

Project 2: Multi-Agent
- Introduction
* - 题目介绍
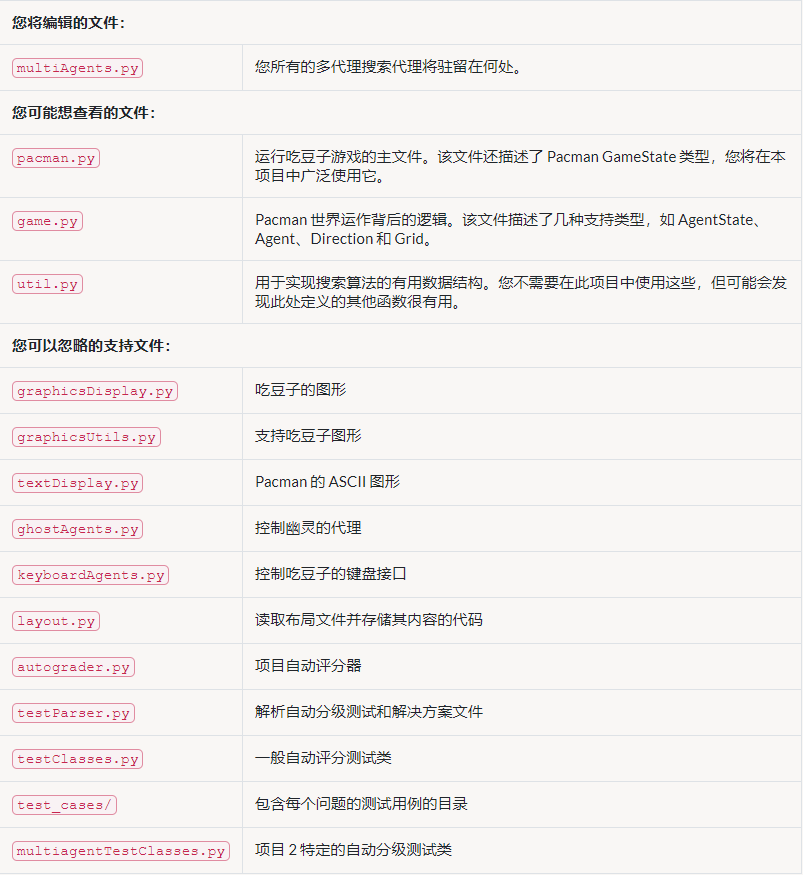
- 文件介绍
- 说在前面
- Problem2:Minimax极小极大
- Problem3:Alpha-Beta剪枝
- Problem4:Expectimax
- Problem5:Evaluation Function评价函数
- 所学感悟
- 参考链接
Introduction
题目介绍
本题目来源于UC Berkeley 2021春季 CS188 Artificial Intelligence Project2上的内容,项目具体介绍链接点击此处:UC Berkeley Spring 2021Project 2: Multi-Agent Search
文件介绍

; 说在前面
本项目只完成了project2中problem2-problem5部分,若有需要查看problem1部分,请移步至其他技术博客。
项目开发环境:Python3.9+VS Code
若电脑上未安装Python环境或者所安装的Python环境版本较低,可以在cmd中运行python查看情况。
若未安装,则cmd会跳转至Python安装界面:
安装后的cmd如图所示:
Problem2:Minimax极小极大
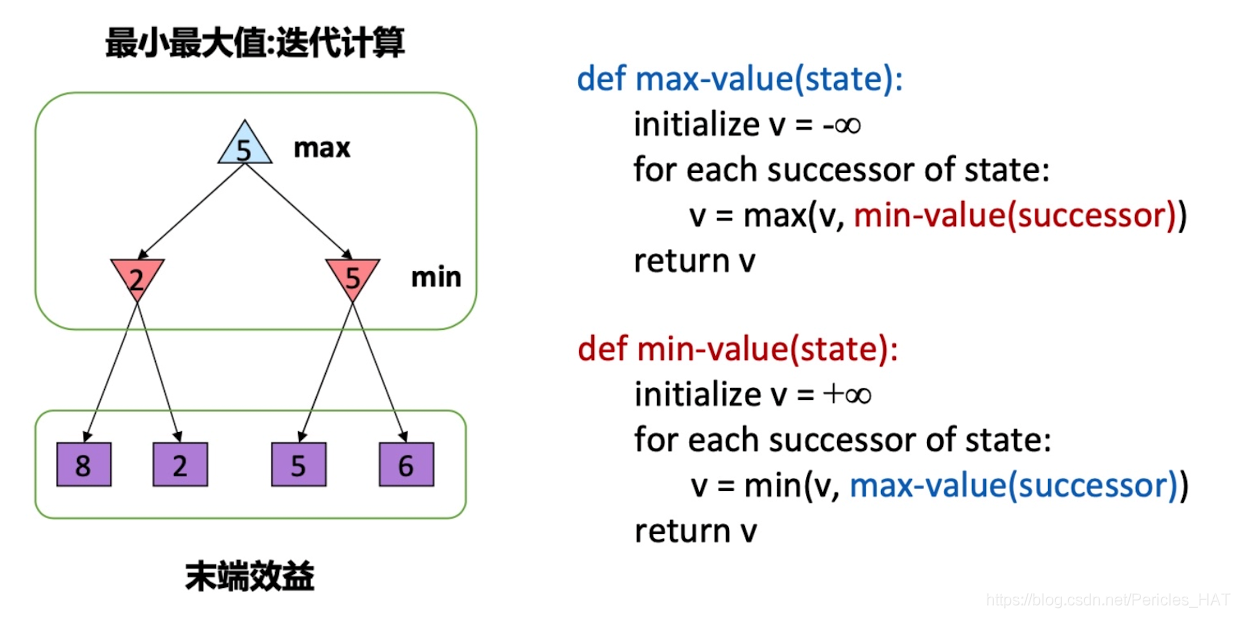
Minimax极小极大算法是 对抗搜索中的重要搜索方法,根据题目要求,我们可以通过迭代的方式找出失败的的最大可能性中的最小值。
在本题中,由于需要AI去击败玩家Player,所以我们 考虑Max作为AI的最大利益,Min作为Player的最小利益。
我们能够将如下的伪代码转换成我们需要的代码。值得一提的是,在2021年春季的project2中,将之前的 generatSuccessor函数改为了 getNextState函数,含义更具体与清晰。
class MinimaxAgent(MultiAgentSearchAgent):
"""
Your minimax agent (question 2)
"""
def getAction(self, gameState):
"""
Returns the minimax action from the current gameState using self.depth
and self.evaluationFunction.
Here are some method calls that might be useful when implementing minimax.
gameState.getLegalActions(agentIndex):
Returns a list of legal actions for an agent
