

目录
0 前言
目前是被封控的第四天了,只能呆在宿舍不能出去,记得上次这样子还是一年前大四快毕业那时候了……
这几天在宿舍没有什么事干,实验也暂时做不了了,将部分数据处理完后,就把之前的这个内容做一下笔记吧,这也不是什么新的知识了,简单记录一下,方便以后可以查看。
1 为图片数据集打上标签并保存为txt文件
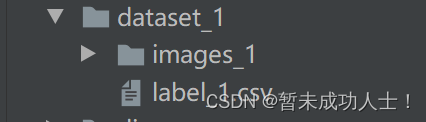
由于这里我做的是用深度学习回归预测,所以我的标签保存在(.csv)文件中,这时候需要将图片和标签一一对应起来,并且要分好文件夹,下面是我分好的文件夹(images保存的是图片,label.csv保存的是对应的标签,这里可以根据个人的数据集更改文件名称):

下面是为图片数据集打上标签并保存为txt文件的代码(文件的路劲需要根据自己文件所在位置进行更改):
import os
import numpy as np
import pandas as pd
label = pd.read_csv('../dataset_1/label_1.csv')
label = np.array(label)
label = label.tolist()
target = ''
for i in range(len(label)):
for j in range(len(label[i])):
target += str(label[i][j]) + ' '
print(target)
target = ''
def generate(dir):
files = os.listdir(dir) #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
# files.sort() #对文件或文件夹进行排序
files.sort(key=lambda x: int(x.replace("frame", "").split('.')[0]))
print('****************')
print('input :', dir)
print('start...')
target = ''
i = 0
listText = open('H:/代码练习/Deeplearning/data_txt_path/all_data_list_1.txt', 'a+') #创建并打开一个txt文件,a+表示打开一个文件并追加内容
listText.truncate(0)#清空txt文件里的内容
for file in files: #遍历文件夹中的文件
fileType = os.path.split(file) #os.path.split()返回文件的路径和文件名,【0】为路径,【1】为文件名
if fileType[1] == '.txt': #若文件名的后缀为txt,则继续遍历循环,否则退出循环
continue
name = outer_path + folder + '/' +file #name 为文件路径和文件名+空格+label+换行
for j in range(len(label[i])):
target += str(label[i][j]) + ' '
name = name + ' ' + target + '\n'
# print(name)
# listText.write(name) # 在创建的txt文件中写入name
target = ''
i += 1
listText.write(name) #在创建的txt文件中写入name
listText.close() #关闭txt文件
print('down!')
print('****************')
outer_path = 'H:/代码练习/Deeplearning/dataset_1/' # 这里是你的图片路径
if __name__ == '__main__': #主函数
folderlist = os.listdir(outer_path)# 列举文件夹
