

朴素贝叶斯模型(了解)
*
– 6.1 朴素贝叶斯模型算法原理
–
+ 6.1.1 一维特征向量下的贝叶斯模型
+ 6.1.2 二维特征向量下的贝叶斯模型
+ 6.1.3 n维特征向量下的贝叶斯模型
+ 6.1.4 朴素贝叶斯模型简单代码演示
– 6.2 案例实战 – 肿瘤预测模型(分类模型)
–
+ 6.2.1 案例背景
+ 6.2.2 数据读取与划分
+ 6.2.3 模型搭建与预测
– 6.3 课程相关资源
这一章主要讲解机器学习中的朴素贝叶斯模型,包括朴素贝叶斯的算法原理和编程实现。同时将介绍一个朴素贝叶斯的经典案例:判断肿瘤为良性还是恶性来巩固所学知识点。
6.1 朴素贝叶斯模型算法原理
贝叶斯分类是机器学习中应用较为广泛的分类算法之一,其产生来自于贝叶斯对于逆概问题的思考,朴素贝叶斯是贝叶斯模型当中最简单的一种。
其算法核心为贝叶斯公式:
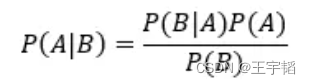

其中P(A)为事件A发生的概率,P(B)为事件B发生的概率, P(A|B)表示在事件B发生的条件下事件A发生的概率,同理P(B|A)则表示在事件A发生的条件下事件B发生的概率。
举个简单的例子,已知流感季节一个人感冒(事件A)的概率为40%(P(A)),一个人打喷嚏(事件B)的概率为80%(P(B)),一个人感冒的条件下打喷嚏的概率为100%(P(B|A)),那么已知一个人开始打喷嚏了,他是患感冒的概率为多少?这其实就是求这个人在打喷嚏的条件下患感冒的概率P(A|B),求解过程如下图所示:
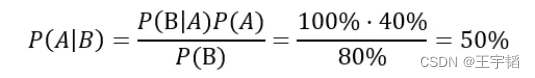
; 6.1.1 一维特征向量下的贝叶斯模型
我们首先以一个更详细的例子来讲解一下贝叶斯公式更加偏实战的应用:如何判断一个人是否感冒了。假设已经有5个样本数据,如下表所示:
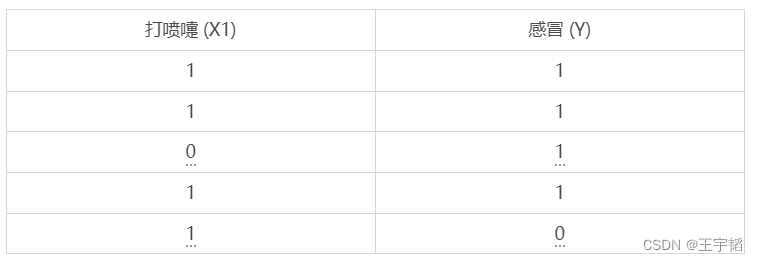
为方便演示,这里选取了一个特征变量:打喷嚏 (X1),其中数字1表示打喷嚏,0表示不打喷嚏;这里的目标变量是感冒 (Y),其中数字1表示感冒了,数字0表示未感冒。
根据上述数据,我们要利用贝叶斯公式,来预测一个人是否处于感冒的状态, 比如说,一个人打喷嚏 (X1=1),那么他是否感冒了呢,也即预测他处于感冒状态的概率为多少,在数学上,我们把此概率写作P(Y|X1)。
应用贝叶斯公式有:
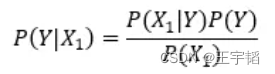
根据上述数据,我们可以计算在打喷嚏 (X1=1) 的条件下,患上感冒的概率为
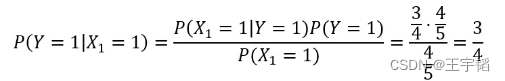
其中P(X1=1|Y=1)为在已经感冒的条件下打喷嚏的概率,这里感冒的4个样本中打喷嚏的有3个,所以该概率为3/4;P(Y=1)则为所有样本中感冒的概率,这里5个人中有4个人感冒,所以为4/5;P(X1=1)则为所有样本中打喷嚏的概率,这里5个人中有4个人打喷嚏,所以为4/5。
同理在打喷嚏 (X1=1) 的条件下,没有患上感冒的概率为:
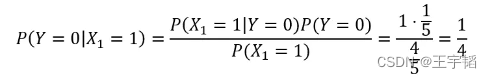
其中P(X1=1|Y=0)为在未感冒的条件下打喷嚏的概率,为1;P(Y=0)则为所有样本中未感冒的概率,为4/5;P(X1=1)则为所有样本中打喷嚏的概率,为4/5。
