

白葡萄酒质量数据集
数据来自于:https://scikit-learn.org/stable/modules/preprocessing.html
导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns #Seaborn是python中的一个可视化库,是对matplotlib进行二次封装而成
sns.set_style('darkgrid')
import warnings
warnings.filterwarnings('ignore')
加载数据
预处理
df = pd.read_csv('white.csv',sep=';')
df.to_csv('white1.csv')
df = pd.read_csv('white1.csv',index_col=0)
df2 = pd.read_csv('white1.csv',index_col=0)
df1 = pd.read_csv('white1.csv')
df.head()
yy = df['quality']
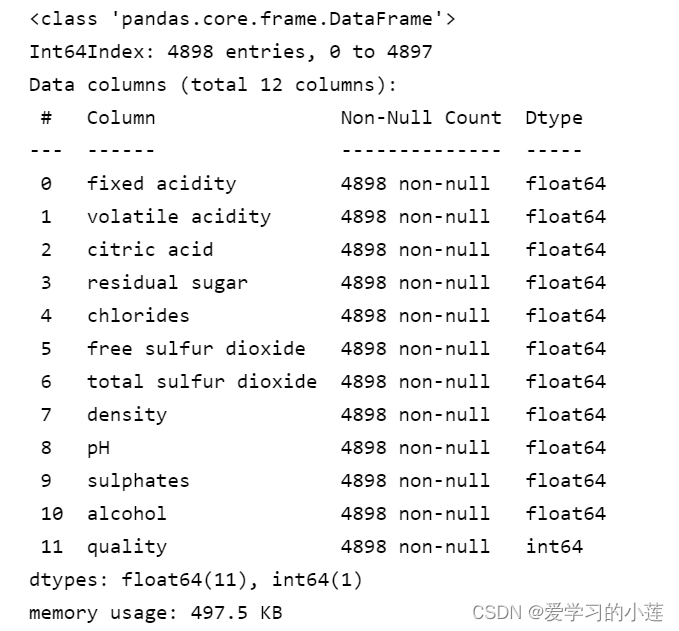
查看数据的一些基本信息
- 数据类型 DataFrame
- 有4898条数据(4898行),索引为0-4897
- 该数据帧有12列
-
: 索引号
- column: 每列数据的列名
- Non-Null count: 每列数据的数据个数,缺失值NaN不作计算。可以看出下面面所有数据都没有缺失值。
- Dtype: 数据的类型。
- dtypes: float64(11), int64(1):数据类型的统计
- memory usage: 459.3 KB:该数据帧占用的运行内存(RAM)
df.info()

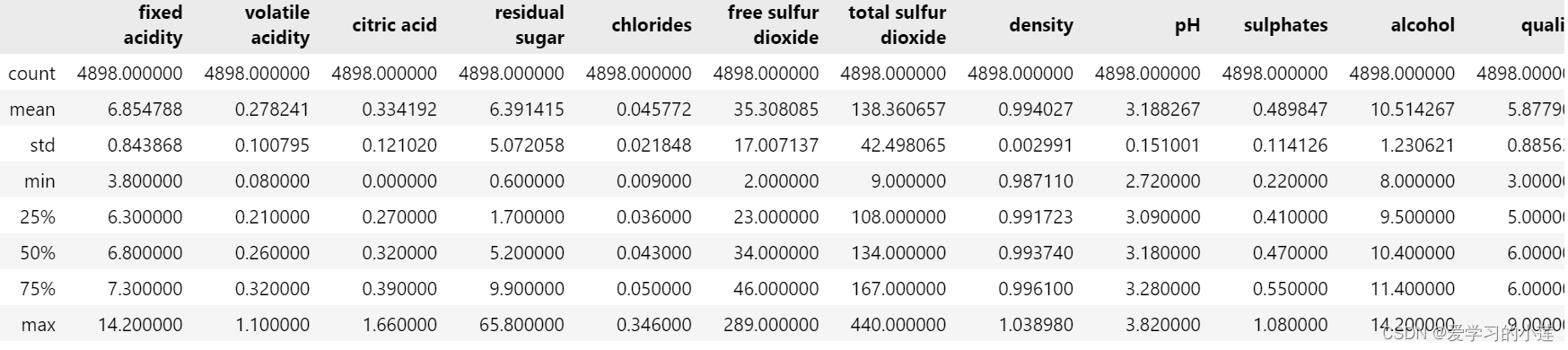
- count:数量统计,此列共有多少有效值
- unipue:不同的值有多少个
- std:标准差
- min:最小值
- 25%:四分之一分位数
- 50%:二分之一分位数
- 75%:四分之三分位数
