

python实现共轭梯度优化算法
- 一、共轭梯度算法简介
- 二、实现共轭梯度方法的两块重要积木
* - 1.共轭方向的确定
- 2.方向优化步长的确定
- note
- 三、共轭梯度算法优化过程
- 四、python实现共轭梯度算法
* - 1.FR-CG
- 2.PRP-CG
- 3.GD
- 五、总结
一、共轭梯度算法简介
共轭梯度(Conjugate Gradient)方法是一种迭代算法,可用于求解 无约束的优化问题,例如能量最小化。常见的优化算法还有梯度下降法,相比于梯度下降法,共轭梯度法具有收敛更快,以及算法稳定性更好的优点。
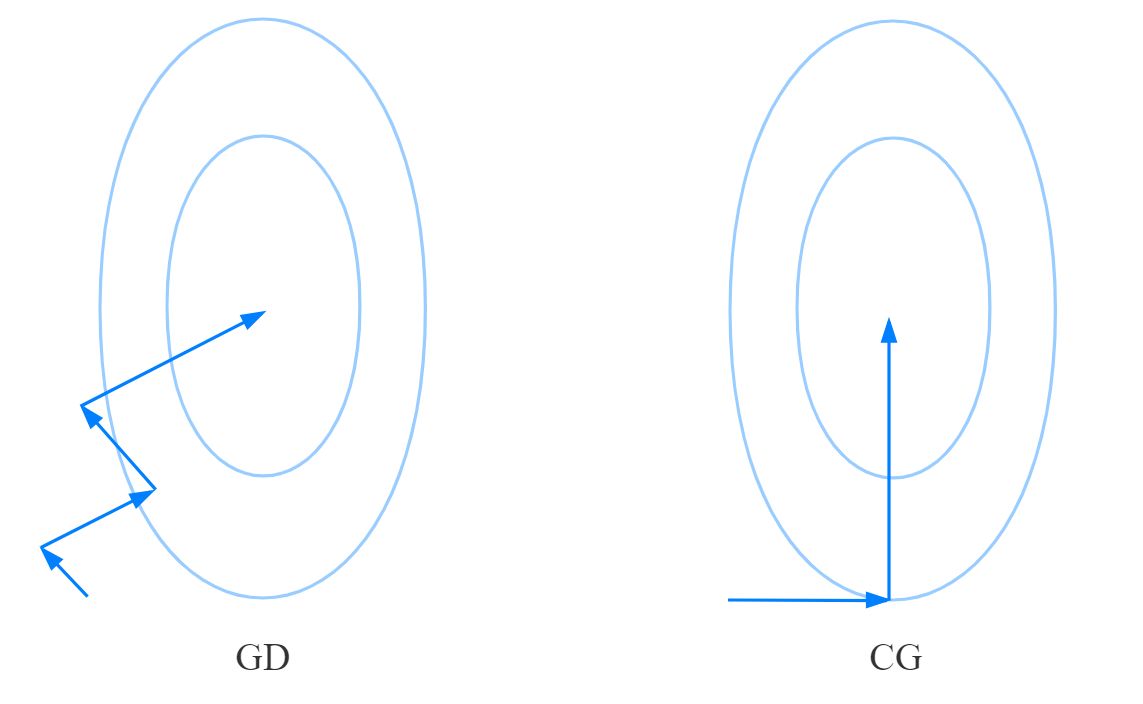

从上图可以看出来,梯度下降法优化过程中函数是沿着梯度的反方向逐步优化,后一步优化的结果会对前一步的优化结果造成影响,收敛较慢。而共轭梯度方法每一步的优化方向与前一步的优化方向是 共轭的,因此并不会对前一步的优化结果造成影响,同时优化过程中保证在每一个方向上函数优化到最小值,从而保证沿着这些共轭方向优化完成后,函数能够达到全局最小值点。具体解释可以参考这篇文章:https://zhuanlan.zhihu.com/p/338838078
; 二、实现共轭梯度方法的两块重要积木
1.共轭方向的确定
共轭梯度方法中的新的共轭方向仅由 上一步的梯度, 新的梯度和 上一步的优化方向决定,即:
d ⃗ k + 1 = − g ⃗ k + 1 + β k d ⃗ k \vec{d}{k+1}=-\vec{g}{k+1}+\beta_k\vec{d}k d k +1 =−g k +1 +βk d k
其中β k \beta_k βk 的定义方式有很多种,常用的有 FR和 PRP两种:
β k F R = g k + 1 T g k + 1 g k T g k = ∣ g ⃗ k + 1 ∣ 2 ∣ g ⃗ k ∣ 2 \beta_k^{FR}=\frac{g{k+1}^Tg_{k+1}}{g_k^Tg_k}=\frac{|\vec{g}{k+1}|^2}{|\vec{g}_k|^2}βk F R =g k T g k g k +1 T g k +1 =∣g k ∣2 ∣g k +1 ∣2
β k P R P = g k + 1 T ( g k + 1 − g k ) g k T g k = g ⃗ k + 1 ⋅ ( g ⃗ k + 1 − g ⃗ k ) ∣ g ⃗ k ∣ 2 \beta_k^{PRP}=\frac{g{k+1}^T(g_{k+1}-g_k)}{g_k^Tg_k}=\frac{\vec{g}{k+1}\cdot(\vec{g}{k+1}-\vec{g}_k)}{|\vec{g}_k|^2}βk P R P =g k T g k g k +1 T (g k +1 −g k )=∣g k ∣2 g k +1 ⋅(g k +1 −g k )
2.方向优化步长的确定
当优化方向确定之后,需要利用 线性搜索技术确定优化的步长α m i n \alpha_{min}αm i n ,即是寻找α>0使得
