

Retinanet 网络结构详解以及源代码讲解
网络backbone使用ResNet【18, 34, 50, 101, 152】
FPN层
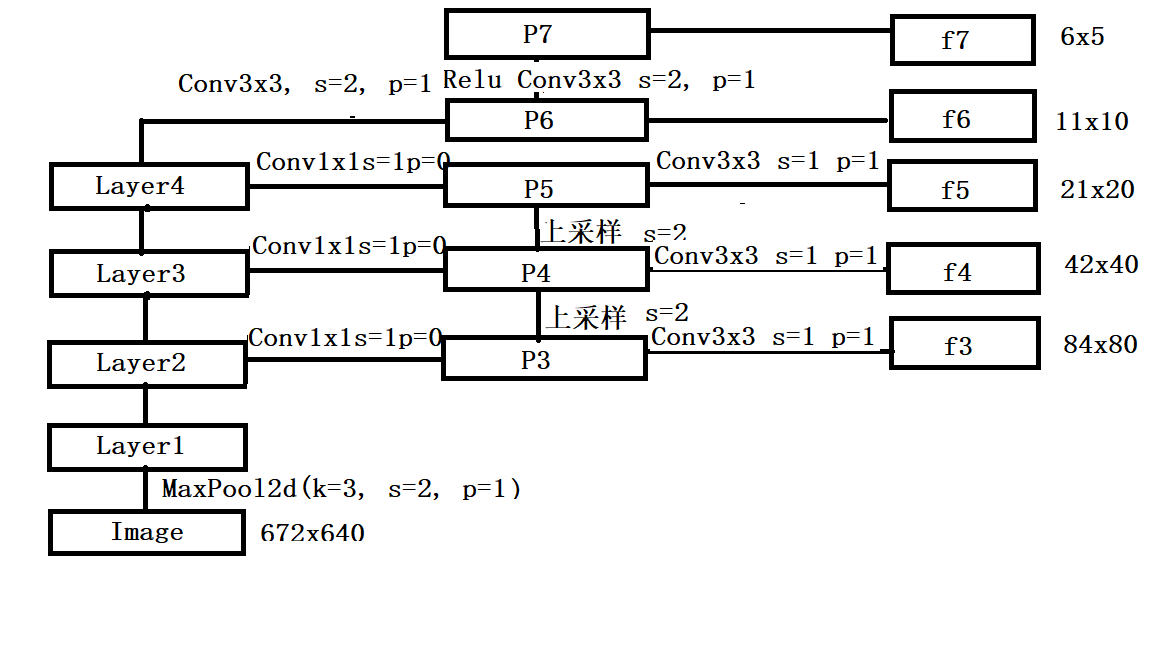

首先输入的照片的大小为672×640, 然后经过一个池化层, 使用ResNet网络提取特征,得到四个不同尺度的特征图,layer1, layer2, layer3,layer4.源代码中的尺度融合是从layer2层开始。然后再经过尺度融合得到f3, f4, f5, f6, f7五个不同尺度的特征层。
; 一、Focal Loss
Retinanet网络的核心就是Focal Loss, 他在精度上超过two-stage网络的精度,在速度上超过one-stage网络的速度,首次实现一阶段网络对二阶段网络的全面超越。
Focal Loss是在二分类交叉熵的基础上进行修改,首先回顾一下二分类交叉熵损失。

可以看到在训练过程中正样本所占的损失权重比较大, 负样本所占的损失权重比较小。但是由于负样本的数量比较多,即使权重比较小,但是大量的样本数量叠加到一块同样带来很大的损失,在训练迭代的过程中很难优化到最优状态,所以Focal Loss在此基础上进行了改进.
Focal Loss损失
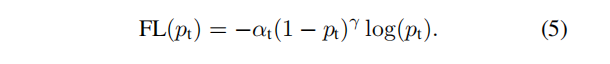
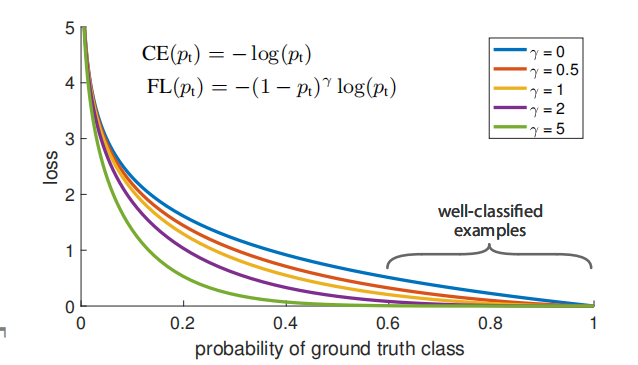
在论文中指出gamma=2.0, alpha=0.25,当预测样本为简单正样本时假设p=0.9, (1-p)的gamma次方就会变得很小,因此损失函数值就会变得非常小,对于负样本而言,当预测概率为0.5时,损失只减少0.25倍,因此损失函数更加关注这类难以区分的的样本。
; 二、源代码讲解
1.model.py
代码如下(示例):
import torch.nn as nn
import torch
import math
import torch.utils.model_zoo as model_zoo
from torchvision.ops import nms
from retinanet.utils import BasicBlock, Bottleneck, BBoxTransform, ClipBoxes
from retinanet.anchors import Anchors
from retinanet import losses
model_urls = {
'resnet18': 'https:
'resnet34': 'https:
'resnet50': 'https:
'resnet101': 'https:
'resnet152': 'https:
}
FPN特征图尺度融合
class PyramidFeatures(nn.Module):
def __init__(self, C3_size, C4_size, C5_size, feature_size=256):
super(PyramidFeatures, self).__init__()
# upsample C5 to get P5 from the FPN paper
self.P5_1 = nn.Conv2d(C5_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P5_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P5_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
# add P5 elementwise to C4
self.P4_1 = nn.Conv2d(C4_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P4_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P4_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
# add P4 elementwise to C3
self.P3_1 = nn.Conv2d(C3_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P3_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
# "P6 is obtained via a 3x3 stride-2 conv on C5"
self.P6 = nn.Conv2d(C5_size, feature_size, kernel_size=3, stride=2, padding=1)
# "P7 is computed by applying ReLU followed by a 3x3 stride-2 conv on P6"
self.P7_1 = nn.ReLU()
self.P7_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=2, padding=1)
def forward(self, inputs):
C3, C4, C5 = inputs
P5_x = self.P5_1(C5)
P5_upsampled_x = self.P5_upsampled(P5_x)
P5_x = self.P5_2(P5_x)
P4_x = self.P4_1(C4)
P4_x = P5_upsampled_x + P4_x
P4_upsampled_x = self.P4_upsampled(P4_x)
P4_x = self.P4_2(P4_x)
P3_x = self.P3_1(C3)
P3_x = P3_x + P4_upsampled_x
P3_x = self.P3_2(P3_x)
P6_x = self.P6(C5)
P7_x = self.P7_1(P6_x)
P7_x = self.P7_2(P7_x)
return [P3_x, P4_x, P5_x, P6_x, P7_x]
回归预测
class RegressionModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, feature_size=256):