- max:最大值
- mean:均值
df.describe()
; 数据分析
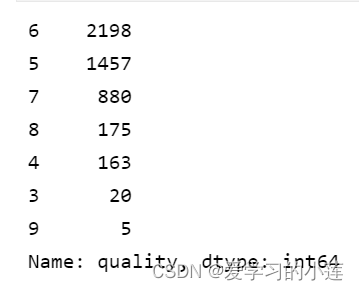
绘制计数图
sns.countplot(df['quality'])
print(df['quality'].value_counts())
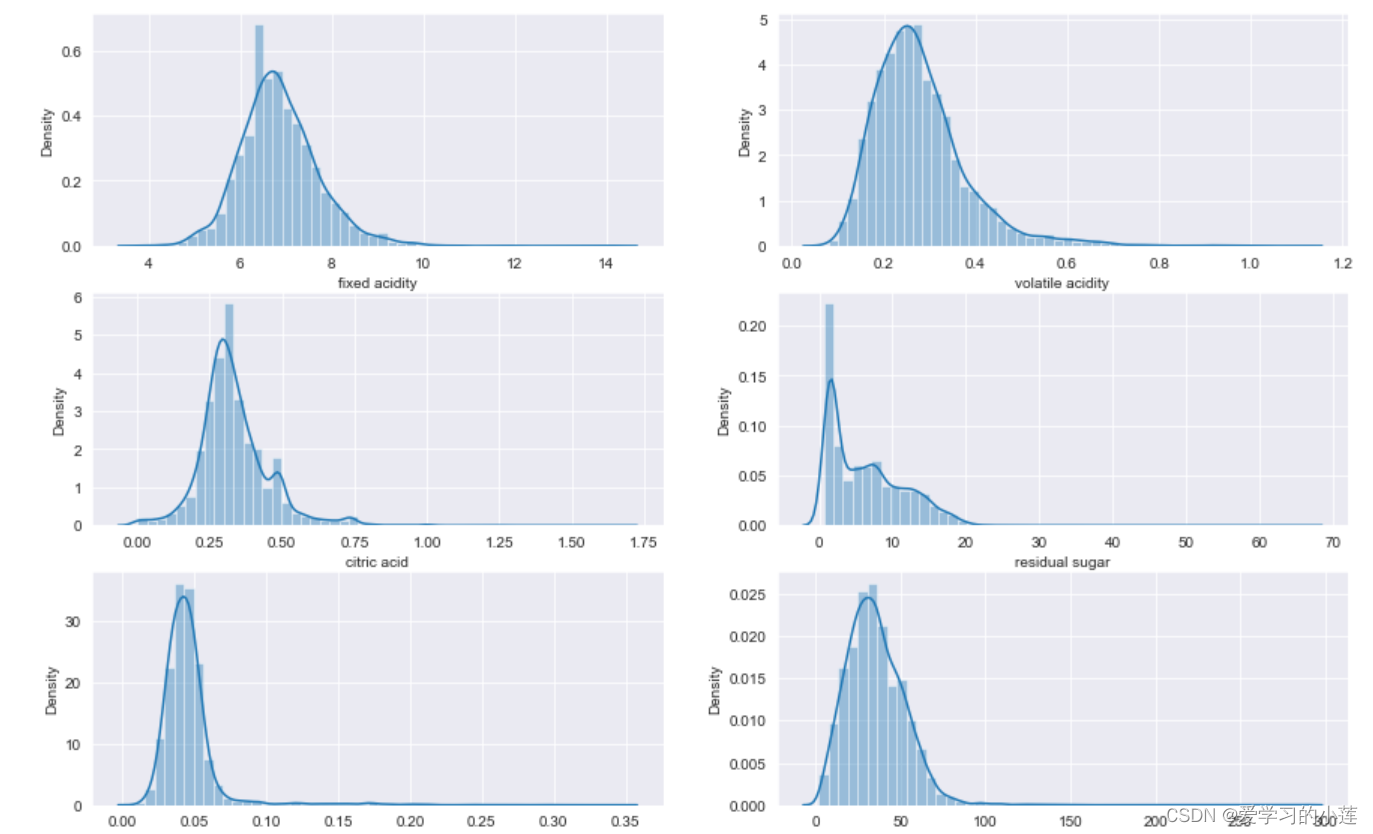
i=1
plt.figure(figsize=(15,20))
for col in df.columns:
plt.subplot(6,2,i)
sns.distplot(df[col])
i+=1
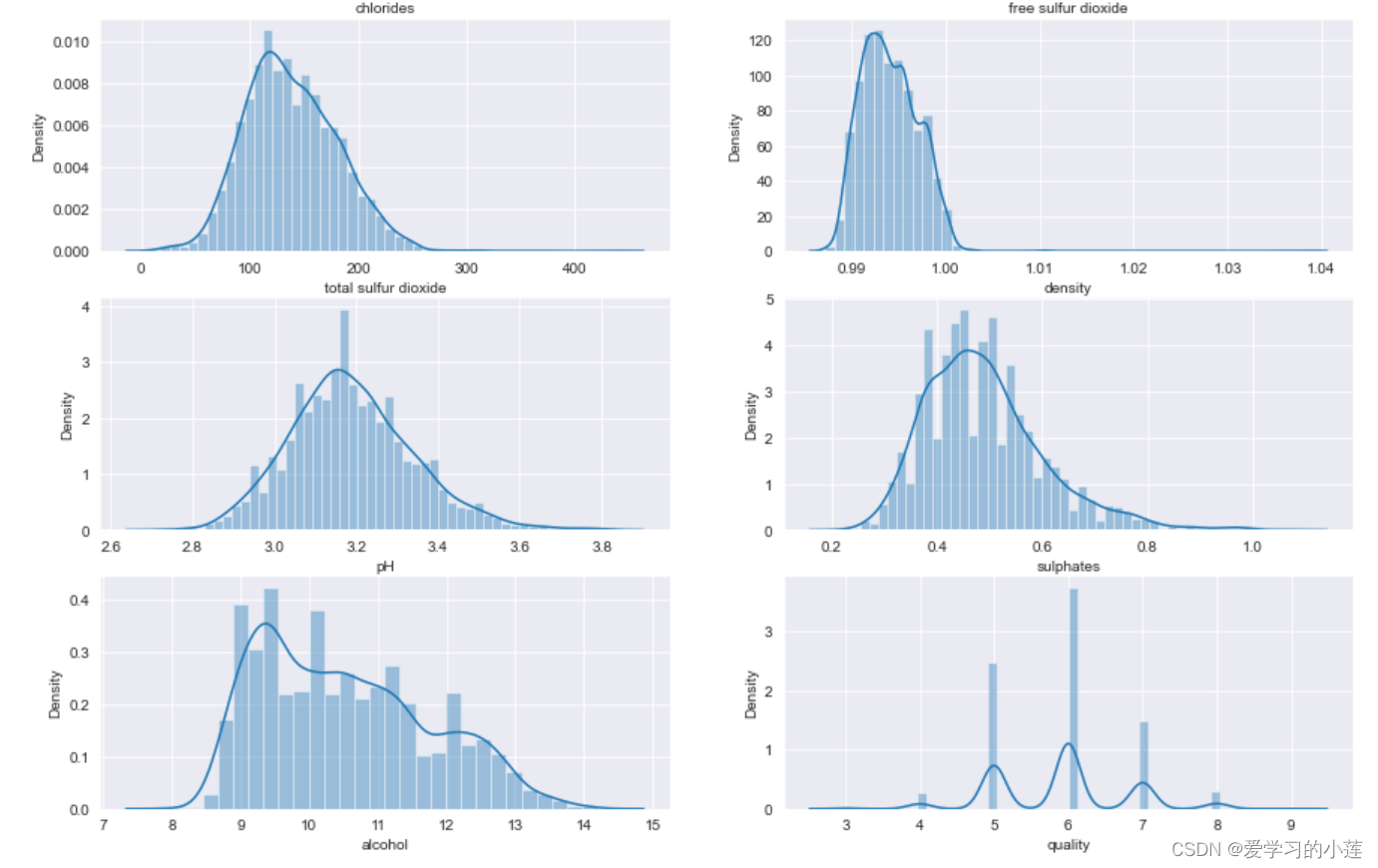
i=1
plt.figure(figsize=(15,20))
for col in df.columns:
plt.subplot(6,2,i)
sns.barplot(x=df['quality'], y= df[col])
i+=1
