

1 Actor Critic算法简介
1.1 为什么要有Actor Critic
Actor-Critic的Actor的前身是Policy Gradient,这能让它毫不费力地在连续动作中选取合适的动作,而Q-Learning做这件事会瘫痪,那为什么不直接用Policy Gradient呢,原来Actor-Critic中的Critic的前身是Q-Learning或者其他的以值为基础的学习法,能进行单步更新,而更传统的Policy Gradient则是回合更新,这降低了学习效率。
现在我们有两套不同的体系,Actor和Critic,他们都能用不同的神经网络来代替。现实中的奖惩会左右Actor的更新情况。Policy Gradient也是靠着这个来获取适宜的更新。那么何时会有奖惩这种信息能不能被学习呢?这看起来不就是以值为基础的强化学习方法做过的事吗。那我们就拿一个Critic去学习这些奖惩机制,学习完了以后,由Actor来指手画脚,由Critic来告诉Actor你的哪些指手画脚哪些指得好,哪些指得差,Critic通过学习环境和奖励之间的关系,能看到现在所处状态的潜在奖励,所以用它来指点Actor便能使Actor每一步都在更新,如果使用单纯的Policy Gradient,Actor只能等到回合结束才能开始更新。
但是事务始终有它坏的一面,Actor-Critic设计到了两个神经网络,而且每次都是在连续状态中更新参数,每次参数更新前后都存在相关性,导致神经网络只能片面的看待问题,甚至导致神经网络学不到东西。Google DeepMind为了解决这个问题,修改了Actor-Critic的算法。
1.2 改进版Deep Deterministic Policy Gradient(DDPG)
将之前在电动游戏Atari上获得成功的DQN网络加入进Actor-Critic系统中,这种新算法叫做Deep Deterministic Policy Gradient,成功的解决在连续动作预测上的学不到东西的问题。
文章【强化学习】Deep Deterministic Policy Gradient(DDPG)算法详解一文对该算法有详细的介绍,文章链接:https://blog.csdn.net/shoppingend/article/details/124344083?spm=1001.2014.3001.5502
2 Actor-Critic算法详解
2.1 要点
一句话概括Actor-Critic算法:结合了Policy Gradient(Actor)和Function Approximation(Critic)的方法。Actor基于概率选行为,Critic基于Actor的行为评判行为的得分,Actor根据Critic的评分修改选行为的概率。
Actor-Critic方法的优势:可以进行单步更新,比传统的Policy Gradient要快。
Actor-Critic方法的劣势:取决于Critic的价值判断,但是Critic难收敛,再加上Actor的更新,就更难收敛,为了解决这个问题,Google Deepmind提出了Actor-Critic升级版Deep Deterministic Policy Gradient。后者融合了DQN的优势,解决了收敛难得问题。
2.2 算法
这套算法是在普通的Policy Gradient算法上面修改的,如果对Policy Gradient算法不是很了解,可以点这里https://blog.csdn.net/shoppingend/article/details/124297444?spm=1001.2014.3001.5502了解一下。
这套算法打个比方:Actor修改行为时就像蒙着眼睛一直向前开车,Critic就是那个扶方向盘改变Actor开车方向的。
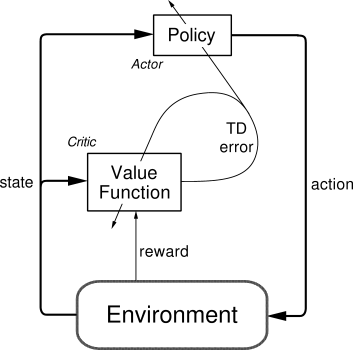

或者说详细点,就是Actor在运用Policy Gradient的方法进行Gradient ascent的时候,由Critic来告诉他,这次的Gradient ascent是不是一次正确的ascent,如果这次的得分不好,那么就不要ascent这么多。