super(RegressionModel, self).__init__()
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
# 因为每个anchor 对应的位置参数有四个所以输出维度为num_anchors * 4
self.output = nn.Conv2d(feature_size, num_anchors * 4, kernel_size=3, padding=1)
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
# out is B x C x W x H, with C = 4*num_anchors
out = out.permute(0, 2, 3, 1)
return out.contiguous().view(out.shape[0], -1, 4)
分类预测
class ClassificationModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, num_classes=80, prior=0.01, feature_size=256):
super(ClassificationModel, self).__init__()
self.num_classes = num_classes
self.num_anchors = num_anchors
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
# 每个先验框有num_classes个类别,所以输出的维度为num_anchors * num_classes
self.output = nn.Conv2d(feature_size, num_anchors * num_classes, kernel_size=3, padding=1)
# 将输出的概率经过sigmoid处理
self.output_act = nn.Sigmoid()
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
out = self.output_act(out)
# out is B x C x W x H, with C = n_classes + n_anchors
out1 = out.permute(0, 2, 3, 1)
batch_size, width, height, channels = out1.shape
out2 = out1.view(batch_size, width, height, self.num_anchors, self.num_classes)
return out2.contiguous().view(x.shape[0], -1, self.num_classes)
用于特征提取的残差网络
class ResNet(nn.Module):
def __init__(self, num_classes, block, layers):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 512
self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # 1024
self.layer4 = self._make_layer(block, 512, layers[3], stride=2) # 2048
# 得到layer2, layer3, layer4 三个特征层的输出通道数
if block == BasicBlock:
fpn_sizes = [self.layer2[layers[1] - 1].conv2.out_channels, self.layer3[layers[2] - 1].conv2.out_channels,
self.layer4[layers[3] - 1].conv2.out_channels]
elif block == Bottleneck:
fpn_sizes = [self.layer2[layers[1] - 1].conv3.out_channels, self.layer3[layers[2] - 1].conv3.out_channels,
self.layer4[layers[3] - 1].conv3.out_channels]
else:
raise ValueError(f"Block type {block} not understood")
self.fpn = PyramidFeatures(fpn_sizes[0], fpn_sizes[1], fpn_sizes[2])
self.regressionModel = RegressionModel(256)
self.classificationModel = ClassificationModel(256, num_classes=num_classes)
self.anchors = Anchors()
self.regressBoxes = BBoxTransform()
self.clipBoxes = ClipBoxes()
self.focalLoss = losses.FocalLoss()
# 权值参数初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
prior = 0.01
self.classificationModel.output.weight.data.fill_(0)
self.classificationModel.output.bias.data.fill_(-math.log((1.0 - prior) / prior))
self.regressionModel.output.weight.data.fill_(0)
self.regressionModel.output.bias.data.fill_(0)
self.freeze_bn()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def freeze_bn(self):
'''Freeze BatchNorm layers.'''