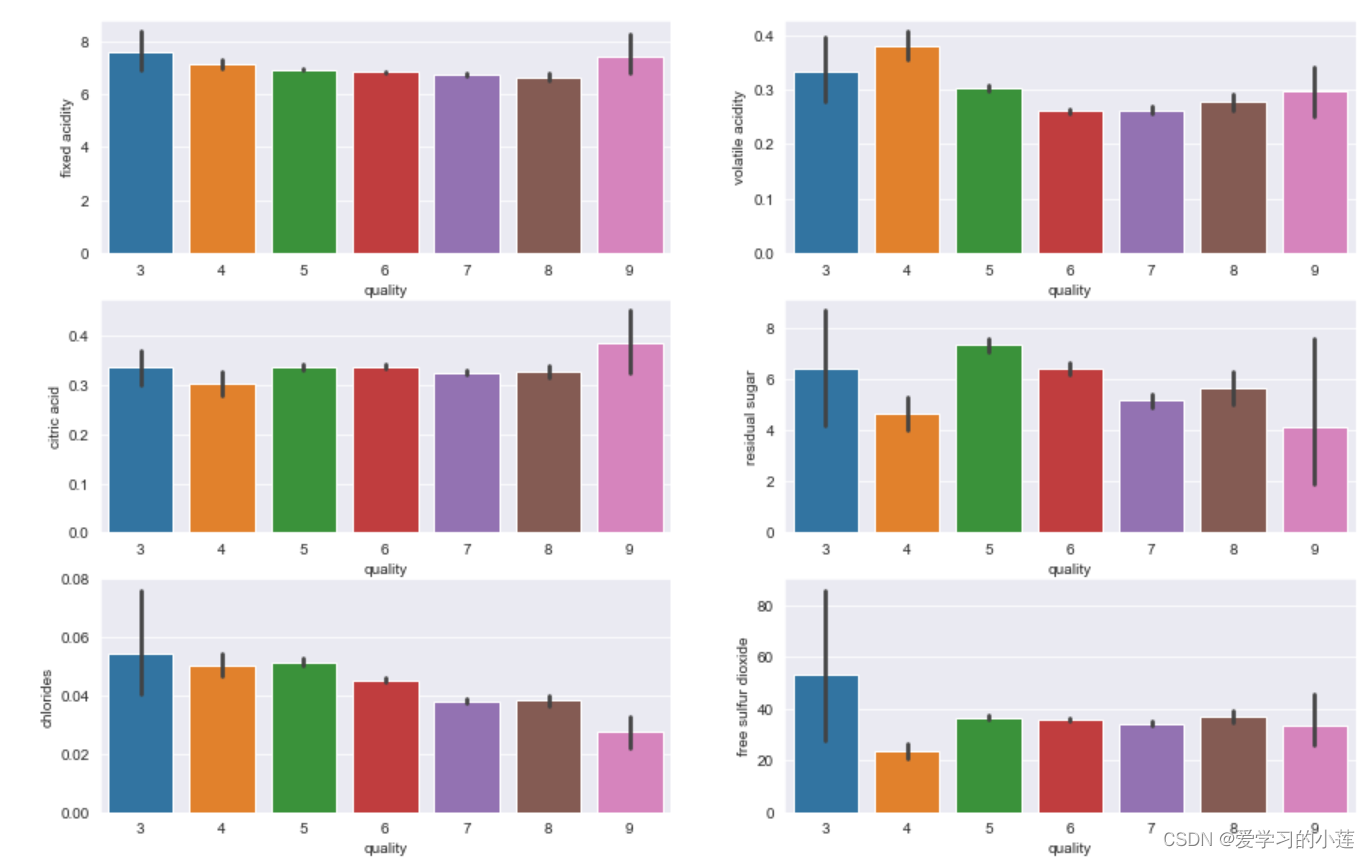
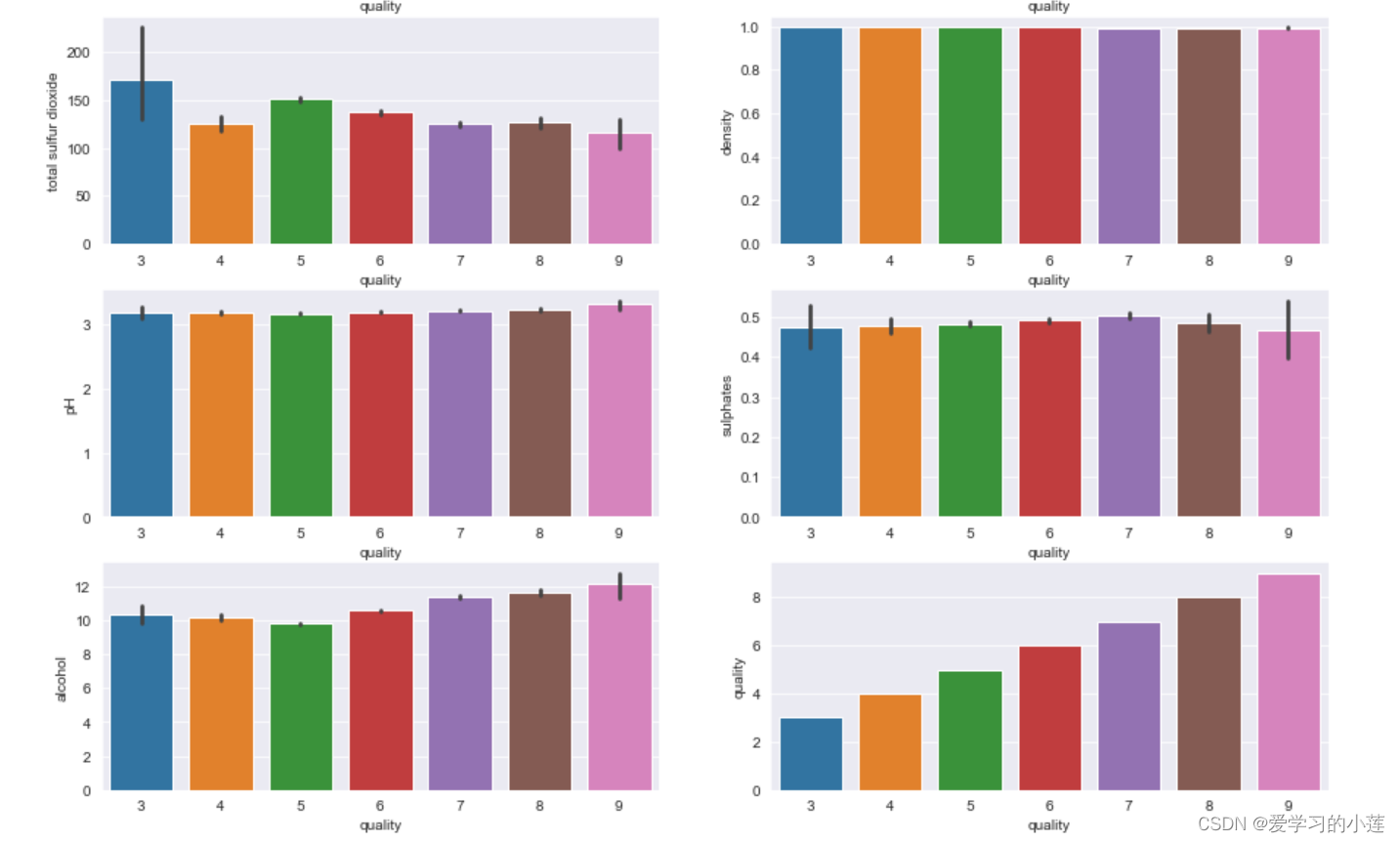
整体过采样
说到最重要的部分,我们现在将进行欠采样和过采样。
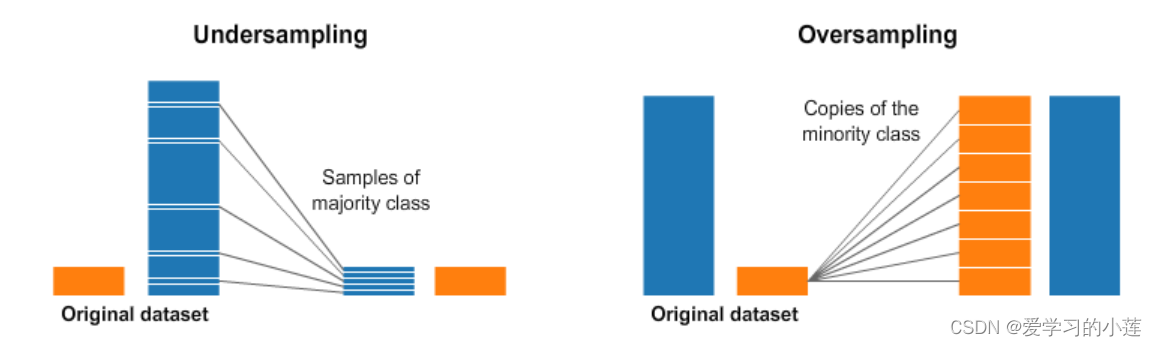
通过这张图片了解过采样和欠采样究竟是什么
简单来说:
- 过采样中,最简单实现是从少数类复制随机记录,这可能会导致过度重合。
- 欠采样中,最简单的方法是从多数类中删除随机记录,这可能会导致信息丢失。
df_3 = df2[df2.quality==3]
df_4 = df2[df2.quality==4]
df_5 = df2[df2.quality==5]
df_6 = df2[df2.quality==6]
df_7 = df2[df2.quality==7]
df_8 = df2[df2.quality==8]
df_9 = df2[df2.quality==9]
#我们之前已经确定,除了质量6之外,所有其他的都是少数!