agentIndex=0 means Pacman, ghosts are >= 1
gameState.getNextState(agentIndex, action):
Returns the child game state after an agent takes an action
gameState.getNumAgents():
Returns the total number of agents in the game
gameState.isWin():
Returns whether or not the game state is a winning state
gameState.isLose():
Returns whether or not the game state is a losing state
"""
"*** YOUR CODE HERE ***"
#Step 1.to realize get 'Min-Value'part
def min_value(gameState,depth,agentIndex):
#Initialize v= positively infinity
v=float('inf')
#if current state is gonna to stop"
if gameState.isWin() or gameState.isLose():
#it returns a number, where higher numbers are better
return self.evaluationFunction(gameState)
#for each successor of state:get min-value
for legalAction in gameState.getLegalActions(agentIndex):
if agentIndex==gameState.getNumAgents()-1:
#v=min(v,max_value(successor))
v=min(v,max_value(gameState.getNextState(agentIndex,legalAction),depth))
else:
#go on searching the next ghost
v=min(v,min_value(gameState.getNextState(agentIndex,legalAction),depth,agentIndex+1))
return v
#Step 2.to realize get 'Max-Value'part
def max_value(gameState,depth):
#Initialize v= negatively infinity
v=float('-inf')
#while the first step is the top point,go on and depth add 1
depth=depth+1
#if current state is gonna to stop
if depth==self.depth or gameState.isLose() or gameState.isWin():
return self.evaluationFunction(gameState)
#for each successor of state:get max-value
for legalAction in gameState.getLegalActions(0):
#v=max(v,min_value(successor))
v=max(v,min_value(gameState.getNextState(0,legalAction),depth,1))
return v
nextAction=gameState.getLegalActions(0)
Max=float('-inf')
Result=None
for nAction in nextAction:
if(nAction!="stop"):
depth=0
value=min_value(gameState.getNextState(0,nAction),depth,1)
if(value>Max):
Max=value
Result=nAction
return Result
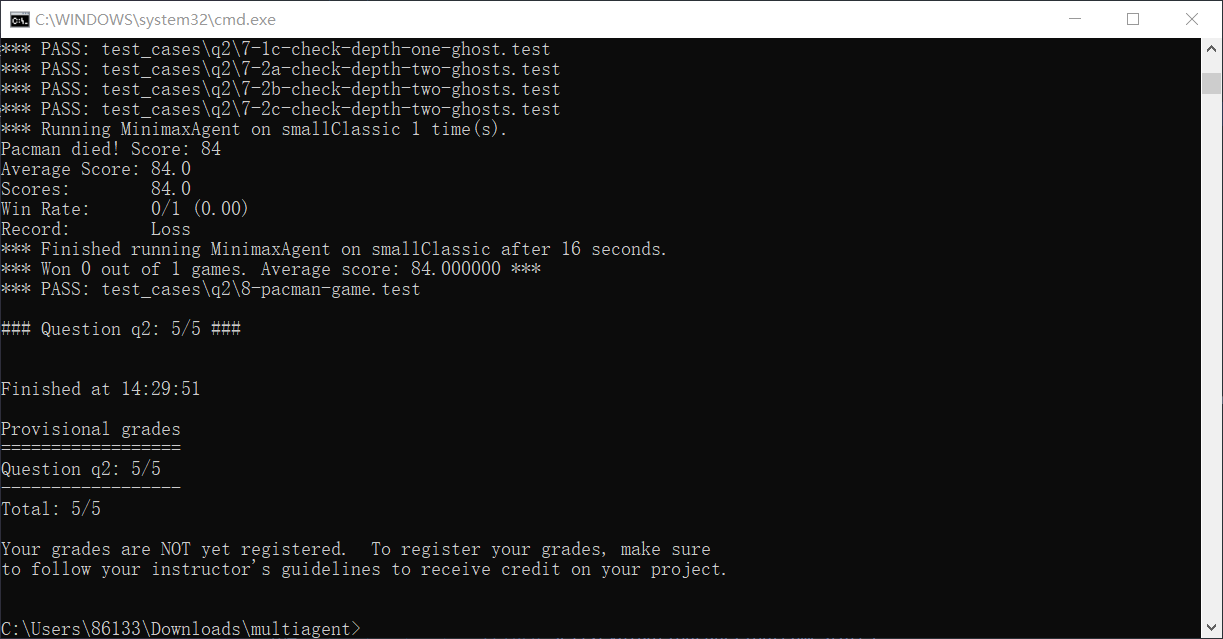
运行及截图:
python autograder.py -q q2 --no-graphics
Problem3:Alpha-Beta剪枝
在Minimax极小极大算法中有重复计算的部分,所以要进行剪枝。
Alpha-Beta剪枝用于裁剪搜索树中不需要搜索的树枝,来提升运算效率。
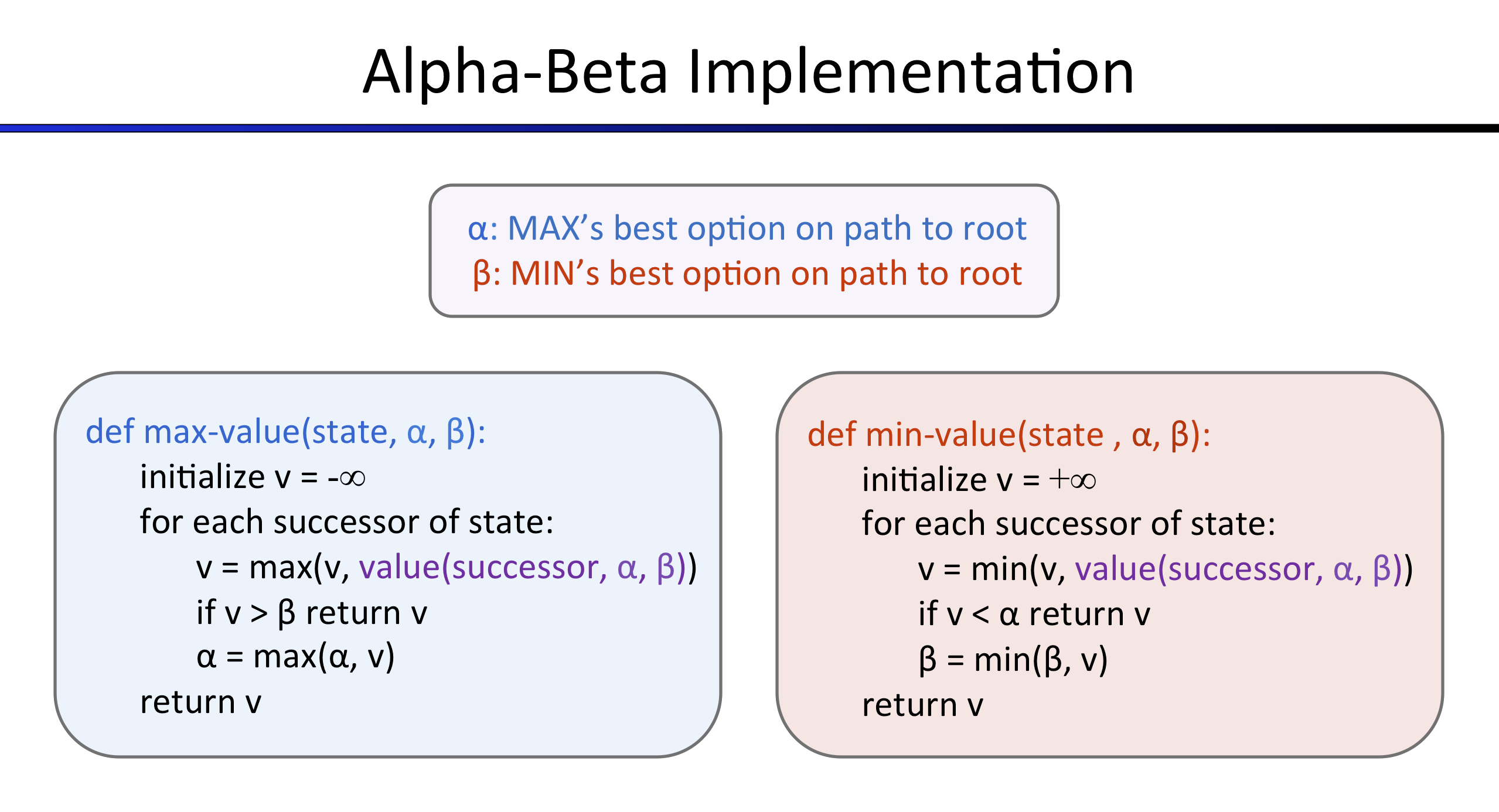
在Alpha-Beta部分我的做法不同于Minimax,在此部分进行了一定的改善。比如在比较过程中加入了函数getValue()来简化计算过程。最大的改善之处主要max-value和min-value中需要加入参数alpha&beta,并通过比较来返回值v。
class AlphaBetaAgent(MultiAgentSearchAgent):
"""
Your minimax agent with alpha-beta pruning (question 3)
"""
def getAction(self, gameState):
"""
Returns the minimax action using self.depth and self.evaluationFunction
"""