for layer in self.modules():
if isinstance(layer, nn.BatchNorm2d):
layer.eval()
def forward(self, inputs):
# if self.training:
img_batch, annotations = inputs
# else:
# img_batch = inputs
x = self.conv1(img_batch)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
features = self.fpn([x2, x3, x4])
regression = torch.cat([self.regressionModel(feature) for feature in features], dim=1)
classification = torch.cat([self.classificationModel(feature) for feature in features], dim=1)
anchors = self.anchors(img_batch)
if self.training:
return self.focalLoss(classification, regression, anchors, annotations)
else:
transformed_anchors = self.regressBoxes(anchors, regression)
transformed_anchors = self.clipBoxes(transformed_anchors, img_batch)
finalResult = [[], [], []]
finalScores = torch.Tensor([])
finalAnchorBoxesIndexes = torch.Tensor([]).long()
finalAnchorBoxesCoordinates = torch.Tensor([])
if torch.cuda.is_available():
finalScores = finalScores.cuda()
finalAnchorBoxesIndexes = finalAnchorBoxesIndexes.cuda()
finalAnchorBoxesCoordinates = finalAnchorBoxesCoordinates.cuda()
for i in range(classification.shape[2]):
scores = torch.squeeze(classification[:, :, i])
scores_over_thresh = (scores > 0.05)
if scores_over_thresh.sum() == 0:
# no boxes to NMS, just continue
continue
scores = scores[scores_over_thresh]
anchorBoxes = torch.squeeze(transformed_anchors)
anchorBoxes = anchorBoxes[scores_over_thresh]
anchors_nms_idx = nms(anchorBoxes, scores, 0.5)
finalResult[0].extend(scores[anchors_nms_idx])
finalResult[1].extend(torch.tensor([i] * anchors_nms_idx.shape[0]))
finalResult[2].extend(anchorBoxes[anchors_nms_idx])
finalScores = torch.cat((finalScores, scores[anchors_nms_idx]))
finalAnchorBoxesIndexesValue = torch.tensor([i] * anchors_nms_idx.shape[0])
if torch.cuda.is_available():
finalAnchorBoxesIndexesValue = finalAnchorBoxesIndexesValue.cuda()
finalAnchorBoxesIndexes = torch.cat((finalAnchorBoxesIndexes, finalAnchorBoxesIndexesValue))
finalAnchorBoxesCoordinates = torch.cat((finalAnchorBoxesCoordinates, anchorBoxes[anchors_nms_idx]))
return [finalScores, finalAnchorBoxesIndexes, finalAnchorBoxesCoordinates]
def resnet18(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18'], model_dir='.'), strict=False)
return model
def resnet34(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34'], model_dir='.'), strict=False)
return model
def resnet50(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50'], model_dir='.'), strict=False)
return model
def resnet101(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101'], model_dir='.'), strict=False)
return model
def resnet152(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152'], model_dir='.'), strict=False)
return model
2.anchors.py
代码如下(示例):
import numpy as np
import torch
import torch.nn as nn
class Anchors(nn.Module):
def __init__(self, pyramid_levels=None, strides=None, sizes=None, ratios=None, scales=None):
super(Anchors, self).__init__()
if pyramid_levels is None:
self.pyramid_levels = [3, 4, 5, 6, 7]
# 特征图相对于原图的步长
if strides is None:
self.strides = [2 ** x for x in self.pyramid_levels]
# 先验框的尺寸
if sizes is None:
self.sizes = [2 ** (x + 2) for x in self.pyramid_levels]
if ratios is None:
self.ratios = np.array([0.5, 1, 2])
if scales is None:
self.scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
def forward(self, image):
image_shape = image.shape[2:]
image_shape = np.array(image_shape)
# 获得特征图的大小
image_shapes = [(image_shape + 2 ** x - 1)
# compute anchors over all pyramid levels
all_anchors = np.zeros((0, 4)).astype(np.float32)
for idx, p in enumerate(self.pyramid_levels):
anchors = generate_anchors(base_size=self.sizes[idx], ratios=self.ratios, scales=self.scales)
shifted_anchors = shift(image_shapes[idx], self.strides[idx], anchors)
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
all_anchors = np.expand_dims(all_anchors, axis=0)
# 返回所有的先验框
if torch.cuda.is_available():
return torch.from_numpy(all_anchors.astype(np.float32)).cuda()
else:
return torch.from_numpy(all_anchors.astype(np.float32))
def generate_anchors(base_size=16, ratios=None, scales=None):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales w.r.t. a reference window.
"""
if ratios is None:
ratios = np.array([0.5, 1, 2])
if scales is None:
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
num_anchors = len(ratios) * len(scales)
# initialize output anchors
anchors = np.zeros((num_anchors, 4))
# scale base_size
anchors[:, 2:] = base_size * np.tile(scales, (2, len(ratios))).T
# compute areas of anchors
areas = anchors[:, 2] * anchors[:, 3]
# correct for ratios
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales)))
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales))
# transform from (x_ctr, y_ctr, w, h) -> (x1, y1, x2, y2)
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
return anchors
def compute_shape(image_shape, pyramid_levels):
"""Compute shapes based on pyramid levels.
