

论文提出新颖的轻量级通道注意力机制coordinate attention,能够同时考虑通道间关系以及长距离的位置信息。通过实验发现,coordinate attention可有效地提升模型的准确率,而且仅带来少量的计算消耗,十分不错
来源:晓飞的算法工程笔记 公众号
论文: Coordinate Attention for Efficient Mobile Network Design


; Introduction
目前,轻量级网络的注意力机制大都采用SE模块,仅考虑了通道间的信息,忽略了位置信息。尽管后来的BAM和CBAM尝试在降低通道数后通过卷积来提取位置注意力信息,但卷积只能提取局部关系,缺乏长距离关系提取的能力。为此,论文提出了新的高效注意力机制coordinate attention,能够将横向和纵向的位置信息编码到channel attention中,使得移动网络能够关注大范围的位置信息又不会带来过多的计算量。
coordinate attention的优势主要有以下几点:
- 不仅获取了通道间信息,还考虑了方向相关的位置信息,有助于模型更好地定位和识别目标。
- 足够灵活和轻量,能够简单地插入移动网络的核心结构中。
- 可以作为预训练模型用于多种任务中,如检测和分割,均有不错的性能提升。
Coordinate Attention
Coordinate Attention可看作增强移动网络特征表达能力的计算单元,接受中间特征X = [ x 1 , x 2 , ⋯ , x C ] ∈ R C × H × W X=[x_1,x_2,\cdots,x_C]\in\mathbb{R}^{C\times H\times W}X =[x 1 ,x 2 ,⋯,x C ]∈R C ×H ×W作为输入,输出与X X X大小相同的增强特征Y = [ y 1 , y 2 , ⋯ , y C ] Y=[y_1,y_2,\cdots,y_C]Y =[y 1 ,y 2 ,⋯,y C ]。
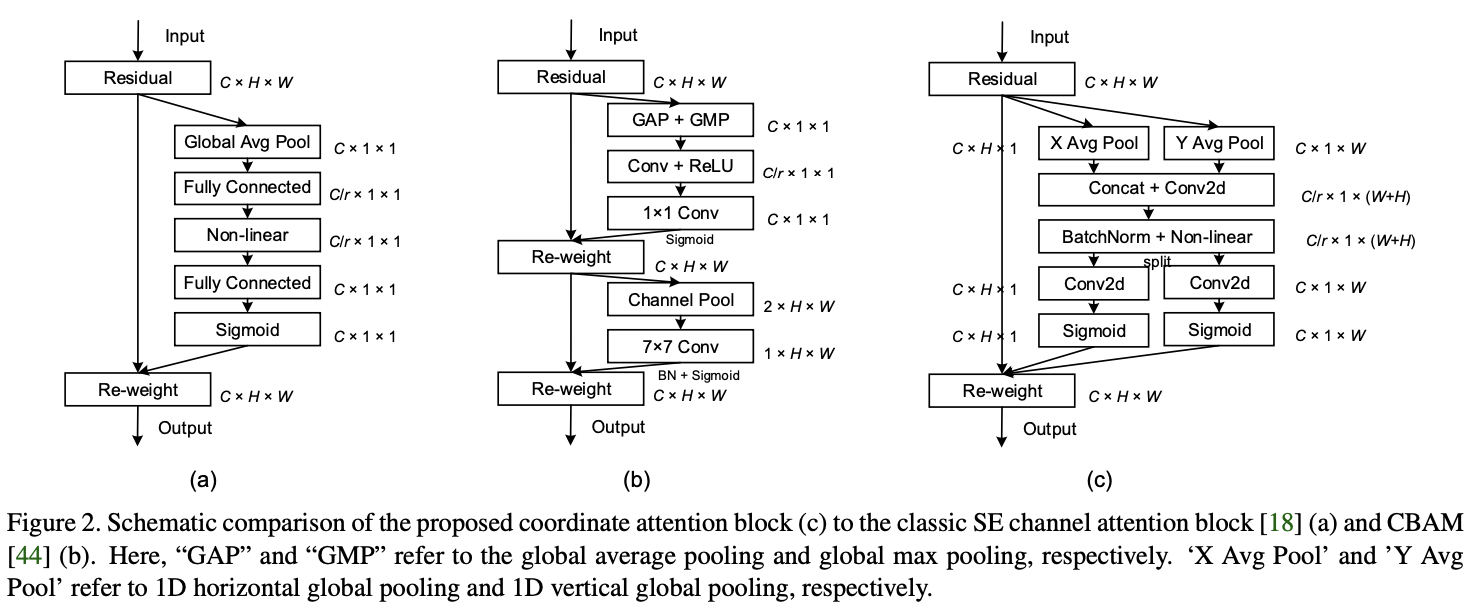
; Coordinate Attention Blocks
Coordinate Attention基于coordinate information embedding和coordinate attention generation两个步骤来编码通道关系和长距离关系。
- *Coordinate Information Embedding
channel attention常用全局池化编码全局空间信息,将全局信息压缩成一个标量,难以保留重要的空间信息。为此,论文将全局池化改造成两个1维向量的编码操作。对于输入X X X,使用池化核( H , 1 ) (H,1)(H ,1 )和( 1 , W ) (1,W)(1 ,W )来编码水平方向和垂直方向特征,即第c c c维特征的输出为:
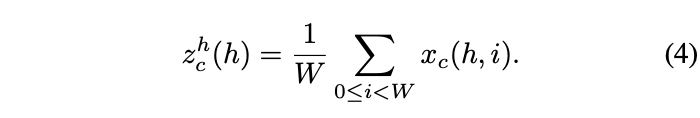

