

pandas 读取excel文件
*
– 一 read_excel() 的基本用法
– 二 read_excel() 的常用的参数:
– 三 示例
–
+ 1. IO:路径
+ 2. sheet_name:指定工作表名
+ 3. header :指定标题行
+ 4. names: 指定列名
+ 5. index_col: 指定列索引
+ 6. skiprows:跳过指定行数的数据
+ 7. skipfooter:省略从尾部的行数据
+ 8.dtype 指定某些列的数据类型
pandas 读取excel文件使用的是 read_excel方法。本文将详细解析read_excel方法的常用参数,以及实际的使用示例
一 read_excel() 的基本用法
import pandas as pd
file_name = 'xxx.xlsx'
pd.read_excel(file_name)
二 read_excel() 的常用的参数:
- io: excel路径 可以是文件路径, 类文件对象, 文件路径对象等。
- sheet_name=0: 访问指定excel某张工作表。sheet_name可以是str, int, list 或 None类型, 默认值是0。
- str类型 是直接指定工作表的名称
- int类型 是指定从0开始的工作表的索引, 所以sheelt_name默认值是0,即第一个工作表。
- list类型 是多个索引或工作表名构成的list,指定多个工作表。
- None类型, 访问所有的工作表
- sheet_name=0: 得到的是第1个sheet的DataFrame类型的数据
- sheet_name=2: 得到的是第3个sheet的DataFrame类型的数据
- sheet_name=’Test1′: 得到的是名为’Test1’的sheet的DataFrame类型的数据
- sheet_name=[0, 3, ‘Test5’]: 得到的是第1个,第4个和名为Test5 的工作表作为DataFrame类型的数据的字典。