"*** YOUR CODE HERE ***"
alpha = float('-inf')
beta = float('inf')
v = float('-inf')
bestAction = None
for legalAction in gameState.getLegalActions(0):
value = self.getValue(gameState.getNextState(0, legalAction),1,0,alpha,beta)
if value is not None and value>v:
v = value
bestAction = legalAction
#update new alpha
alpha=max(alpha,v)
return bestAction
def getValue(self, gameState, agentIndex, depth, alpha, beta):
legalActions = gameState.getLegalActions(agentIndex)
if len(legalActions)==0:
return self.evaluationFunction(gameState)
#according to the value of agentIndex,gain the function of next state
#to assure the next is player or ghost
if agentIndex==0:
#cross 1 time
depth=depth+1
if depth == self.depth:
return self.evaluationFunction(gameState)
else:
return self.max_value(gameState, agentIndex, depth, alpha, beta)
elif agentIndex>0:
return self.min_value(gameState, agentIndex, depth, alpha, beta)
def max_value(self, gameState, agentIndex, depth, alpha, beta):
#Initialize v= negatively infinity
v = float('-inf')
#for each successor of state:get max-value
for legalAction in gameState.getLegalActions(agentIndex):
value = self.getValue(gameState.getNextState(agentIndex, legalAction),
(agentIndex+1)%gameState.getNumAgents(), depth, alpha, beta)