f ( x ⃗ + α m i n d ⃗ ) = m i n f ( x ⃗ + α d ⃗ ) f(\vec{x}+\alpha_{min}\vec{d})=minf(\vec{x}+\alpha\vec{d})f (x +αm i n d )=m i n f (x +αd )
线搜索技术包含两大类,即精确线搜索技术和非精确线搜索技术,详见这篇文章:https://www.longzf.com/optimization/2/line_search/
精确线搜索技术包括牛顿法和二分法。由于之后的代码使用的线搜索技术是牛顿法,所以下面简单介绍一下牛顿法。
牛顿法被用于求解函数的极小极大值问题,函数在极值点处应有f ′ ( α ) = 0 f'(\alpha)=0 f ′(α)=0,将函数展开到二阶泰勒展开之后,可以得到α的迭代公式:
α k + 1 = α k − f ′ ( α k ) f ′ ′ ( α k ) \alpha_{k+1} = {\alpha}_k – \frac{f'(\alpha_k)}{f”(\alpha_k)}αk +1 =αk −f ′′(αk )f ′(αk )
note
由于数值计算过程中要用到差分的方法,所以这里简单列出以下使用一阶微分和二阶微分所使用的差分表达式:
f ′ ( x ) ≈ f ( x + δ ) − f ( x − δ ) 2 δ f'(x)\approx\frac{f(x+\delta )-f(x-\delta)}{2\delta}f ′(x )≈2 δf (x +δ)−f (x −δ)
f ′ ′ ( x ) ≈ f ( x + δ ) + f ( x − δ ) − 2 f ( x ) δ 2 f”(x)\approx\frac{f(x+\delta)+f(x-\delta)-2f(x)}{\delta^2}f ′′(x )≈δ2 f (x +δ)+f (x −δ)−2 f (x )
其中δ \delta δ是小量。
三、共轭梯度算法优化过程
- 计算初始初始梯度值g ⃗ 0 \vec{g}_0 g 0 和优化方向d ⃗ 0 \vec{d}_0 d 0
g ⃗ 0 = ∇ ⃗ f ( x ⃗ 0 ) \vec{g}_0=\vec{\nabla}f(\vec{x}_0)g 0 =∇f (x 0 )
d ⃗ 0 = − g ⃗ 0 \vec{d}_0 = -\vec{g}_0 d 0 =−g 0 - 如果g ⃗ k < ϵ ⃗ \vec{g}_k,退出迭代过程,否则执行以下步骤
- 用线性搜索算法(牛顿法)求出使得m i n f ( x ⃗ k + α d ⃗ k ) minf(\vec{x}k+\alpha\vec{d}_k)m i n f (x k +αd k )的步长α,并更新x ⃗ k + 1 \vec{x}{k+1}x k +1 :
x ⃗ k + 1 = x ⃗ k + α d ⃗ k \vec{x}_{k+1}=\vec{x}_k+\alpha\vec{d}_k x k +1 =x k +αd k - 计算新的梯度
g ⃗ k + 1 = ∇ ⃗ f ( x ⃗ k + 1 ) \vec{g}{k+1}=\vec{\nabla}f(\vec{x}{k+1})g k +1 =∇f (x k +1 ) - 根据前面提到的FR公式或PRP公式计算新的组合系数