:param image_shape:
:param pyramid_levels:
:return:
"""
image_shape = np.array(image_shape[:2])
image_shapes = [(image_shape + 2 ** x - 1)
return image_shapes
def anchors_for_shape(
image_shape,
pyramid_levels=None,
ratios=None,
scales=None,
strides=None,
sizes=None,
shapes_callback=None,
):
image_shapes = compute_shape(image_shape, pyramid_levels)
# compute anchors over all pyramid levels
all_anchors = np.zeros((0, 4))
for idx, p in enumerate(pyramid_levels):
anchors = generate_anchors(base_size=sizes[idx], ratios=ratios, scales=scales)
shifted_anchors = shift(image_shapes[idx], strides[idx], anchors)
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
return all_anchors
def shift(shape, stride, anchors):
shift_x = (np.arange(0, shape[1]) + 0.5) * stride
shift_y = (np.arange(0, shape[0]) + 0.5) * stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((
shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel()
)).transpose()
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
A = anchors.shape[0]
K = shifts.shape[0]
all_anchors = (anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
all_anchors = all_anchors.reshape((K * A, 4))
return all_anchors
3. losses.py
代码如下(示例):
import numpy as np
import torch
import torch.nn as nn
def calc_iou(a, b):
# b框的面积
# 计算交并比
area = (b[:, 2] - b[:, 0]) * (b[:, 3] - b[:, 1]) # 计算得到b框的面积
#每个 a 框与所有b框相交部分的宽
iw = torch.min(torch.unsqueeze(a[:, 2], dim=1), b[:, 2]) - torch.max(torch.unsqueeze(a[:, 0], 1), b[:, 0])
# 每个a 框与所有b框相交部分的高
ih = torch.min(torch.unsqueeze(a[:, 3], dim=1), b[:, 3]) - torch.max(torch.unsqueeze(a[:, 1], 1), b[:, 1])
iw = torch.clamp(iw, min=0)
ih = torch.clamp(ih, min=0)
# a 框与 b框的并集
ua = torch.unsqueeze((a[:, 2] - a[:, 0]) * (a[:, 3] - a[:, 1]), dim=1) + area - iw * ih
ua = torch.clamp(ua, min=1e-8)
intersection = iw * ih
IoU = intersection / ua
return IoU
class FocalLoss(nn.Module):
# def __init__(self):
# classifications 网络预测类别信息
# regressions 网络预测回归信息
# anchors 先验框
# annotations 真实框的坐标以及类别信息
def forward(self, classifications, regressions, anchors, annotations):
alpha = 0.25
gamma = 2.0
batch_size = classifications.shape[0]
classification_losses = []
regression_losses = []
anchor = anchors[0, :, :]
anchor_widths = anchor[:, 2] - anchor[:, 0]
anchor_heights = anchor[:, 3] - anchor[:, 1]
anchor_ctr_x = anchor[:, 0] + 0.5 * anchor_widths
anchor_ctr_y = anchor[:, 1] + 0.5 * anchor_heights
for j in range(batch_size):
# 获取分类预测结果
classification = classifications[j, :, :]
# 获取回归预测结果
regression = regressions[j, :, :]
# 获得真实先验框信息
bbox_annotation = annotations[j]
bbox_annotation = bbox_annotation[bbox_annotation[:, 4] != -1]
classification = torch.clamp(classification, 1e-4, 1.0 - 1e-4)
if bbox_annotation.shape[0] == 0:
# 只有负样本时只计算分类Focal loss
if torch.cuda.is_available():
alpha_factor = torch.ones(classification.shape).cuda() * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float().cuda())
else:
alpha_factor = torch.ones(classification.shape) * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float())
continue
IoU = calc_iou(anchors[0, :, :], bbox_annotation[:, :4]) # num_anchors x num_annotations
# IoU_max 对应的每个a框对应的所有b框的最大交并比
# IoU_argmax 每个先验框对应真实框的索引
IoU_max, IoU_argmax = torch.max(IoU, dim=1) # num_anchors x 1
# import pdb
# pdb.set_trace()
# compute the loss for classification
targets = torch.ones(classification.shape) * -1
if torch.cuda.is_available():
targets = targets.cuda()
targets[torch.lt(IoU_max, 0.4), :] = 0
# 返回的时bool 索引
positive_indices = torch.ge(IoU_max, 0.5)
num_positive_anchors = positive_indices.sum()
# 每个先验框对应的正样本
assigned_annotations = bbox_annotation[IoU_argmax, :]
# a首先将正样本的类别全部设置为0, 然后在将正样本的类别设置为1, 方便后续的CrossEntropy计算
targets[positive_indices, :] = 0
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1
if torch.cuda.is_available():
alpha_factor = torch.ones(targets.shape).cuda() * alpha
else:
alpha_factor = torch.ones(targets.shape) * alpha
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
if torch.cuda.is_available():
# 过滤掉那些值为-1的值
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape).cuda())
else:
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape))
classification_losses.append(cls_loss.sum() / torch.clamp(num_positive_anchors.float(), min=1.0))
# compute the loss for regression
if positive_indices.sum() > 0:
assigned_annotations = assigned_annotations[positive_indices, :]
# 正样本先验框对应的w, h, ctr_x, ctr_y
anchor_widths_pi = anchor_widths[positive_indices]
anchor_heights_pi = anchor_heights[positive_indices]
anchor_ctr_x_pi = anchor_ctr_x[positive_indices]
anchor_ctr_y_pi = anchor_ctr_y[positive_indices]
gt_widths = assigned_annotations[:, 2] - assigned_annotations[:, 0]
gt_heights = assigned_annotations[:, 3] - assigned_annotations[:, 1]
gt_ctr_x = assigned_annotations[:, 0] + 0.5 * gt_widths
gt_ctr_y = assigned_annotations[:, 1] + 0.5 * gt_heights