#this condition is similar with problem2 ' s condition
if value is not None and value > v:
v=value
#if v>beta return v
if v>beta:
return v
#update new alpha
alpha=max(alpha,v)
return v
def min_value(self, gameState, agentIndex, depth, alpha, beta):
#Initialize v= positively infinity
v = float('inf')
#for each successor of state:get min-value
for legalAction in gameState.getLegalActions(agentIndex):
value = self.getValue(gameState.getNextState(agentIndex, legalAction),
(agentIndex+1)%gameState.getNumAgents(), depth, alpha, beta)
if value is not None and value < v:
v=value
#if v
if v<alpha:
return v
#update new beta
beta=min(beta,v)
return v
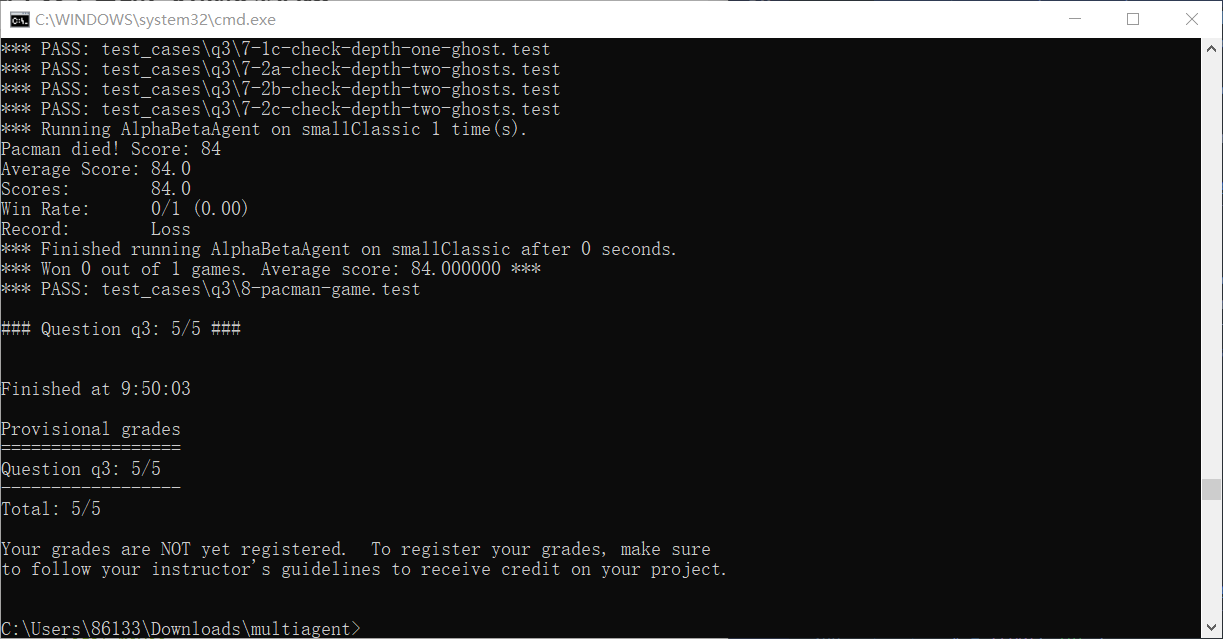
运行及截图:
python autograder.py -q q3 --no-graphics
Problem4:Expectimax
Expectimax算法本质上就是每次进行 期望值的计算,然后再选取最大值,不断递归。首先从吃豆人开始,遍历所有可行的下一步,取效用最佳的action为bestAction。
和Alpha-Beta剪枝相比,本算法出现了exp-value,即计算期望值。通过对合法动作遍历,轮询所有的下一个状态,取所有评价值的平均值作为计算结果。
class ExpectimaxAgent(MultiAgentSearchAgent):
"""
Your expectimax agent (question 4)
"""
def getAction(self, gameState):
"""
Returns the expectimax action using self.depth and self.evaluationFunction
All ghosts should be modeled as choosing uniformly at random from their
legal moves.