for folder in folderlist: #遍历文件夹中的文件夹(若engagement文件夹中存在txt或py文件,则后面会报错)
generate(os.path.join(outer_path, folder))#调用generate函数,函数中的参数为:(图片路径+文件夹名,标签号)
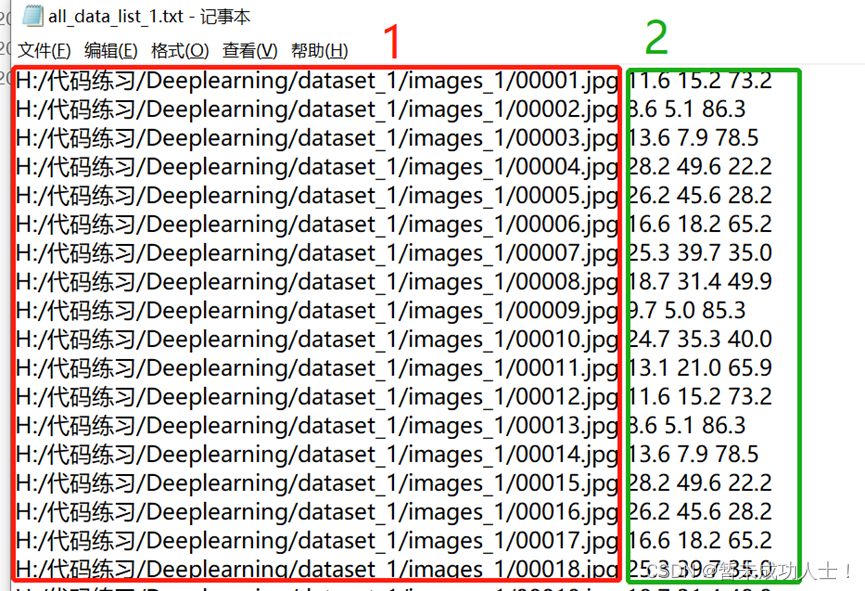
代码运行后结果如下图:序号1为图片的路径,序号2为对应的标签,因为我一张图片对应3个标签,所以有后面3个值。
2 将txt文件中的图片标签数据集随机划分为训练集和测试集
完成第一个步骤后,需要将txt文件中的图片标签数据集随机划分为训练集和测试集,划分后生成训练集和测试集两个txt文件,可以根据自己的需求,更改训练集和测试集的比例。下面为划分数据集的代码(文件的路劲需要根据自己文件所在位置进行更改):
import os
import random
划分比例,训练集 : 验证集 = 8 : 2
split_rate = 0.2
class SplitFiles():
"""按行分割文件"""
def __init__(self, file_name):
"""初始化要分割的源文件名和分割后的文件行数"""
self.file_name = file_name
# def get_random(self):
# """生成随机数组,随机划分 (0,190001)txt标签行数, 7600测试集标签行数"""
# random_num = random.sample(range(0, 19001), 108)
#
# return random_num
def split_file(self):
if self.file_name and os.path.exists(self.file_name):
try:
with open(self.file_name) as f: # 使用with读文件
# temp_count = 1
file = f.readlines()
count = len(file)
eval_index = random.sample(file, k=int(count * split_rate)) # 从images列表中随机抽取 k 个图像名称
for index,image_path in enumerate(file):
if image_path in eval_index:
self.write_file('test', image_path)
else:
self.write_file('train', image_path)
# temp_count += 1
except IOError as err:
print(err)
else:
print("%s is not a validate file" % self.file_name)
def get_part_file_name(self, part_name):
""""获取分割后的文件名称:在源文件相同目录下建立临时文件夹temp_part_file,然后将分割后的文件放到该路径下"""
temp_path = os.path.dirname(self.file_name) # 获取文件的路径(不含文件名)
file_folder = temp_path
if not os.path.exists(file_folder): # 如果临时目录不存在则创建
os.makedirs(file_folder)
part_file_name = file_folder + "/" + str(part_name) + "_list_1.txt"
return part_file_name
def write_file(self, part_num, line):
"""将按行分割后的内容写入相应的分割文件中"""
part_file_name = self.get_part_file_name(part_num)