过采样少数类以生成平衡数据:
from sklearn.utils import resample
df_3_upsampled = resample(df_3, replace=True, n_samples=2000, random_state=12)
df_4_upsampled = resample(df_4, replace=True, n_samples=2000, random_state=12)
df_5_upsampled = resample(df_5, replace=True, n_samples=2000, random_state=12)
df_7_upsampled = resample(df_7, replace=True, n_samples=2000, random_state=12)
df_8_upsampled = resample(df_8, replace=True, n_samples=2000, random_state=12)
df_9_upsampled = resample(df_9, replace=True, n_samples=2000, random_state=12)
减少多数的行以生成余额数据:
df_6_downsampled = df2[df2.quality==6].sample(n=2000).reset_index(drop=True)
将下采样多数类与上采样少数类相结合
Balanced_df = pd.concat([df_3_upsampled, df_4_upsampled, df_7_upsampled,
df_8_upsampled, df_9_upsampled,df_5_upsampled, df_6_downsampled]).reset_index(drop=True)
显示新类别计数
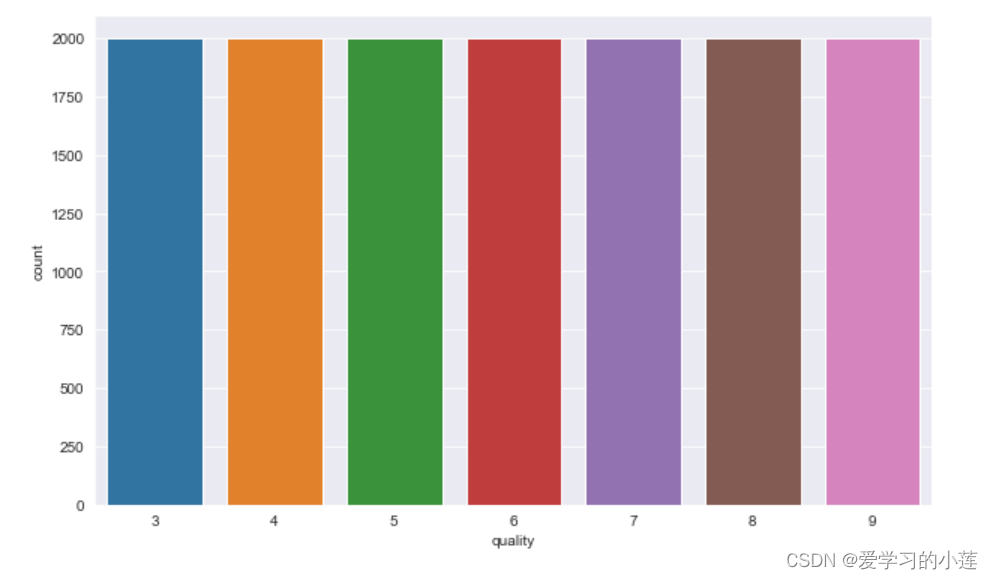
Balanced_df.quality.value_counts()
我们可以看到,我们所有质量类别的数量都是相等的!
