

异常检测(Anomaly detection)是目前时序数据分析最成熟的应用之一,定义是从正常的时间序列中识别不正常的事件或行为的过程。 有效的异常检测被广泛用于现实世界的很多领域,例如量化交易,网络安全检测、自动驾驶汽车和大型工业设备的日常维护。以在轨航天器为例,由于航天器昂贵且系统复杂,未能检测到危险可能会导致严重甚至无法弥补的损害。异常随时可能发展为严重故障,因此准确及时的异常检测可以提醒航天工程师尽早采取措施。
一般而言,很多异常可以通过人工的方式来判断。然而当业务组合复杂、时序规模变大后,依靠传统的人工和简单的同比环比等绝对值算法来判断就显得捉襟见肘了。 因此,在面对各种各样的工业级场景时,系统的了解时间序列异常检测方法尤为重要。
异常类型概述
通常说的异常大致分为异常值、波动值、异常时间序列等几种情况:
- 异常值(Outlier)
- 给定输入时间序列[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gpgjDfWM-1651809559416)(https://mmbiz.qpic.cn/mmbiz_svg/wcib2GksmGOlHr1z1jobUqwaATSrIKPsrDbSJ3wpkQl2wRvibZBzRbrEcZXIT38aYNs5pDOhIMbDiarQicDGDnA1Omk8CBicc82S4/640?wx_fmt=svg)],异常值是时间戳值其中观测值x_t与该时间序列的期望值E(x_t)不同。


- *波动点(Change Point)
给定输入时间序列[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HHiiQHcQ-1651809559417)(https://mmbiz.qpic.cn/mmbiz_svg/wcib2GksmGOlHr1z1jobUqwaATSrIKPsrDbSJ3wpkQl2wRvibZBzRbrEcZXIT38aYNs5pDOhIMbDiarQicDGDnA1Omk8CBicc82S4/640?wx_fmt=svg)],波动点是指在某个时间t,其状态在这个时间序列上表现出与t前后的值不同的特性。

- 断层异常(Breakout)

- 异常时间序列(Anomalous Time Series)
- 给定一组时间序列[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OqrWfIwQ-1651809559417)(https://mmbiz.qpic.cn/mmbiz_svg/wcib2GksmGOlHr1z1jobUqwaATSrIKPsrDbSJ3wpkQl2wRvibZBzRbrEcZXIT38aYNs5pDOhIMbDiarQicDGDnA1Omk8CBicc82S4/640?wx_fmt=svg)],异常时间序列是在X上与大多数时间序列值不一致的部分。
; 异常检测方法
基于统计的异常检测
许多异常检测技术首先建立一个数据模型。异常是那些同模型不能完美拟合的对象。例如,数据分布模型可以通过估计概率分布的参数来创建。如果一个对象不能很好地同该模型拟合,即如果它很可能不服从该分布,则它是一个异常。如果模型是簇的集合,则异常是不显著属于任何簇的对象。在使用回归模型时,异常是相对远离预测值的对象。
由于异常和正常对象可以看作两个不同的类,因此可以使用分类方法来建立这两个类的模型。当然,仅当某些对象存在类标号,使得我们可以构造训练数据集时才可以使用分类方法。此外,异常相对稀少,在选择分类方法和评估度量是需要考虑这一因素。
基于模型的方法又称为统计方法,主要通过拟合单个模型或多个模型来判断该点的概率。
3σ-法则
(μ−3σ,μ+3σ)区间内的概率为99.74。所以可以认为,当数据分布区间超过这个区间时,即可认为是异常数据。

