



@作者 : SYFStrive
@博客首页 : HomePage;
🥧 上一篇续文传送门
📌: 个人社区(欢迎大佬们加入) 👉:社区链接🔗
📌: 如果觉得文章对你有帮助可以点点关注 👉:专栏连接🔗
🥧: 感谢支持,学习累了可以先看小段由小胖给大家带来的街舞😀
🔗: 阅读文章


目录
; 简介
- Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据 (例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
- Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。
- 提示:Twisted 是一个基于事件驱动的网络引擎框架,同样采用 Python 实现。
📦Scrapy使用前准备
-
文档如👇
-
官网文档:链接
-
C语言中文文档:链接
-
安装
-
安装语法:python -m pip install Scrapy
- 报错:使用pip install -i https://pypi.tuna.tsinghua.edu.cn/simple –trusted-host pypi.tuna.tsinghua.edu.cn 加名称
Yield的使用
- 带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代
- yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行
- 简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始
Python爬虫之Scrapy框架之🔔🔔爬取数据
案例使用的内容
涉及 单管道、多管道
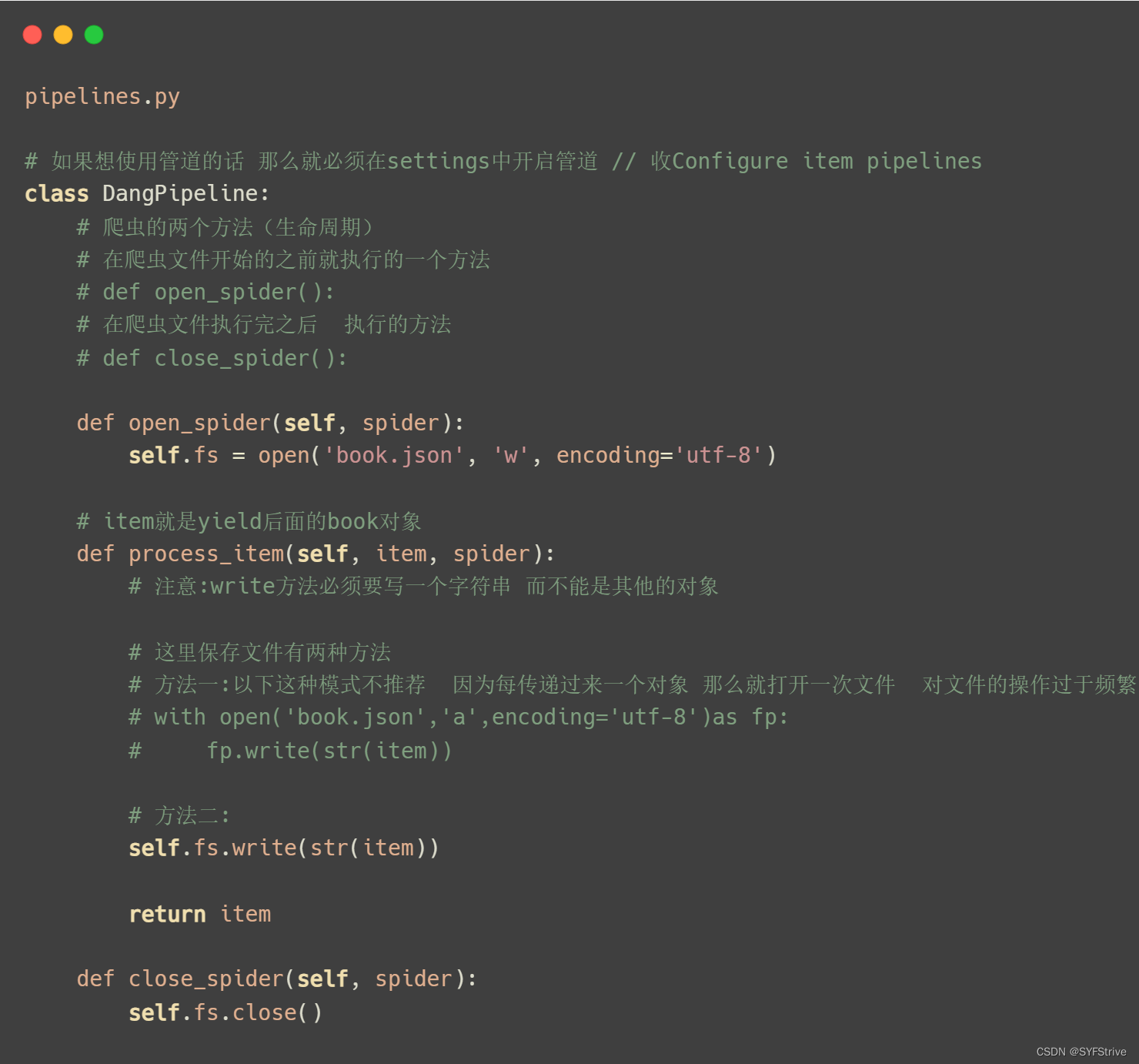
单管道
📰代码演示:
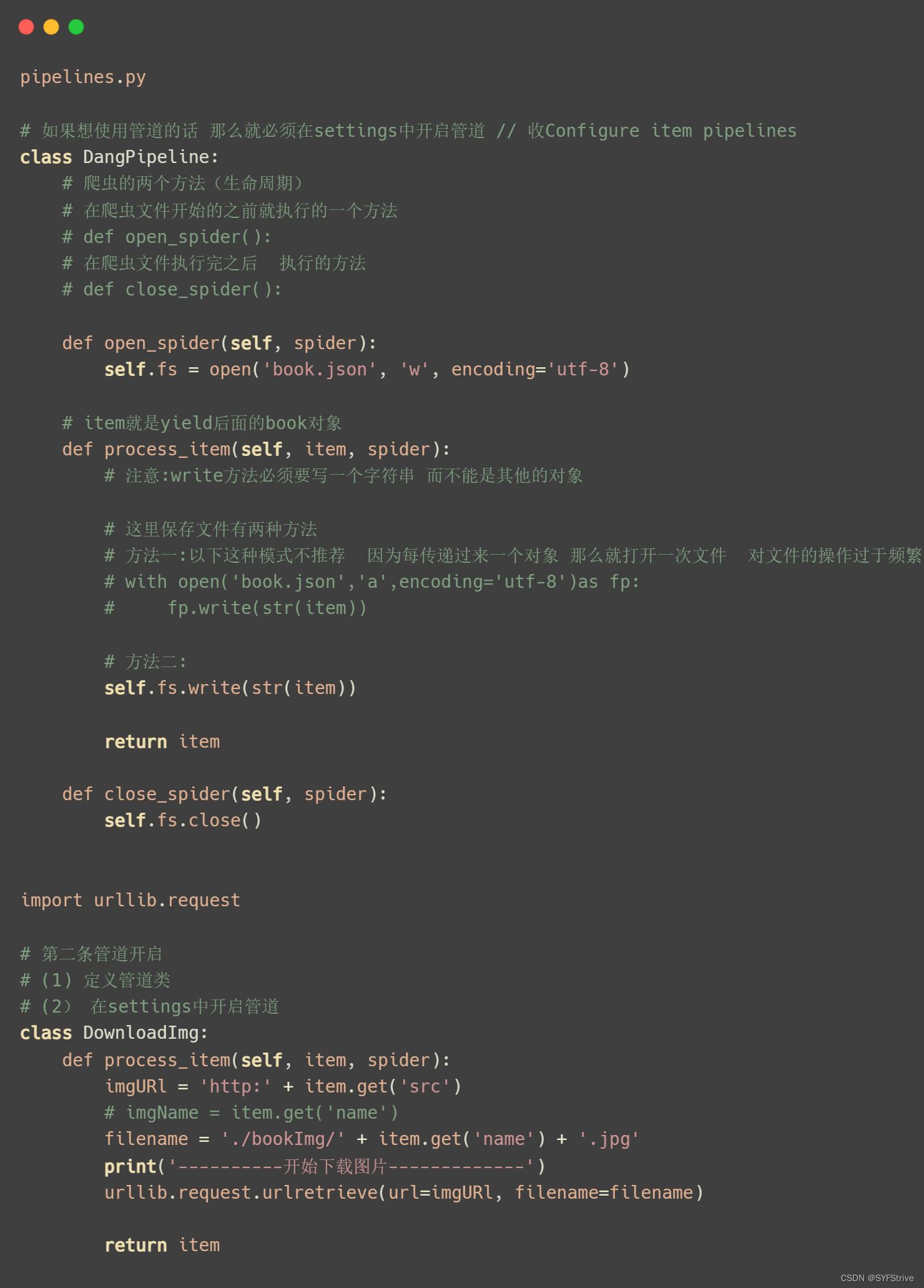
; 多管道(单独使用一个管道下载图片……)
📰代码演示:
如下图(下载成功🆗):
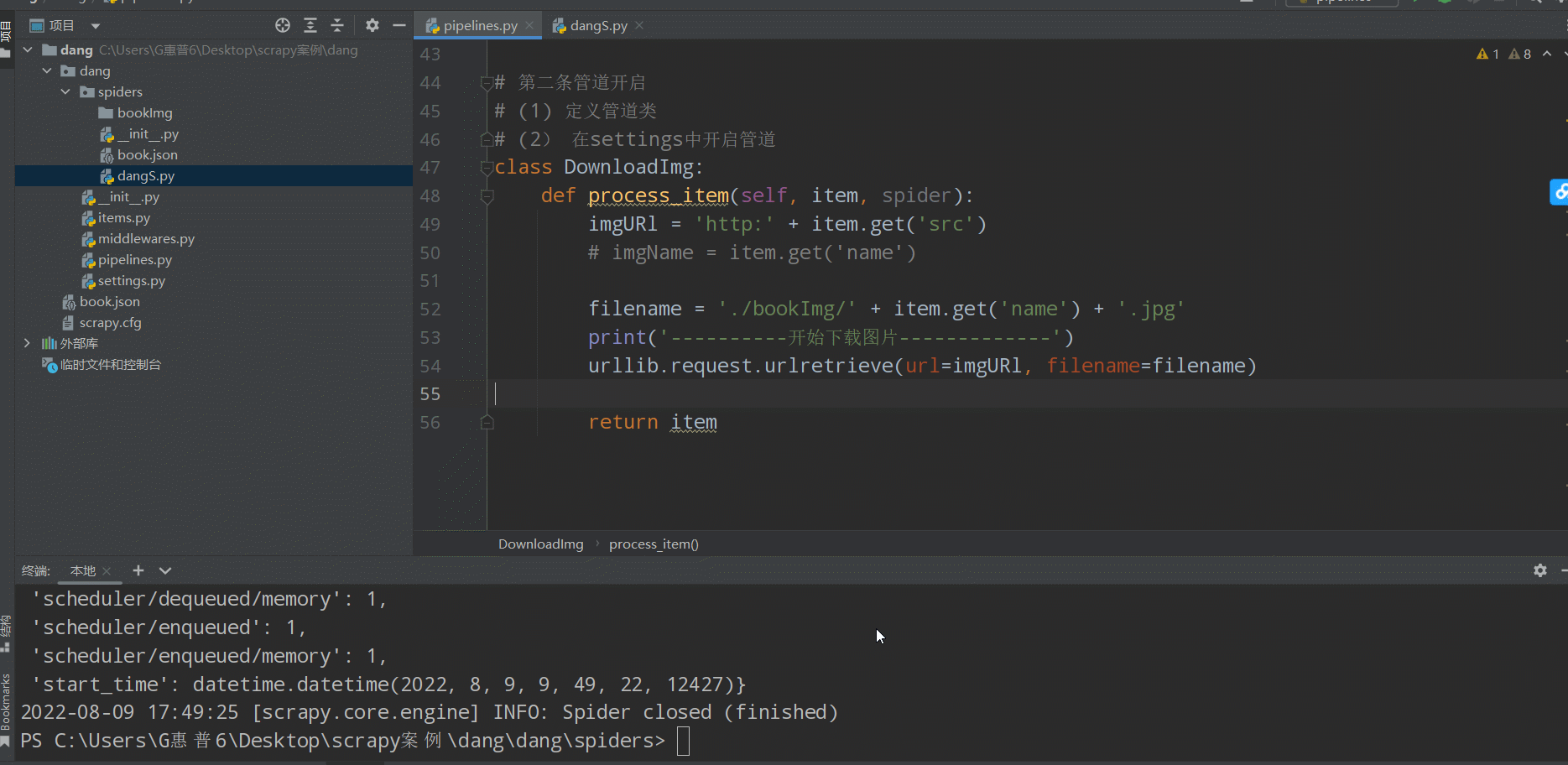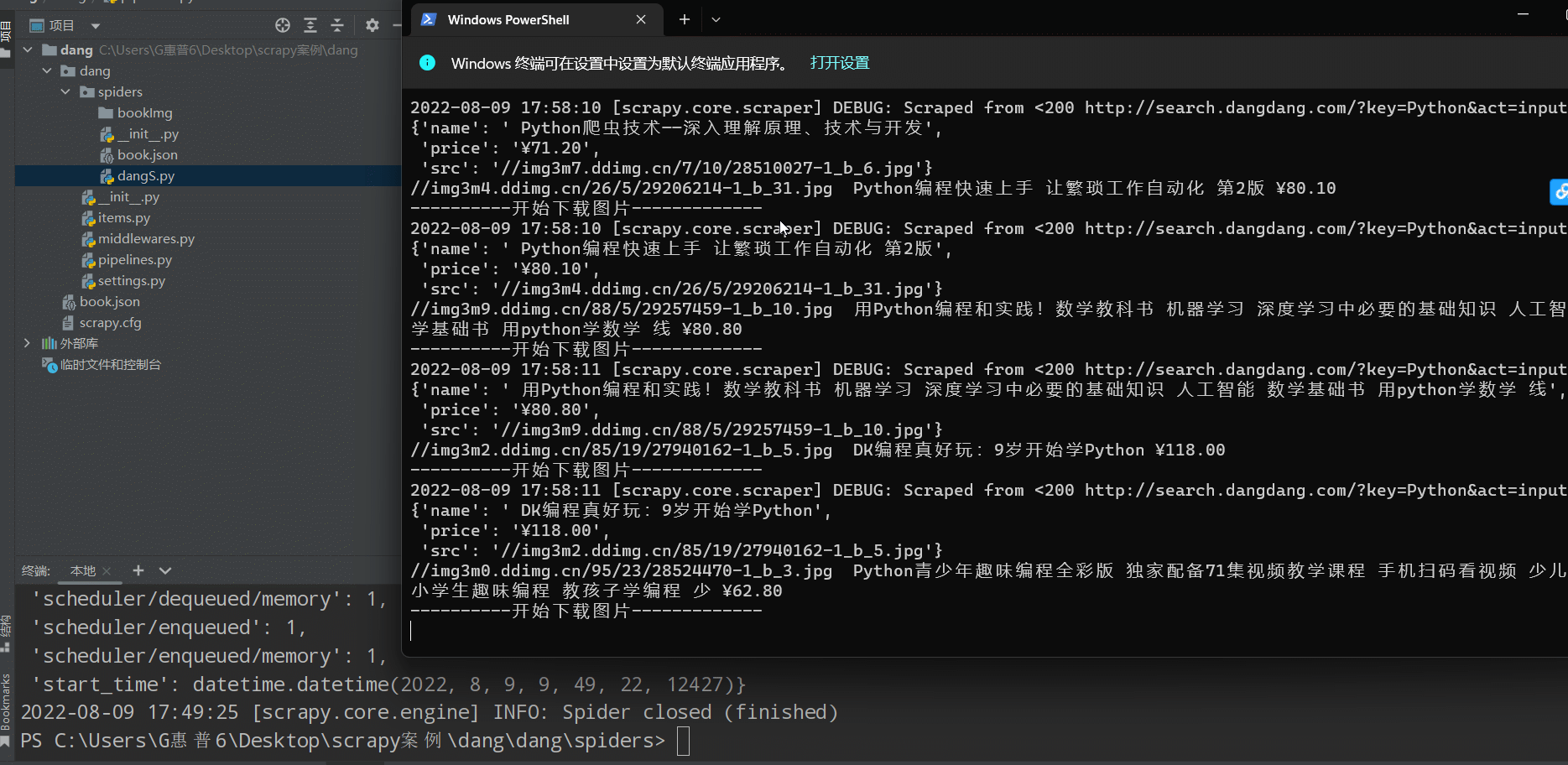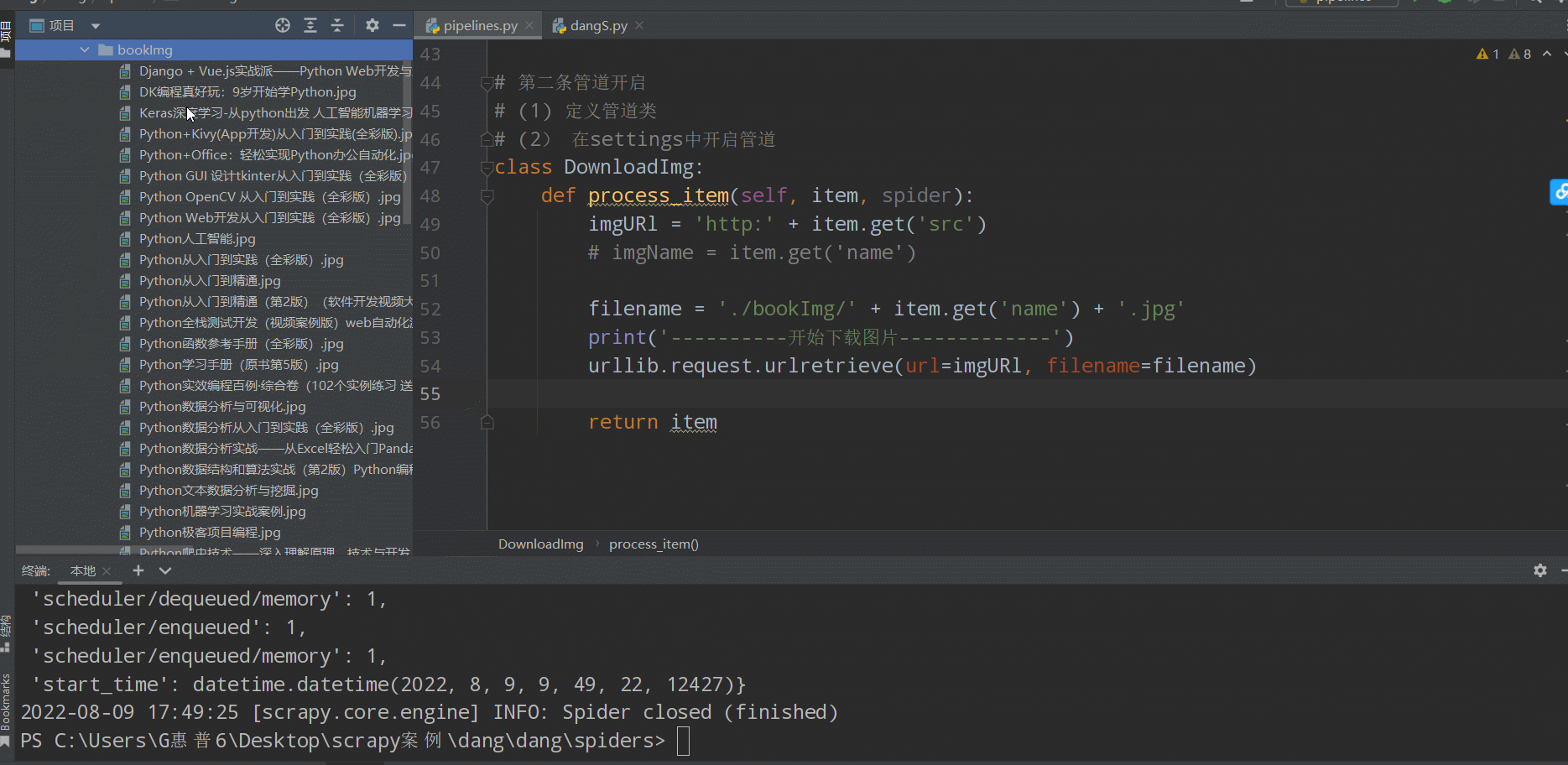