- header=0:header是标题行,通过指定具体的行索引,将该行作为数据的标题行,也就是整个数据的列名。默认首行数据(0-index)作为标题行,如果传入的是一个整数列表,那这些行将组合成一个多级列索引。没有标题行使用header=None。
- name=None: 传入一列类数组类型的数据,用来作为数据的列名。
如果文件数据不包含标题行,要显式的指出header=None。 - skiprows:int类型, 类列表类型或可调函数。 要跳过的行号(0索引)或文件开头要跳过的行数(int)。如果可调用,可调用函数将根据行索引进行计算,如果应该跳过行则返回True,否则返回False。一个有效的可调用参数的例子是lambda x: x in [0, 1, 2]。
- skipfooter=0: int类型, 默认0。自下而上,从尾部指定跳过行数的数据。
- usecols=None: 指定要使用的列,如果没有默认解析所有的列。
- index_col=None: int或元素都是int的列表, 将某列的数据作为DataFrame的行标签,如果传递了一个列表,这些列将被组合成一个多索引,如果使用usecols选择的子集,index_col将基于该子集。
- squeeze=False, 布尔值,默认False。 如果解析的数据只有一列,返回一个Series。
- dtype=None: 指定某列的数据类型,可以使类型名或一个对应列名与类型的字典,例
{‘A’: np.int64, ‘B’: str} - nrows=None: int类型,默认None。 只解析指定行数的数据。
三 示例
如图是演示使用的excel文件,它包含5张工作表。
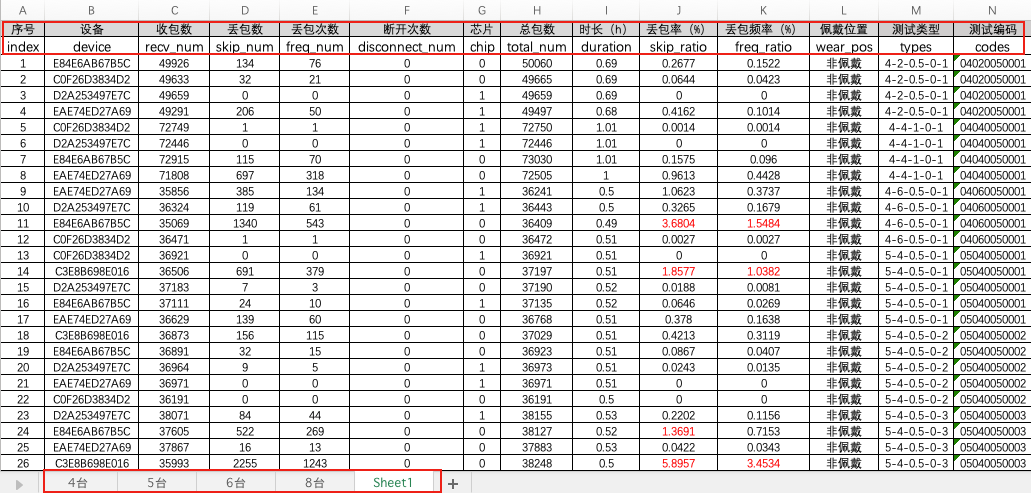

; 1. IO:路径
举一个IO为文件对象的例子, 有些时候file文件路径的包含较复杂的中文字符串时,pandas 可能会解析文件路径失败,可以使用文件对象来解决。
file = 'xxxx.xlsx'
f = open(file, 'rb')