# clip widths to 1
gt_widths = torch.clamp(gt_widths, min=1)
gt_heights = torch.clamp(gt_heights, min=1)
targets_dx = (gt_ctr_x - anchor_ctr_x_pi) / anchor_widths_pi
targets_dy = (gt_ctr_y - anchor_ctr_y_pi) / anchor_heights_pi
targets_dw = torch.log(gt_widths / anchor_widths_pi)
targets_dh = torch.log(gt_heights / anchor_heights_pi)
targets = torch.stack((targets_dx, targets_dy, targets_dw, targets_dh))
targets = targets.t()
if torch.cuda.is_available():
# 对偏移量进行归一化
targets = targets / torch.Tensor([[0.1, 0.1, 0.2, 0.2]]).cuda()
else:
targets = targets / torch.Tensor([[0.1, 0.1, 0.2, 0.2]])
negative_indices = 1 + (~positive_indices)
# targets [dx, dy, w, h]
regression_diff = torch.abs(targets - regression[positive_indices, :])
regression_loss = torch.where(
torch.le(regression_diff, 1.0 / 9.0),
0.5 * 9.0 * torch.pow(regression_diff, 2),
regression_diff - 0.5 / 9.0
)
regression_losses.append(regression_loss.mean())
else:
if torch.cuda.is_available():
regression_losses.append(torch.tensor(0).float().cuda())
else:
regression_losses.append(torch.tensor(0).float())
return torch.stack(classification_losses).mean(dim=0, keepdim=True), torch.stack(regression_losses).mean(dim=0,
keepdim=True)
4. dataloader.py
代码如下(示例):此部分与源码不同,稍作修改
from __future__ import print_function, division
import sys
import os
import torch
import numpy as np
import random
import csv
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
from torch.utils.data.sampler import Sampler
import skimage.io
import skimage.transform
import skimage.color
import skimage
import cv2
from retinanet.utils import merge_bboxes
from PIL import Image
class RetinanetDataset(Dataset):
def __init__(self, train_lines, image_size, mosaic=False, is_train=True):
super(RetinanetDataset, self).__init__()
self.train_lines = train_lines
self.train_batches = len(train_lines)
self.image_size = image_size
self.mosaic = mosaic
self.flag = True
self.is_train = is_train
def __len__(self):
return self.train_batches
def rand(self, a=0, b=1):
return np.random.rand() * (b - a) + a
def get_random_data(self, annotation_line, input_shape, jitter=.3, hue=.1, sat=1.5, val=1.5, random=True):
"""实时数据增强的随机预处理"""
line = annotation_line.split()
image = Image.open(line[0])
iw, ih = image.size
h, w = input_shape
box = np.array([np.array(list(map(int, box.split(',')))) for box in line[1:]])
if not random:
scale = min(w / iw, h / ih)
nw = int(iw * scale)
nh = int(ih * scale)
dx = (w - nw)
dy = (h - nh)
image = image.resize((nw, nh), Image.BICUBIC)
new_image = Image.new('RGB', (w, h), (128, 128, 128))
new_image.paste(image, (dx, dy))
image_data = np.array(new_image, np.float32)
# 调整目标框坐标
box_data = np.zeros((len(box), 5))
if len(box) > 0:
np.random.shuffle(box)
box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx
box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy
box[:, 0:2][box[:, 0:2] < 0] = 0
box[:, 2][box[:, 2] > w] = w
box[:, 3][box[:, 3] > h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w > 1, box_h > 1)] # 保留有效框
box_data = np.zeros((len(box), 5))
box_data[:len(box)] = box
return image_data, box_data
# 调整图片大小
new_ar = w / h * self.rand(1 - jitter, 1 + jitter) / self.rand(1 - jitter, 1 + jitter)
scale = self.rand(.25, 2)
if new_ar < 1:
nh = int(scale * h)
nw = int(nh * new_ar)
else:
nw = int(scale * w)
nh = int(nw / new_ar)
image = image.resize((nw, nh), Image.BICUBIC)
# 放置图片
dx = int(self.rand(0, w - nw))
dy = int(self.rand(0, h - nh))
new_image = Image.new('RGB', (w, h),
(np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255)))
new_image.paste(image, (dx, dy))
image = new_image
# 是否翻转图片
# flip = self.rand() < .5
# if flip:
# image = image.transpose(Image.FLIP_LEFT_RIGHT)
# 色域变换
# hue = self.rand(-hue, hue)
# sat = self.rand(1, sat) if self.rand() < .5 else 1 / self.rand(1, sat)
# val = self.rand(1, val) if self.rand() < .5 else 1 / self.rand(1, val)
# x = cv2.cvtColor(np.array(image, np.float32) / 255, cv2.COLOR_RGB2HSV)
# x[..., 0] += hue * 360
# x[..., 0][x[..., 0] > 1] -= 1
# x[..., 0][x[..., 0] < 0] += 1
# x[..., 1] *= sat
# x[..., 2] *= val
# x[x[:, :, 0] > 360, 0] = 360
# x[:, :, 1:][x[:, :, 1:] > 1] = 1
# x[x < 0] = 0
# image_data = cv2.cvtColor(x, cv2.COLOR_HSV2RGB) * 255
# 调整目标框坐标
box_data = np.zeros((len(box), 5))
if len(box) > 0:
np.random.shuffle(box)
box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx
box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy
# if flip:
# box[:, [0, 2]] = w - box[:, [2, 0]]
box[:, 0:2][box[:, 0:2] < 0] = 0
box[:, 2][box[:, 2] > w] = w
box[:, 3][box[:, 3] > h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w > 1, box_h > 1)] # 保留有效框
box_data = np.zeros((len(box), 5))
box_data[:len(box)] = box
return image, box_data
def get_random_data_with_Mosaic(self, annotation_line, input_shape, hue=.1, sat=1.5, val=1.5):
