

目录
1.1 高斯金字塔 ( Gaussian pyramid):
1.2 拉普拉斯金字塔(Laplacian pyramid)
4.1 FPN(Feature Pyramid Networks)的结构
1.什么是图像金字塔
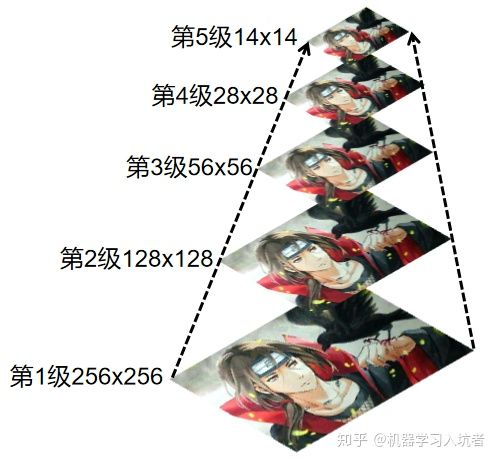
图像金字塔是图像中多尺度表达的一种,最主要用于图像的分割,是 一种以多分辨率来解释图像的有效但概念简单的结构。图像金字塔最初用于机器视觉和图像压缩,一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。

获得图像金字塔一般包括二个步骤:
-
利用低通滤波器平滑图像
-
对平滑图像进行抽样(采样)
有两种采样方式——上采样(分辨率逐级升高)和下采样(分辨率逐级降低)
上采样:

下采样:

常见两类图像金字塔
1.1 高斯金字塔 ( Gaussian pyramid):
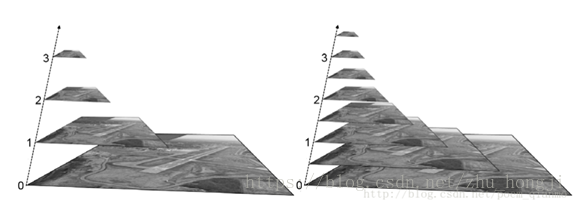
用来向下/降采样,主要的图像金字塔, 高斯金字塔是通过高斯平滑和亚采样获得一系列下采样图像,也就是说第K层高斯金字塔通过平滑、亚采样就可以获得K+1层高斯图像,高斯金字塔包含了一系列低通滤波器,其截至频率从上一层到下一层是以因子2逐渐增加,所以高斯金字塔可以跨越很大的频率范围。金字塔的图像如下:
上图中最下层是原始的图像, 越靠上的层图像尺寸越小,这一组图像就被称为高斯金字塔(在某些资料中,下采样之前需要 首先进行高斯滤波

可以看出,随着下采样的进行,图像的分辨率不断降低,视觉效果也越来越模糊。
对图像的向下取样操作,即缩小图像。
为了获取层级为 G_i+1 的金字塔图像,方法步骤如下:
得到的图像即为G_i+1的图像,显而易见,结果图像只有原图的四分之一。通过对输入图像G_i(原始图像)不停迭代以上步骤就会得到整个金字塔。同时我们也可以看到,向下取样会逐渐丢失图像的信息。以上就是对图像的向下取样操作,即缩小图像。
对图像的向上取样,即放大图像
方法步骤如下:
得到的图像即为放大后的图像,但是与原来的图像相比会发觉比较模糊,因为在缩放的过程中已经丢失了一些信息, 如果想在缩小和放大整个过程中减少信息的丢失,这些数据形成了拉普拉斯金字塔。上述的上采样和下采样的过程是一个非逆向过程。
如果高斯金字塔中任意一张图Gi(比如G0为最初的高分辨率图像)先进行下采样得到图Down(Gi),再进行上采样得到图Up(Down(Gi)),得到的Up(Down(Gi))与Gi是存在差异的, 因为下采样过程丢失的信息不能通过上采样来完全恢复,也就是说下采样是不可逆的。
下面展示了一张图先进行下采样,再进行上采样的过程:

可以看出,原始图片下采样后得到的小尺寸图片虽然保留了视觉效果,但是将该小尺寸图像再次上采样也不能完整的恢复出原始图像。
1.2 拉普拉斯金字塔(Laplacian pyramid)
如果想在缩小和放大整个过程中减少信息的丢失,这些数据形成了拉普拉斯金字塔。拉普拉斯金字塔是通过源图像减去先缩小后再放大的图像的一系列图像构成的。保留的是残差!为图像还原做准备!因此拉普拉斯金字塔可以认为是残差金字塔, 用来存储下采样后图片与原始图片的差异!
