

结构速览
*
– 1.论文的整体逻辑是什么
– 2.具体怎么加入噪声和去掉噪声的
–
+ 2.1加入参数的大致指导思想
+ 2.2具体怎么加入噪声
+ 2.3怎么去掉噪声(问题最后转化为怎么估算噪声)
+ 2.4怎么估计噪声(实际上怎么训练)
* 3.和其他的比较和
*
– 3.1 和GAN流程的区别
* 4.其他细节
*
– 4.1只预测噪声的均值,这样可以帮助稳定训练。
1.论文的整体逻辑是什么
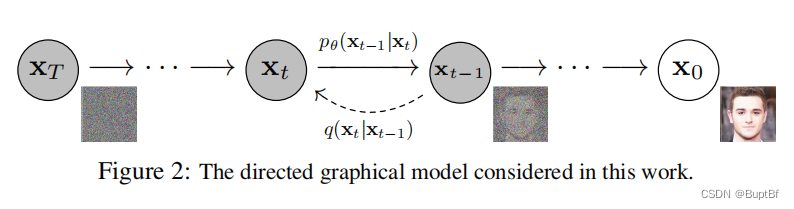

- 1.我们可以看到最终通过不断的加入噪声,原始的图片变成了一个完全混乱的图片,这个完全混乱的图片就可以当成一个随机生成的噪声图片。(从x0开始不断加入噪声到xt,xt只是一个带有噪声的图片,再逐渐加入更多噪声,到XT的时候图片已经完全变成一个噪声图片了。)
- 2.类似的我们可以想到如何从一张随机生成的噪声图片得到生成的图片, 我们只需要知道在这个完全混乱的噪声图片当中如何不断拿去刚刚加入的噪声,让其变得不混乱,逐步更加接近真实图片,就可以得到最开始的图片。
- 3.所以这里面如何预测噪声就成了我们的关键需求,人是算不出来的,所以我们需要借助网络来帮忙。
- 4.为了让网络预测这些噪声,我们先要知道这些噪声(噪声就是标签),为了训练我们需要在一开始加入噪声的时候。逐个存下来,对网络进行训练,让网络有预测噪声的能力
- 5.最终通过网络学习的方法得到每次获得的噪声帮助我们回推。
理解一下这个过程:
- 1.我们加入噪声的时候虽然是随机加入的噪声,反向思考,拿去噪声并不是随机的,而是有目的性的拿去,有目的的不断拿去噪声,才导致了最终图片的生成;
- 2.只要网络学会了这种有目的的拿去,就可以生成对应的图片,所以网络为:输入xt,输出xt变成xt-1需要被有目的拿去的噪声。
这里面我们注意一些其他细节:
- 1)去的时候和回来的时候,噪声并不太一样。去的时候噪声是随便的,什么都可以的。回来的时候噪声必须是结合当前时刻图片的情况,专门设计的一种特定的噪声。
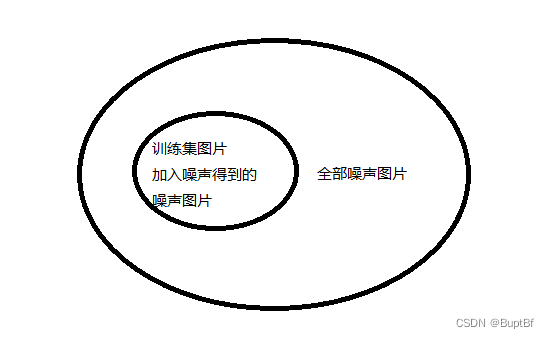
- 2)为什么要预测?这里其实我们训练的时候通过给正常图片加入噪声得到的训练模型其实只是在真正的噪声图片当中占一小部分,我们需要预测更多的噪声图片要怎么回来。所以其实也是一个检验模型泛化能力的过程。
- 3)这里用能力更强的网络(例如transformer),可能会让生成的图片更加接近训练集,大约就是因为噪声预测的太准了,一下子就回到原始训练数据了,所以有时候不是很准,也许效果更具有多样性。
; 2.具体怎么加入噪声和去掉噪声的
2.1加入参数的大致指导思想
- 1.加入噪声的过程需要是噪声逐渐增大的:
1) 因为加入噪声的目标是让图片变的更加混乱,一开始图片还比较完整的清晰的时候我们稍微加一点噪声图片就变得更加混乱了。但是,后面的时候图片已经变的十分混乱了,所以我们需要更多的噪声来干扰这个图片
2)我个人认为也有这么一个考虑,在之后生成的过程中需要回推,回推刚开始的时候是从噪声开始的,如果步子更大一点,好像也没有太大的问题,可以加速训练的进行;但是在最后调整的时候,稍微错一点可能就会出现大问题,所以需要细致的调整。而这个快慢变化大致和我们加入噪声的时候大致趋势是一致的,因此需要让加入噪声的时候速度逐渐增加。 - 2.加入噪声的时候,每个图片之间具有马可夫性:
马可夫性就是当前时刻的状态只和上一时刻的状态有关,和其他时刻无关。这是显然的,因为这一时刻的图片是由上一时刻的图片加入噪声之后得到的,显然之后上一时刻有关,和上上时刻的关系不大,因为他们之间还隔了一个噪声的加入。
2.2具体怎么加入噪声
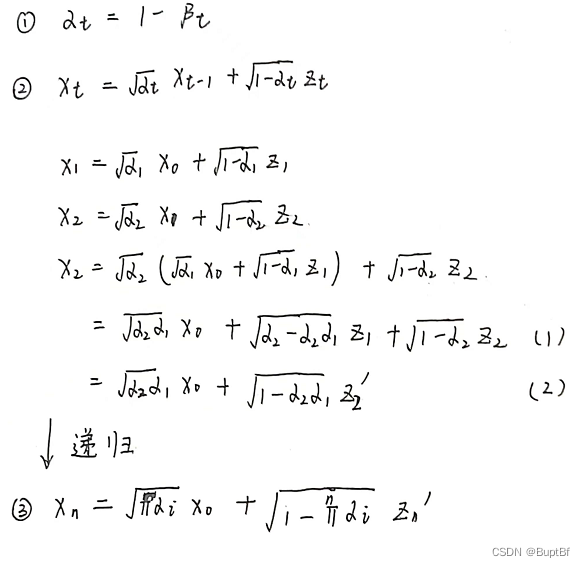
- ①式是一个控制参数,这里的β会逐渐增大来使得噪声的影响越来越大(原因上面说了)。
- ②式是一个具体怎么加入噪声的过程,这里为什么是加上根号的主要目标是为了方便推算出来③式的时候简化计算。
- ③式是从x0直接推算到最终的xt噪声的式子。
- x1x2x3x4…xt是从最开始的完美图片到最后的噪声。
- z1z2z3…zt是每次加入的噪声
- (1)到(2)的推算是合并两个正态分布的噪声。
; 2.3怎么去掉噪声(问题最后转化为怎么估算噪声)
我们想要去掉噪声,其实就是从xt推算出来xt-1
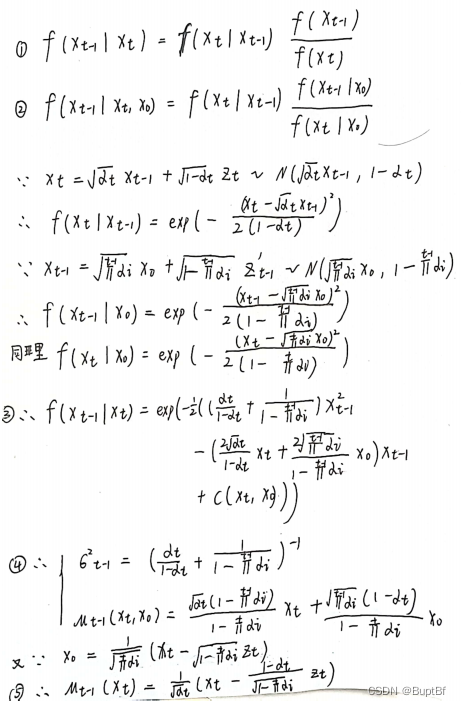
- 这里的f(x)指的是概率分布
- ①式是我们传统贝叶斯公式的结果
- ②式是①式当中的xt和xt-1的分布没法直接计算,所以,额外引入了一个x0。
- ③式是我们化简了一下子上面这个式子。
- ④式是我们根据正态分布的分布函数情况,计算的均值和方差
- ⑤式是我们依据估计的内容(其实是用xt粗略的估计了x0)巧妙的消去x0.
2.4怎么估计噪声(实际上怎么训练)
- 作者只是使用了一个简单的Unet来完成任务,训练过程大约如下
1:表示重复多轮
2:表示我们在图片当中随机选一部分
3:表示我们每次训练的时候不是这张图片全过程当中的每一个点都进行预测,只是选择了其中一部分进预测
4:取一个噪声
5:这里是作者构造损失的地方,我们质疑看前面的是不带θ的是实际上加入的噪声值,后面带有θ的是在训练的模型。输入的其实前面是xt的估计值,后面的t是因为我们在输入的时候每一次加入的噪声大小不同,越往后越大,所以我们预测噪声的时候也要跟第几次加入有关因此设置了这个输入。 - 回推过程如下
3:这里其实就是最后一次不加噪声了。
4:只有这里最关键,其实就是我们上面推算出来的公式。

- 每次我们都是输入当前这个xt,使用这个Unet预测一个噪声zt,每次使用的Unet是一样的,只是输入不太一样。
; 3.和其他的比较和
3.1 和GAN流程的区别
比较起来看的话,GAN网络是全局的函数求解,而diffusion更倾向于一个求导函数的过程,diffusion通过拟合一个导函数进而知道每一步怎么前进,最终完成图像的估计。
4.其他细节
4.1只预测噪声的均值,这样可以帮助稳定训练。
具体来说这个细节是:
- 1.扩散模型预测的其实是扩散模型只预测加入的噪声,也就是只预测一个高斯噪声;
- 2.既然预测的是高斯噪声,可以直接预测均值和方差;
- 3.DDPM作者发现可以直接固定这个噪声的均值,只预测均值就能取得很好的效果;
- 4.后面也有人预测噪声的方差,虽有效果提升,但是这种方式开销较大。
Original: https://blog.csdn.net/qq_43210957/article/details/127049721
Author: BuptBf
Title: 生成网络论文阅读:DDPM(一):Denoising Diffusion Probabilistic Models论文概述
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/718461/
转载文章受原作者版权保护。转载请注明原作者出处!