h, w = input_shape
min_offset_x = 0.3
min_offset_y = 0.3
scale_low = 1 - min(min_offset_x, min_offset_y)
scale_high = scale_low + 0.2
image_datas = []
box_datas = []
index = 0
place_x = [0, 0, int(w * min_offset_x), int(w * min_offset_x)]
place_y = [0, int(h * min_offset_y), int(h * min_offset_y), 0]
for line in annotation_line:
# 每一行进行分割
line_content = line.split()
# 打开图片
image = Image.open(line_content[0])
image = image.convert("RGB")
# 图片的大小
iw, ih = image.size
# 保存框的位置
box = np.array([np.array(list(map(int, box.split(',')))) for box in line_content[1:]])
# 是否翻转图片
flip = self.rand() < .5
if flip and len(box) > 0:
image = image.transpose(Image.FLIP_LEFT_RIGHT)
box[:, [0, 2]] = iw - box[:, [2, 0]]
# 对输入进来的图片进行缩放
new_ar = w / h
scale = self.rand(scale_low, scale_high)
if new_ar < 1:
nh = int(scale * h)
nw = int(nh * new_ar)
else:
nw = int(scale * w)
nh = int(nw / new_ar)
image = image.resize((nw, nh), Image.BICUBIC)
# 进行色域变换
hue = self.rand(-hue, hue)
sat = self.rand(1, sat) if self.rand() < .5 else 1 / self.rand(1, sat)
val = self.rand(1, val) if self.rand() < .5 else 1 / self.rand(1, val)
x = cv2.cvtColor(np.array(image, np.float32) / 255, cv2.COLOR_RGB2HSV)
x[..., 0] += hue * 360
x[..., 0][x[..., 0] > 1] -= 1
x[..., 0][x[..., 0] < 0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x[:, :, 0] > 360, 0] = 360
x[:, :, 1:][x[:, :, 1:] > 1] = 1
x[x < 0] = 0
image = cv2.cvtColor(x, cv2.COLOR_HSV2RGB) # numpy array, 0 to 1
image = Image.fromarray((image * 255).astype(np.uint8))
# 将图片进行放置,分别对应四张分割图片的位置
dx = place_x[index]
dy = place_y[index]
new_image = Image.new('RGB', (w, h),
(np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255)))
new_image.paste(image, (dx, dy))
image_data = np.array(new_image)
index = index + 1
box_data = []
# 对box进行重新处理
if len(box) > 0:
np.random.shuffle(box)
box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx
box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy
box[:, 0:2][box[:, 0:2] < 0] = 0
box[:, 2][box[:, 2] > w] = w
box[:, 3][box[:, 3] > h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w > 1, box_h > 1)]
box_data = np.zeros((len(box), 5))
box_data[:len(box)] = box
image_datas.append(image_data)
box_datas.append(box_data)
# 将图片分割,放在一起
cutx = np.random.randint(int(w * min_offset_x), int(w * (1 - min_offset_x)))
cuty = np.random.randint(int(h * min_offset_y), int(h * (1 - min_offset_y)))
new_image = np.zeros([h, w, 3])
new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :]
new_image[cuty:, :cutx, :] = image_datas[1][cuty:, :cutx, :]
new_image[cuty:, cutx:, :] = image_datas[2][cuty:, cutx:, :]
new_image[:cuty, cutx:, :] = image_datas[3][:cuty, cutx:, :]
# 对框进行进一步的处理
new_boxes = np.array(merge_bboxes(box_datas, cutx, cuty))
return new_image, new_boxes
def __getitem__(self, index):
lines = self.train_lines
n = self.train_batches
index = index % n
if self.mosaic:
if self.flag and (index + 4) < n:
img, y = self.get_random_data_with_Mosaic(lines[index:index + 4], self.image_size[0:2])
else:
img, y = self.get_random_data(lines[index], self.image_size[0:2], random=self.is_train)
self.flag = bool(1 - self.flag)
else:
img, y = self.get_random_data(lines[index], self.image_size[0:2], random=self.is_train)
# if len(y) != 0:
# 从坐标转换成0~1的百分比
# boxes = np.array(y[:, :4], dtype=np.float32)
# boxes[:, 0] = boxes[:, 0] / self.image_size[1]
# boxes[:, 1] = boxes[:, 1] / self.image_size[0]
# boxes[:, 2] = boxes[:, 2] / self.image_size[1]
# boxes[:, 3] = boxes[:, 3] / self.image_size[0]
# boxes[:, 0] = boxes[:, 0]
# boxes[:, 1] = boxes[:, 1]
# boxes[:, 2] = boxes[:, 2]
# boxes[:, 3] = boxes[:, 3]
# boxes = np.maximum(np.minimum(boxes, 1), 0)
# boxes[:, 2] = boxes[:, 2] - boxes[:, 0]
# boxes[:, 3] = boxes[:, 3] - boxes[:, 1]
#
# boxes[:, 0] = boxes[:, 0] + boxes[:, 2] / 2
# boxes[:, 1] = boxes[:, 1] + boxes[:, 3] / 2
# y = np.concatenate([boxes, y[:, -1:]], axis=-1)
img = np.array(img, dtype=np.float32)
tmp_inp = np.transpose(img / 255.0, (2, 0, 1))
tmp_targets = np.array(y, dtype=np.float32)
return tmp_inp, tmp_targets
DataLoader中collate_fn使用
def retinanet_dataset_collate(batch):
images = []
bboxes = []
for img, box in batch:
images.append(img)
bboxes.append(box)
images = np.array(images)
return images, bboxes
class Resizer(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample, min_side=608, max_side=1024):
image, annots = sample['img'], sample['annot']
rows, cols, cns = image.shape
smallest_side = min(rows, cols)
# rescale the image so the smallest side is min_side
scale = min_side / smallest_side
# check if the largest side is now greater than max_side, which can happen
# when images have a large aspect ratio
largest_side = max(rows, cols)
if largest_side * scale > max_side:
scale = max_side / largest_side
# resize the image with the computed scale
image = skimage.transform.resize(image, (int(round(rows * scale)), int(round((cols * scale)))))