try:
with open(part_file_name, "a") as part_file:
part_file.writelines(line)
except IOError as err:
print(err)
if __name__ == "__main__":
file = SplitFiles(r'H:/代码练习/Deeplearning/data_txt_path/all_data_list_1.txt')
file.split_file()
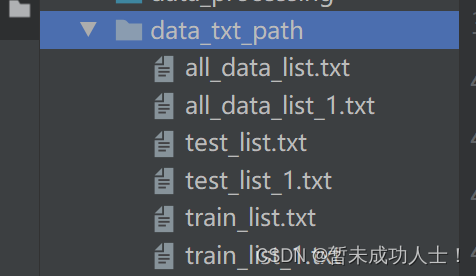
我这里将总的数据文件和划分好的数据集存在一个文件夹里,方便后面管理(本来是只有3个txt文件的,我弄了两个数据集,所以就有了6个文件)。
3 加载txt文件中的图片标签数据集
在完成步骤1和2后,最后是对数据进行加载,下面为加载数据的代码,后面读取数据调用这个类函数就可以:
import os
import numpy as np
import torch
from torchvision import transforms
from PIL import Image
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
我们读取图片的根目录, 在根目录下有所有图片的txt文件, 拿到txt文件后, 先读取txt文件, 之后遍历txt文件中的每一行, 首先去除掉尾部的换行符, 在以空格切分,前半部分是图片名称, 后半部分是图片标签, 当图片名称和根目录结合,就得到了我们的图片路径
class MyDataset(Dataset):
def __init__(self, img_path, transform=None):
super(MyDataset, self).__init__()
self.root = img_path
# self.txt_root = self.root + 'all_list.txt'
f = open(self.root, 'r')
data = f.readlines()
imgs = []
labels = []
# label_1,label_2,label_3 = [],[],[]
for line in data:
line = line.rstrip()
word = line.split()
imgs.append(os.path.join(self.root, word[1],word[2],word[3],word[0]))
# labels.append([float(word[1]),float(word[2]),float(word[3])])
labels.append([word[1],word[2],word[3]])
# label_1,label_2,label_3 = word[1],word[2],word[3]
# labels.append([[label_1],[label_2],[label_3]])
self.img = imgs
self.label = labels
self.transform = transform
# print(self.img)
# print(self.label)
def __len__(self):
return len(self.label)
return len(self.img)
def __getitem__(self, item):
img = self.img[item]
label = self.label[item]
# print(img)
img = Image.open(img).convert('RGB')
# 此时img是PIL.Image类型 label是str类型
if transforms is not None:
img = self.transform(img)