下面展示了一张图先进行下采样,再进行上采样的过程:
可以看出,原始图片下采样后得到的小尺寸图片虽然保留了视觉效果,但是将该小尺寸图像再次上采样也不能完整的恢复出原始图像。为了能够从下采样图像Down(Gi)中还原原始图像Gi,我们需要记 录再次上采样得到Up(Down(Gi))与原始图片Gi之间的差异,这就是拉普拉斯金字塔的核心思想,下面最右边的图展示了这种差异(为了效果明显我进行了伽马矫正):

拉普拉斯金字塔就是 记录高斯金字塔每一级下采样后再上采样与下采样前的差异,目的是为了能够完整的恢复出每一层级的下采样前图像。下面的公式就是前面的差异记录过程:
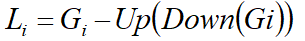

因此高斯金字塔用来向下降采样图像,注意降采样其实是由金字塔底部向上采样,分辨率降低,它和我们理解的金字塔概念相反(注意);而拉普拉斯金字塔则用来从金字塔底层图像中向上采样重建一个图像。
1.3 DOG金字塔
差分金字塔,DOG(Difference of Gaussian)金字塔是在高斯金字塔的基础上构建起来的,其实生成高斯金字塔的目的就是为了构建DOG金字塔。
DOG金字塔的第1组第1层是由高斯金字塔的第1组第2层减第1组第1层得到的。以此类推,逐组逐层生成每一个差分图像,所有差分图像构成差分金字塔。概括为DOG金字塔的第o组第l层图像是有高斯金字塔的第o组第l+1层减第o组第l层得到的。
DOG金字塔的构建可以用下图描述:
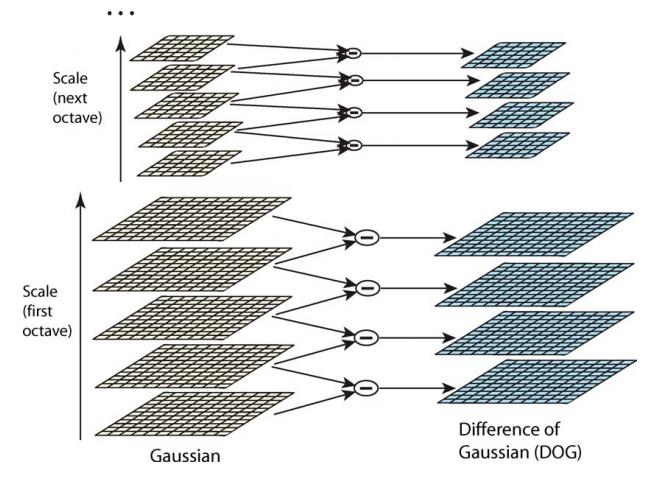
下边 对这些DOG图像进行归一化,可有很明显的看到差分图像所蕴含的特征,并且有一些特征是在不同模糊程度、不同尺度下都存在的,这些特征正是Sift所要提取的”稳定”特征:
- 多尺度网络(MTCNN)
卷积神经网络通过逐层抽象的方式来提取目标的特征,其中一个重要的概念是感受野,如果感受野太小,只能观察到局部的特征,如果感受野太大,则获得过多无效的特征。因此研究员一直都在设计各种各样的尺度模型架构。用于综合不同感受野和粒度下的特征。通常采用的是图像金字塔和特征金字塔这两种方案。具体的网络结构可以分成一下几种:
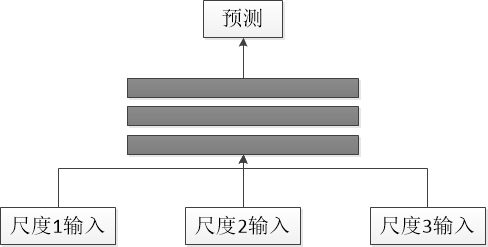
2.1 多尺度输入网络
多尺度输入网络就是使用多个尺度的图像(图像金字塔)作为输入,如下图所示,然后对其结果进行融合,传统的人脸检测算法V-J框架采用的就是这样的思路。深度学习网络模型MTCNN人脸检测算法也是使用的这样的思路。