df = pd.read_excel(f, sheet_name='Sheet1')
f.close()
with open(file, 'rb') as f:
df = pd.read_excel(f, sheet_name='Sheet1')
2. sheet_name:指定工作表名
sheet_name=’Sheet’, 指定解析名为”Sheet1″的工作表。返回一个DataFrame类型的数据。
df = pd.read_excel(file, sheet_name='Sheet1')
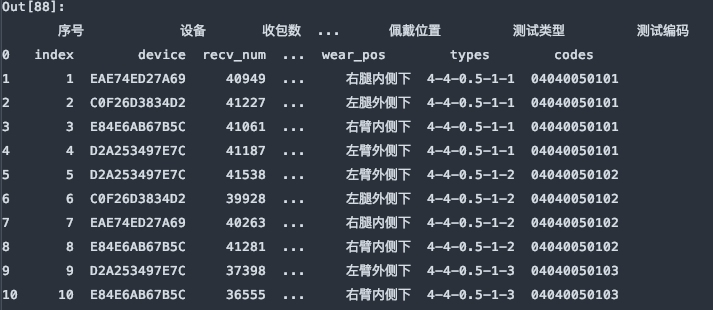
sheet_name=[0, 1, ‘Sheet1’], 对应的是解析文件的第1, 2张工作表和名为”Sheet1″的工作表。它返回的是一个有序字典。结构为{name:DataFrame}这种类型。
df_dict = pd.read_excel(file, sheet_name=[0,1,'Sheet1'])
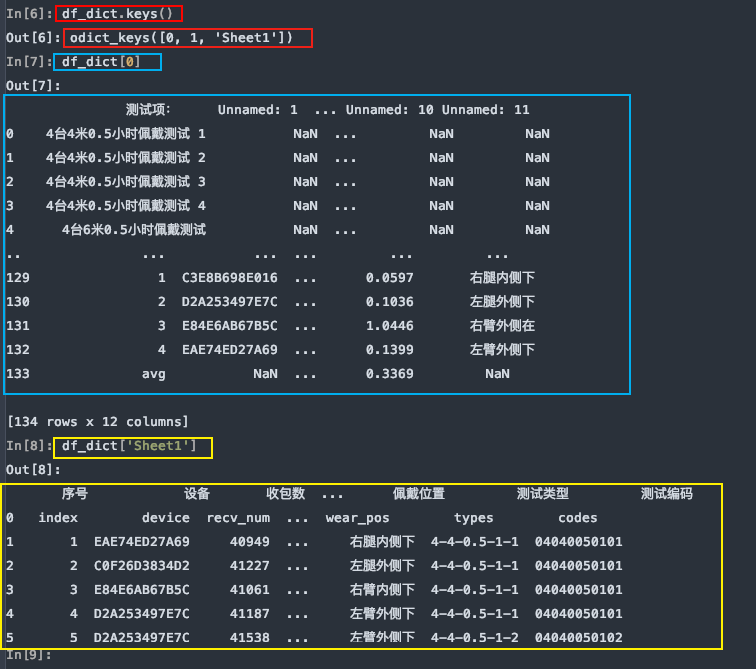
sheet_name=None 会解析该文件中所有的工作表,返回一个同上的字典类型的数据。
df_dict = pd.read_excel(file, sheet_name=None)

3. header :指定标题行
header是用来指定数据的标题行,也就是数据的列名的。本文使用的示例文件具有中英文两行列名,默认header=0是使用第一行数据作为数据的列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1')
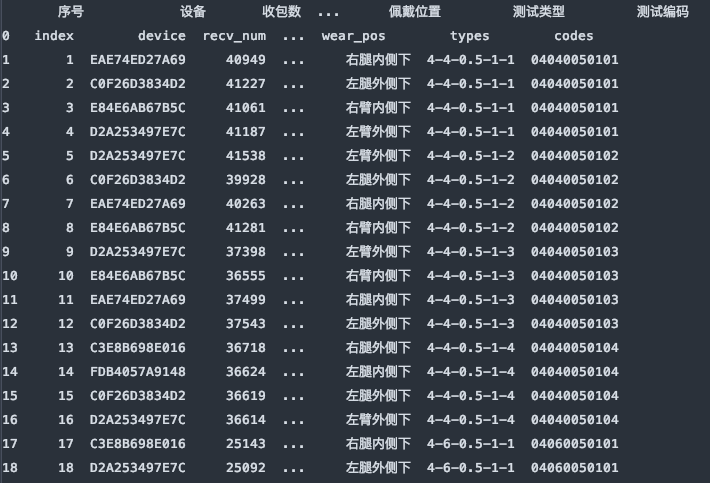
header=1, 使用指定使用第二行的英文列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1', header=1)
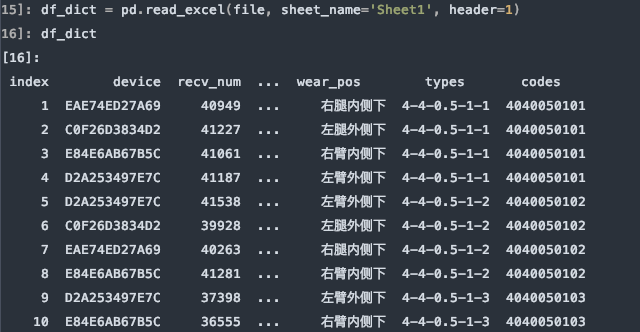
