

1.理论背景
在美国,著名的沃尔玛超市发现啤酒与尿布总是共同出现在购物车中,于是沃尔玛超市经过分析发现许多美国年轻的父亲下班之后经常要去购买婴儿的尿布,而在购买尿布的同时,他们往往会顺手购买一些啤酒;因此沃尔玛超市将啤酒与尿布放在相近的位置,方便顾客购买,并明显提高了销售额。这是频繁模式挖掘的一个经典例子——”啤酒和尿布”。简单来说,频繁模式就是当出现物品A时也经常出现物品B,比如在分析超市的购物清单时,发现买啤酒的人经常也买尿布。
购物篮分析(或是亲密性分析)是介绍频繁模式挖掘的最佳案例,它是众所周知的频繁模式挖掘应用之一。购物篮分析试图从消费者加入购物篮的商品中挖掘出某种模式或者关联,可以是真实的购物篮,也可以是虚拟的,并且给出支持度或是置信度。这一方法在用户行为分析中存在巨大的价值。将购物篮分析推而广之就成了 频繁模式挖掘,实际上它与分类非常类似,只是通过 相互的关联来 预测属性或是属性的组合(不仅仅是预测类别)。因为关联不需要有标签的数据集,所以它属于 无监督式学习。

2.基本概念
2.1频繁模式定义
频繁模式指的就是 频繁出现在数据集中的模式,比如 子序列、项集、子结果。研究频繁模式的目的是得到关联规则和其他的联系,并在实际中应用这些规则和联系。比如,频繁地同时出现在交易数据集中的商品(比如牛奶和面包)的集合是频繁项集;频繁的出现的一个购买顺序(先买笔记本,再买杀毒软件)是频繁子序列。
2.2相关概念定义
频繁项集一般是指频繁地在事务数据集中一起出现的商品的集合,如小卖部中被许多顾客频繁地一起购买的牛奶和面包。
频繁子序列,如顾客倾向于先购买便携机,再购买数码相机,然后再购买内存卡这样的模式就是一个(频繁)序列模式。
频繁子结构是指从图集合中挖掘频繁子图模式。子结构可能涉及不同的结构形式(例如,图、树或格),可以与项集或子序列结合在一起。如果一个子结构频繁地出现,则称它为(频繁)子结构模式。
关联规则是形如
的蕴含式,其中l且,则X称为规则的条件,Y称为规则的结果。如果事务数据库D中有s%的事务包含,则称关联规则的支持度为s%。例如 牛奶=>鸡蛋【支持度=2%,置信度=60%】。 关联规则意味着元素项之间”如果…那么…”的关系。
事务是由一组物品组成,可看作一个订单中的物品集合。
支持度是某几个物品一起出现在事物中的次数或在数据库中所占的比例。
置信度是在出现A时出现B的概率,就是P(B|A) = P(A B) / P(A)
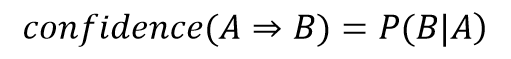
频繁项集是满足最小支持度要求的项集,它给出经常在一起出现的元素项。
项集表示包含0个或者多个项的集合。如果一个项集包含k个项,则称为 k项集 。
强关联规则表示同时满足最小支持度和最小置信度阈值要求的所有关联规则。
例如:假设最小置信度阈值为30%,最小置信度阈值为70%,而关联规则:购买面包⇒购买牛奶[支持度=50%,置信度=100%]的支持度和置信度都满足条件,则该规则为强关联规则。
2.3先验性质
- 关联规则挖掘的任务
①根据最小支持度阈值,找出数据集中所有的频繁项集;
②挖掘出频繁项集中满足最小支持度和最小置信度阈值要求的规则,得到强关联规则;
③对产生的强关联规则进行剪枝,找出有用的关联规则。
- 频繁项集的先验性质
1.如果某个项集是频繁的,那么它的所有子集也是频繁的。例如如果{B,C}是频繁的,那么{B},{C}也一定是频繁的。
2.如果一个项集是非频繁集,那么它的所有超集(包含该非频繁集的父集)也是非频繁的。如果{A, B}是非频繁的,那么{A, B, C},{A, B, C, D}也一定是频繁的。
2.4 关联规则挖掘的步骤
- 找出所有频繁项集,即大于或等于最小支持度阈值的项集。
- 由频繁项集产生强关联规则,这些规则必须大于或等于最小支持度阈值和最小置信度阈值。
3 Apriori算法
3.1算法概述
Apriori算法是布尔关联规则挖掘频繁项集的原创性算法,该算法使用频繁项集性质的先验知识。Apriori使用一种称作逐层搜索的迭代方法,k项集用于探索(k+1)项集。首先,通过扫描数据库,累积每个项(数据集不重复的元素)的计数,并收集满足最小支持度的项,找出频繁1项集的集合,并将集合记作L1。然后,L1用于找频繁2项集的集合L2,L2用于找L3,如此迭代,直到不能再找到频繁k项集。找每个Lk需要一次数据库全扫描。
3.2实现原理
算法实现过程分为两步,一步是 连接,一步是 剪枝。
输入:项集I,事务数据集D,最小支持度计数阈值Min_sup
输出:D中的所有频繁项集的集合L。
实现步骤:
(1)求频繁1项集L1 首先通过扫描事务数据集D,找出所有1项集并计算其支持度,作为候选1项集C1 然后从C1中删除低于最小支持度阈值Min_sup的项集,得到所有频繁1项集的集合L1 。
(2)For k=2,3,4,分别得到L2、L3、L4…Lk。
(3)连接:将Lk-1进行自身连接生成候选k项集的集合Ck,连接方法如下:对于任意p,q∈Lk-1,若按字典序有p={p1,p2,…,pk-2,pk-1}, q={p1,p2,…,pk-2,qk-1},且满足pk-1
Original: https://blog.csdn.net/weixin_56516468/article/details/121479149
Author: 浪荡子爱自由
Title: 【数据挖掘】频繁模式挖掘及Python实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/720322/
转载文章受原作者版权保护。转载请注明原作者出处!