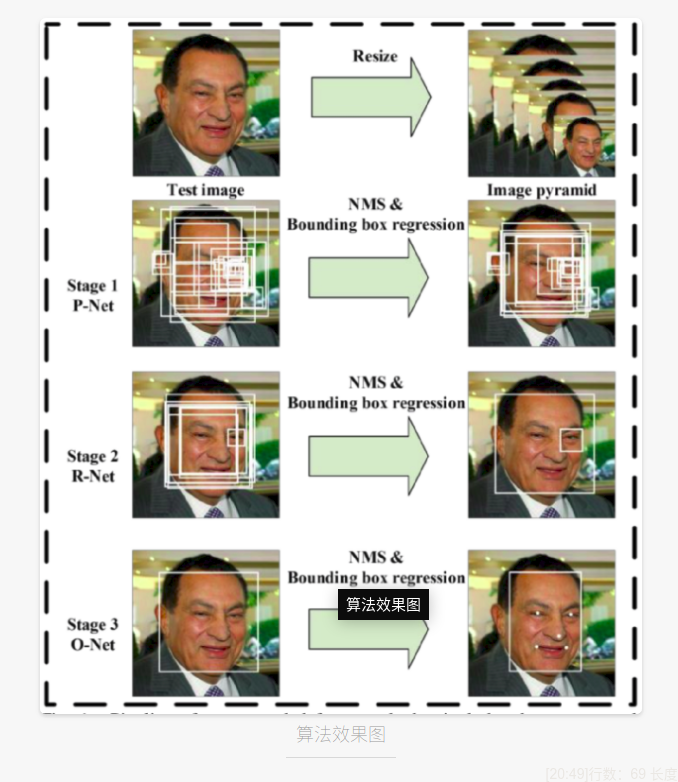
下面详细介绍一下MTCNN神经网络。 MTCNN,Multi-task convolutional neural network(多任务卷积神经网络),将人脸区域检测与人脸关键点检测放在了一起,它的主题框架类似于cascade。总体可分为P-Net、R-Net、和O-Net三层网络结构。
它是2016年中国科学院深圳研究院提出的用于人脸检测任务的多任务神经网络模型,该模型主要采用了 三个级联的网络,采用 候选框加分类器的思想,进行快速高效的人脸检测。这三个级联的网络分别是快速生成 候选窗口的P-Net、进行 高精度候选窗口过滤选择的R-Net和 生成最终边界框与 人脸关键点的O-Net。和很多处理图像问题的卷积神经网络模型,该模型也用到了图像金字塔、边框回归、非最大值抑制等技术。 具体的实现过程为:
构建图像金字塔
首先将图像进行不同尺度的变换,构建图像金字塔,以适应不同大小的人脸的进行检测。
P-Net
全称为Proposal Network,其基本的构造是一个全卷积网络。对上一步构建完成的图像金字塔,通过一个 _FCN_进行初步特征提取与标定边框,并进行 _Bounding-Box Regression_调整窗口与 _NMS_进行大部分窗口的过滤。
P-Net是一个人脸区域的区域建议网络,该网络的将特征输入结果三个卷积层之后,通过一个人脸分类器判断该区域是否是人脸,同时使用边框回归和一个面部关键点的定位器来进行人脸区域的初步提议,该部分最终将输出很多张可能存在人脸的人脸区域,并将这些区域输入R-Net进行进一步处理。
这一部分的基本思想是使用较为浅层、较为简单的CNN快速生成人脸候选窗口。

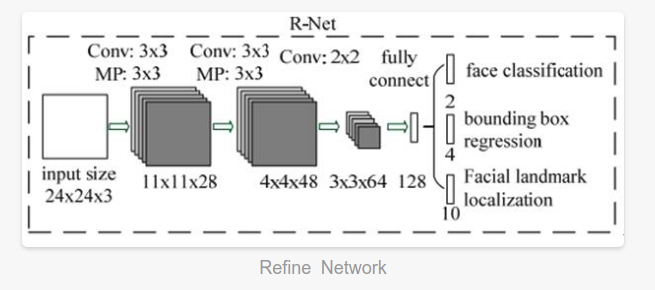
R-Net
全称为Refine Network,其基本的构造是一个卷积神经网络,相对于第一层的P-Net来说,增加了一个全连接层,因此对于输入数据的筛选会更加严格。在图片经过P-Net后,会留下许多预测窗口,我们将所有的预测窗口送入R-Net,这个网络会滤除大量效果比较差的候选框,最后对选定的候选框进行Bounding-Box Regression和NMS进一步优化预测结果。
R-Net的思想是使用一个相对于P-Net更复杂的网络结构来对 P-Net 生成的可能是人脸区域区域窗口进行进一步选择和调整,从而达到高精度过滤和人脸区域优化的效果。