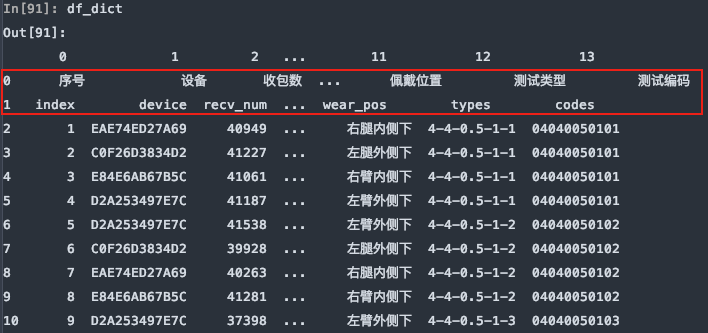
需要注意的是,如果不行指定任何行作为列名,或数据源是无标题行的数据,可以显示的指定header=None来表明不使用列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1', header=None)
4. names: 指定列名
指定数据的列名,如果数据已经有列名了,会替换掉原有的列名。
df = pd.read_excel(file, sheet_name='Sheet1', names=list('123456789ABCDE'))
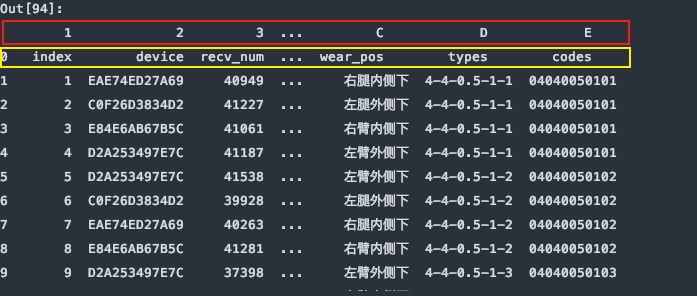
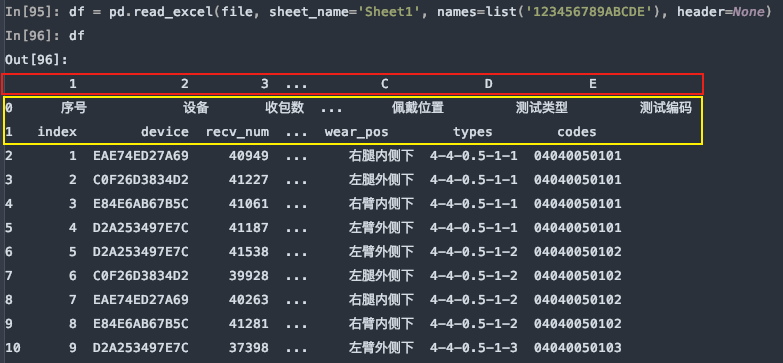
上图是header=0默认第一行中文名是标题行,最后被names给替换了列名,如果只想使用names,而又对源数据不做任何修改,我们可以指定header=None
df = pd.read_excel(file, sheet_name='Sheet1', names=list('123456789ABCDE'), header=None)
5. index_col: 指定列索引
df = pd.read_excel(file, sheet_name='Sheet1', header=1, index_col=0)
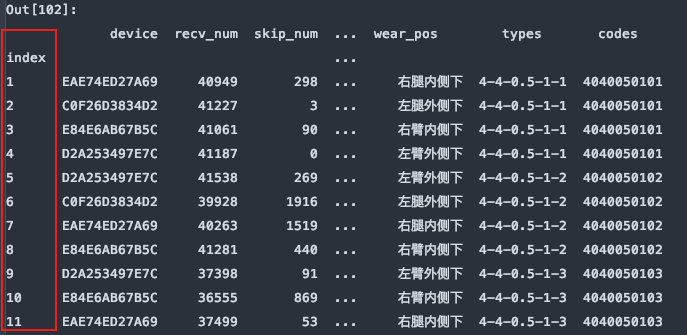
6. skiprows:跳过指定行数的数据
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=0)
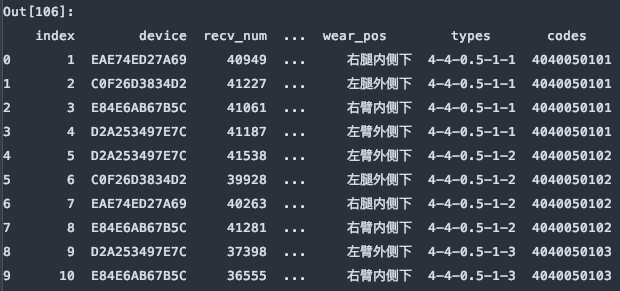
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=[1,3,5,7,9,])
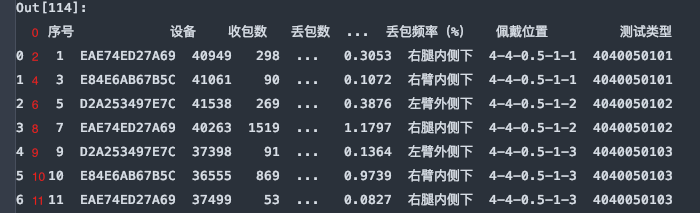