由于3/4大于1/4,所以在打喷嚏(X1=1) 的条件下患感冒的概率要高于不患感冒的概率,所以判断该人感冒了。
6.1.2 二维特征向量下的贝叶斯模型
层层递进,我们加入另外一个特征变量:头痛(X2),其中数字1表示头痛,0表示不头痛;这里的目标变量仍为感冒(Y)。
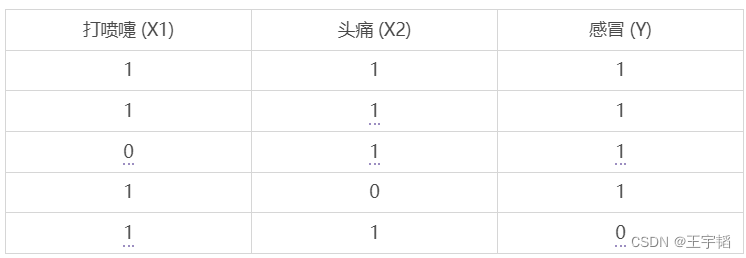
根据上述数据,我们仍利用贝叶斯公式,来预测一个人是否处于感冒的状态, 比如说,一个人他打喷嚏且头痛 (X1=1, X2=1) ,那么他是否感冒了呢,也即预测他处于感冒状态的概率为多少,在数学上,我们把此概率写作P(Y|X1,X2)。
应用贝叶斯公式有:
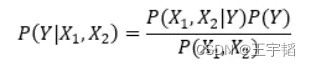
在比较 P(Y=1|X1,X2) 与 P(Y=0|X1,X2) 时,由于分母 P(X1,X2) 的值是相同的,所以我们在实际计算中可以舍去这部分的计算,直接比较两者分子大小即可。即:
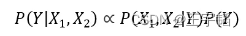
补充知识点:独立性假设
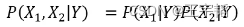
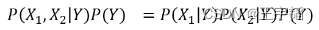
在独立性假设的条件下,我们可以计算打喷嚏且头痛 (X1=1,X2=1) 的条件下感冒的概率P(Y=1|X1,X2) ,即简化为计算 P(X1|Y=1)P(X2|Y=1)P(Y=1) (P(X1|Y)P(X2|Y)P(Y))的值:
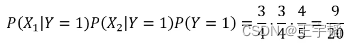
同理可以计算打喷嚏且头痛 (X1=1,X2=1) 的条件下没有患感冒的概率 P(Y=0|X1,X2), 即简化为计算P(X1|Y=0)P(X2|Y=0)P(Y=0):
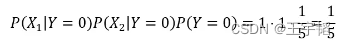
由于9/20大于1/5,我们可以判断在打喷嚏但不头痛(X1=1,X2=1) 的条件下患感冒的概率要高于不患感冒的概率。
; 6.1.3 n维特征向量下的贝叶斯模型
我们可以在2个特征变量的基础上推广至n个特征变量 X1, X2, … , Xn,应用贝叶斯公式有:
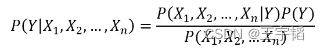
同理因为分母相同,我们只需要关注分子
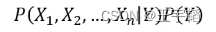
朴素贝叶斯模型假设给定目标值后特征之间相互独立,上式可以写作
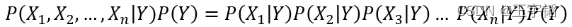
其中P(X1|Y)、P(X2|Y)、P(Y)等数据都是已知的,由此可以根据上述公式计算在n个特征变量的不同取值的条件下,目标变量取某个值的概率,并且选择概率更高者对样本进行分类。
6.1.4 朴素贝叶斯模型简单代码演示
朴素贝叶斯模型(这里用的是高斯贝叶斯分类器)的引入方式如下所示:
from sklearn.naive_bayes import GaussianNB
在Jupyter Notebook编辑器中,在引入该库后,可以通过如下代码获取官方讲解内容:
GaussianNB?