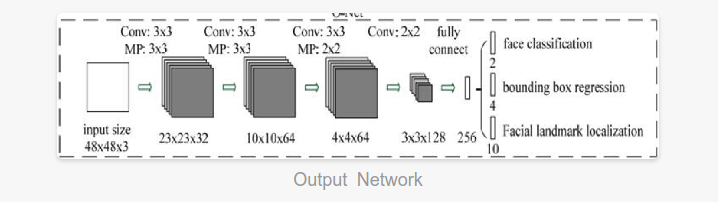
O-Net
O-Net的思想和R-Net类似,使用更复杂的网络对模型性能进行优化
下面是整个系统的工作流图
2.2 多尺度特征融合网络
多尺度特征融合网络常见的是两种结构,一种是并行多分支网络(图1),一种是串行的跳层连接网络图2。
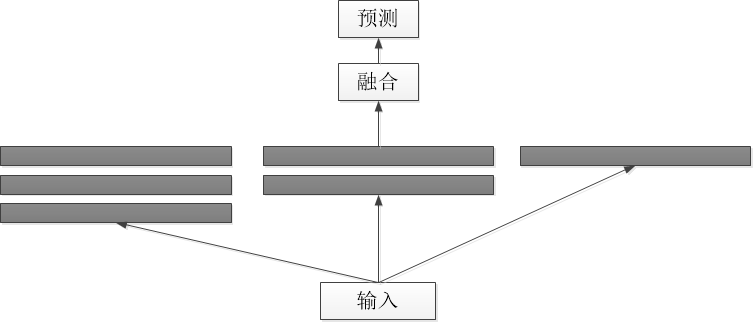
图 1 并行多分支网络
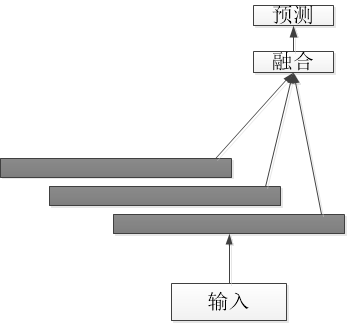
图 2 串行的跳层连接网络
2.2.1 并行多分支网络
1)Inception结构
并行多分支网络通常包含感受野不同的卷积核,最为典型的结构为Inception结构,如图所示分别使用11 的卷积,33的卷积,55的卷积和33的最大池化。该结构将这四个分支对输入分别提取特征后进行融合,然后作为下一层的特征输入。

Inception结构
2) PSPNet 结构(图像分割中使用)
PSPNet 直接使用不同大小的池化操作,核心模块是金字塔池化模块( pyramid pooling module),它能够聚合不同区域的上下文信息,从而提高获取全局信息的能力。实验表明这样的先验表示(即指代PSP这个结构)是有效的,在多个数据集上展现了优良的效果。
PSPNet的整体架构如下:
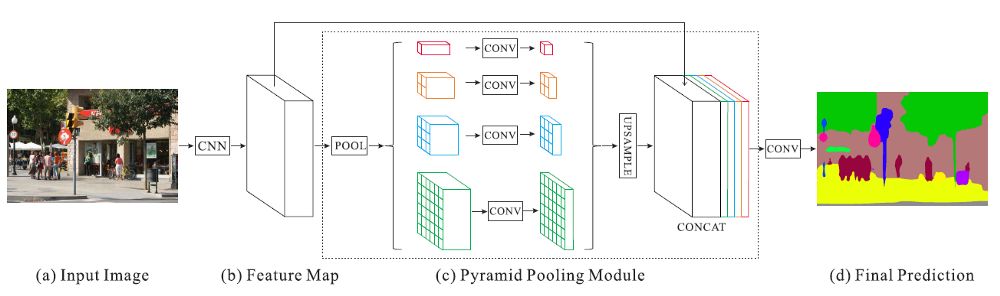
该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1×1的卷积将对于级别通道降为原本的1/N。再通过双线性插值获得未池化前的大小,最终concat到一起。
金字塔等级的池化核大小是可以设定的,这与送到金字塔的输入有关。论文中使用的4个等级,核大小分别为1×1,2×2,3×3,6×6;
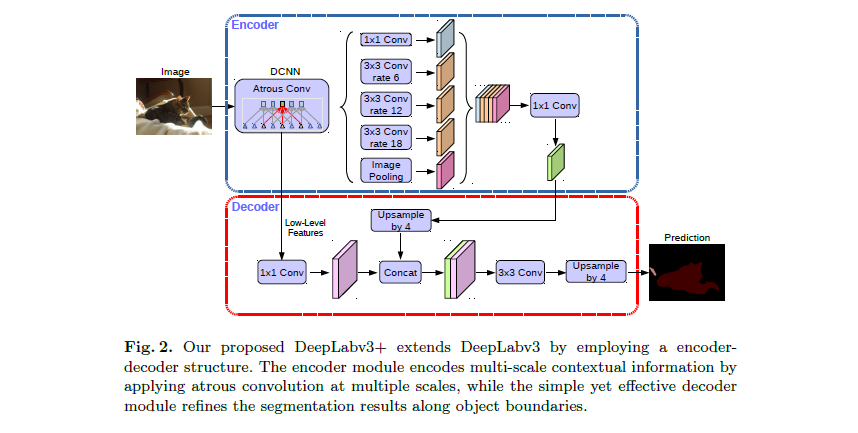
3)DeeplabV3结构(图像分割中使用)
和 Inception结构不同的地方主要是使用空洞卷积控制感受野,DeepLab v3+将特征提取阶段最后几个layer的conv(图片中黄色部分)变成了 dilated conv,使分辨率不再降低,但增大感受野。也就是说这样在保留位置信息的同时,语义信息保持不变。
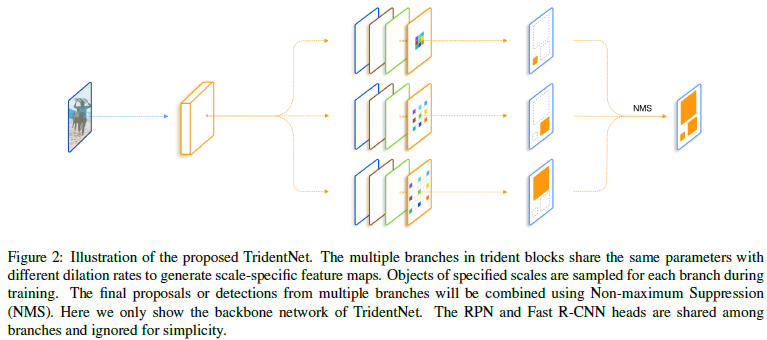