rows, cols, cns = image.shape
pad_w = 32 - rows % 32
pad_h = 32 - cols % 32
new_image = np.zeros((rows + pad_w, cols + pad_h, cns)).astype(np.float32)
new_image[:rows, :cols, :] = image.astype(np.float32)
annots[:, :4] *= scale
return {'img': torch.from_numpy(new_image), 'annot': torch.from_numpy(annots), 'scale': scale}
class Augmenter(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample, flip_x=0.5):
if np.random.rand() < flip_x:
image, annots = sample['img'], sample['annot']
image = image[:, ::-1, :]
rows, cols, channels = image.shape
x1 = annots[:, 0].copy()
x2 = annots[:, 2].copy()
x_tmp = x1.copy()
annots[:, 0] = cols - x2
annots[:, 2] = cols - x_tmp
sample = {'img': image, 'annot': annots}
return sample
class Normalizer(object):
def __init__(self):
self.mean = np.array([[[0.485, 0.456, 0.406]]])
self.std = np.array([[[0.229, 0.224, 0.225]]])
def __call__(self, sample):
image, annots = sample['img'], sample['annot']
return {'img': ((image.astype(np.float32) - self.mean) / self.std), 'annot': annots}
class UnNormalizer(object):
def __init__(self, mean=None, std=None):
if mean == None:
self.mean = [0.485, 0.456, 0.406]
else:
self.mean = mean
if std == None:
self.std = [0.229, 0.224, 0.225]
else:
self.std = std
def __call__(self, tensor):
"""
Args:
tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
Returns:
Tensor: Normalized image.
"""
for t, m, s in zip(tensor, self.mean, self.std):
t.mul_(s).add_(m)
return tensor
class AspectRatioBasedSampler(Sampler):
def __init__(self, data_source, batch_size, drop_last):
self.data_source = data_source
self.batch_size = batch_size
self.drop_last = drop_last
self.groups = self.group_images()
def __iter__(self):
random.shuffle(self.groups)
for group in self.groups:
yield group
def __len__(self):
if self.drop_last:
return len(self.data_source)
else:
return (len(self.data_source) + self.batch_size - 1)
def group_images(self):
# determine the order of the images
order = list(range(len(self.data_source)))
order.sort(key=lambda x: self.data_source.image_aspect_ratio(x))
# divide into groups, one group = one batch
return [[order[x % len(order)] for x in range(i, i + self.batch_size)] for i in
range(0, len(order), self.batch_size)]
5.train.py
代码如下:
import argparse
import collections
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from retinanet import model
from retinanet.dataloader import RetinanetDataset
from retinanet.dataloader import retinanet_dataset_collate
from torch.utils.data import DataLoader
load the classes
def get_classes(classes_path):
with open(classes_path) as f:
class_name = f.readlines()
class_names = [c.strip() for c in class_name]
return class_names
def fit_one_epoch(net, epoch, epoch_size, epoch_size_val, dataloader_train, dataloader_val, Epoch, cuda):
# net.train()
# 因为添加了并行计算所以要使用net.module来取出模型
net.module.freeze_bn()
total_loss = 0
val_loss = 0
print("Strat train {%d}" % epoch)
for iteration, data in enumerate(dataloader_train):
images, targets = data[0], data[1]
with torch.no_grad():
if cuda:
images = torch.from_numpy(images).type(torch.FloatTensor).cuda()
targets = [torch.from_numpy(ann).type(torch.FloatTensor) for ann in targets]
else:
images = torch.from_numpy(images).type(torch.FloatTensor)
targets = [torch.from_numpy(ann).type(torch.FloatTensor) for ann in targets]
# 梯度清零
optimizer.zero_grad()
classification_loss, regression_loss = net([images, targets])
classification_loss = classification_loss.mean()
regression_loss = regression_loss.mean()
loss = classification_loss + regression_loss
total_loss += loss.item()
if bool(loss == 0):
continue
loss.backward()
torch.nn.utils.clip_grad_norm_(net.parameters(), 0.1)
optimizer.step()
print(
'Epoch: {} | Iteration: {} | Classification loss: {:1.5f} | Regression loss: {:1.5f} | Running loss: {:1.5f}'.format(
epoch, iteration, float(classification_loss), float(regression_loss), float(loss) / (iteration + 1)))
scheduler.step(total_loss / (epoch_size + 1))
print("Start Validation")
# net.eval()
for iteration, batch in enumerate(dataloader_val):
images_val, targets_val = batch[0], batch[1]
with torch.no_grad():
if cuda:
images_val = torch.from_numpy(images_val).type(torch.FloatTensor).cuda()
targets_val = [torch.from_numpy(ann).type(torch.FloatTensor) for ann in targets_val]
else:
images_val = torch.from_numpy(images_val).type(torch.FloatTensor)
targets_val = [torch.from_numpy(ann).type(torch.FloatTensor) for ann in targets_val]
optimizer.zero_grad()
classification_loss, regression_loss = net([images_val, targets_val])
print(classification_loss.shape)
print(regression_loss.shape)
classification_loss = classification_loss.mean()
regression_loss = regression_loss.mean()
loss = classification_loss + regression_loss
val_loss += loss.item()
print("Validation Finished!")
