

Title: Learning transferable visual models from natural language supervision
作者:Alec Radford * 1 Jong Wook Kim * 1 Chris Hallacy 1 Aditya Ramesh 1 Gabriel Goh 1 Sandhini Agarwal Girish Sastry 1 Amanda Askell 1 Pamela Mishkin 1 Jack Clark 1 Gretchen Krueger 1 Ilya Sutskever 1
发表单位:OpenAI, San Francisco
关键词:clip、多模态
论文: https://arxiv.org/pdf/2103.00020
代码: https://github.com/OpenAI/CLIP
一句话总结:利用text信息监督视觉任务自训练,本质就是将分类任务化成了图文匹配任务,效果可与全监督方法相当 ;
最大的优点:它打破了categorical label的限制(在分类的时候必须要定义一个分类的列表,如果不在分类的任务之中,是没办法分出来的,或者只能分类成最相似的。)
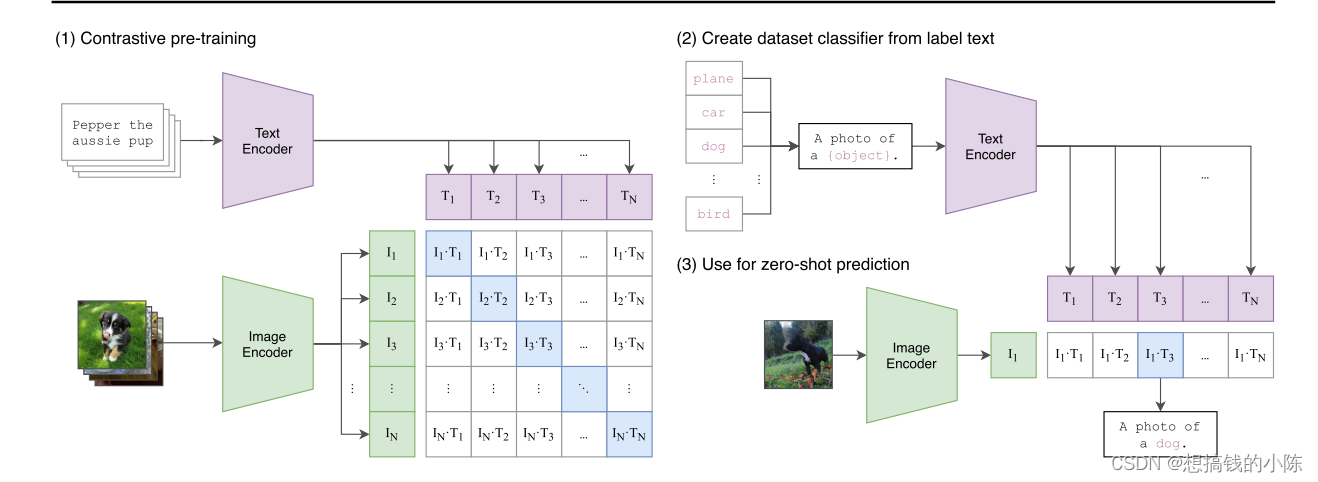

文本和图像的匹配。 假设有n个样本对,一个图片对应一个文本。
每个句子经过一个text encoder(可以是resnet,也可以是transformer)得到n个向量,记为T_N;每个图片经过image encoder得到N个向量得到I_N。构建一个矩阵,这个矩阵的对角线上的损失最小(因为是匹配的),是正样本,非对角线的元素是负样本,希望损失最大。
数据:CLIP采用了4E的图文配对的数据,从头开始学习。
类型:zero-shot
证明了简单的 预训练任务,即预测哪个标题caption与哪个图像相匹配,是一种有效的、可扩展的方法,可以在从互联网上收集的4亿个(图像、文本)对数据集上从头开始学习SOTA的图像表示。
摘要:
SOTA计算机视觉系统经过训练,可以预测一组固定的预定对象类别。这种受限的监管形式限制了它们的通用性和可用性,因为需要额外的标记数据来指定任何其他视觉概念。直接从原始文本中学习图像是一种很有前途的选择,它利用了更广泛的监督来源。我们证明,在从互联网收集的4亿对(图像、文本)数据集上,预测哪个字幕(caption)与哪个图像匹配的简单预训练任务是一种有效且可扩展的方法,可以从头学习SOTA图像表示。在预训练后,使用自然语言引用学习到的视觉概念(或描述新概念),从而实现模型到下游任务的zero-shot 的迁移。我们研究了30多个不同计算机视觉数据集的性能,包括OCR、视频中的动作识别、地理定位和许多类型的细粒度对象分类等任务。该模型可以非平凡地转移到大多数任务,并且通常可以与完全监督的基线进行竞争,而无需任何特定于数据集的培训。例如,我们在ImageNet zero shot上匹配原始ResNet50的精度,而不需要使用它所训练的128万个训练示例中的任何一个。
introduction
在过去几年中,直接从原始文本学习的方法彻底改变了NLP(Dai&Le,2015;Peters et al.,2018;Howard&Ruder,2018;Radford et al.,2018;Devlin et al.,2018;Raffel et al.,2019)。将”文本到文本”发展为标准化的输入-输出接口,使任务无关架构能够将zero-shot 迁移到下游数据集。像GPT-3这样的旗舰系统(Brown et al.,2020)现在在许多定制(bespoke)模型的任务中都具有竞争力,同时几乎不需要数据集特定的培训数据。这些结果表明,在网络规模的文本集合中,现代预训练方法的总体监督能力超过了高质量的人群标记NLP数据集。