4)Trident Network(目标检测模型)
Trident network的网络结构如下,显然,叫做”三叉戟网络”就名副其实了。由图中可以看出,三个分支从上到下对应的 Dilation系数逐渐增大,因此对应的目标尺寸也逐渐增大。即第一个分支用来检测小目标,第二个分支用来检测中等目标,第三个分支用来检测大目标,其和 DeeplabV3网络一样,也是通过dilated conv(空洞卷积),使分辨率不再降低,但增大感受野。
2.2.2 串行的跳层连接网络
串行的跳层连接网络以FCN为代表,FCN的运行原理:将一张任意尺寸的图片输入到FCN中,首先经过卷积得到特征图(因为该特征图非常小,故可以称为热图),然后 运用反卷积和跳级的方法,还原出与输入图片尺寸相同的特征图,将该特征图与原始图像对比,实现了每个像素的预测,保留了原始输入图像中的空间信息。
整体的运行流程如下所示:

跳级的思想:
前面提到了”放大”、”缩小”的两个卷积过程,可是根据实际操作发现, 一步直接将”缩小”后特征图放大效果非常不好,有很多图片的细节没有办法体现。于是作者提出了跳级的思想。

所谓跳级,也就是 分步将特征图”放大”。可以看到图中有三种”放大”的策略,它们分别是FCN-32s,FCN-16s,FCN-8s。而且FCN中对特征图的放大一共是32倍(原因是2的8次方)。
我们以FCN-8s为例讲解跳级思想,首先将1 × 1特征图上采样2倍,然后与之前特征图尺寸相同的相加,得到新的上采样2倍特征图。
新的上采样2倍的特征图继续上采样2倍,然后与之前特征图尺寸相同的相加,得到新的上采样4倍的特征图。
之后,特征图不再与之前的特征图相加,以2倍的上采样不断进行,直到采样的总倍数为32倍。所以跳级的精华在于与之前的特征图相融合,可以更好的利用底层位置信息和高层语义信息。
下图详细的介绍了网路的连接结构
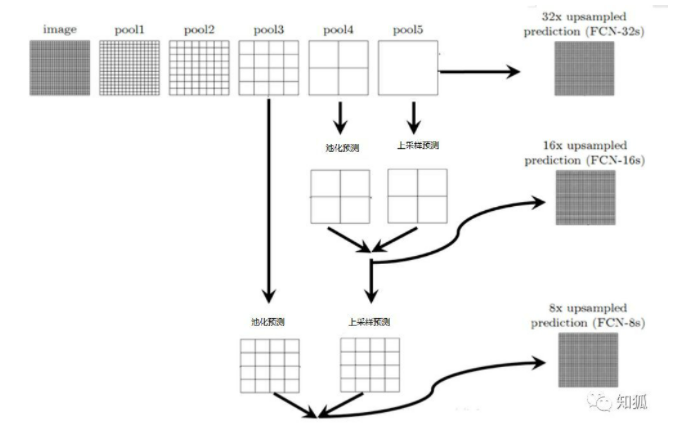
图中,image是原图像,conv1,conv2..,conv5为卷积操作,pool1,pool2,..pool5为pool操作(pool就是使得图片变为原图的1/2),注意con6-7是最后的卷积层,最右边一列是upsample后的end to end结果。必须说明的是图中nx是指对应的特征图上采样n倍(即变大n倍),并不是指有n个特征图,如32x upsampled 中的32x是图像只变大32倍,不是有32个上采样图像,又如2x conv7是指conv7的特征图变大2倍。