plt.figure(figsize=(10,6))
sns.countplot(x='quality', data=Balanced_df, order=[3, 4, 5, 6, 7, 8, 9])
我们可以看到,我们所有质量类别的数量都是相等的!
from sklearn.model_selection import train_test_split
xxx = Balanced_df
yyy = Balanced_df.quality
XXX_train, XXX_test, YYY_train,YYY_test= train_test_split(xxx,yyy, test_size=0.3)
整体过采样PCA处理
from sklearn.preprocessing import StandardScaler
scalar = StandardScaler()
df_scaled1 = pd.DataFrame(scalar.fit_transform(Balanced_df), columns=Balanced_df.columns)
df_scaled1.head()

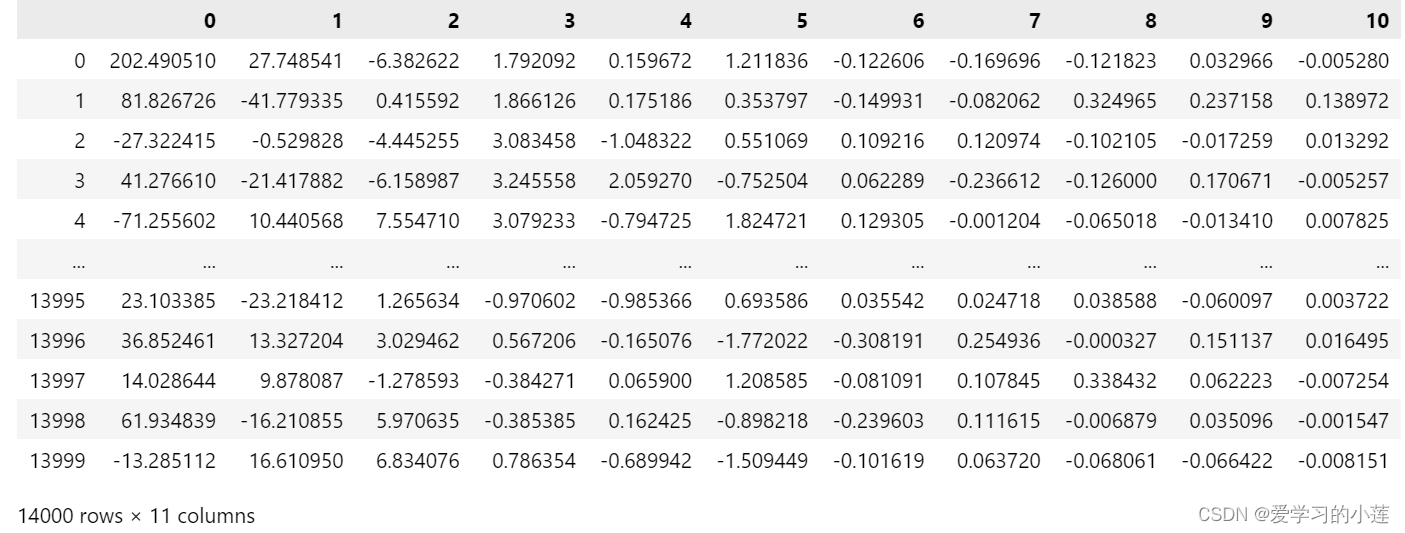
from sklearn.decomposition import PCA
pca1 = PCA(n_components=11)
df_pca1 = pd.DataFrame(pca1.fit_transform(Balanced_df))
xx1 = df_pca1
xx1
from sklearn.model_selection import train_test_split
yyy = Balanced_df.quality
XXX_train, XXX_test, YYY_train,YYY_test= train_test_split(xx1,yyy, test_size=0.3)
print(len(XXX_train))
print(len(XXX_test))
PCA全数据过采样与欠采样模型选择
training_scores= []
testing_scores=[]
for key, value in models.items():
value.fit(XXX_train, YYY_train)
train_score= value.score(XXX_train, YYY_train)
test_score= value.score(XXX_test, YYY_test)
training_scores.append(train_score)
testing_scores.append(test_score)
print(f"{key}\n")