朴素贝叶斯模型简单代码演示如下所示:
from sklearn.naive_bayes import GaussianNB
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
y = [0, 0, 0, 1, 1]
model = GaussianNB()
model.fit(X, y)
print(model.predict([[5, 5]]))
其中X是特征变量,其共有2个特征;y是目标变量,共有两个类别:0和1;第5行引入模型;第6行通过fit()函数训练模型;最后1行通过predict()函数进行预测,预测结果如下:
[0]
6.2 案例实战 – 肿瘤预测模型(分类模型)
这一节将以一个医疗行业较为经典的肿瘤预测模型为例讲解如何在实战中应用朴素贝叶斯模型,我们将利用该模型来预测肿瘤为良性肿瘤还是恶性肿瘤。
6.2.1 案例背景
医疗水平突飞猛进,人们对医院快速识别肿瘤是否为良性的要求同样也越来越高,能否根据患者肿瘤的相关特征水平快速判断肿瘤的性质影响着患者的治疗方式和痊愈速度。传统的做法是医生根据数十个指标来判断肿瘤的性质,不过该方法的预测效果依赖于医生的个人经验而且效率较低,而通过机器学习我们有望能快速预测肿瘤的性质。
6.2.2 数据读取与划分
1.读取数据
首先导入某医院569个患者乳腺肿瘤6个特征维度的数据以及患者的肿瘤是否为良性 (Y) 的数据。其中良性肿瘤数据为358例、恶性肿瘤数据为211例。
import pandas as pd
df = pd.read_excel('肿瘤数据.xlsx')
df.head()
df.head()用来展示前五行数据。运行结果如下图所示:
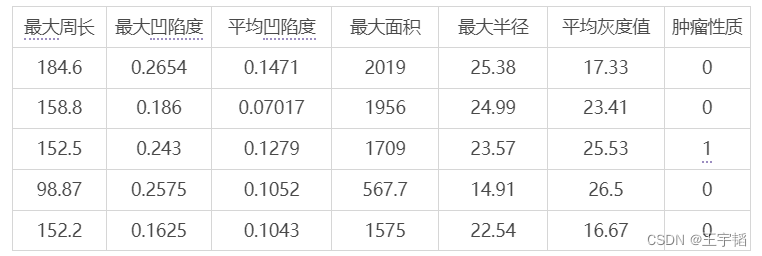
其中6个特征变量分别为:最大周长,最大凹陷度,平均凹陷度,最大面积,最大半径,平均表面纹理灰度值。最大周长代表所有肿瘤中周长最大3个值的平均值;最大凹陷度代表所有肿瘤中凹陷度最大3个值的平均值;平均凹陷度代表所有肿瘤凹陷度的平均值;最大面积代表所有肿瘤中面积最大3个值的平均值;最大半径代表所有肿瘤中半径最大3个值的平均值;平均灰度值代表所有肿瘤图像灰度值的平均值。对于目标变量肿瘤性质,Y=0 代表肿瘤为恶性,Y=1代表肿瘤为良性。
注意这里为了方便演示,只选取了6个特征变量,但在医疗行业中,用来判断肿瘤是否为良性的特征变量多得多。
2.划分特征变量和目标变量
通过如下代码将特征变量和目标变量单独提取出来,代码如下:
X = df.drop(columns='肿瘤性质')
y = df['肿瘤性质']
这里通过drop()函数删除”肿瘤性质”这一列,将剩下的数据作为特征变量赋值给变量X。然后通过DataFrame提取列的方式提取”肿瘤性质”这一列作为目标变量,并赋值给变量y。
6.2.3 模型搭建与预测
1.划分训练集和测试集
和之前章节类似,通过如下代码将数据分为训练集和测试集,其中训练集用来训练模型,而测试集用来对模型进行测试,从而检测模型的质量。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
其中X_train,y_train为训练集的特征变量和目标变量数据,X_test,y_test则为测试集中的特征变量和目标变量数据,感兴趣的读者可以将它们打印出来看看。注意这里有500多个数据,并不算多,所以按8:2的比例来划分训练集和测试集,所以test_size设定为0.2。
因为每次运行程序时,train_test_split()函数都是随机划分数据的,如果想每次划分数据产生的内容都是一致的,可以设置random_state参数为1,数字1没有特殊含义,可以换成别的数字,它只是相当于一个种子参数,使得这样每次划分数据的时候,内容都是一致的。
2.模型搭建
模型搭建的过程相对比较容易,通过如下代码即可搭建朴素贝叶斯模型。