3,多尺度特征预测融合网络
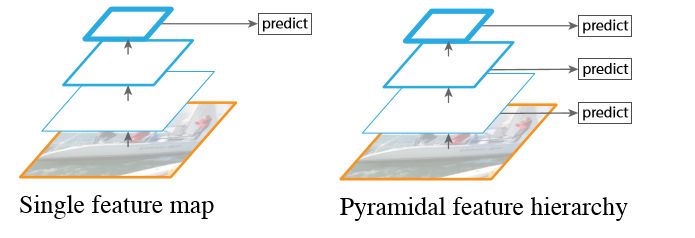
多尺度特征预测融合网络即在不同的特征尺度进行预测,最后将结果进行融合如下图所示,目标检测SSD为其主要的代表网络。
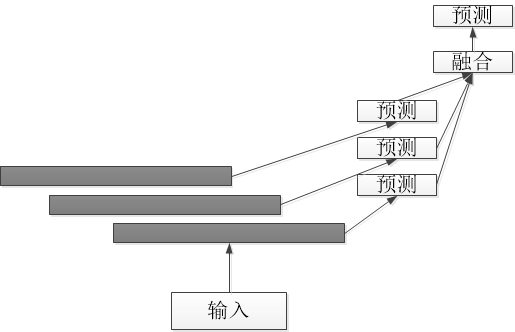
单层feature map预测和特征金字塔预测对比
3.1 SSD 网络
最基础的SSD网络是以Vgg16作为backbone(主干网), 输入图片尺寸为300×300,SSD(Single Shot MultiBox Detector)检测网络可概括为三个特征:one-stage检测器,多个尺度的特征图检测(MultiBox),大量的先验框(Prior Boxes)。相比于YoLo和Faster-RCNN,在准确度和速度上进行了折衷。
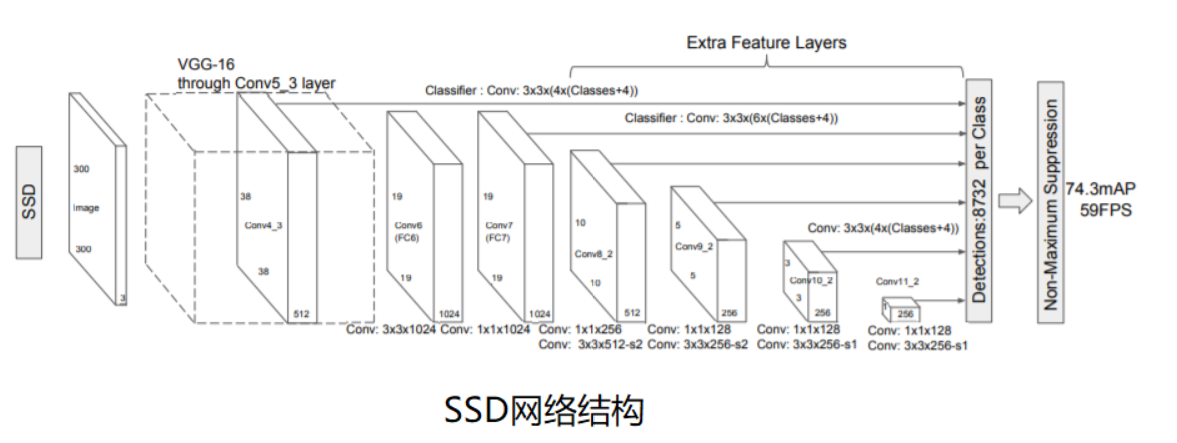
模型计算流程:
- 模型通过Base部分得到两个特征图(1, 512, 38, 38)和(1, 1024, 19, 19)
- 通过extra部分得到四个特征图(1, 512, 10, 10),(1, 256, 5, 5),(1, 256, 3, 3)和(1, 256, 1, 1)
- 这6个特征图再通过class_predictors和box_predictors分别得到置信度和坐标:
*(1, 512, 38, 38) =》 (1, 4×4, 38, 38) 和 (1, 4×21, 38, 38) (1, 1024, 19, 19) =》 (1, 6×4, 19, 19) 和 (1, 6×21, 19, 19) (1, 512, 10, 10) =》 (1, 6×4, 10, 10) 和 (1, 6×21, 10, 10) (1, 256, 5, 5) =》 (1, 6×4, 5, 5) 和 (1, 6×21, 5, 5) (1, 256, 3, 3) =》 (1, 4×4, 3, 3) 和 (1, 4×21, 3, 3) (1, 256, 1, 1) =》 (1, 4×4,1, 1) 和 (1, 4×21, 1, 1)
- 最终得到所有预测框的loc:(1, 8732, 4)和conf:(1, 8732, 21)
训练阶段
- 输出所有预测框的loc_p:(1, 8732, 4),con_p:(1, 8732, 21)和先验框anchors:(8732, 4);结合gt_box, gt_id计算loss
