

强化学习PPO算法
最近再改一个代码,需要改成PPO方式的,由于之前没有接触过此类算法,因此进行了简单学习,论文没有看的很详细,重点看了实现部分,这里只做简单记录。
这里附上论文链接,需要的可以详细看一下。
Proximal Policy Optimization Algorithms
一、PPO算法
PPO算法本质上是一个On-Policy的算法,它可以对采样到的样本进行多次利用,在一定程度上解决样本利用率低的问题,收到较好的效果。论文里有两种实现方式,一种是结合KL的penalty的,另一种是clip裁断的方法。大部分都是采用的后者,本文记录的也主要是后者的实现。
二、伪代码
在网上找了一下伪代码,大概两类,前者是Open AI的,比较精炼,后者是Deepmind的,写的比较详细,在这里同时附上.



; 三、相关的简单理论
1.ratio
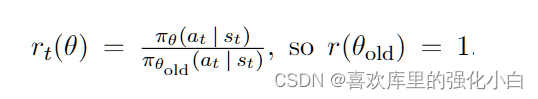
这里的比例ratio,是两种策略下动作的概率比,而在程序实现中,用的是对动作分布取对数,而后使用e指数相减的方法,具体实现如下所示:
action_logprobs = dist.log_prob(action)
ratios = torch.exp(logprobs - old_logprobs.detach())
2.裁断

其中,裁断对应的部分如下图所示:
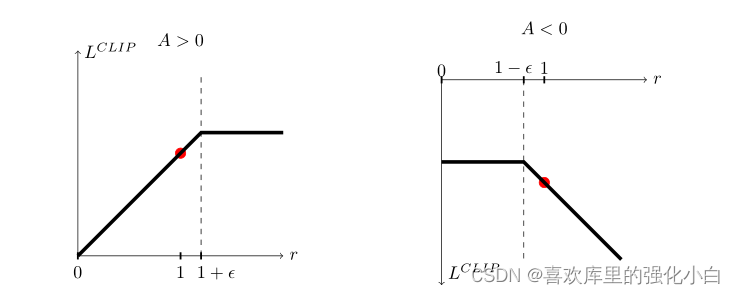
上述公式代表的含义如下:
clip公式含义.

这里我是这样理解的:
(1)如果A>0,说明现阶段的(st,at)相对较好,那么我们希望该二元组出现的概率越高越好,即ratio中的分子越大越好,但是分母分子不能差太多,因此需要加一个上限;
(2)如果A
Original: https://blog.csdn.net/weixin_47471559/article/details/125593870
Author: 喜欢库里的强化小白
Title: 【强化学习PPO算法】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/727829/
转载文章受原作者版权保护。转载请注明原作者出处!