from sklearn.naive_bayes import GaussianNB
nb_clf = GaussianNB() # 高斯朴素贝叶斯模型
nb_clf.fit(X_train,y_train)
第一行代码从Scikit-Learn库中引入贝叶斯模型(naive_bayes),并且这里使用的是应用场景最为广泛的高斯朴素贝叶斯模型 (GaussianNB) ,它可以适用于任何连续数值型的数据集。
第二行代码将逻辑回归模型赋值给nb_clf变量,这里没有设置参数,也即使用默认参数。
第三行代码则是通过fit()方法来进行模型的训练,其中传入的参数就是上一步骤获得的训练集数据X_train, y_train。
至此,一个朴素贝叶斯模型便已经搭建完成了,之后就可以利用模型来进行预测了,此时之前划分的测试集就可以发挥作用了,我们可以利用测试集来进行预测并评估模型的预测效果。
3.模型预测 – 预测数据结果
搭建模型的目的便是希望利用它来预测数据,这里把测试集中的数据导入到模型中来进行预测,代码如下,其中nb_clf就是上面搭建的朴素贝叶斯回归模型。
y_pred = nb_clf.predict(X_test)
通过print(y_pred[:100])将预测的y_pred的前100项数据打印输出如下,0和1为预测的结果,0为预测为恶性肿瘤,1为预测为良性肿瘤。

利用创建DataFrame相关知识点,将预测的y_pred和测试集实际的y_test汇总,代码如下:
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
此时生成的对比表格如下所示:
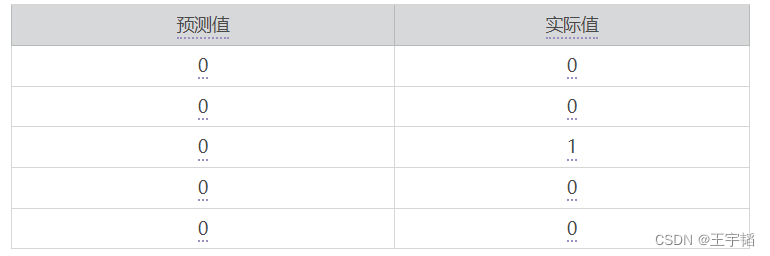
可以看到此时前五项的预测准确度为80%,如果想看所有测试集数据的预测准确度,可以使用如下代码:
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
其中第一行引入可以计算准确度的accuracy_score()方法,然后第二行将预测值y_pred和实际值y_test传入accuracy_score()的括号中,便可以计算预测的准确度,将score打印输出,发现score的值为0.947,也即预测准确度为94.7%,说明114(569*0.2)个测试数据中,共有约108个数据预测正确,6个数据预测错误。
作为分类模型,朴素贝叶斯模型也可以利用ROC曲线来评估其模型模型效果,感兴趣的读者可以自己尝试一下,其方法和之前逻辑回归模型和决策树模型的方法是一样的。这里的6个特征变量是笔者已经筛选过的特征重要性较高的变量了,所以该模型的ROC曲线会比较陡峭,且AUC值会较高。
总结来说,朴素贝叶斯模型是一个非常经典的机器学习模型,它主要基于贝叶斯公式,在应用过程中,会把数据集中的特征看成是相互独立的,而不需考虑特征间的关联关系,其运算速度较快。相比于其他经典的机器学习模型,朴素贝叶斯模型泛化的能力稍微弱一点,不过当样本及特征的数量增加时,其预测效果也是不错的。
6.3 课程相关资源
笔者获取方式:微信号获取
添加如下微信:huaxz001 。
笔者网站:www.huaxiaozhi.com
王宇韬相关课程可通过:
京东链接:[https://search.jd.com/Search?keyword=王宇韬],搜索” 王宇韬“,在 淘宝、当当也可购买。加入学习交流群,可以添加如下微信:huaxz001(请注明缘由)。

各类课程可在 网易云、51CTO搜索王宇韬,进行查看。
Original: https://blog.csdn.net/wangyutao12345/article/details/126322987
Author: 王宇韬
Title: 机器学习第六章之朴素贝叶斯模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/720124/
转载文章受原作者版权保护。转载请注明原作者出处!