

分类交叉熵是一种用于多类分类任务的损失函数。在这些任务中,一个示例只能属于许多可能类别中的一个,模型必须决定哪个类别。
形式上,它旨在量化两种概率分布之间的差异。
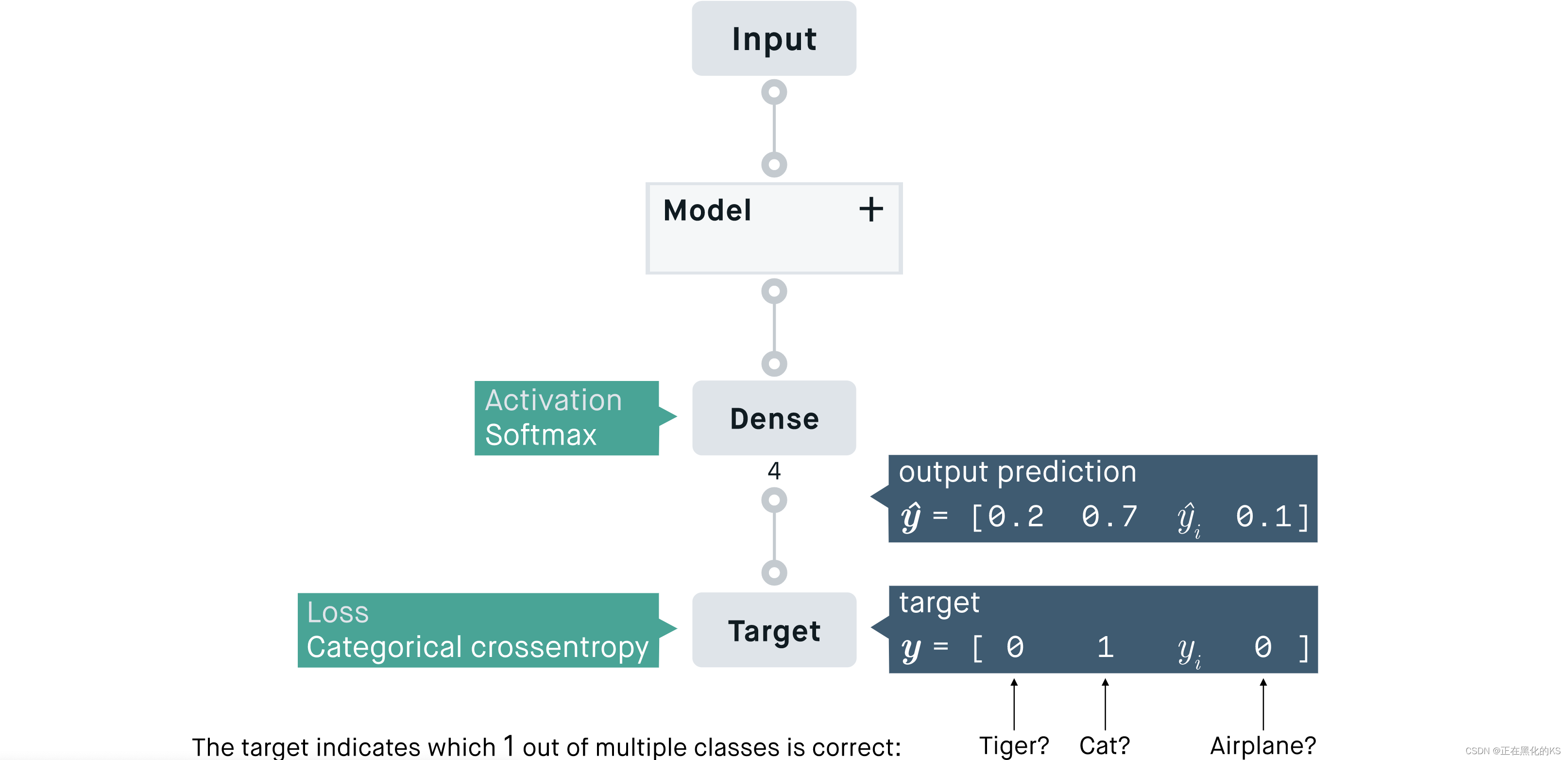

分类交叉熵的数学计算方式:
交叉熵损失函数通过计算以下和来计算示例的损失:
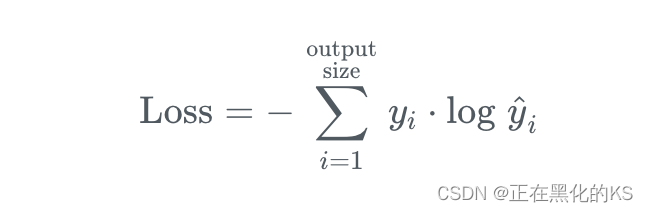
根据公式我们可以发现,因为 yi,要么是0,要么是1。而当 yi等于0时,结果就是0,当且仅当 yi等于1时,才会有结果。也就是说 categorical_crossentropy只专注与一个结果,因而它一般配合softmax做单标签分类。
分类交叉熵的使用方法:
分类交叉熵非常适合分类任务,因为一个示例可以被视为属于概率为1的特定类别和其他概率为0的类别。
示例:MNIST数字识别教程,其中有数字0、1、2、3、4、5、6、7、8和9的图像。
该模型使用绝对交叉熵来学习给正确的数字高概率,给其他数字低概率。
搭配的激活函数:
Softmax是唯一建议与类别交叉熵损失函数一起使用的激活函数。
严格来说,模型的输出只需要是正的,这样每个输出值的对数存在。