header与skiprows在有些时候效果相同,例skiprows=5和header=5。因为跳过5行后就是以第六行,也就是索引为5的行默认为标题行了。需要注意的是skiprows=5的5是行数,header=5的5是索引为5的行。
df = pd.read_excel(file, sheet_name='Sheet1', header=5)
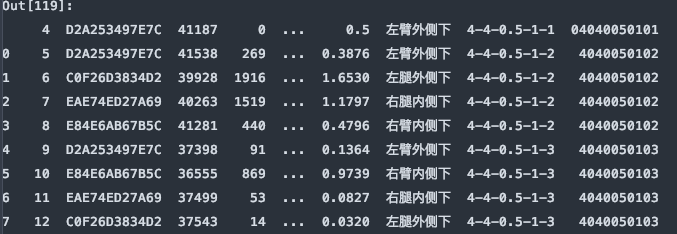
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=5)
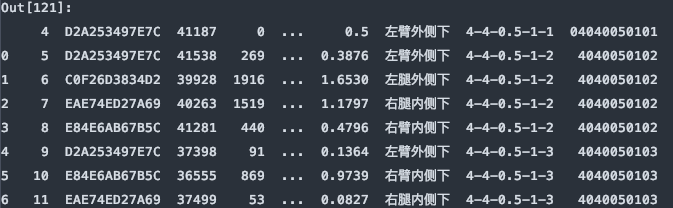
原始的数据有47行,如下图所示:
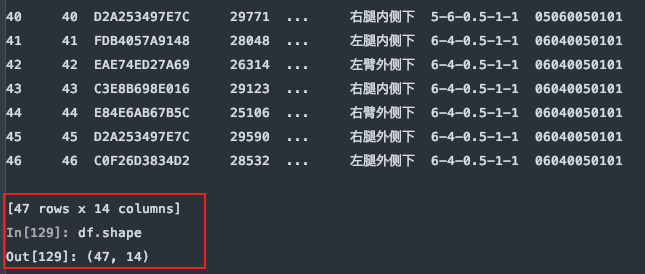
从尾部跳过5行:
df = pd.read_excel(file, sheet_name='Sheet1', skipfooter=5)

8.dtype 指定某些列的数据类型
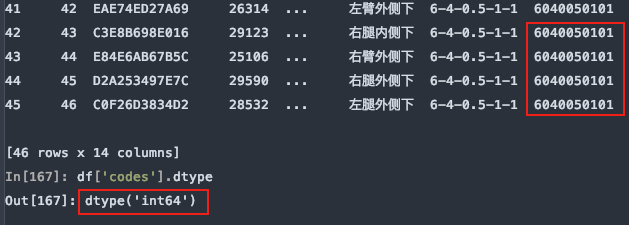
示例数据中,测试编码数据是文本,而pandas在解析的时候自动转换成了int64类型,这样codes列的首位0就会消失,造成数据错误,如下图所示
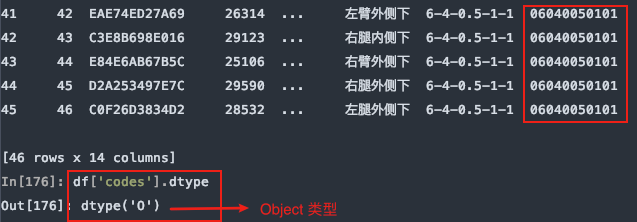
指定codes列的数据类型:
df = pd.read_excel(file, sheet_name='Sheet1', header=1, dtype={'codes': str})
Original: https://blog.csdn.net/littleRpl/article/details/113996603
Author: littleRpl
Title: pandas 读取excel文件
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/731683/
转载文章受原作者版权保护。转载请注明原作者出处!