上面的公式从不同的方向集成特征,输出一对方向可知的特征图。对比全局池化的压缩方式,这样能够允许attention block捕捉单方向上的长距离关系同时保留另一个方向上的空间信息,帮助网络更准确地定位目标。
- *; Coordinate Attention Generation
为了更好地利用上述的coordinate infomation,论文提出了配套的coordinate attention generation操作,主要基于以下三点准则进行设计:
- 足够简单和轻量。
- 能完全利用提取的位置信息。
- 能同样高效地处理通道间的关系。
首先将公式4和公式5的输出concatenate起来,使用1 × 1 1\times 1 1 ×1卷积、BN和非线性激活进行特征转化:
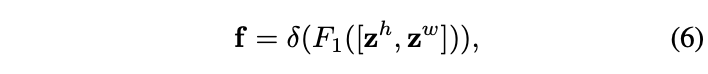
f ∈ R C / r × ( H + W ) f\in\mathbb{R}^{C/r\times(H+W)}f ∈R C /r ×(H +W )为包含横向和纵向空间信息的中间特征,r r r为缩减因子。这里两个方向的特征没有做激烈的融合,concatenate的主要目的我觉得是进行统一的BN操作。随后将f f f分为两个独立的特征f h ∈ R C / r × H f^h\in\mathbb{R}^{C/r\times H}f h ∈R C /r ×H和f w ∈ R C / r × W f^w\in\mathbb{R}^{C/r\times W}f w ∈R C /r ×W,使用另外两个1 × 1 1\times 1 1 ×1卷积和sigmoid函数进行特征转化,使其维度与输入X X X一致:
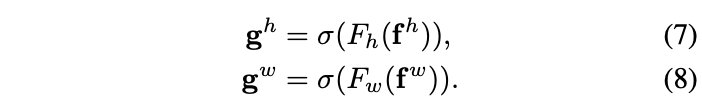
将输出g h g^h g h和g w g^w g w合并成权重矩阵,用于计算coordinate attention block输出:
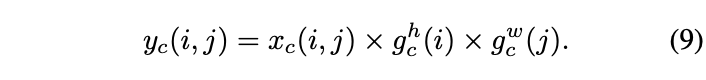
coordinate attention block与se block的最大区别是,coordinate attention block的每个权重都包含了通道间信息、横向空间信息和纵向空间信息,能够帮助网络更准确地定位目标信息,增强识别能力。
Implementation
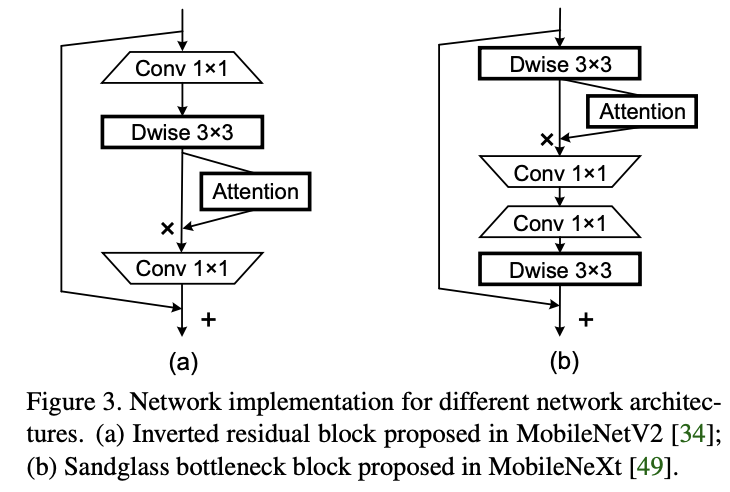
将coordinate attention block应用于MobileNetV2和MobileNeXt上,block结构如图3所示。
; Experiment