测试阶段
- 根据先验框anchors和预测box偏移值,计算真实box坐标值和类别置信度,经过NMS,最后输出预测的box坐标值和置信度
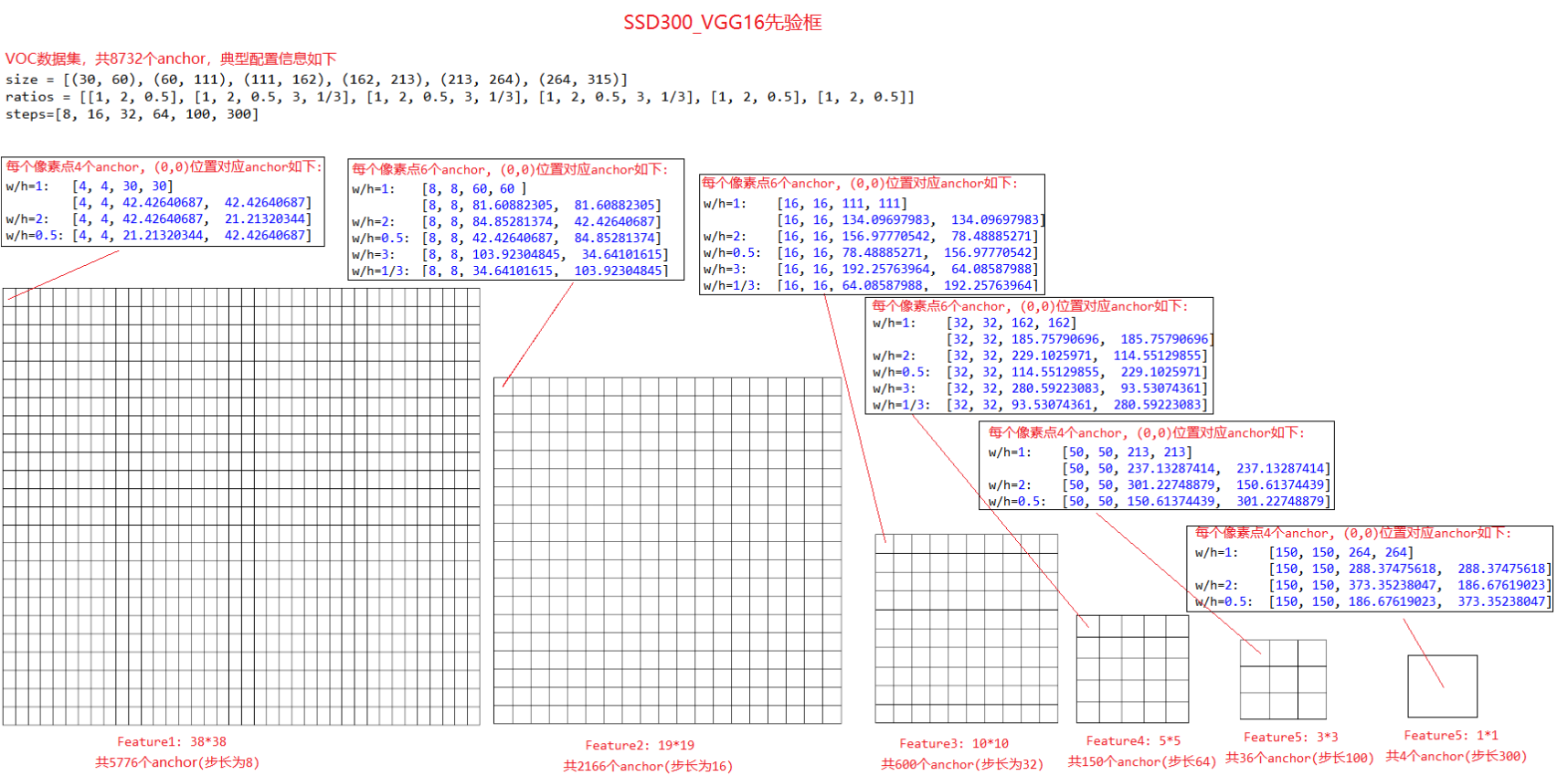
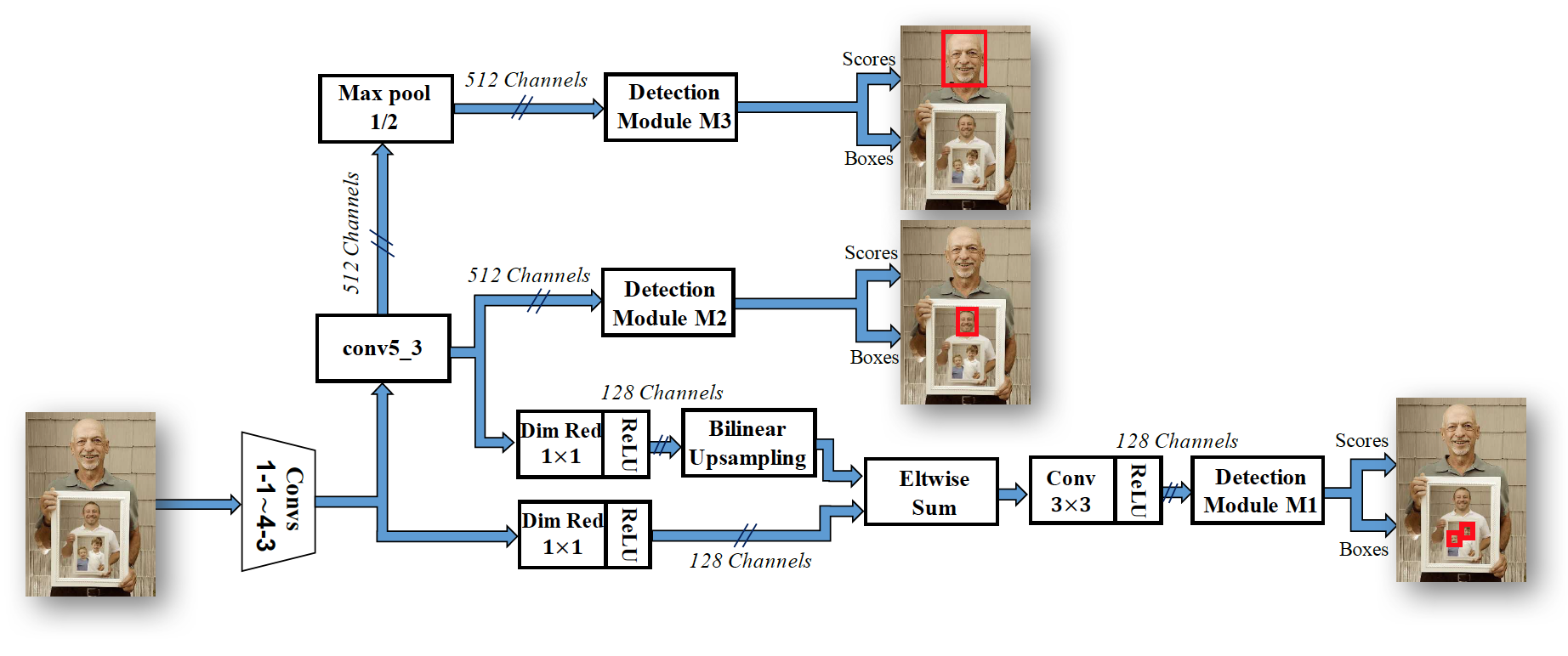
3.2 SSH 网络
骨干网络: VGG-16
工作原理如下图所示:

4,多尺度特征和预测融合网络
这种机制就是将第2章还有第三章的两种方法的融合,将两种机制融合在一起,特征提取可以多尺度同时预测也可以多尺度。该网络较为经典的网络是FPN(目标检测网络),该网络将高层特征添加到相邻的低层组成新的特征,然后进行预测。
4.1 不同多尺度特征及预测方式的对比
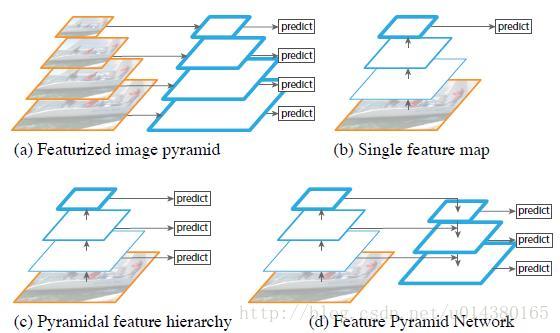
下图FIg1展示了4种利用特征的形式:
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
(b)像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。
(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d)FPN采用顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
4.1 FPN(Feature Pyramid Networks)的结构
通过图像金字塔来构建不同尺度的特征金字塔。主要解决的问题是目标检测在处理多尺度变化问题是的不足,现在的很多网络都使用了利用单个高层特征(比如说Faster R-CNN利用下采样四倍的卷积层——Conv4,进行后续的物体的分类和bounding box的回归),但是这样做有一个明显的缺陷,即小物体本身具有的像素信息较少,在下采样的过程中极易被丢失,为了处理这种物体大小差异十分明显的检测问题,经典的方法是利用图像金字塔的方式进行多尺度变化增强,但这样会带来极大的计算量。所以这篇论文提出了特征金字塔的网络结构,能在增加极小的计算量的情况下,处理好物体检测中的多尺度变化问题。FPN是一种具有侧向连接(lateral connections)的自上而下的网络结构,用来构建不同尺寸的具有高级语义信息的特征图。
FPN主网络采用ResNet,算法大致结构如下图: 一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