然而,在计算机视觉等其他领域,在人群标记数据集(如ImageNet)上预训练模型仍然是标准做法(Deng等人,2009)。直接从网络文本中学习的可扩展的预训练方法能否在计算机视觉领域取得类似的突破?
之前的工作令人鼓舞。Joulin等人(2016年)证明,经过训练以预测图像字幕中的单词的CNN可以学习与ImageNet训练相竞争的表征。Li等人(2017)随后将该方法扩展到预测短语n-gram以及单个单词,并证明了他们的系统能够将零镜头传输到其他图像分类数据集。VirTex(Desai&Johnson,2020)、ICMLM(Bulent Sariyildiz et al.,2020)和ConVIRT(Zhang et al.,2020)最近采用了更新的架构和培训前方法,展示了基于转换器的语言建模、掩蔽语言建模和对比目标从文本中学习图像表示的潜力。然而,上述模型仍在执行当前的SOTA计算机视觉模型,如大转移(Kolesnikov et al.,2019)和弱监督的ResNeXt(Mahajan et al.,2018)。一个关键的区别是规模。Mahajan et al.(2018)和Kolesnikov et al.(2019)在数百万到数十亿张图像上进行了加速器年培训,VirTex、ICMLM和ConVIRT在一到二十万张图像上进行了加速器日培训。我们填补了这一空白,并大规模研究了自然语言监督训练的图像模型的行为。我们证明了一种简化的ConVIRT从头开始训练,我们称之为CLIP,用于对比语言图像预训练,是一种有效且可扩展的自然语言监控学习方法。我们找到了CLIP在预训练期间学习执行一系列任务,包括OCR、地理定位、动作识别,并在计算效率更高的情况下优于最好的公共可用ImageNet模型。我们还发现,零镜头剪辑模型比同等精度的监督ImageNet模型更具鲁棒性。
approach
现有工作主要使用了三个数据集,MS-COCO(Lin et al.,2014)、Visual Genome(Krishna et al.,2017)和YFCC100(Thomee et al.,2016)。虽然MS-COCO和Visual Genome是高质量的人群标记数据集,但按照现代标准,它们都很小,每个都有大约100000张训练照片。相比之下,其他计算机视觉系统在多达35亿张Instagram照片上接受培训(Mahajan等人,2018年)。1亿张照片的YFCC100M是一种可能的替代方案,但每个图像的元数据都很稀疏,质量也各不相同。许多图像使用自动生成的文件名,如2016071613957。JPG作为”标题”或包含相机曝光设置的”说明”。经过筛选,只保留带有自然语言标题和/或英文描述的图像后,数据集缩小了6倍,只有1500万张照片。这与ImageNet的大小大致相同。自然语言监管的一个主要动机是互联网上公开的大量这种形式的数据。为了验证这一点,我们构建了一个新的数据集,该数据集包含从互联网上各种公开来源收集的4亿对(图像、文本)。为了尽可能广泛地涵盖一组视觉概念,我们在构建过程中搜索(图像、文本)对,其文本包括一组500000个查询中的一个。我们通过在每个查询中包含多达20000对(图像、文本)来大致平衡结果。结果数据集的总字数与用于训练GPT-2的WebText数据集相似。我们将此数据集称为WebImageText的WIT。
我们最初的方法类似于VirTex,从零开始联合训练图像CNN和文本转换器来预测图像的标题。然而,我们在有效地扩展此方法时遇到了困难。在图2中,我们展示了一个6300万参数的transformer语言模型,该模型已经使用了其ResNet50图像编码器两倍的计算量,它学习识别ImageNet类的速度比Joulin et al.(2016)类似的方法慢三倍,该方法预测了相同文本的一袋单词编码。对比表征学习的最新研究发现,对比目标可以优于等效预测目标(Tian等人,2019)。注意到这一发现,我们探索了训练一个系统来解决可能更容易的代理任务,即仅预测哪个文本作为一个整体与哪个图像配对,而不是预测该文本的确切单词。从同一袋单词编码基线开始,我们将预测目标替换为图2中的对比目标,观察到零炮传输到ImageNet的效率进一步提高了4倍。