基于MobileNetV2进行模块设置的对比实验。
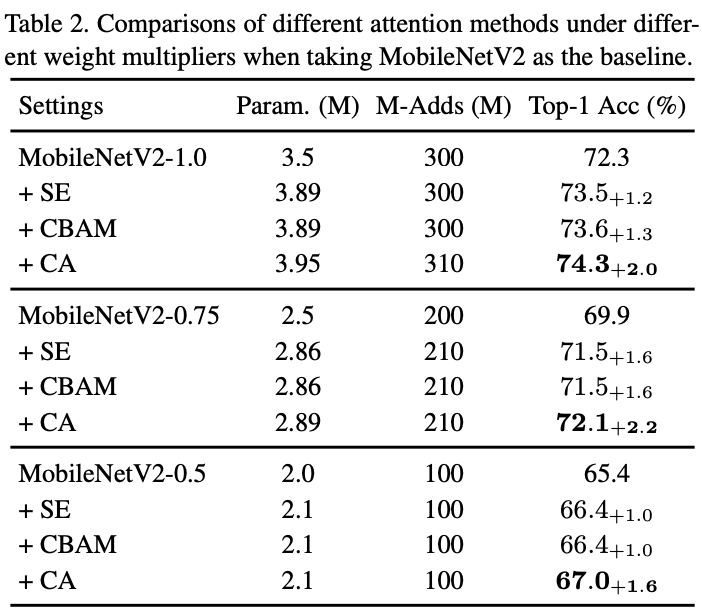
不同注意力结构在不同主干网络上的性能对比。
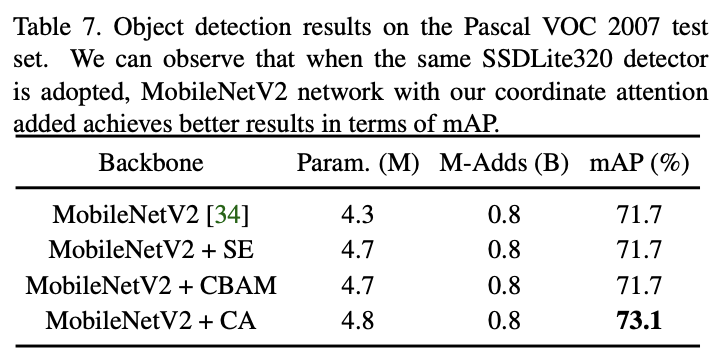
对目标检测网络的性能对比。
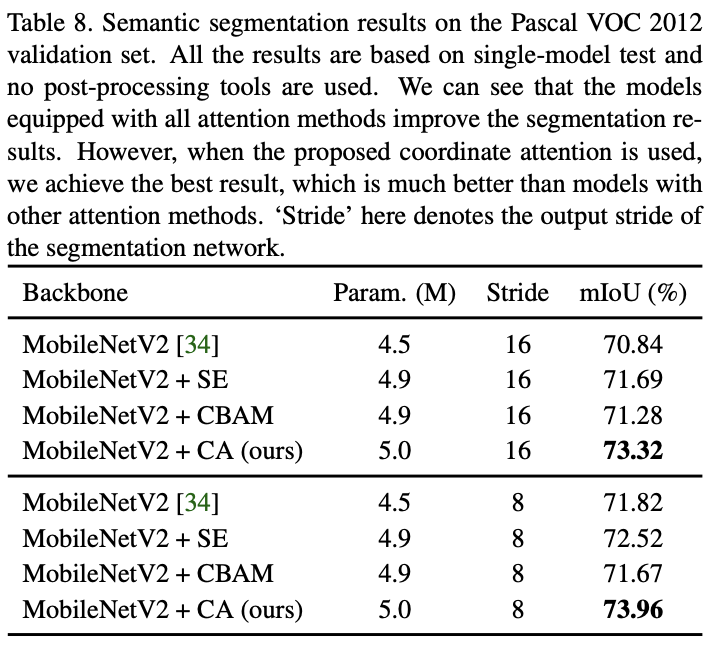
对语义分割任务的性能对比。
Conclusion
论文提出新颖的轻量级通道注意力机制coordinate attention,能够同时考虑通道间关系以及长距离的位置信息。通过实验发现,coordinate attention可有效地提升模型的准确率,而且仅带来少量的计算消耗,十分不错。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

Original: https://blog.csdn.net/lichlee/article/details/125596913
Author: 晓飞的算法工程笔记
Title: CA:用于移动端的高效坐标注意力机制 | CVPR 2021
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/719881/
转载文章受原作者版权保护。转载请注明原作者出处!