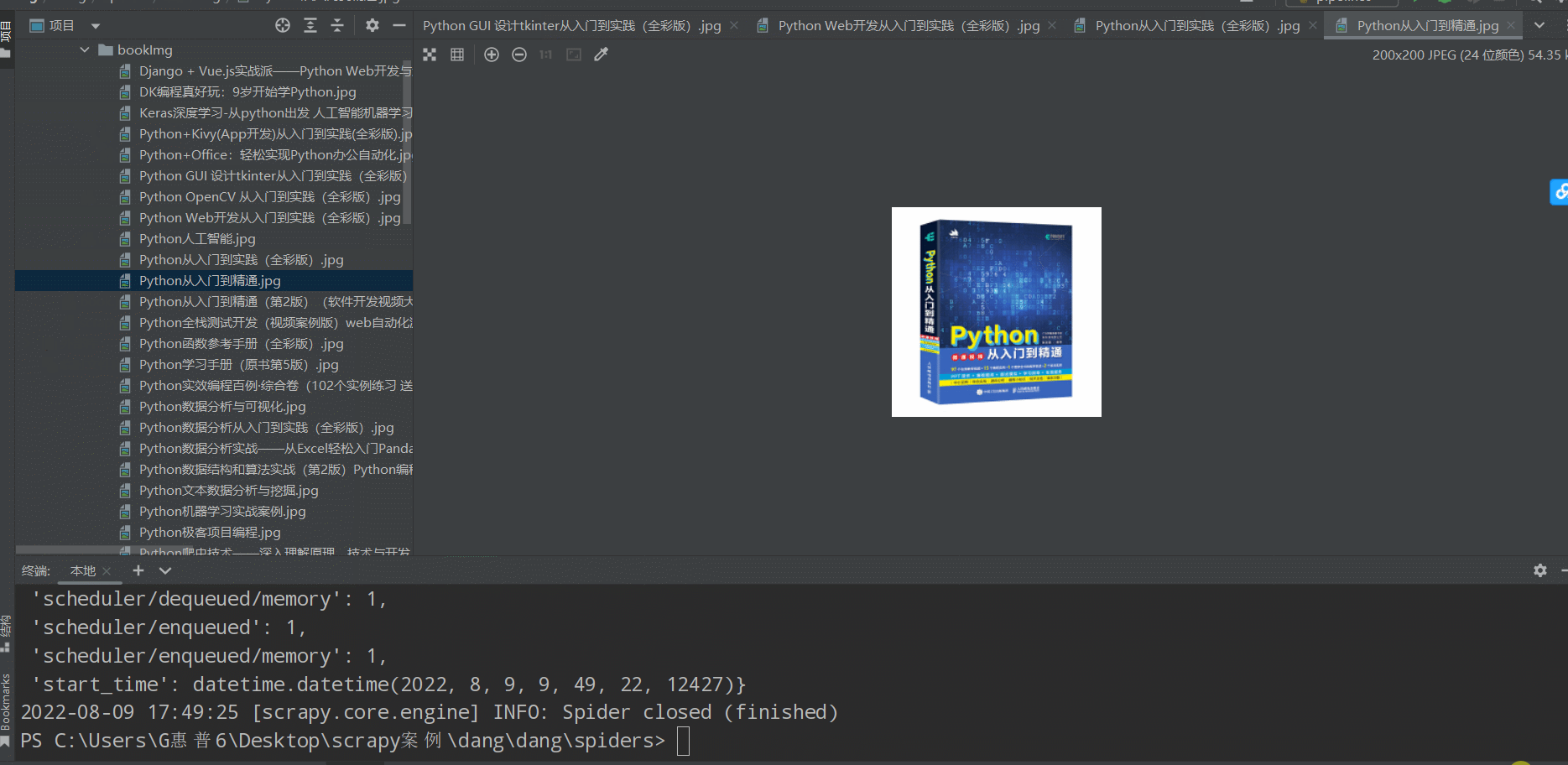
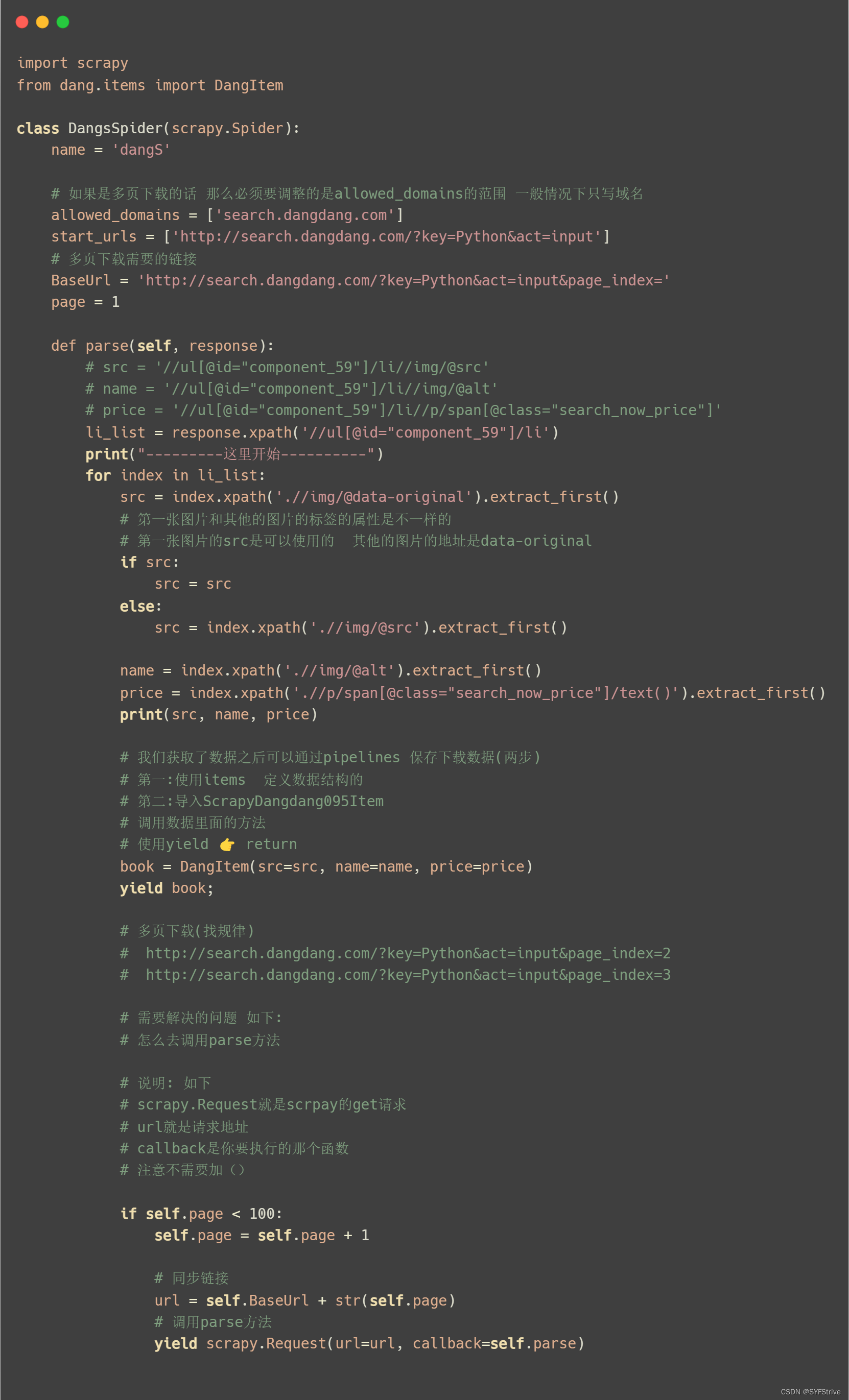
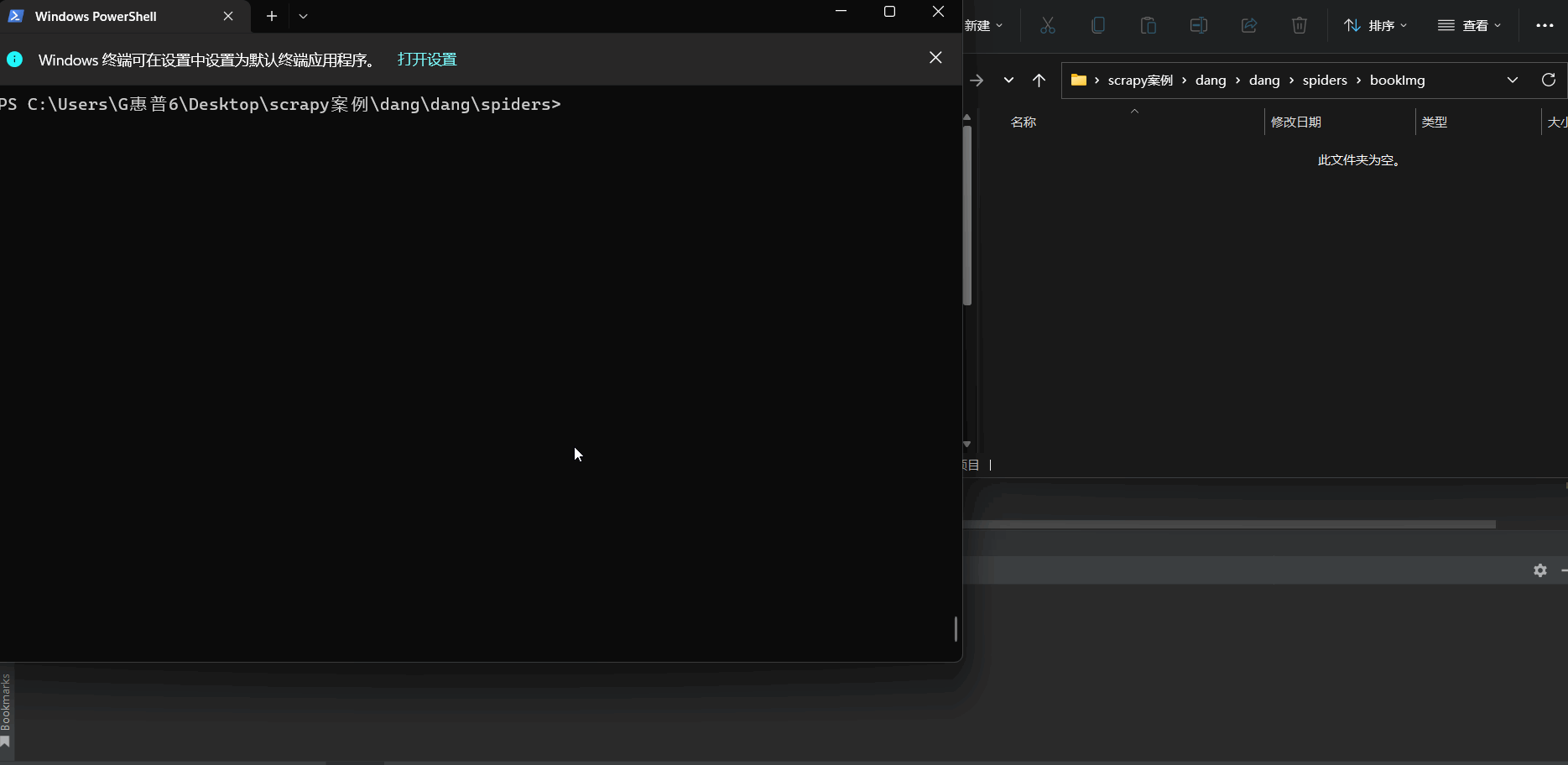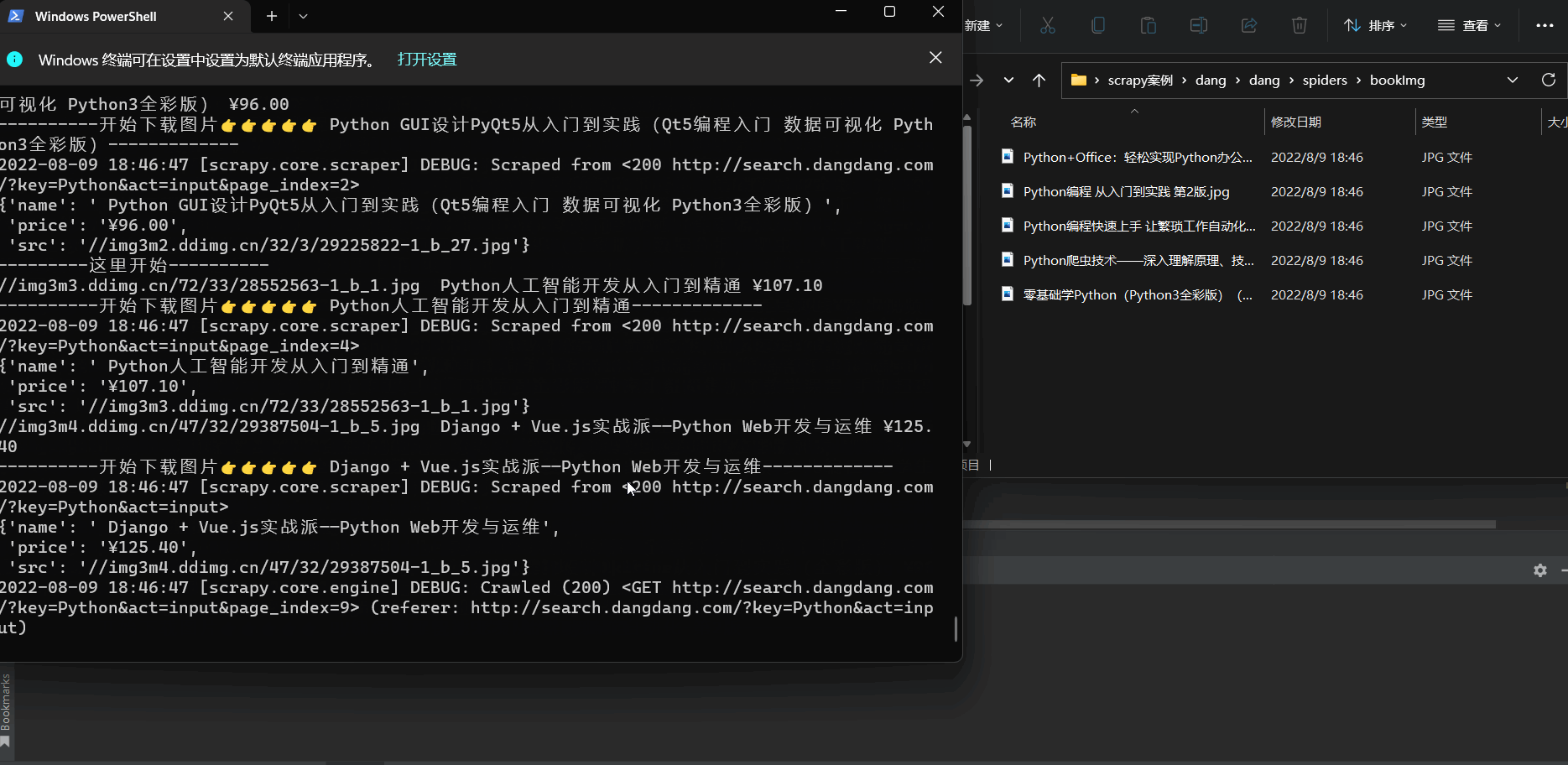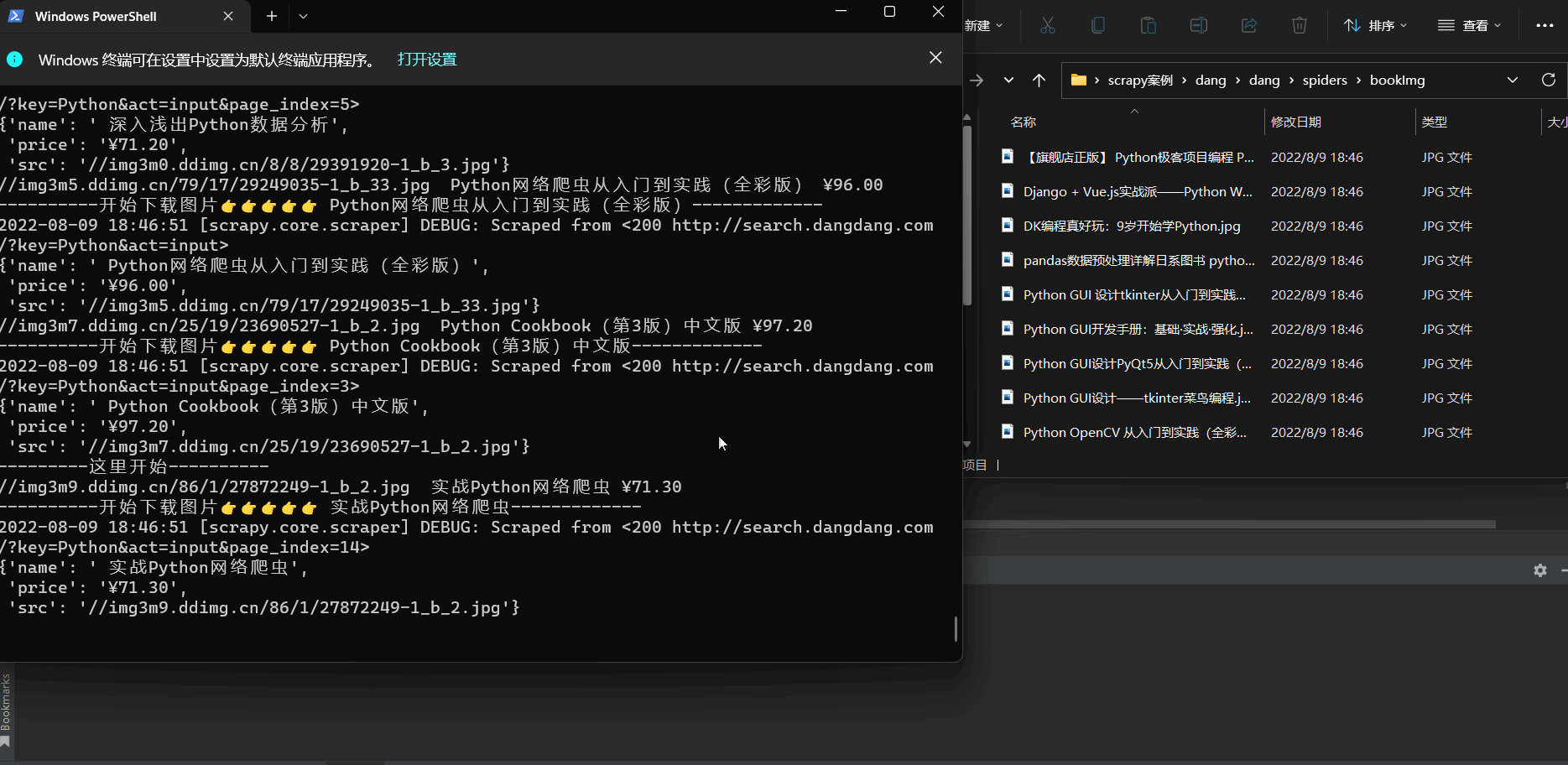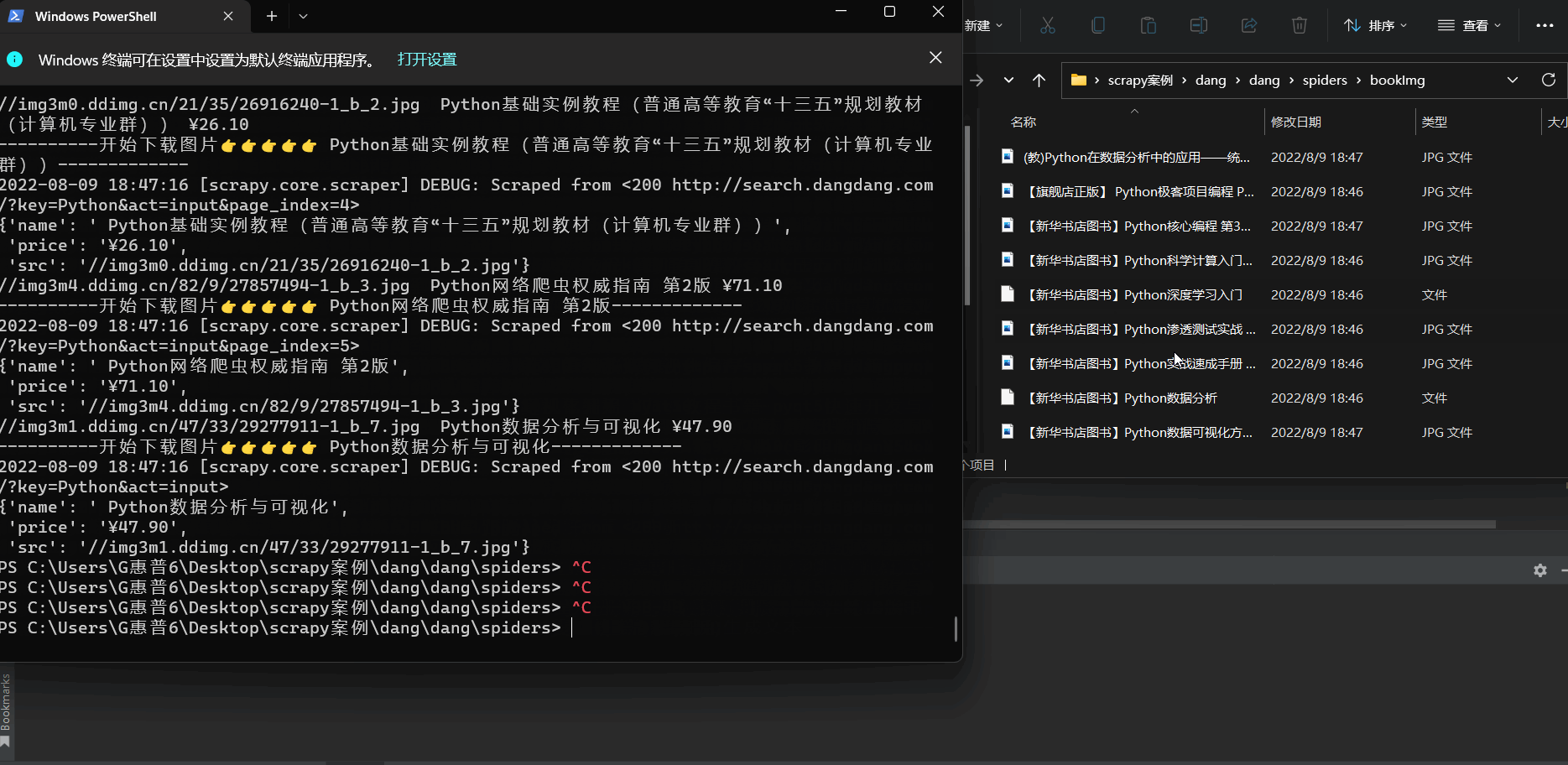
实现多页面下载 (爬取100页内容)
📰代码演示:
如下图(下载成功🆗):
; 案例总结
- 两个生命函数