"""
"*** YOUR CODE HERE ***"
maxVal = float('-inf')
bestAction = None
for action in gameState.getLegalActions(agentIndex=0):
value = self.getValue(gameState.getNextState(agentIndex=0, action=action), agentIndex=1, depth=0)
if value is not None and value>maxVal:
maxVal = value
bestAction = action
return bestAction
def getValue(self, gameState, agentIndex, depth):
legalActions = gameState.getLegalActions(agentIndex)
if len(legalActions)==0:
return self.evaluationFunction(gameState)
if agentIndex==0:
depth += 1
if depth == self.depth:
return self.evaluationFunction(gameState)
else:
return self.max_value(gameState, agentIndex, depth)
elif agentIndex>0:
return self.exp_value(gameState, agentIndex, depth)
def max_value(self, gameState, agentIndex, depth):
maxVal = -float('inf')
legalActions = gameState.getLegalActions(agentIndex)
for action in legalActions:
value = self.getValue(gameState.getNextState(agentIndex, action), (agentIndex+1)%gameState.getNumAgents(), depth)
if value is not None and value > maxVal:
maxVal = value
return maxVal
def exp_value(self, gameState, agentIndex, depth):
legalActions = gameState.getLegalActions(agentIndex)
total = 0
for action in legalActions:
value = self.getValue(gameState.getNextState(agentIndex, action), (agentIndex+1)%gameState.getNumAgents(), depth)
if value is not None:
total += value
return total/(len(legalActions))
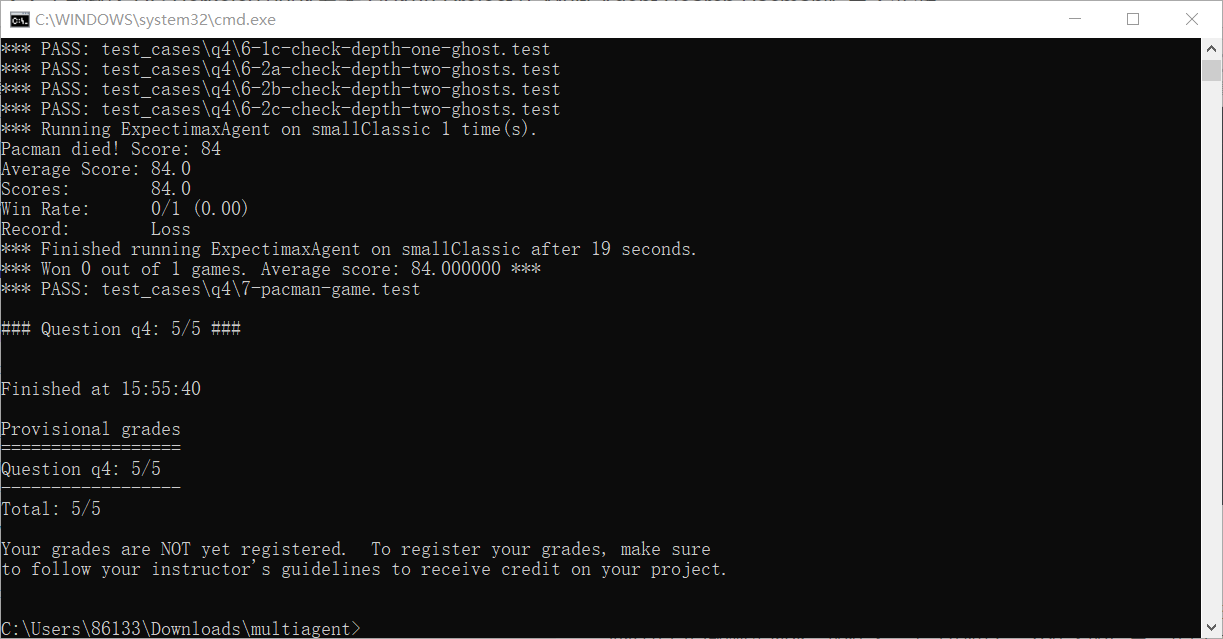
运行及截图:
python autograder.py -q q4
“你现在应该在与鬼魂的近距离观察中观察到一种更加傲慢的方法。尤其是,如果吃豆子意识到自己可能被困住了,但可能会逃跑去抓几块食物,他至少会尝试一下。调查这两种情况的结果:”
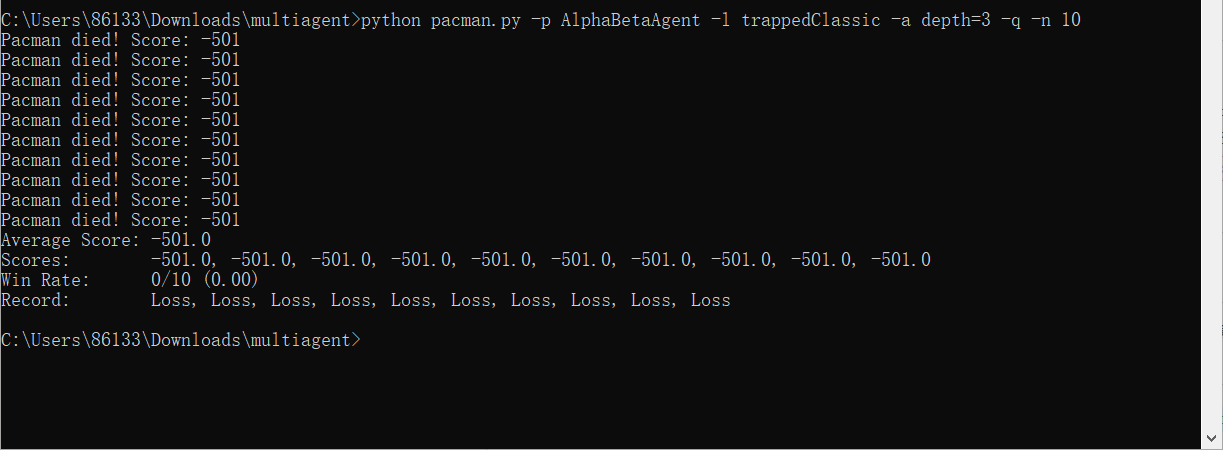
python pacman.py -p AlphaBetaAgent -l trappedClassic -a depth=3 -q -n 10
python pacman.py -p ExpectimaxAgent -l trappedClassic -a depth=3 -q -n 10
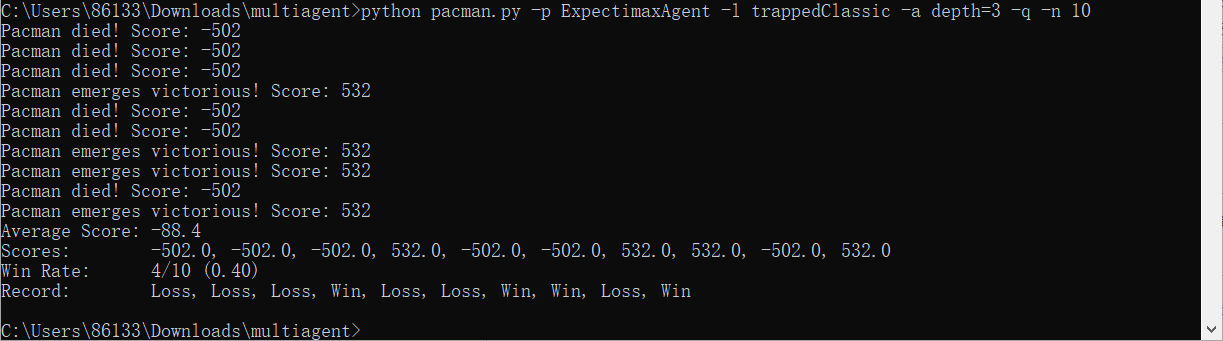
和预想中的相同,ExpectimaxAgent赢了大约一半的时间,而AlphaBetaAgent总是输。
Problem5:Evaluation Function评价函数
此题要求对Reflex Agent的代码进行改进,特别注意函数的参数发生了变化,此时我们只能观察到当前的状态,而无法得知下一个状态的信息。我们可以通过计算total这个值来表示 鬼怪保持可以被吃掉状态的剩余时间,由于通过吃掉地图上的大豆豆可以得到这个正反馈,所以吃豆人会考虑吃掉附近的大豆豆。最后把 计算好的各种启发值加在游戏得分上,并返回。
def betterEvaluationFunction(currentGameState):
"""
Your extreme ghost-hunting, pellet-nabbing, food-gobbling, unstoppable
evaluation function (question 5).