- 计算新的共轭方向:
d ⃗ k + 1 = − g ⃗ k + 1 + β k d ⃗ k \vec{d}{k+1}=-\vec{g}{k+1}+\beta_k\vec{d}_k d k +1 =−g k +1 +βk d k - 重复执行第2步
四、python实现共轭梯度算法
这里使用的测试函数形式是:
f ( x , y ) = ( 3 x − 2 y ) 2 + ( x − 1 ) 4 f(x, y)=(3x-2y)^2+(x-1)^4 f (x ,y )=(3 x −2 y )2 +(x −1 )4
可以看到函数存在最小值点(1, 1.5),以下是实现的python代码。
1.FR-CG
import numpy as np
import matplotlib.pyplot as plt
def testFun(x, y):
t = 3.0*x - 2.0*y
t1 = x - 1.0
z = np.power(t, 2) + np.power(t1, 4)
return z
def gradTestFun(x, y):
'''
求函数的梯度
'''
delta_x = 1e-6
delta_y = 1e-6
grad_x = (testFun(x+delta_x, y)-testFun(x-delta_x, y))/(2.0*delta_x)
grad_y = (testFun(x, y+delta_y)-testFun(x, y-delta_y))/(2.0*delta_y)
grad_xy = np.array([grad_x, grad_y])
return grad_xy
def getStepLengthByNewton(array_xy, array_d):
'''
采用牛顿法,精确线性搜索确定移动步长
'''
a0 = 1.0
e0 = 1e-6
delta_a = 1e-6
while(1):
new_a = array_xy + a0*array_d
new_a_l = array_xy + (a0-delta_a)*array_d
new_a_h = array_xy + (a0+delta_a)*array_d
diff_a0 = (testFun(new_a_h[0], new_a_h[1]) - testFun(new_a_l[0], new_a_l[1]))/(2.0*delta_a)
if np.abs(diff_a0) < e0:
break
ddiff_a0 = (testFun(new_a_h[0], new_a_h[1]) + testFun(new_a_l[0], new_a_l[1]) - 2.0*testFun(new_a[0], new_a[1]))/(delta_a*delta_a)
a0 = a0 - diff_a0/ddiff_a0
return a0
def plotResult(array_xy_history):
x = np.linspace(-1.0, 4.0, 100)
y = np.linspace(-4.0, 8.0, 100)
X, Y = np.meshgrid(x, y)