假设数据集由一个正太分布产生,该分布可以用 N(μ,σ) 表示,其中 μ 是序列的均值,σ是序列的标准差,数据落在 (μ-3σ,μ+3σ) 之外的概率仅有0.27%,落在 (μ-4σ,μ+4σ) 之外的区域的概率仅有0.01%,可以根据对业务的理解和时序曲线,找到合适的K值用来作为不同级别的异常报警。
; 箱型图(分位数异常检测)
箱型图,是一种用作显示一组数据分散情况资料的统计图。主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比较,其绘制方法是:先找出一组数据的最大值、最小值、中位数和上下两个四分位数。通过不同分位数来划分异常值和疑似异常值。
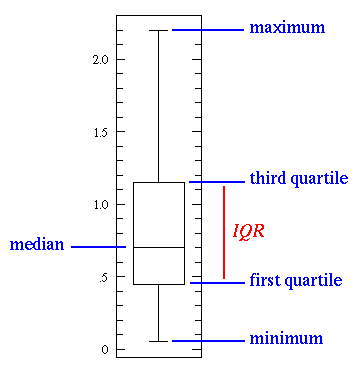
IQR是第三四分位数减去第一四分位数,大于Q3+1.5IQR之外的数和小于Q1-1.5IQR的值被认为是异常值。
Grubbs测试
Grubbs测试是一种从样本中找出outlier的方法,所谓outlier,是指样本中偏离平均值过远的数据,他们有可能是极端情况下的正常数据,也有可能是测量过程中的错误数据。使用Grubbs测试需要总体是正态分布的。
算法流程:
-
样本从小到大排序
-
求样本的mean和std.dev
-
计算min/max与mean的差距,更大的那个为可疑值
-
求可疑值的z-score (standard score),如果大于Grubbs临界值,那么就是outlier;
-
Grubbs临界值可以查表得到,它由两个值决定:检出水平α(越严格越小),样本数量n,排除outlier,对剩余序列循环做 1-4 步骤。由于这里需要的是异常判定,只需要判断tail_avg是否outlier即可。
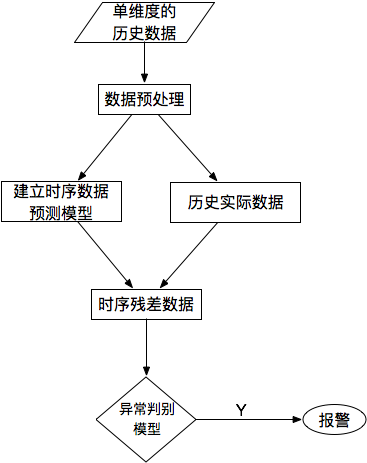
基于预测的异常检测
对于单条时序数据,根据其预测出来的时序曲线和真实的数据相比,求出每个点的残差,并对残差序列建模,利用KSigma或者分位数等方法便可以进行异常检测。具体的流程如下:
以网络流量曲线为例,该曲线局部都抖动地很厉害,若对原始数据建模,则会吸收很很大的噪音,影响模型的效果,可以先用平滑函数对数据进行平滑处理。下图中,蓝色曲线是原始的网络流量数据,紫色是经过长度为5的矩形窗口平滑之后的结果。

为了让大家有对比的看清楚平滑的效果,上图中两条曲线是画在不同的Y轴坐标系下的。先将两条曲线绘制在同一个Y轴下面,计算对应的点的残差序列,可以较好的找到异常的点。如下图中的红色圆圈标记出来的结果。

基于距离的方法/基于邻近度的方法
通常可以在对象之间定义邻近性度量,并且许多异常检测方法都基于邻近度。异常对象是那些远离大部分其他对象的对象。这一领域的许多方法都基于距离,称作基于距离的离群点检测方法。当数据能够以二维或三维散布图显示时,通过寻找与大部分其他点分离的点,可以从视觉上检测出基于距离的离群点。但是该方法计算复杂度过高,且分布不均匀的点,容易出错。
方法:
- 基于角度的离群点检测:角度越小,说明距离越远。
- k-最近邻:评分为数据对象与最近的k个点的距离之和。很明显,与k个最近点的距离之和越小,异常分越低;与k个最近点的距离之和越大,异常分越大。设定一个距离的阈值,异常分高于这个阈值,对应的数据对象就是异常点。
- Local Outlier Factor(LOF):LOF得分为数据对象的k个最近邻的平均局部密度与数据对象本身的局部密度之比。
- Connectivity Outlier Factor(COF):如果点p的平均连接距离大于它的k最近邻的平均连接距离,则点p是异常点。COF将异常值识别为其邻域比其近邻的邻域更稀疏的点。
- Stochastic Outlier Selection(SOS):通过构建时序点之间的特征矩阵(feature martrix)或者相异度矩阵(dissimilarity matrix)。基于方差,近邻点越多,方差越小;近邻点越大,方差越大。
基于密度的方法
对象的密度估计可以相对直接地计算,特别是当对象之间存在邻近性度量时,低密度区域中的对象相对远离近邻,可能被看作异常。一种更复杂的方法考虑到数据集可能有不同密度区域这一事实,仅当一个点的局部密度显著地低于它的大部分近邻时才将其分类为离群点。
1. 基于密度的异常
异常就是那些在低密度区域的数据对象,一个数据对象的异常分就是该对象所在区域的密度的倒数
2. 给定半径的邻域内的数据对象数
一个数据对象的密度等于半径为d的邻域内的数据对象数。
d的选择很重要,若d太小,则会有很多正常的数据对象被认为是异常点;若d太大,则很多异常数据对象会被误判为正常点。事实上,当密度分布不均匀的时候,上述方法得到的异常点会不正确。为了克服密度不均匀的情况,我们使用下面的平均相对密度来作为异常分。
3. 平均相对密度

