

常用文字识别算法主要有两个框架:
- CNN+RNN+CTC(CRNN+CTC)
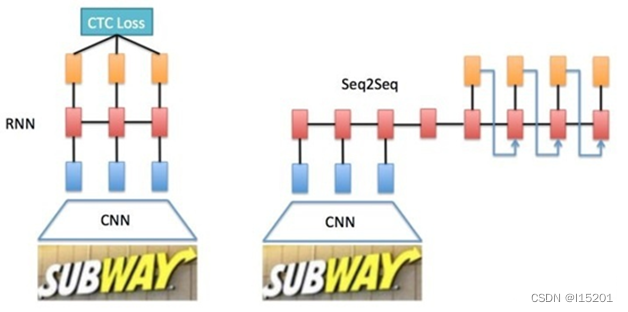

文章认为文字识别是对序列的预测方法,所以采用了对序列预测的RNN网络。通过CNN将图片的特征提取出来后采用RNN对序列进行预测,最后通过一个CTC的翻译层得到最终结果。说白了就是CNN+RNN+CTC的结构。
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。
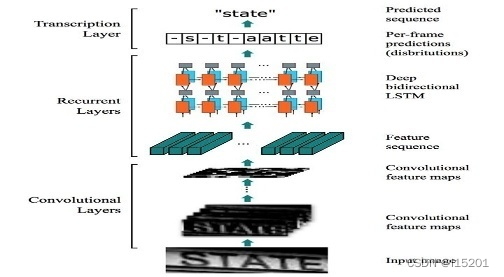
整个CRNN网络结构包含三部分,从下到上依次为:
CNN(卷积层),使用深度CNN,对输入图像提取特征,得到特征图;
RNN(循环层),使用双向RNN(BLSTM)对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签(真实值)分布;
因为 RNN 有梯度消失的问题,不能获取更多上下文信息,所以 CRNN 中使用的是 LSTM,LSTM 的特殊设计允许它捕获长距离依赖。
LSTM 是单向的,它只使用过去的信息。然而,在基于图像的序列中,两个方向的上下文是相互有用且互补的。将两个LSTM,一个向前和一个向后组合到一个双向LSTM中。此外,可以堆叠多层双向LSTM,深层结构允许比浅层抽象更高层次的抽象
这里采用的是两层各256单元的双向 LSTM 网络:
CTC loss(转录层),使用 CTC 损失,把从循环层获取的一系列标签分布转换成最终的标签序列。
LSTM是一种特核事故的RNN,主要是解决长序列的训练过程中的梯度消失和梯度爆炸问题,简单来说,LSTM在更长序列表现好。
-
*创新点
-
使用双向BLSTM 来提取图像特征,对序列特征识别效果明显
-
将语音识别领域的CTC—LOSS 引入图像,这是质的飞越
-
*不足点
-
网络复杂,尤其是BLSTM 和CTC 很难理解,且很难计算。
- 由于使用序列特征,对于角度很大的值很难识别。
CTC 的核心思路主要分为以下几部分:
- 它扩展了RNN 的输出层,在输出序列和最终标签之间增加了多对一的空间映射,并在此基础上定义了CTC Loss 函数
- 它借鉴了HMM (Hidden Markov Model )的Forward-Backward 算法思路,利用动态规划算法有效地计算CTC Loss 函数及其导数,从而解决了RNN 端到端训练的问题
- 最后,结合CTC Decoding 算法RNN 可以有效地对序列数据进行端到端的预测
CTC 的特征
- 条件独立:CTC 的一个非常不合理的假设是其假设每个时间片都是相互独立的,这是一个非常不好的假设。在OCR 或者语音识别中,各个时间片之间是含有一些语义信息的,所以如果能够在CTC 中加入语言模型的话效果应该会有提升。
- 单调对齐:CTC 的另外一个约束是输入X XX 与输出Y YY 之间的单调对齐,在OCR 和语音识别中,这种约束是成立的。但是在一些场景中例如机器翻译,这个约束便无效了。
Original: https://blog.csdn.net/l15201/article/details/126906392
Author: l15201
Title: CRNN——文本识别算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/721168/
转载文章受原作者版权保护。转载请注明原作者出处!