# 在爬虫文件开始的之前就执行的一个方法
# def open_spider():
# 在爬虫文件执行完之后 执行的方法
# def close_spider():
- 简单步骤:获取数据后 👉 使用items 定义数据结构的 👉 导入items(传递数据) 👉 使用Yield返回 👉 通过pipelines管道下载数据(使用前要开启管道(item就是yield后面的book对象))
- 添加管道:定义管道类 👉 在settings中开启管道
- 注意:
1、如果是多页下载的话 那么必须要调整的是allowed_domains的范围 一般情况下只写域名
2、write方法必须要写一个字符串 而不能是其他的对象
3、通过该案例检测的一点就是下载的图片目录文件是spiders下的理解如:’./bookImg/’ + item.get(‘name’) + ‘.jpg’
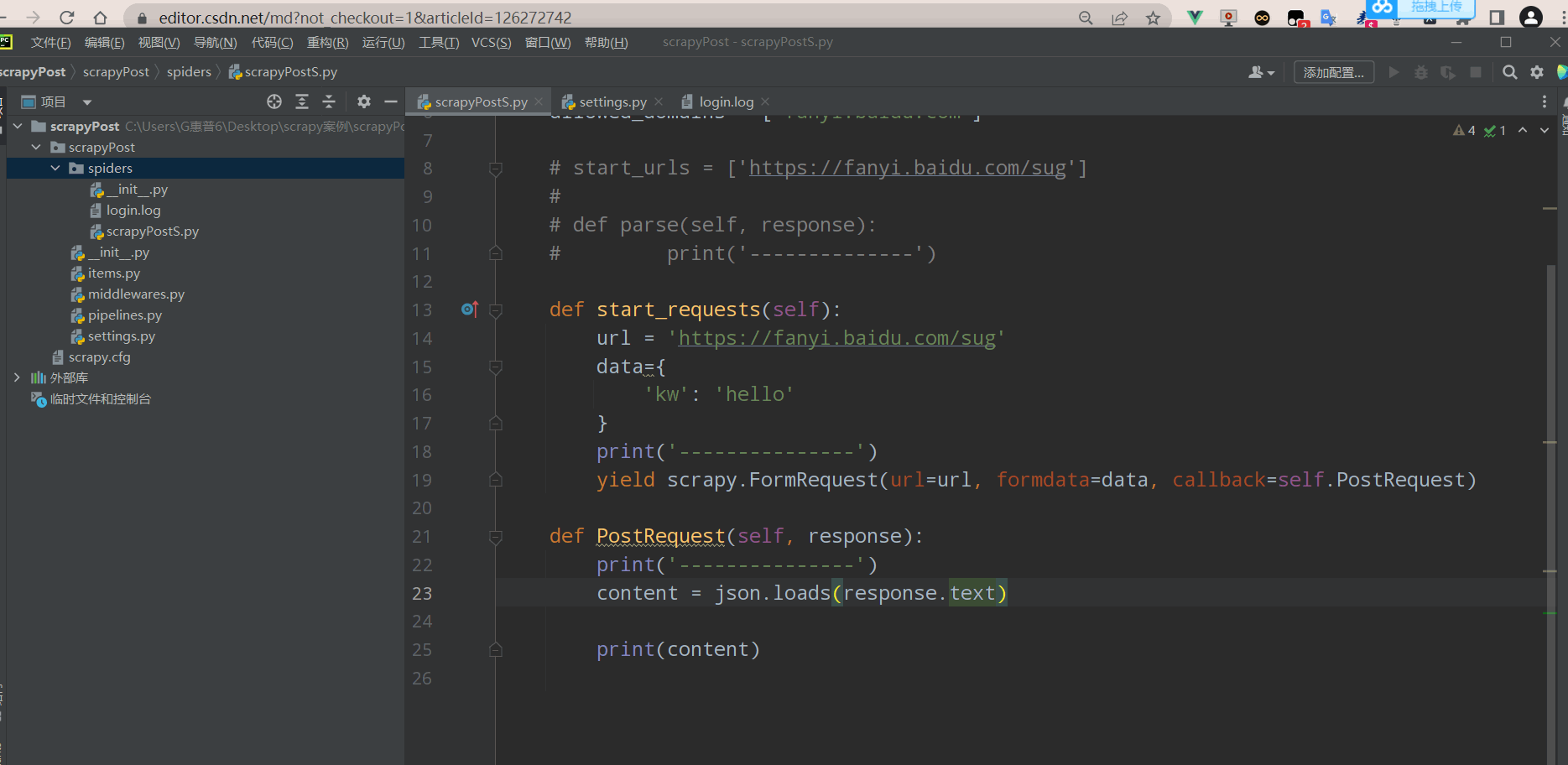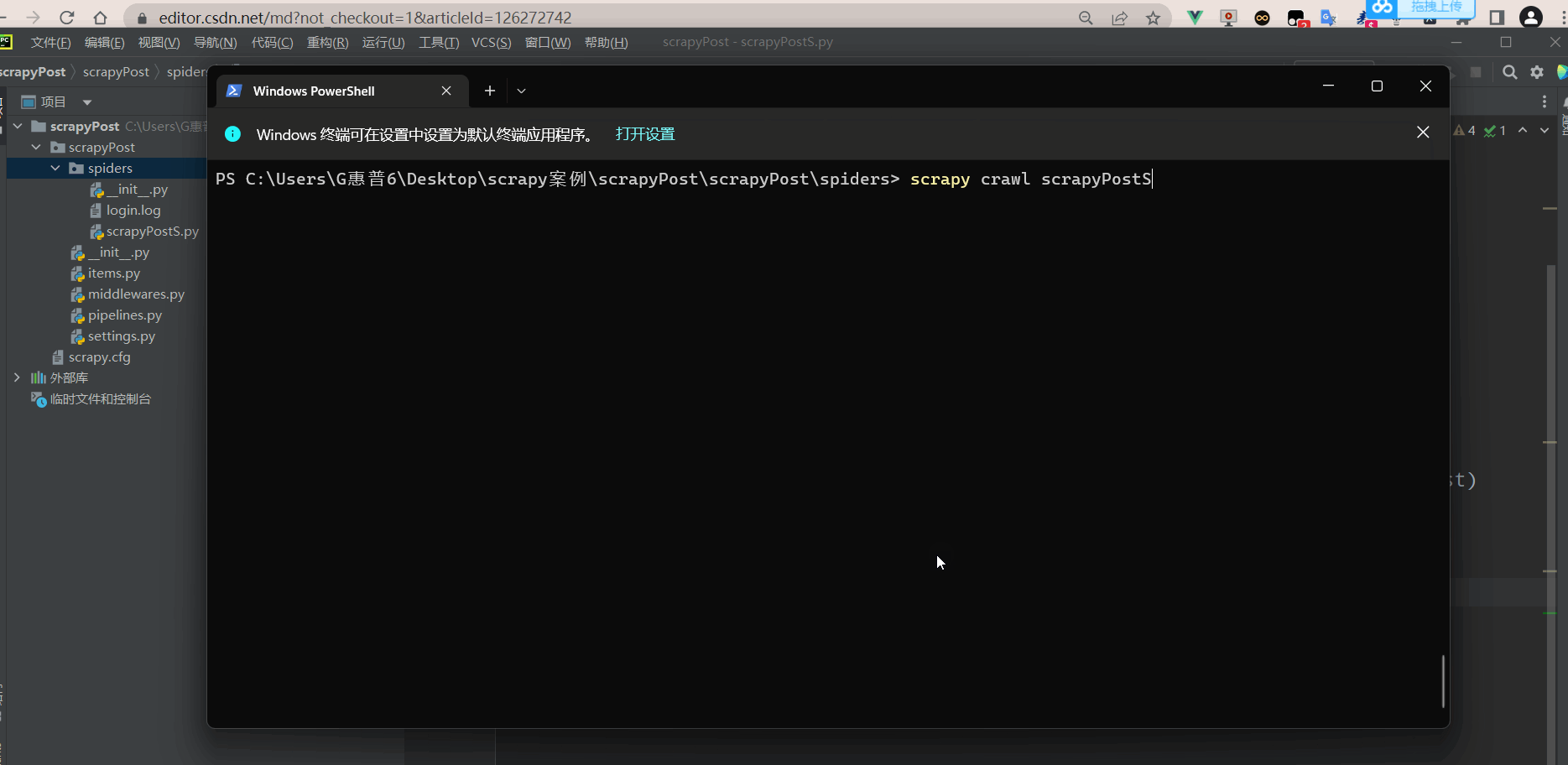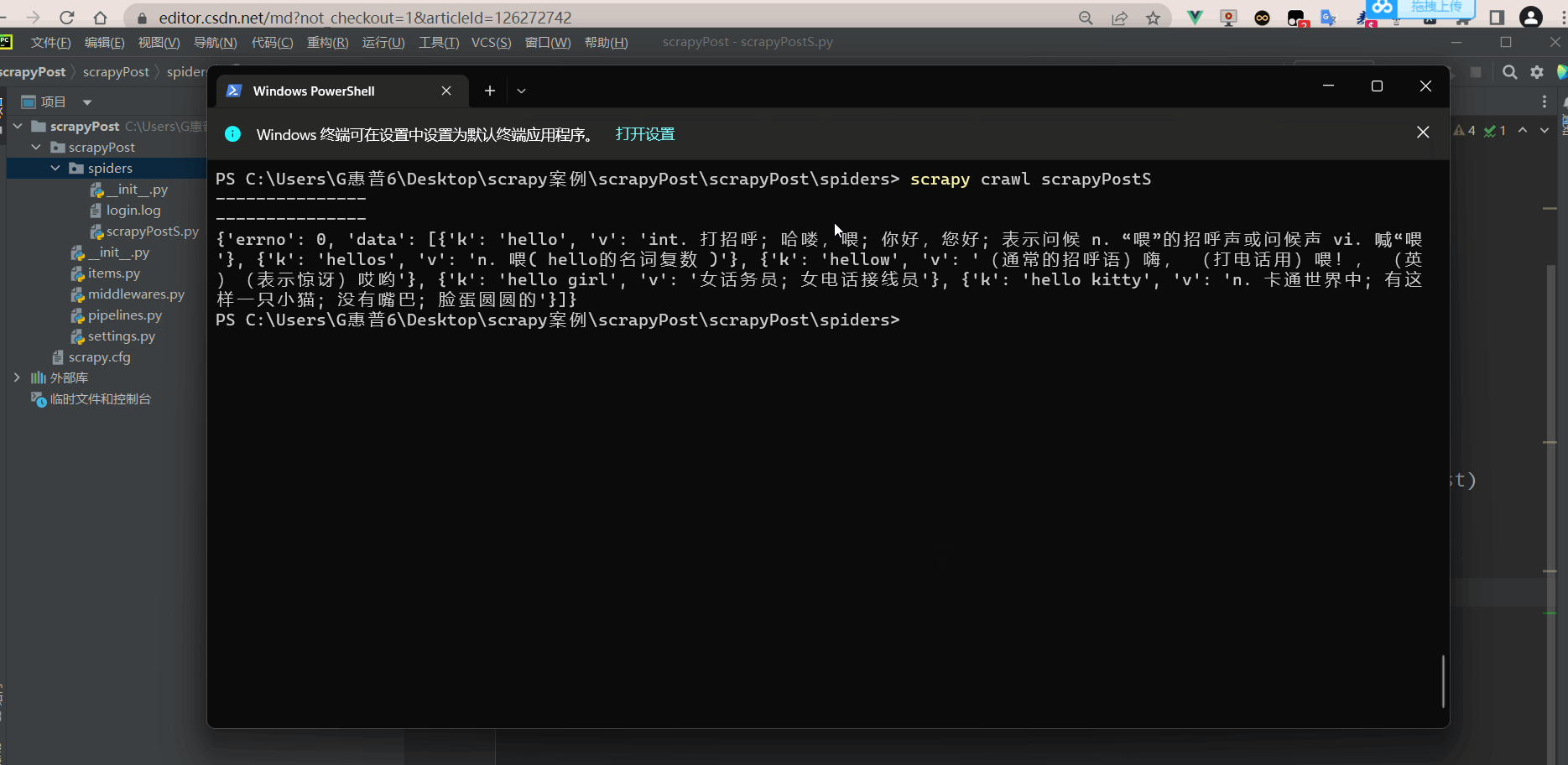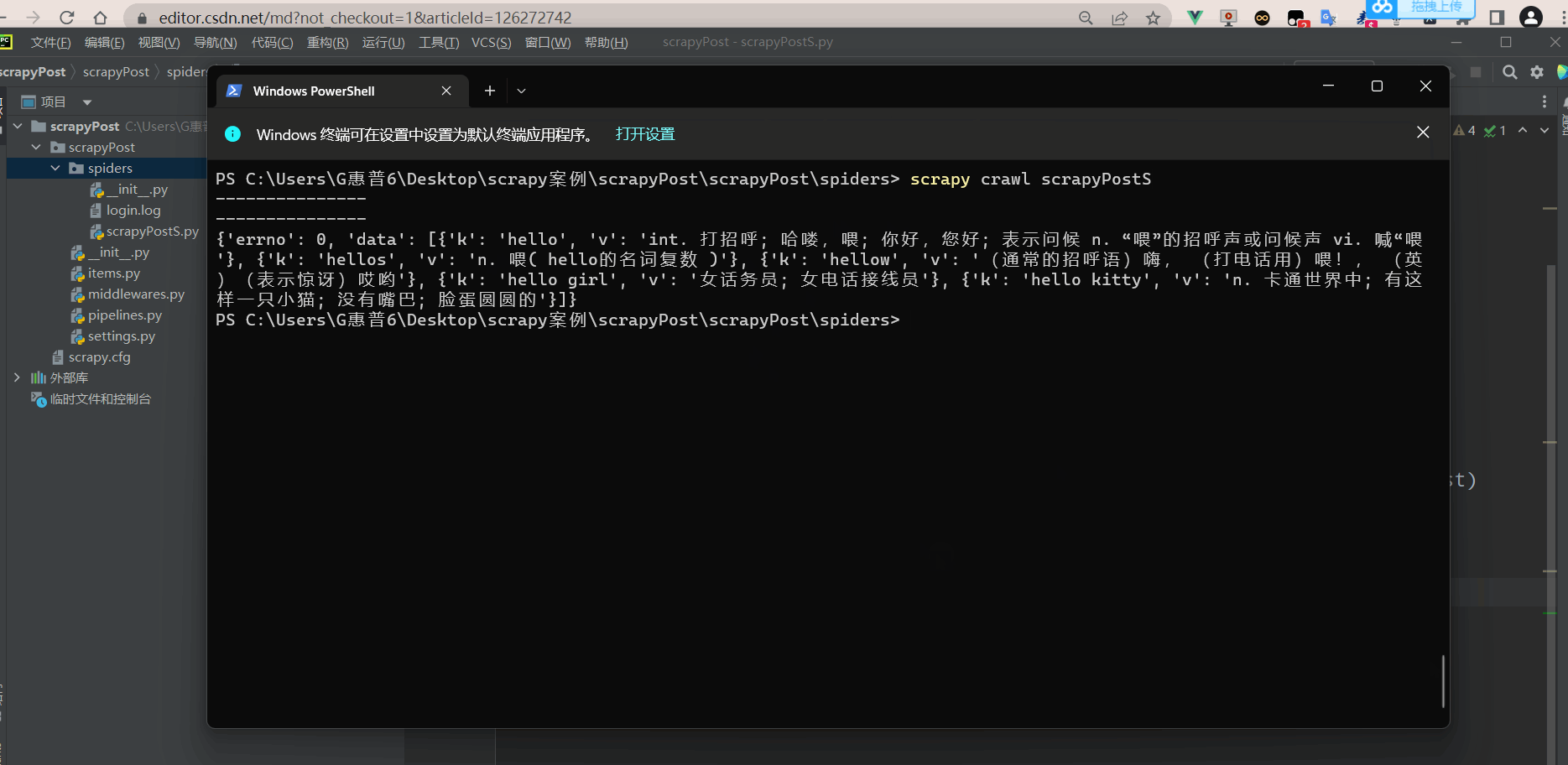
Post请求
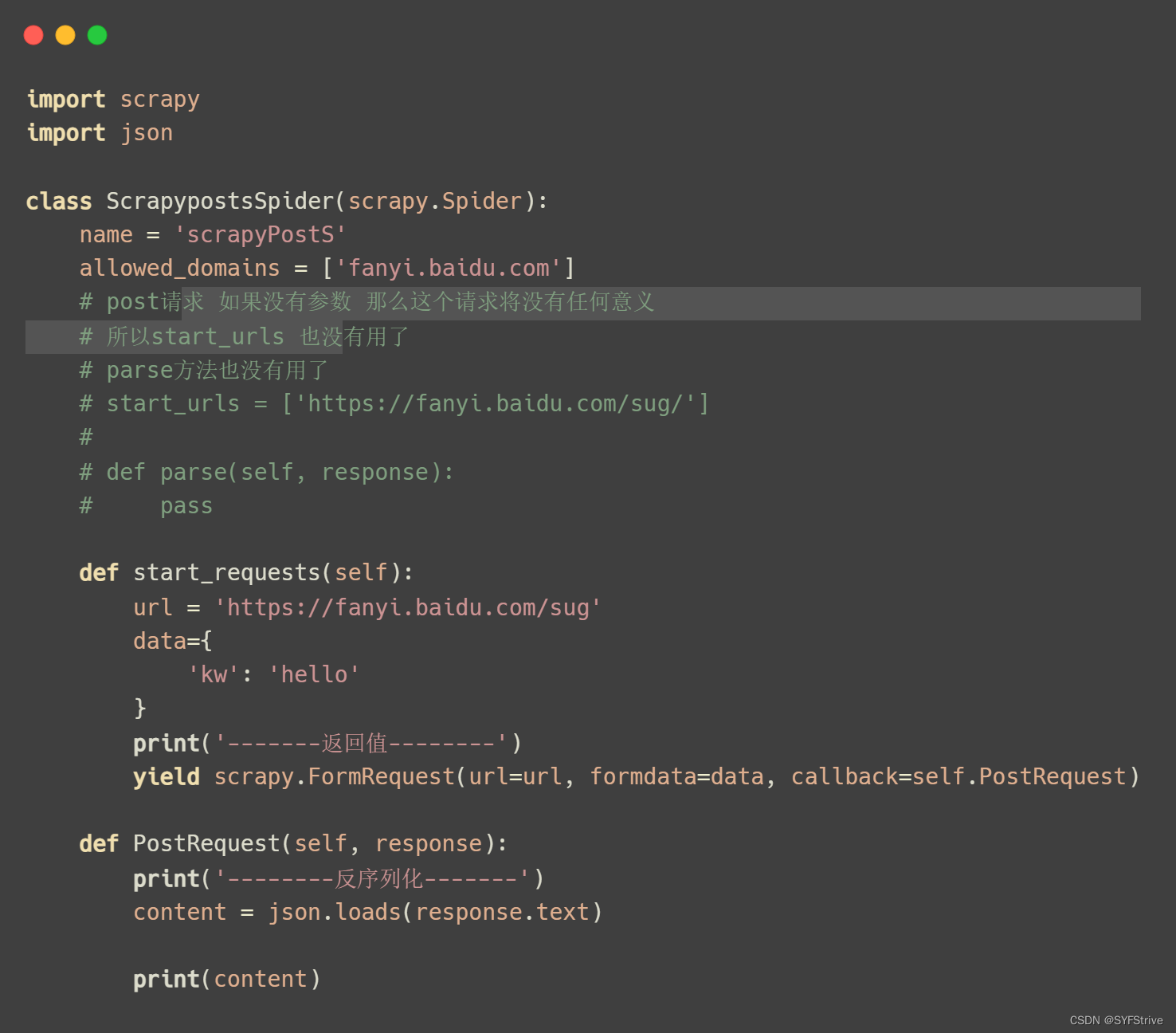
效果如下:
; Python爬虫之Scrapy框架之🎦爬取数据
📰代码演示:
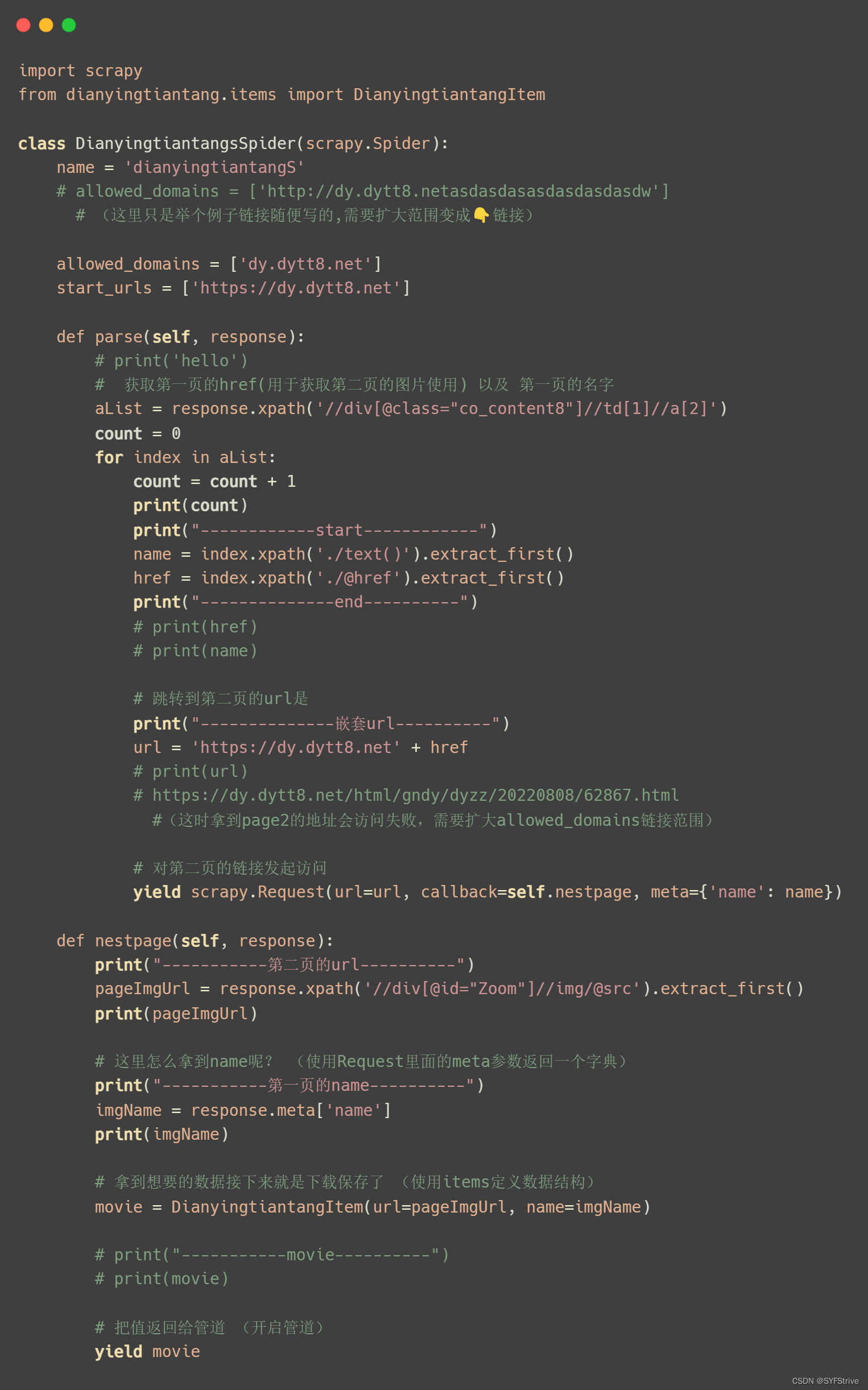
📰代码演示:
class DianyingtiantangPipeline:
def open_spider(self, spider):
self.fs = open('movie.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 简单理解:这里的item相当于yield movie返回值
self.fs.write(str(item))
return item
def close_spider(self, spider):
self.fs.close()
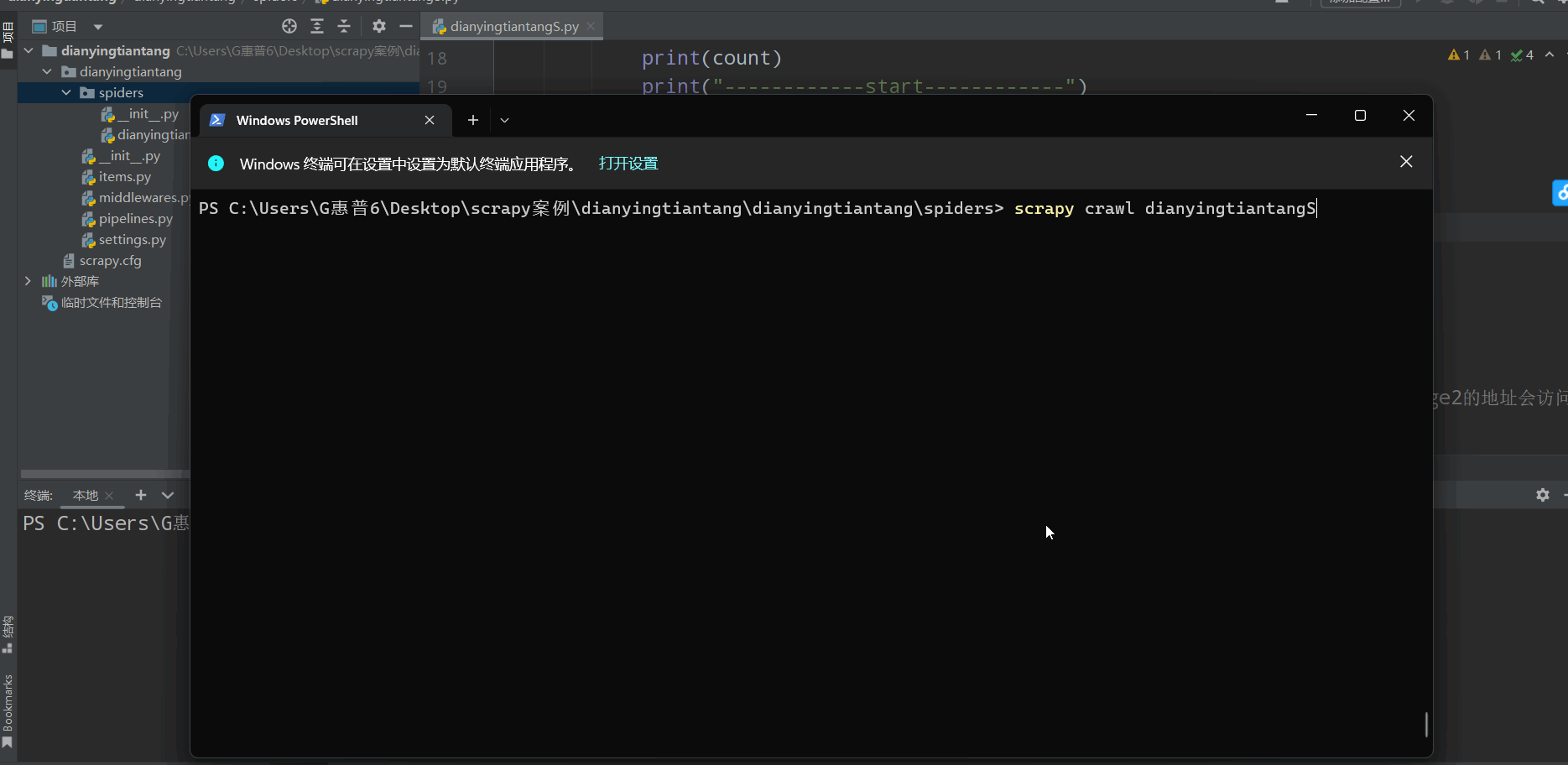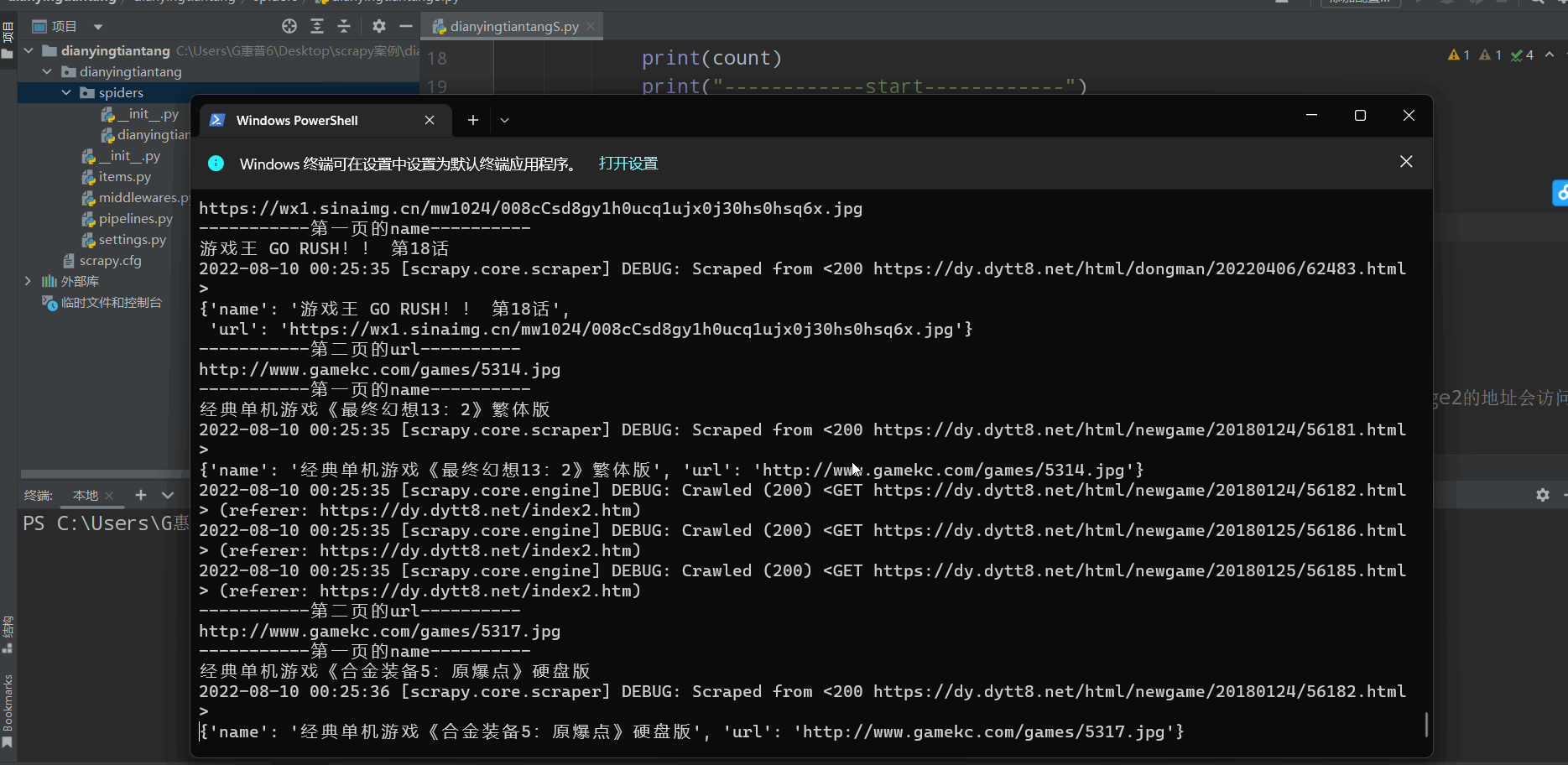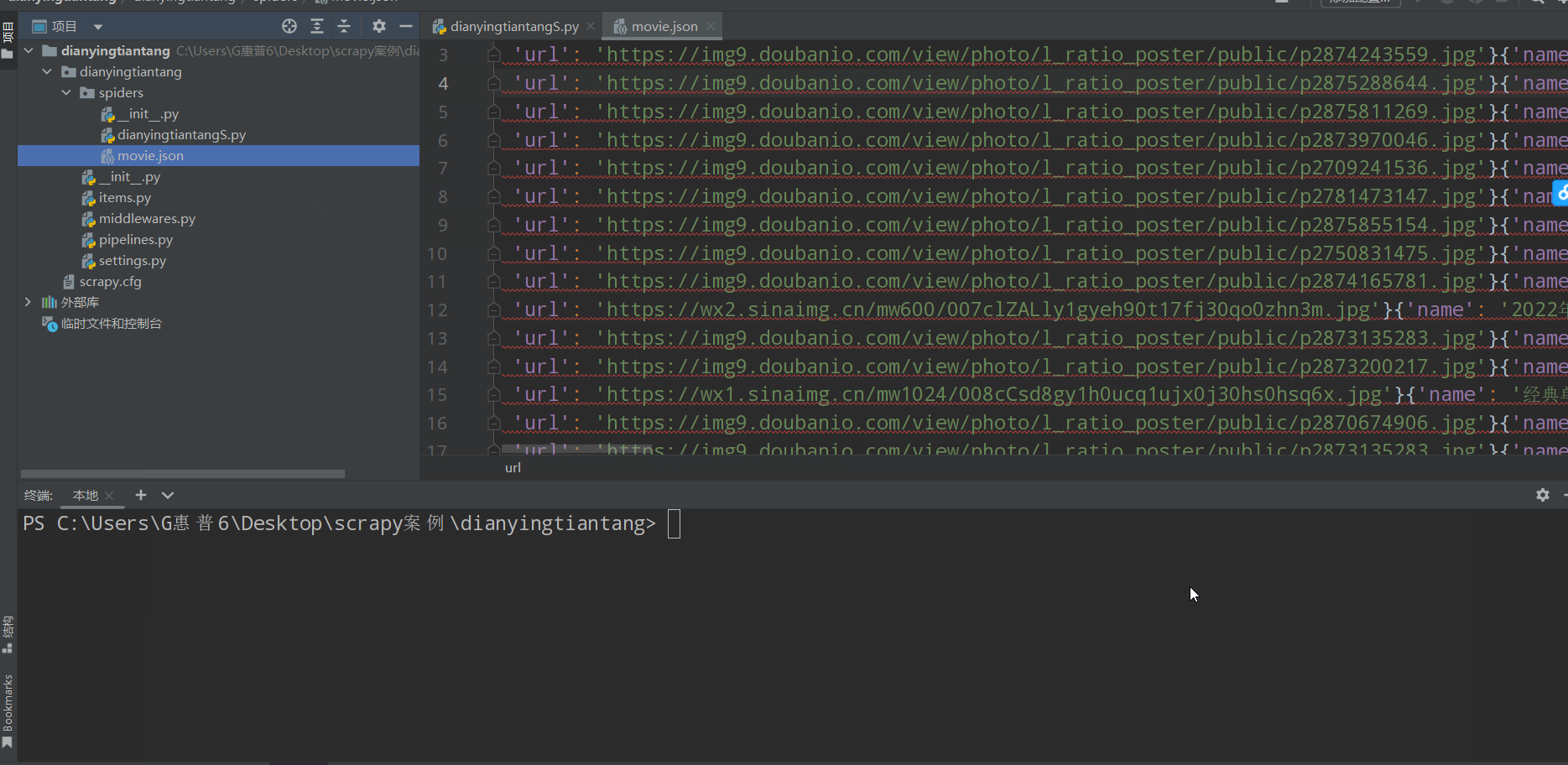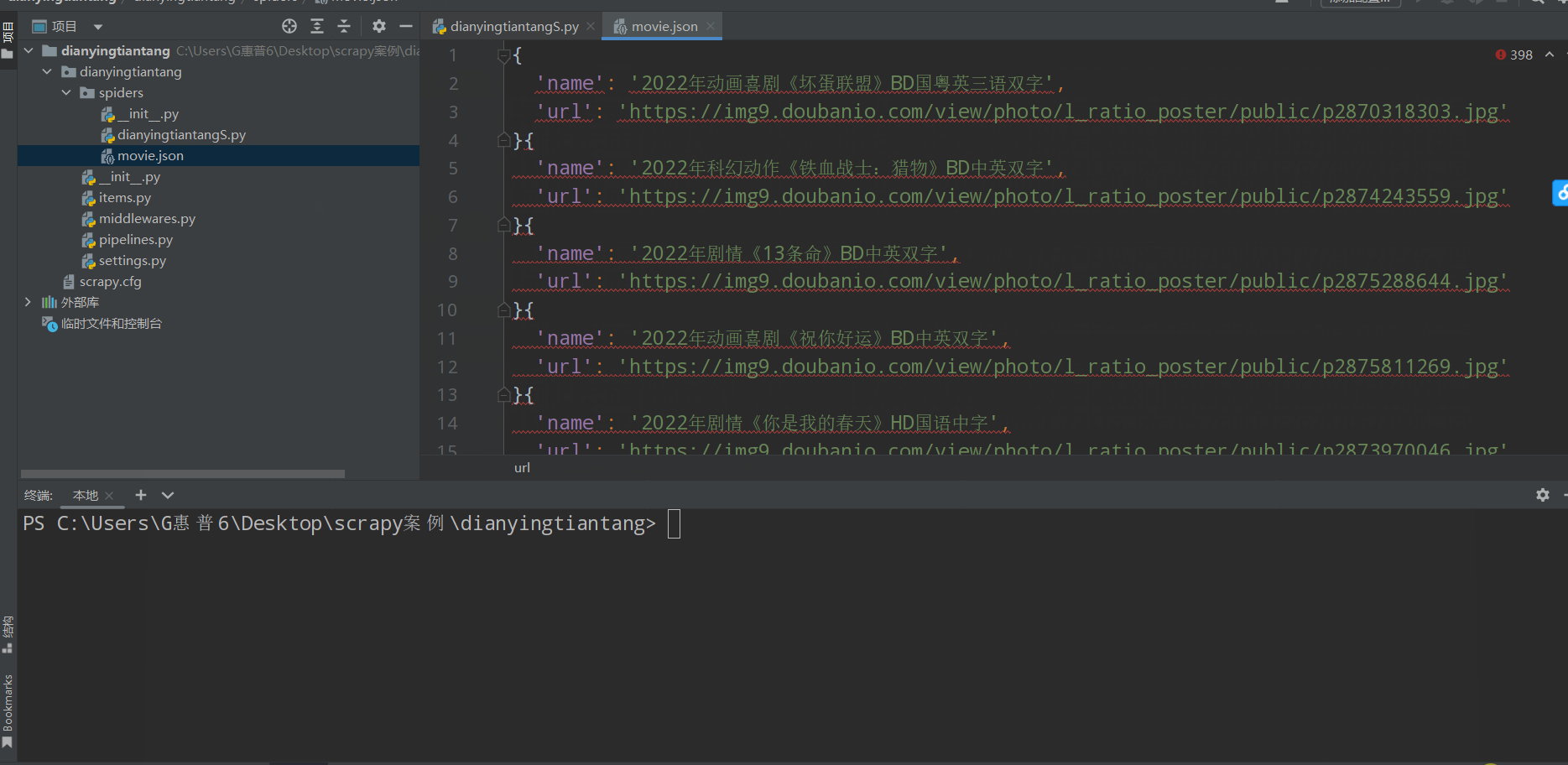
如下图(下载成功🆗):
最后
Scrapy框架还未结束(待更),觉得不错的请给我专栏点点订阅,你的支持是我们更新的动力,感谢大家的支持,希望这篇文章能帮到大家

下篇文章再见ヾ( ̄▽ ̄)ByeBye

Original: https://blog.csdn.net/m0_61490399/article/details/126246408
Author: SYFStrive
Title: Python爬虫之Scrapy框架(案例练习)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/727952/
转载文章受原作者版权保护。转载请注明原作者出处!