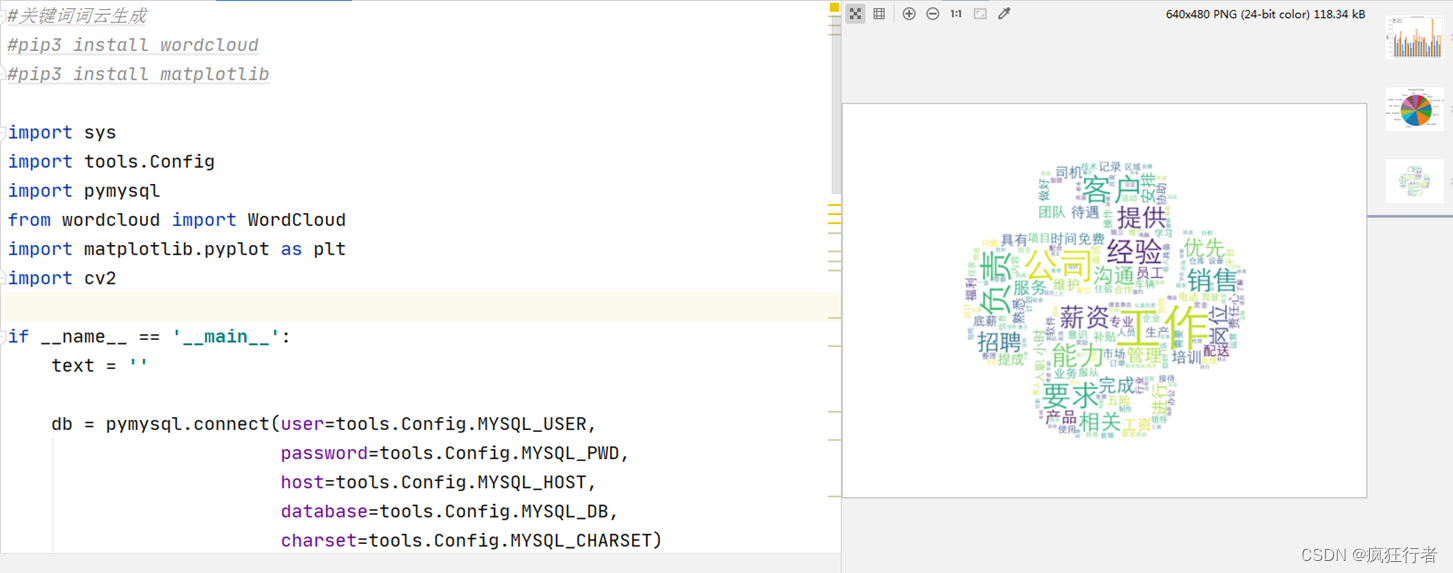
该功能主要为了统计大学生就业这个话题中出现的人们关键字,这个统计可以得出现在企业招聘时关注的关键词,给学生应聘指导了知识的方向,也给学生应聘提前的装备机会统计图和代码如下。
; 2.6 大学生就业之线性回归预测
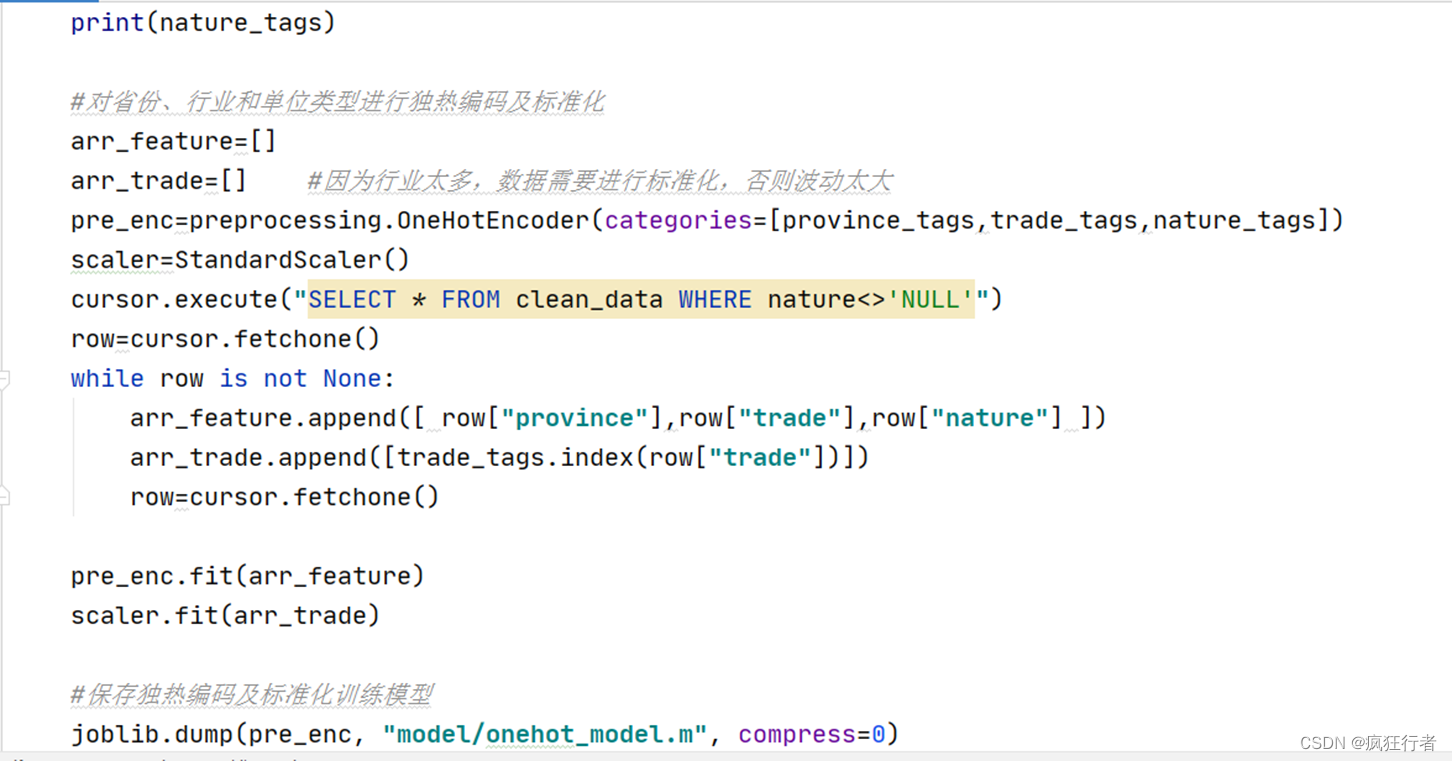
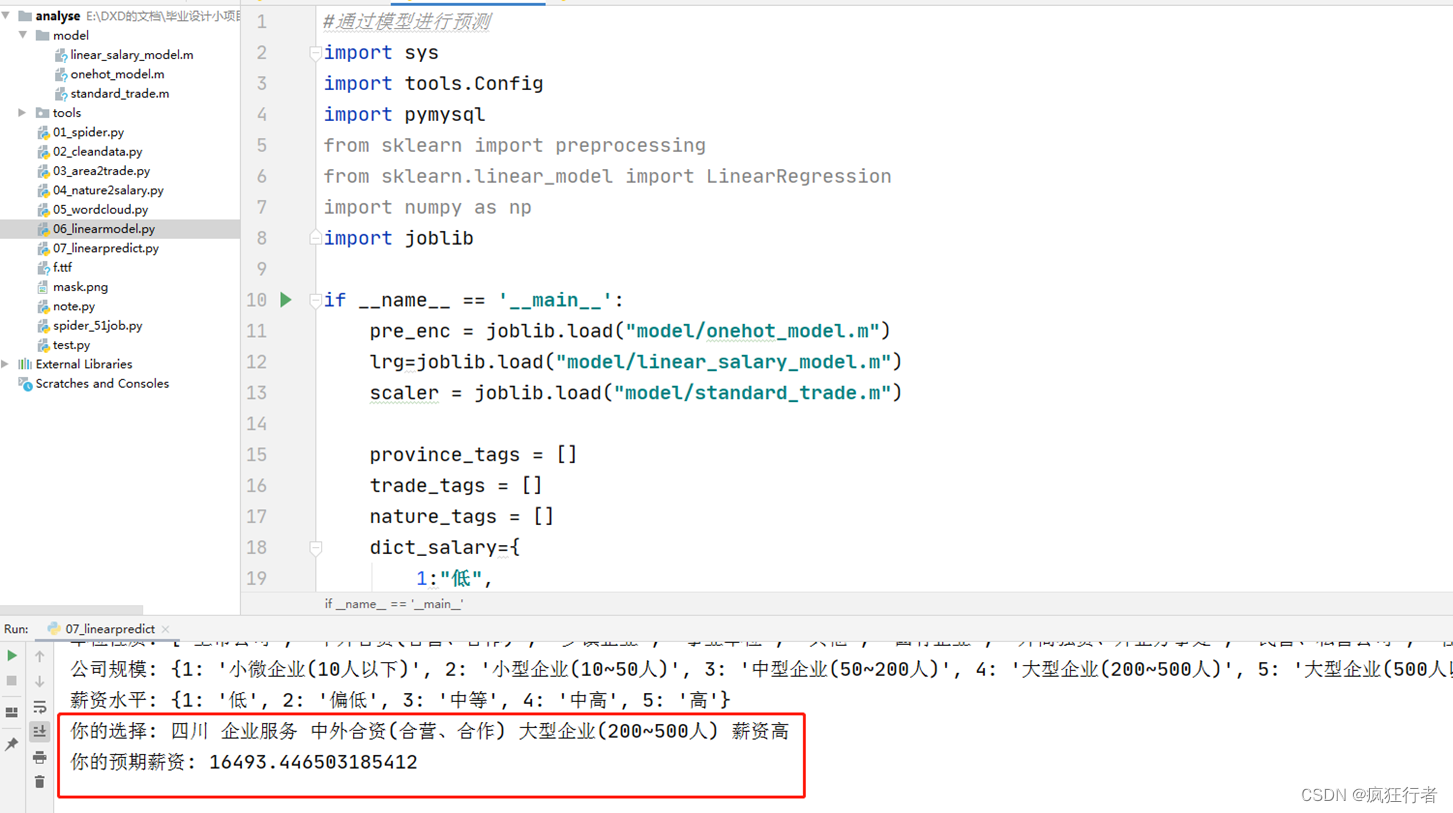
线性回归主要是通过sklearn技术来实现,该技术中主要包含数据标准化、归一化、独热编码。第一数据标准化主要是为了保证数据的特征值为机器底层二进制0(均值移除),主要目的是为了消除大学生就业数据的量纲关系,让大学生就业数据具有可比性,目前编程使用最广的标准化之一就是Z标准,其均值为0,方差为1的结果大学生就业数据。第二大学生就业数据的归一化,主要是为了对数据在不同维度上进行伸缩变换,这里的不同维度主要是几个方面如地区和自我期望薪资、最大公司规模和公司性质、行业影响,通过对大学生就业数据的归一化处理后使其三个方面的权重对目标线性回归函数的影响权重是一致的,并没有偏向性。
总结
大家点赞、收藏、关注、评论啦 、
打卡 文章 更新 40/ 365天
精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
Original: https://blog.csdn.net/QinTao9961220/article/details/126715872
Author: 疯狂行者
Title: 基于网络爬虫的大学生就业数据分析与预测模型研究
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/731742/
转载文章受原作者版权保护。转载请注明原作者出处!