DESCRIPTION: <write something here so we know what you did>
"""
"*** YOUR CODE HERE ***"
#we only observe the current state and dont know the next state
#initialize information we could use
Pos = currentGameState.getPacmanPosition() #current position
Food = currentGameState.getFood() #current food
GhostStates = currentGameState.getGhostStates() #ghost state
ScaredTimes = [ghostState.scaredTimer for ghostState in GhostStates]
#find food and calculate positive reflection
if len(Food.asList())>0:
nearestFood = (min([manhattanDistance(Pos, food) for food in Food.asList()]))
foodScore = 9/nearestFood
else:
foodScore = 0
#find ghost and calculate negative reflection
nearestGhost = min([manhattanDistance(Pos,ghostState.configuration.pos) for ghostState in GhostStates])
dangerScore = -10/nearestGhost if nearestGhost!=0 else 0
#the rest time of ghost
totalScaredTimes = sum(ScaredTimes)
#return sum of all value
return currentGameState.getScore() + foodScore + dangerScore + totalScaredTimes
Abbreviation
better = betterEvaluationFunction
运行及截图:
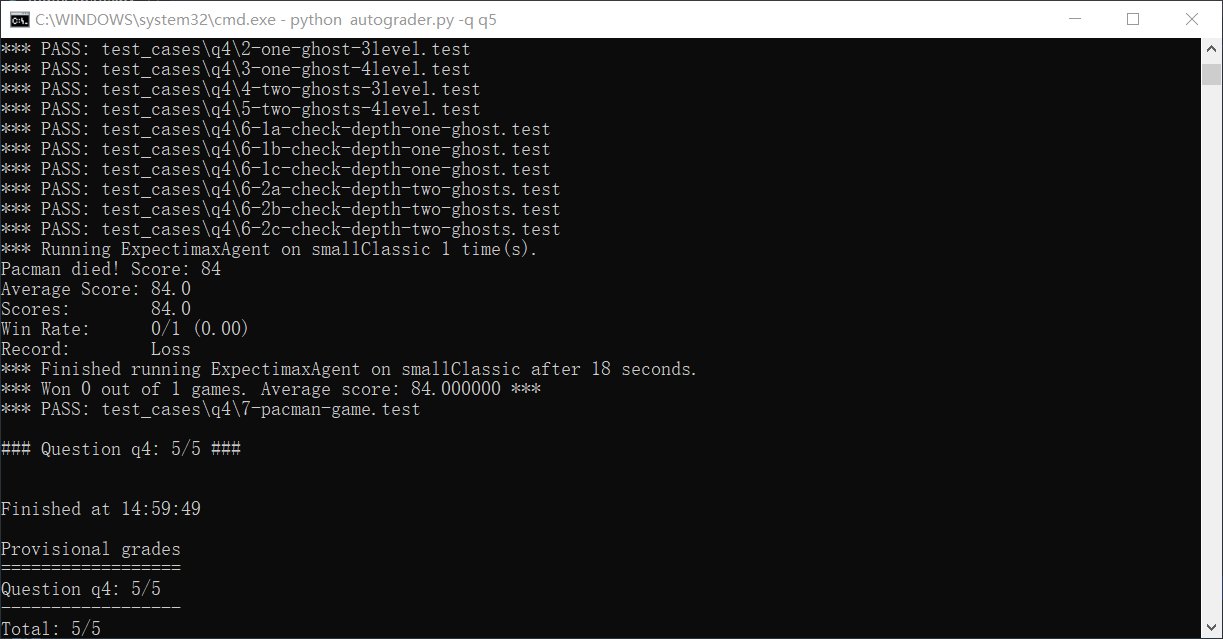
python autograder.py -q q5 --no-graphics
所学感悟
本次实验中,我能够在理解他人代码以及所学理论知识的基础上,对本游戏进行完成及实现,同时,也增加了我对对抗搜索知识体系的巩固。
参考链接
1、【人工智能导论】吃豆人游戏(上):对抗搜索与Minimax算法
2、敲代码学人工智能:对抗搜索问题
3、算法学习:Pac-Man的简单对抗
4、Berkeley Intro to AI学习笔记(一)MultiSearch
5、解析吃豆人游戏
Original: https://blog.csdn.net/weixin_45942927/article/details/120315999
Author: 夹小汁
Title: 【人工智能】UC Berkeley 2021春季 CS188 Project 2: Multi-Agent Search Pacman吃豆人游戏
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/720098/
转载文章受原作者版权保护。转载请注明原作者出处!