然而,这种损失函数的主要吸引力在于比较两种概率分布。Softmax激活重新缩放模型输出,使其具有正确的属性。
目标特征:
使用单个类别功能作为目标。
这将自动从数据集中确定的所有类别中创建一个单热向量。每个单热向量都可以被认为是一个概率分布,这就是为什么通过学习预测它,模型将输出一个示例属于任何类别的概率。
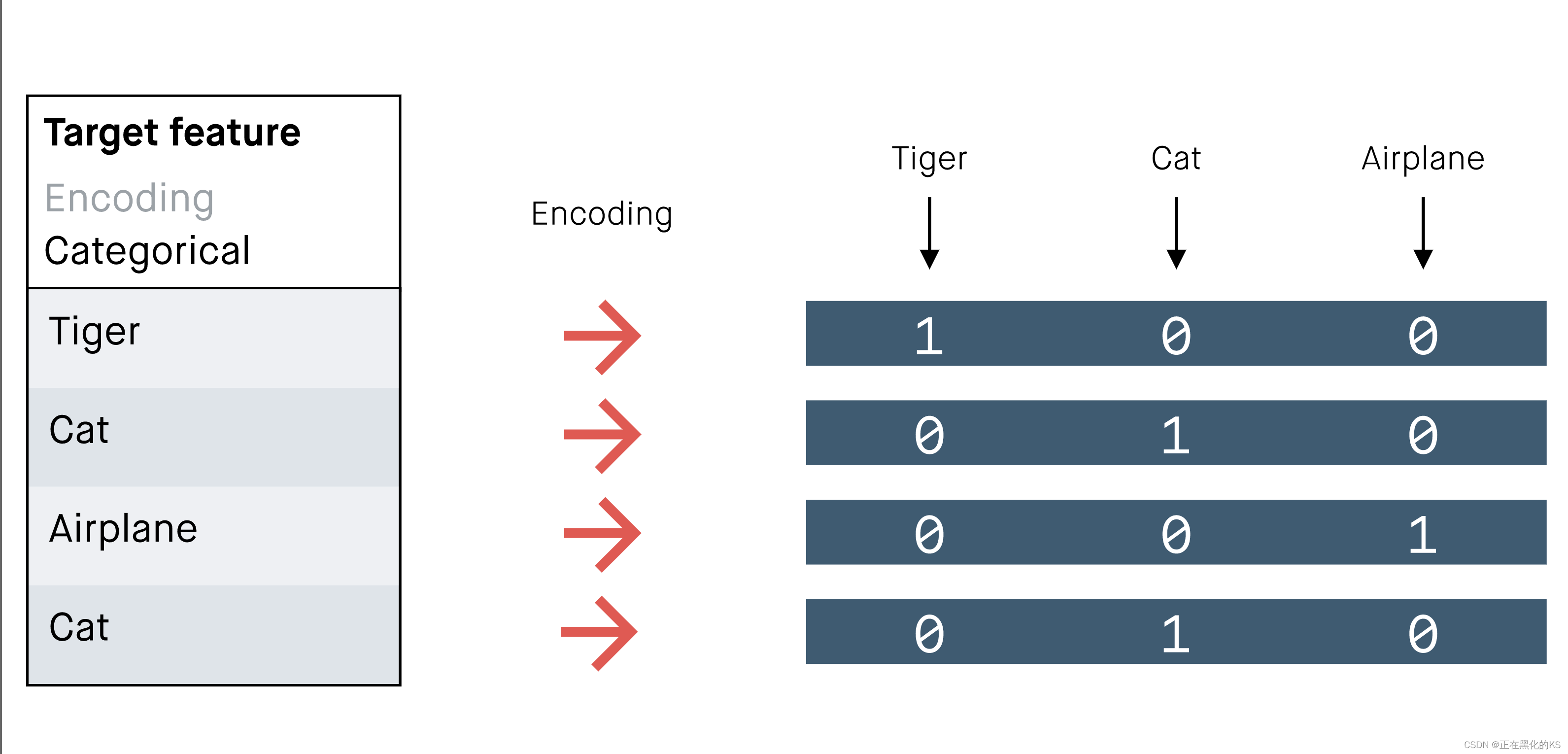
分类特征是在引擎盖下编码的。这使得它们直接适合与绝对的交叉熵损失函数一起使用。
或者,可以使用Numpy数组的数字功能来指定任何概率分布。
当希望模型预测任意概率分布,或者想实现标签平滑,这会很有用
Original: https://blog.csdn.net/m0_54689021/article/details/126546767
Author: 正在黑化的KS
Title: 深度学习理论:Categorical crossentropy 损失函数
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/718075/
转载文章受原作者版权保护。转载请注明原作者出处!