# print(img.max())
label = np.array(label).astype(np.float32)
label = torch.from_numpy(label)
return img, label
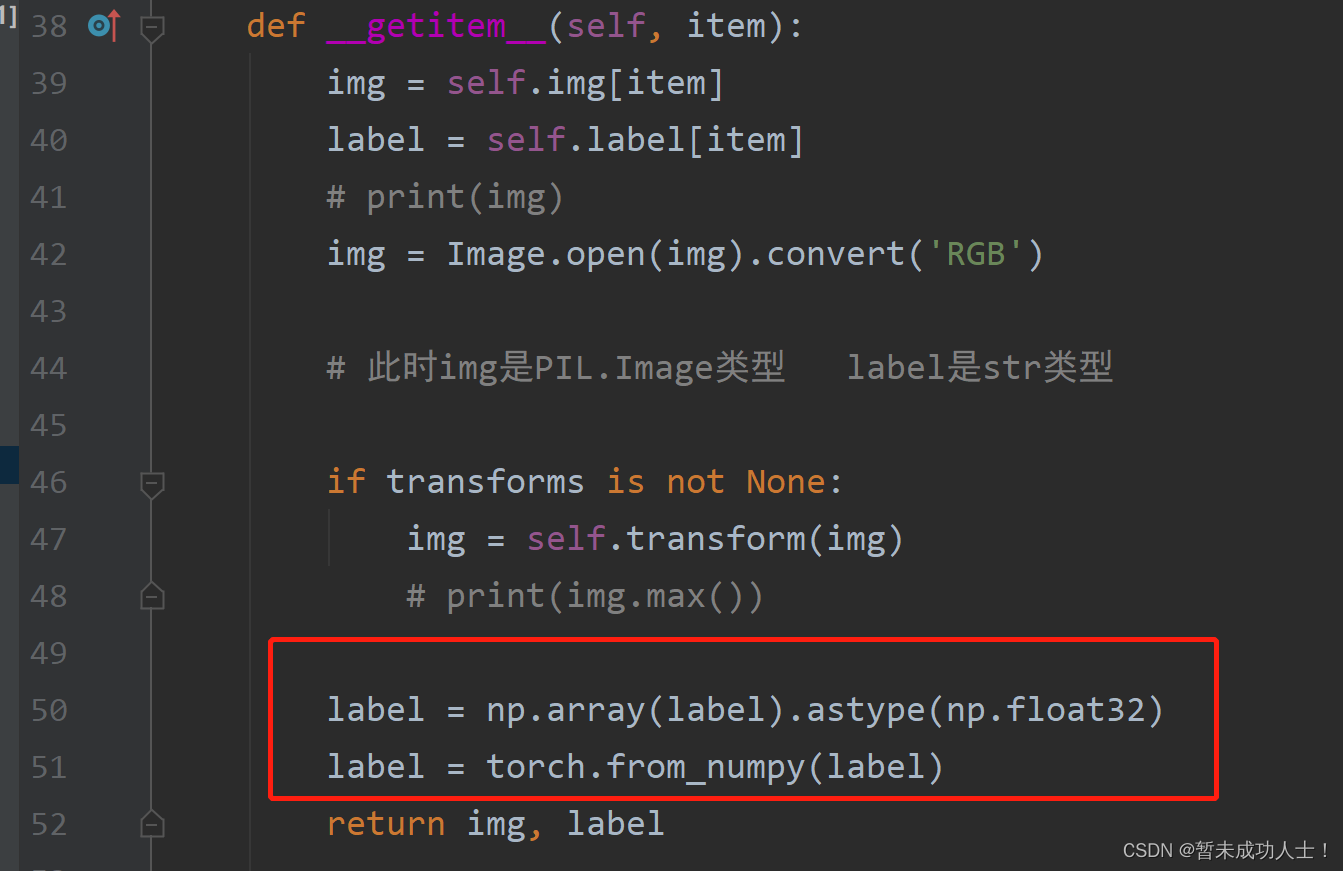
注意:上面/下图代码是我同时加载了三个标签,因为一张图片我是同时对应了三个标签,假如是一个图片对应一个标签,可在以下图片的函数中进行更改:

因为我的标签是浮点数,所以我在这里将其变为浮点数类型,假如是整形,可以在上面代码下图位置更改。
在执行完 步骤1的代码文件后,将图片数据集打上标签并保存为txt文件;在执行 步骤2的代码文件将txt文件中的图片标签数据集随机划分为训练集和测试集;最后编写 步骤3加载txt文件中的图片标签数据集代码,就可加载自己的数据集 。下面是深度学习训练时,调用上面加载数据的类实现对数据的加载,也可根据自己的代码进行编写,可以参考一下下面的例子:
root_train = r'H:/代码练习/Deeplearning/data_txt_path/train_list_1.txt'
root_test = r'H:/代码练习/Deeplearning/data_txt_path/test_list_1.txt'
#将图像的像素值归一化到[-1,1]之间
normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_transform = transforms.Compose([
transforms.Resize((224,224)),
# transforms.RandomVerticalFlip(),
transforms.ToTensor(),
normalize])
val_transform = transforms.Compose([
transforms.Resize((224,224)),
# transforms.RandomVerticalFlip(),
transforms.ToTensor(),
normalize])
train_dataset = MyDataset(root_train,transform=train_transform)
val_dataset = MyDataset(root_test,transform=val_transform)
train_dataloader = DataLoader(dataset=train_dataset,batch_size=16,shuffle=True)
val_dataloader = DataLoader(dataset=val_dataset,batch_size=16,shuffle=True)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
for batch, (x, y) in enumerate(data_loader):
image, y= x.to(device), y.to(device)
参考来源:制作数据集(二)–为图片数据集打上标签并保存为txt文件_困坤的小菜鼠的博客-CSDN博客
python 划分数据集文件(txt标签文件按比例随机切分)_努力学习DePeng的博客-CSDN博客_python按比例随机切分数据
pytorch加载自己的图片数据集的两种方法__-周-_的博客-CSDN博客_pytorch读取图片数据集
Original: https://blog.csdn.net/weixin_42795788/article/details/128049574
Author: 暂未成功人士!
Title: 深度学习制作自己的数据集—为数据集打上标签保存为txt文件,并进行划分和加载数据集
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/728004/
转载文章受原作者版权保护。转载请注明原作者出处!