Z = testFun(X, Y)
plt.figure(dpi=300)
plt.xlim(-1.0, 4.0)
plt.ylim(-4.0, 8.0)
plt.xlabel("x")
plt.ylabel("y")
plt.contour(X, Y, Z, 40)
plt.plot(array_xy_history[:,0], array_xy_history[:,1], marker='.', ms=10)
xy_count = array_xy_history.shape[0]
for i in range(xy_count):
if i == xy_count-1:
break
dx = (array_xy_history[i+1][0] - array_xy_history[i][0])*0.6
dy = (array_xy_history[i+1][1] - array_xy_history[i][1])*0.6
plt.arrow(array_xy_history[i][0], array_xy_history[i][1], dx, dy, width=0.1)
def mainFRCG():
'''
使用CG算法优化,用FR公式计算组合系数
'''
ls_xy_history = []
xy0 = np.array([4.0, -2.0])
grad_xy = gradTestFun(xy0[0], xy0[1])
d = -1.0*grad_xy
e0 = 1e-6
xy = xy0
while(1):
ls_xy_history.append(xy)
grad_xy = gradTestFun(xy[0], xy[1])
tag_reach = np.abs(grad_xy) < e0
if tag_reach.all():
break
step_length = getStepLengthByNewton(xy, d)
xy_new = xy + step_length*d
grad_xy_new = gradTestFun(xy_new[0], xy_new[1])
b = np.dot(grad_xy_new, grad_xy_new)/np.dot(grad_xy, grad_xy)
d = b*d - grad_xy_new
xy = xy_new
array_xy_history = np.array(ls_xy_history)
plotResult(array_xy_history)
return array_xy_history
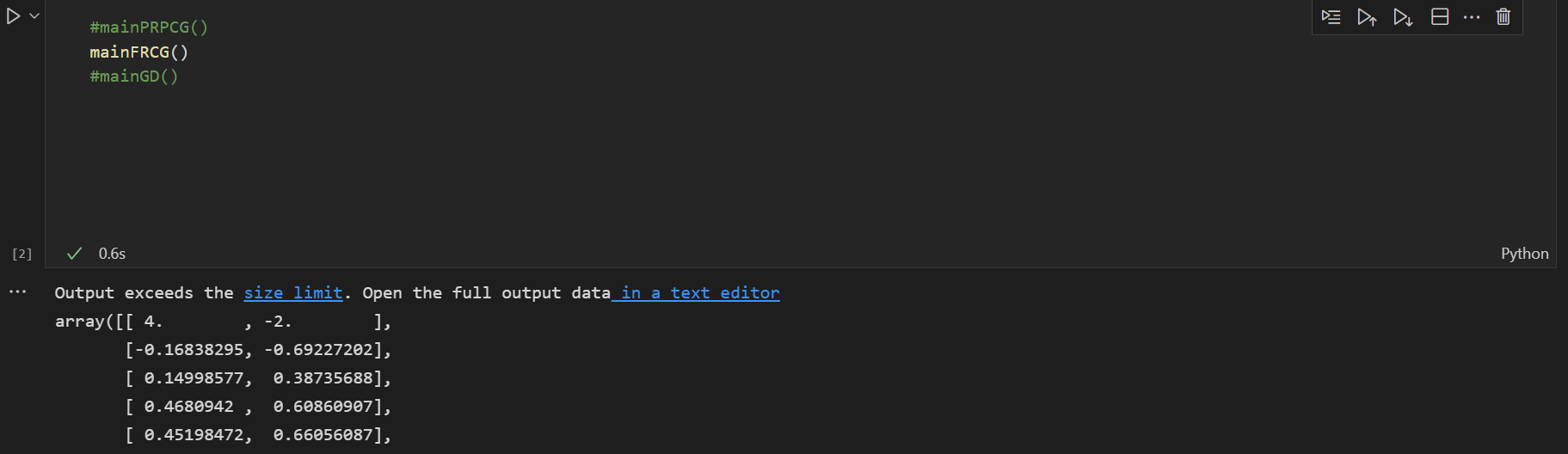
以下是运行结果

最终得到的最小值的坐标为[ 1.00113664, 1.50170496]
运行时间:
2.PRP-CG
换用PRP公式计算只需要将上面求解组合系数部分的代码作少量修改即可,代码为:
def mainPRPCG():
'''
使用CG算法优化,用PRP公式计算组合系数
'''
ls_xy_history = []
xy0 = np.array([4.0, -2.0])
grad_xy = gradTestFun(xy0[0], xy0[1])