基于聚类的方法
一种利用聚类检测离群点的方法是丢弃远离其他簇的小簇。这种方法可以与任何聚类方法一起使用,但是需要最小簇大小和小簇与其他簇之间距离的國值。通常,该过程可以简化为丢弃小于某个最小尺寸的所有簇。这种方案对簇个数的选择高度敏感。此外,使用这一方案,很难将离群点得分附加在对象上。注意,把一组对像看作离群点,将离群点的概念从个体对象扩展到对象组,但是本质上没有任何改变。
一种更系统的方法是,首先聚类所有对象,然后评估对象属于簇的程度。对于基于原型的聚类,可以用对象到它的簇中心的距离来度量对象属于簇的程度。更一般地,对于基于目标函数的聚类方法,可以使用该目标函數来评估对象属于任意簇的程度。特殊情况下,如果删除一个对象导致该目标的显著改进,则我们可以将对象分类为离群点。比如,对于K均值,脷除远离其相关簇中心的对象能够显著地改进簇的误差的平方和(SSE)。总而言之,聚类创建数据的模型,而非异常扭曲模型。
基于划分的方法
基于划分的方法用于异常检测,常常具有非常好的可解释性,同时也好操作。最简单的划分方法就是阈值检测,其通过人为经验划定阈值,对数据进行异常判断。
具体的,为了避免单点抖动产生的误报,需要将求取累积的窗口均值进行阈值判别,具体的累积就是通过窗口进行操作:

业务同学可以根据自己的接受范围对阈值进行分级设置,不同的阈值对应不同的操作
另一种更高级的基于划分的异常检测算法,是 iForest (Isolation Forest)孤立森林,一个基于Ensemble的快速异常检测方法。其将时序中的数据点划分成树,深度越低,说明越容易被划分,即为离群点。

图 | b和c的高度为3,a的高度是2,d的高度是1
基于线性的方法
PCA在做特征值分解之后得到的特征向量反应了原始数据方差变化程度的不同方向,特征值为数据在对应方向上的方差大小。所以,最大特征值对应的特征向量为数据方差最大的方向,最小特征值对应的特征向量为数据方差最小的方向。原始数据在不同方向上的方差变化反应了其内在特点。如果单个数据样本跟整体数据样本表现出的特点不太一致,比如在某些方向上跟其它数据样本偏离较大,可能就表示该数据样本是一个异常点。
基于非线性的方法
传统的维度下降依赖于线性方法,如 PCA,找出高维数据中最大的方差的方向。通过选择这些方向,PCA 本质上刻画了包含了最终信息的方向。所以我们可以找到一个较小的维度的数目来作为降维的结果。然而,PCA 方法的线性性使得特征维度类型的抽取上有很大限制。近年来很多神经网络的方法被用于时间序列的异常检测,比如Autoencoder,通过引入神经网络天生的非线性性克服这些限制。

针对非数值型的方法
之前介绍的大多数异常检测算法都是处理数值类型的数据,那么处理category 类型的数据,有没有什么好的算法? attribute value算法,就是非常有效的一种。
AVF算法全称Attribute Value Frequency,针对非数值型的数据,即类别离散数据的方法。具体步骤如下:
- 将所有的数据点都标为非异常点;
- 计算所有每一个属性值的频数;
- 计算每一个点的AVF score,即样本点x的每一个属性值对应的频数之和除以属性总数,当然这里的属性指的都是category 的属性。
AVFscore值越小,样本越异常。
; 开源异常检测系统
这里帮大家列举一些常用的异常检测算法包,有Java版本、R版本,供各位同学参考使用
- https://github.com/yahoo/egads
- https://github.com/markvanderloo/extremevalues
- https://github.com/yzhao062/pyod
- https://github.com/twitter/AnomalyDetection
- https://github.com/rob-med/awesome-TS-anomaly-detection
总结
其实可以看到,以上方法的分类之间也是相近的。说到底,概率、密度和聚类也是由空间中的数据点之间的距离所决定的。而本文主要是想记录基于时间序列的异常检测方法。当然,以上方法在时间序列抽取后的特征空间中也能够使用。
Original: https://blog.csdn.net/weixin_38037405/article/details/124607239
Author: 我爱Python数据挖掘
Title: 9大时序异常检测方法汇总
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/721146/
转载文章受原作者版权保护。转载请注明原作者出处!