print("Epoch:" + str(epoch + 1) + '/' + str(Epoch))
print("Train Loss : %.4f || Val Loss : %.4f" % (total_loss / (epoch_size + 1), val_loss / (epoch_size_val + 1)))
torch.save(net, 'model_data/{}_retinanet_{}.pt'.format(args.dataset, epoch))
if __name__ == "__main__":
# 添加默认的配置信息
parser = argparse.ArgumentParser(description="Simple training script for retinanet network")
parser.add_argument("--epochs", help="the total num for training", default=50)
parser.add_argument("--depth", help="Resnet network in [18, 34, 50, 101, 152]", type=int, default=50)
parser.add_argument("--class_path", help="the path of classes", type=str, default="model_data/voc_classes.txt")
parser.add_argument("--dataset", help="the dataset for training", type=str, default='voc_2007')
args = parser.parse_args()
# 获取类
classes = get_classes(args.class_path)
# 获取类别数
num_classes = len(classes)
# 创建模型
if args.depth == 18:
retinanet = model.resnet18(num_classes=num_classes, pretrained=True)
elif args.depth == 34:
retinanet = model.resnet34(num_classes=num_classes, pretrained=True)
elif args.depth == 50:
retinanet = model.resnet50(num_classes=num_classes, pretrained=True)
elif args.depth == 101:
retinanet = model.resnet101(num_classes=num_classes, pretrained=True)
elif args.depth == 152:
retinanet = model.resnet152(num_classes=num_classes, pretrained=True)
else:
raise ValueError('Unsupported model depth, must be one of 18, 34, 50, 101, 152')
# 每次训练的数据量
batch_size = 2
# 是否使用GPU训练
cuda = False
# 照片的大小
input_shape = (672, 640)
# 训练文件的路径
annotation_path = "2007_train.txt"
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
# 设置随机数种子,每次打乱之后的顺序相同
np.random.seed(100010)
np.random.shuffle(lines)
np.random.seed(None)
# 验证集的数量
num_val = int(len(lines)) * val_split
# 训练集的数量
num_train = int(len(lines) - num_val)
# 创建数据加载器
train_dataset = RetinanetDataset(lines[:num_train], (input_shape[0], input_shape[1]), mosaic=False, is_train=True)
val_dataset = RetinanetDataset(lines[num_train:], (input_shape[0], input_shape[1]), mosaic=False, is_train=False)
dataloader_train = DataLoader(train_dataset, shuffle=True, batch_size=batch_size, num_workers=4,
collate_fn=retinanet_dataset_collate)
dataloader_val = DataLoader(val_dataset, shuffle=True, batch_size=batch_size, num_workers=4,
collate_fn=retinanet_dataset_collate)
epoch_size = num_train
epoch_size_val = num_val
if cuda:
if torch.cuda.is_available():
retinanet = retinanet.cuda()
if torch.cuda.is_available():
retinanet = torch.nn.DataParallel(retinanet).cuda()
else:
retinanet = torch.nn.DataParallel(retinanet)
# 将模型设置为训练模式
retinanet.training = True
# 创建优化器
optimizer = optim.Adam(retinanet.parameters(), lr=1e-5)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=3, verbose=True)
loss_hist = collections.deque(maxlen=500)
retinanet.train()
retinanet.module.freeze_bn()
for epoch in range(args.epochs):
fit_one_epoch(retinanet, epoch, epoch_size, epoch_size_val, dataloader_train, dataloader_val, args.epochs, cuda)
retinanet.eval()
torch.save(retinanet, "model_data/model_final.pt")
以上部分均为个人理解,如有错误欢迎各位批评指正。
目前已实现口罩数据集检测,效果如下

Original: https://blog.csdn.net/weixin_41981679/article/details/123823507
Author: 目标检测小白
Title: Retinanet网络详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/731091/
转载文章受原作者版权保护。转载请注明原作者出处!