d = -1.0*grad_xy
e0 = 1e-6
xy = xy0
while(1):
ls_xy_history.append(xy)
grad_xy = gradTestFun(xy[0], xy[1])
tag_reach = np.abs(grad_xy) < e0
if tag_reach.all():
break
step_length = getStepLengthByNewton(xy, d)
xy_new = xy + step_length*d
grad_xy_new = gradTestFun(xy_new[0], xy_new[1])
b = np.dot(grad_xy_new, (grad_xy_new - grad_xy))/np.dot(grad_xy, grad_xy)
d = b*d - grad_xy_new
xy = xy_new
array_xy_history = np.array(ls_xy_history)
plotResult(array_xy_history)
return array_xy_history
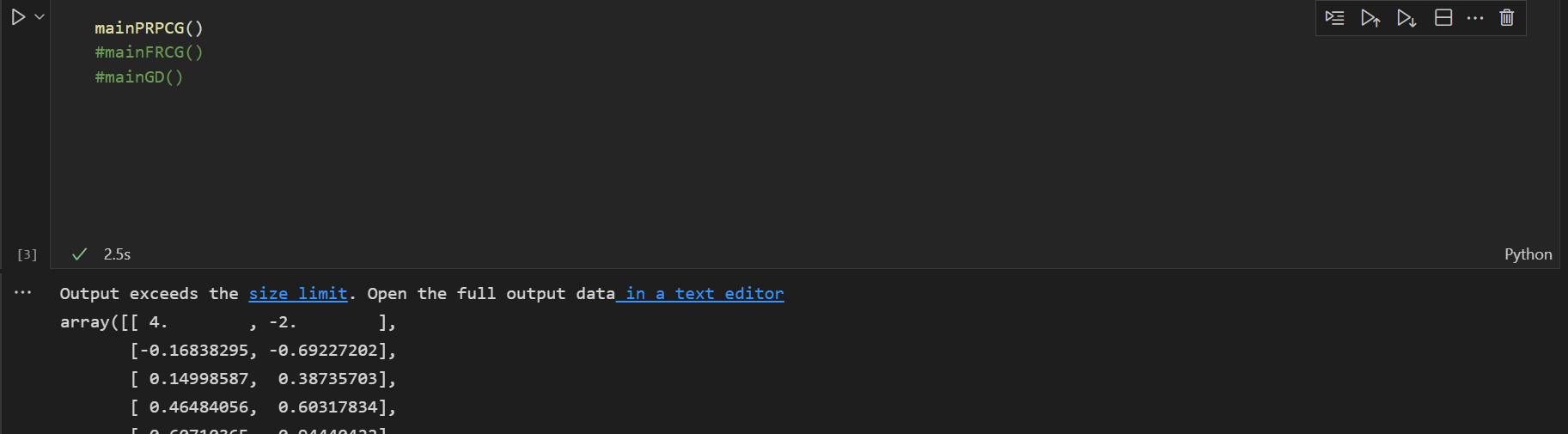
运行结果为:

得到的最小值的坐标是[ 1.00318321, 1.50477481]
运行时间:
3.GD
最后还一起写了利用梯度下降法优化的结果以作对比,以下是实现代码:
def mainGD():
'''
使用梯度下降法计优化函数
'''
ls_xy_history = []
xy0 = np.array([4.0, -2.0])
ls_xy_history.append(xy0)
grad_xy = gradTestFun(xy0[0], xy0[1])
alpha = 1e-3
e0 = 1e-3
xy = xy0
while(1):
tag_reach = np.abs(grad_xy)<e0
if tag_reach.all():
break
xy = xy - alpha*grad_xy
grad_xy = gradTestFun(xy[0], xy[1])
ls_xy_history.append(xy)
array_xy_history = np.array(ls_xy_history)
plotResult(array_xy_history)
return array_xy_history
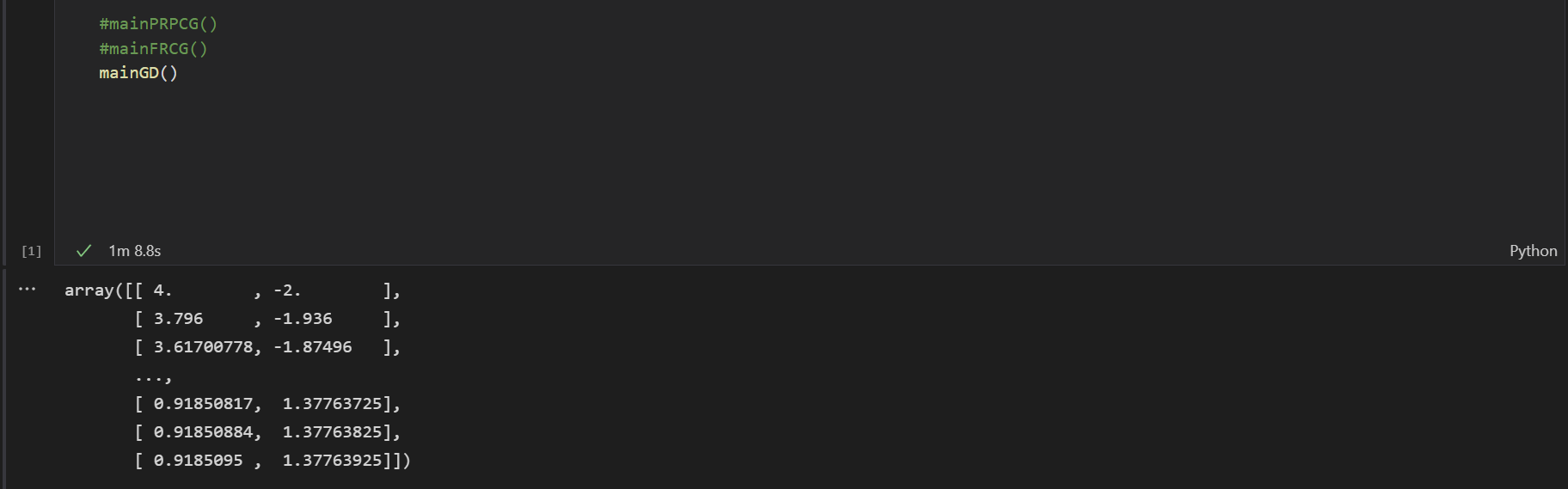
运行结果为:

得到的最小值坐标是[ 0.9185095 , 1.37763925]
运行时间是:
五、总结
对比可以发现,CG算法在计算的速度和准确度上都相较于GD算法有一定的优势。
Original: https://blog.csdn.net/HelloWorldTM/article/details/123647243
Author: 哆啦A梦PLUS
Title: python实现共轭梯度算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/728542/
转载文章受原作者版权保护。转载请注明原作者出处!