给定一批N(图像,文本)对,对片段进行训练,以预测在一批中实际发生的N×N(图像,文本)对中的哪一个。为此,CLIP通过联合训练图像编码器和文本编码器来学习多模态嵌入空间,以最大化批次中N个实数对的图像和文本嵌入的余弦相似性,同时最小化N个实数对的嵌入的余弦相似性− N不正确的配对。我们优化了这些相似性分数上的对称交叉熵损失。在图3中,我们为CLIP实现的核心包含了伪代码。该批量构建技术和目标首次作为多类N对丢失Sohn(2016)引入,最近Zhang等人(2020)将其应用于医学影像领域的对比(文本、图像)表征学习。
由于过度拟合不是主要问题,与Zhang等人(2020)相比,训练CLIP的细节简化了。我们从头开始训练剪辑,而不是用预先训练好的权重进行初始化。我们去除了表示空间和对比嵌入空间之间的非线性投影。我们仅使用线性投影将每个编码器的表示映射到多模态嵌入空间image\u encoder-ResNet或Vision Transformer#text\u encoder-CBOW或text Transformer#I[n,h,w,c]-对齐图像的小批量#T[n,l]-对齐文本的小批量#w\u I[d\u I,d\u e]-要嵌入的图像的学习项目#w\u T[d\u T,d\u e]-要嵌入的文本的学习项目#T-学习的温度参数#提取每个模态的特征表示u f=图像\u编码器(I)#[n,d\u I]T\u f=text\u编码器(T)#[n,d\T]#联合多模式嵌入[n,d\e]I\u e=l2\u规格化(np.dot(I\f,W\u I),axis=1)T\u e=l2\u规格化(np.dot(T\f,W\T),axis=1)#缩放成对余弦相似度[n,n]logits=np。点(I\u e,T\u e.T)*np。exp(t)#对称损失函数标签=np。arange(n)loss\u i=cross\u entropy\u loss(logits,labels,axis=0)loss\u t=cross\u entropy\u loss(logits,labels,axis=1)loss=(loss\u i+loss\u t)\/2图3。类Numpy伪代码,为CLIP的核心实现。我们还删除了文本转换函数tu,该函数从文本中均匀采样一个句子,因为CLIP预训练数据集中的许多(图像、文本)对都只是一个句子。我们还简化了图像转换函数tv。从调整大小的图像中随机裁剪正方形是训练期间使用的唯一数据增强。最后,在训练过程中,控制softmax中logit范围的温度参数τ直接作为对数参数化的乘法标量进行优化,以避免变为超参数。
微调:这种模型如何去微调?经过CLIP训练的网络只能得到图像和文本的特征,他并没有像Resnet,VGG等网络那样有一个分类头,我们无法对其进行微调。因此,CLIP借用了NLP中的prompt template。例如,Imagenet有1000个类,先将1000个类生成为一个简单的句子(以plane为例,生成一个”a photo of plane”),生成的1000个文本信息与图片构建一个1*1000的矩阵进行预测。
为什么这么做微调呢?因为在训练的时候,图片看到的都是一个句子,如果在推理的时候只保留一个单词。
Original: https://blog.csdn.net/qq_34845880/article/details/124910872
Author: 其实也很简单
Title: 【多模态】CLIP模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/718787/
转载文章受原作者版权保护。转载请注明原作者出处!