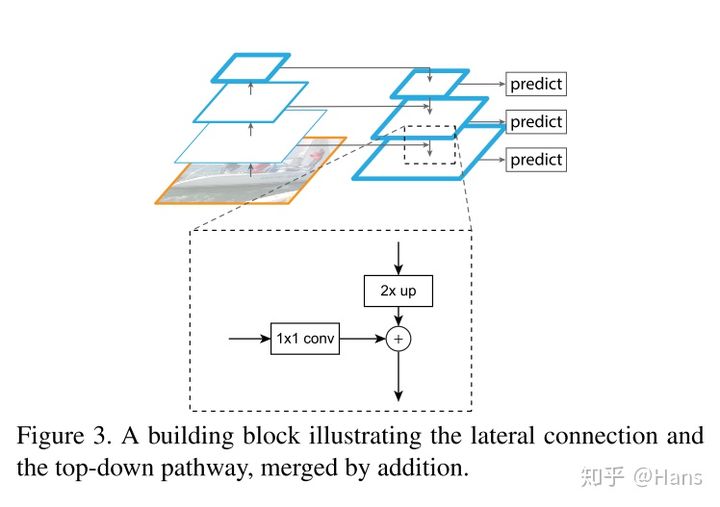
自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
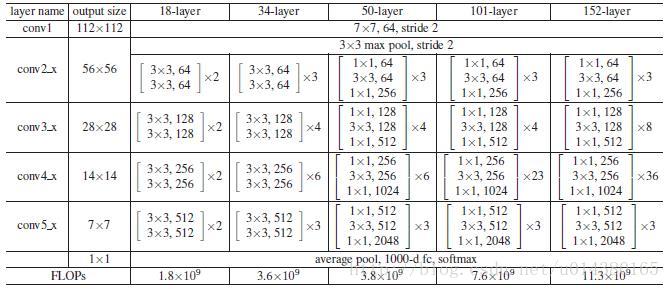
贴一个 ResNet的结构图:这里作者采用Conv2,CONV3,CONV4和CONV5的输出。因此类似Conv2就可以看做一个stage。
4.2 FPN训练过程
作者一方面将FPN放在RPN网络中用于生成proposal,原来的RPN网络是以主网络的某个卷积层输出的feature map作为输入,简单讲就是只用这一个尺度的feature map。但是现在要将FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于P2,P3,P4,P5,P6这些层,定义anchor的大小为32^2,64^2,128^2,256^2,512^2,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor。
正负样本的界定和Faster RCNN差不多:如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
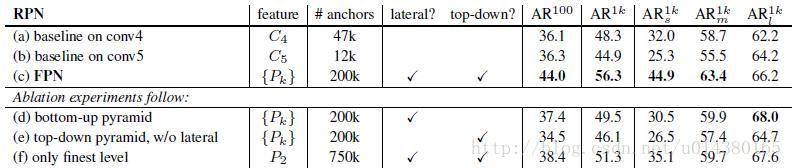
看看 加入FPN的RPN网络的有效性,如下表Table1。网络这些结果都是基于ResNet-50。评价标准采用AR,AR表示Average Recall,AR右上角的100表示每张图像有100个anchor,AR的右下角s,m,l表示COCO数据集中object的大小分别是小,中,大。feature列的大括号{}表示每层独立预测。
FPN参考博文:FPN全解-最全最详细_baidu_30594023的博客-CSDN博客_fpn
Original: https://blog.csdn.net/YOULANSHENGMENG/article/details/121230235
Author: YOULANSHENGMENG
Title: 深度学习笔记—多尺度网络结构归类总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/719461/
转载文章受原作者版权保护。转载请注明原作者出处!