print(f"Training 准确率为: {train_score}" )
print(f"Testing 准确率为: {test_score} \n")

交叉验证
from sklearn.model_selection import cross_val_score
cv_scores= []
for key, value in models.items():
cvs=cross_val_score(value, xx1,yyy, cv=5)#交叉验证生成器或可迭代的次数
cv_scores.append(cvs.mean())
print(f"{key}\n")
print(f"CV 准确率为: {cvs.mean()} \n" )

from sklearn.metrics import classification_report,precision_score
rfc=MLPClassifier()
rfc.fit(XXX_train,YYY_train)
y_pred= rfc.predict(XXX_test)
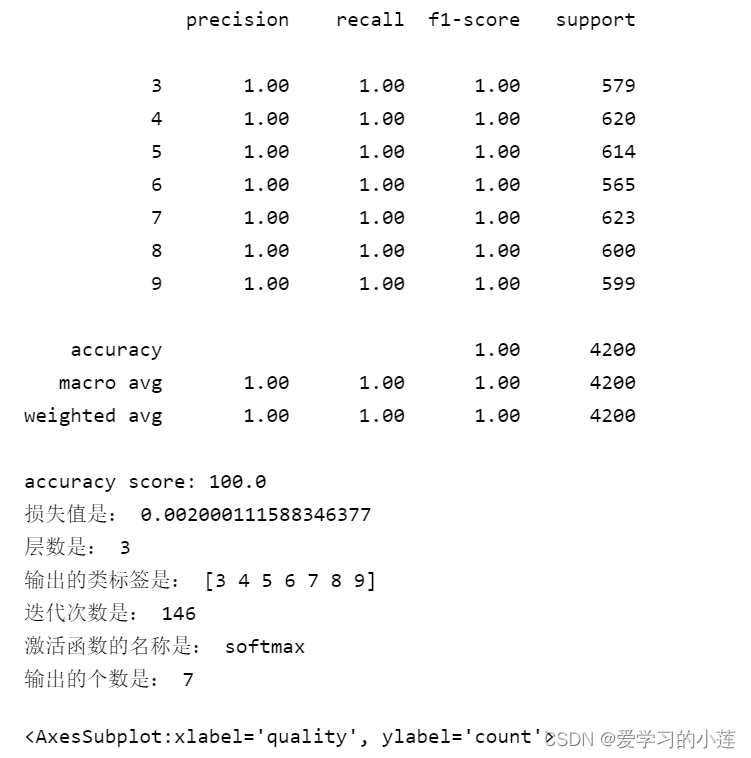
print(classification_report(YYY_test,y_pred))
print("accuracy score:", accuracy_score(YYY_test,y_pred)*100)
print('损失值是:', rfc.loss_)
print('层数是:', rfc.n_layers_)
print('输出的类标签是:', rfc.classes_)
print('迭代次数是:', rfc.n_iter_)
print('激活函数的名称是:', rfc.out_activation_)
print('输出的个数是:', rfc.n_outputs_)
sns.countplot(YYY_test)
pass:正常来说,还要对模型进行模型调参,博主这里已经跑到了100%就没有对模型进行调参。
项目代码文件与PPT介绍也都放在资源库中
https://download.csdn.net/download/qq_52201194/85813596?spm=1001.2014.3001.5503
Original: https://blog.csdn.net/qq_52201194/article/details/125505954
Author: 爱学习的小莲
Title: 白葡萄酒/红葡萄酒质量分析与预测(PCA+MLPClassifier)100%
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/718091/
转载文章受原作者版权保护。转载请注明原作者出处!