; 2.3 代码主结构
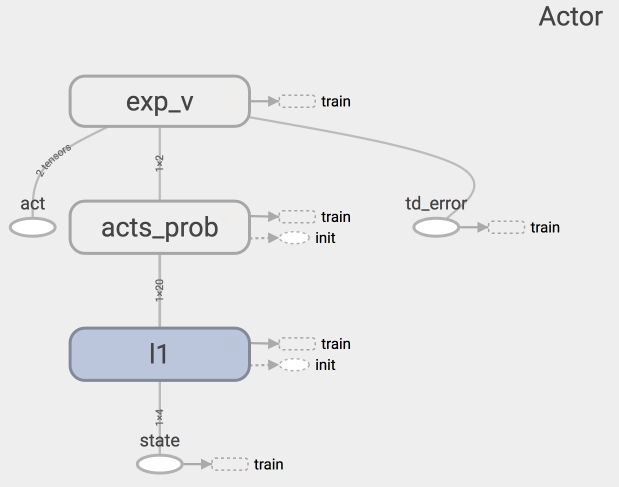
上面是Actor的神经网络结构,代码结构如下:
class Actor(object):
def __init__(self, sess, n_features, n_actions, lr=0.001):
def learn(self, s, a, td):
def choose_action(self, s):
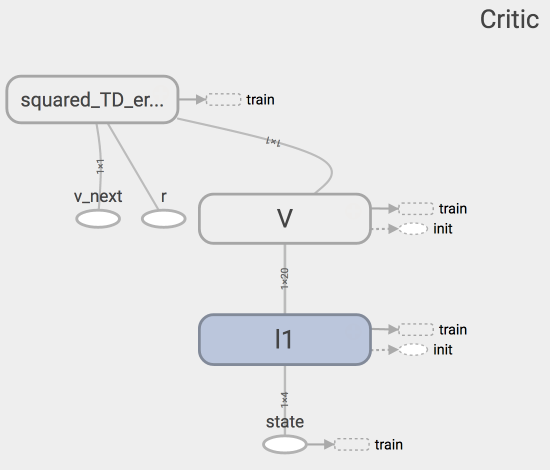
上面是Critic的神经网络结构,代码结构如下:
class Critic(object):
def __init__(self, sess, n_features, lr=0.01):
def learn(self, s, r, s_):
return
2.4 两者学习方式
Actor 想要最大化期望的reward,在Actor-Critic算法中,我们用”比平时好多少”(TDerror)来当作reward,所以就是:
with tf.variable_scope('exp_v'):
log_prob = tf.log(self.acts_prob[0, self.a])
self.exp_v = tf.reduce_mean(log_prob * self.td_error)
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v)
Critic的更新更简单,就是像Q-Learning那样更新现实和估计的误差(TDerror)就好。
with tf.variable_scope('squared_TD_error'):
self.td_error = self.r + GAMMA * self.v_ - self.v
self.loss = tf.square(self.td_error)
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
2.5 每回合算法
for i_episode in range(MAX_EPISODE):
s = env.reset()
t = 0
track_r = []
while True:
if RENDER: env.render()
a = actor.choose_action(s)
s_, r, done, info = env.step(a)
if done: r = -20
track_r.append(r)
td_error = critic.learn(s, r, s_)
actor.learn(s, a, td_error)
s = s_
t += 1
if done or t >= MAX_EP_STEPS:
ep_rs_sum = sum(track_r)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.95 + ep_rs_sum * 0.05
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True
print("episode:", i_episode, " reward:", int(running_reward))
break
文章来源:莫凡强化学习h ttps://mofanpy.com/tutorials/machine-learning/reinforcement-learning/
Original: https://blog.csdn.net/shoppingend/article/details/124341639
Author: 谁最温柔最有派
Title: 【强化学习】Actor-Critic(演员-评论家)算法详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/718979/
转载文章受原作者版权保护。转载请注明原作者出处!