

数据分片技术作为目前架构设计中处理大数据的一种常规手段,当前被广泛用于缓存、数据库、消息队列等中间件的开发与使用当中,例如在数据量较大的项目当中,系统的性能瓶颈主要来自于与数据库的交互,而通过合理的设计数据库分片规则,可将系统中的数据分布在不同的物理数据库中,平衡了单点的数据量与访问压力,达到提升应用系统数据处理速度的目的,从而提高系统的整体性能;
数据库分片的概念
数据分片概念就是按照一定的规则,将数据集划分成相对独立的数据子集,然后将数据子集分布到不同的节点上,这个节点可以是逻辑上节点,也可以是物理上的节点。数据分片需要按照一定的规则,不同的分布式场景需要设计不同的规则,但基本都遵循同样的原则:按照最主要、最频繁使用的访问方式来分片。在常规的项目开发当中,一般有以下三种方式对数据进行分片:hash方式、一致性hash、按照数据范围,每种分片方式是否适用,一方面需要结合项目的实际情况与规模,另一方面也要从几个常规的维度去评估:
1、 数据分片策略,也就是具体的分片方式
2、 数据分片节点的动态扩展,随着数据量的逐步增长,是否能够通过增加节点来动态扩展适应
3、 数据分片节点的负载均衡’,结合分片策略能否保证数据均匀的分布在各个节点上以及各个节点的负载压力是否均衡
4、 数据分片的可用性,当其中一个节点产生异常,能否将该节点的数据转移到其他节点上
下面我们就对三种常规的分片模式做个基本的介绍
hash方式
通过对数据(一般为Key值)先进行hash计算再取模的方式是一种简单且使用频繁的分片方式,也就是Hash(Key)%N,这里的N大部分情况下就是我们的结点个数,这种方式相对简单实用,一般场景下能够满足我们的要求。但Hash取模方式主要的问题是节点扩容或缩减的时候,会产生大量的数据迁移,比如从N台设备扩容到N+1台,绝大部分的数据都要在设备间进行迁移。该种方式代码实现较为简单,既可以采用jdk自带的hash方式也可以采用其他hash算法,大家可以自行搜索具体实现。
一致性hash
一致性hash是将数据按照特征值映射到一个首尾相接的hash环上,同时也将节点映射到这个环上。对于数据,从数据在环上的位置开始,顺时针找到的第一个节点即为数据的存储节点。这种模式的优点在于节点一旦需要扩容或缩减的时候只会影响到hash环上相邻的节点,不会发生大规模的数据迁移。分片方式如下图所示
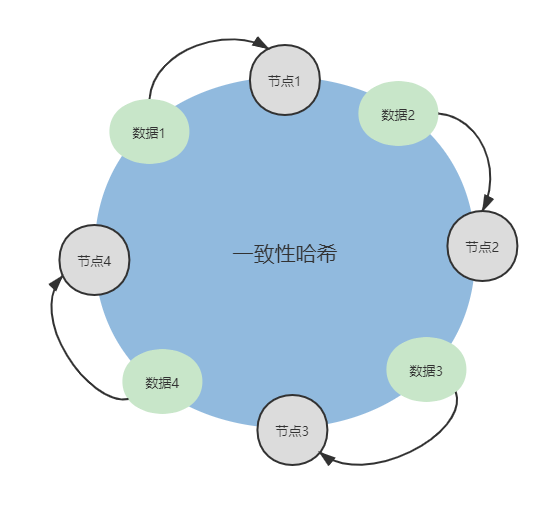

但是常规的一致性hash分片模式也有缺点,一致性hash方式在增加节点的时候,只能分摊一个已存在节点的压力,在其中一个节点挂掉的时候,该节点的压力也会被全部转移到下一个节点。理想的目标是当节点动态发生变化时,已存在的所有节点都能参与进来,达到新的均衡状态。因此在实际开发中一般会引入虚拟节点(virtual node)的概念,即不是将物理节点映射在hash环上,而是将虚拟节点映射到hash环上。虚拟节点的数目远大于物理节点,因此一个物理节点需要负责多个虚拟节点的真实存储。操作数据的时候,先通过hash环找到对应的虚拟节点,再通过虚拟节点与物理节点的映射关系找到对应的物理节点。
引入虚拟节点后的一致性hash需要维护的元数据也会增加:第一,虚拟节点在hash环上的问题,且虚拟节点的数目又比较多;第二,虚拟节点与物理节点的映射关系。但带来的好处是明显的,当一个物理节点失效时,hash环上多个虚拟节点失效,对应的压力也就会发散到多个其余的虚拟节点,事实上也就是多个其余的物理节点。在增加物理节点的时候同样如此。除此之外,可以根据物理节点的性能来调整每一个物理节点对于虚拟节点的数量,充分、合理利用资源。下面看下引入虚拟节点的一致性hash的代码实现
/** * 节点信息 * */ class Node { private String host;//IP信息 private int load;//负载因子 public String getHost() { return host; } public void setHost(String host) { this.host = host; } public int getLoad() { return load; } public void setLoad(int load) { this.load = load; } public Node(String host, int load) { super(); this.host = host; this.load = load; } @Override public String toString() { return "Node [host=" + host + ", 负载因子=" + load + "]"; } } // 真实节点列表 private static ListrealNodes = new ArrayList (); // 虚拟节点,key是Hash值,value是虚拟节点信息 private static SortedMap virtualMap = new TreeMap ,>(); static { //初始化真实节点列表 realNodes.add(new Node("192.168.1.1", 5)); realNodes.add(new Node("192.168.1.2", 10)); realNodes.add(new Node("192.168.1.3", 20)); realNodes.add(new Node("192.168.1.4", 5)); for (Node node : realNodes) { //添加虚拟节点 for (int i = 0; i < node.getLoad(); i++) { String server = node.getHost(); String virtualNode = server + "&&VN" + i; int hash = getHash(virtualNode); virtualMap.put(hash, virtualNode); } } } /** * FNV1_32_HASH算法 */ private static int getHash(String str) { final int p = 16777619; int hash = (int) 2166136261L; for (int i = 0; i < str.length(); i++) hash = (hash ^ str.charAt(i)) * p; hash += hash << 13; hash ^= hash >> 7; hash += hash << 3; hash ^= hash >> 17; hash += hash << 5; // 如果算出来的值为负数则取其绝对值 if (hash < 0) hash = Math.abs(hash); return hash; } /** * 获取被分配的节点名 * * @param node * @return */ public static Node getNode(String key) { int hash = getHash(key);// Integer keyNode = null; // 得到大于该Hash值的所有Map SortedMap ,>subMap = virtualMap.tailMap(hash); if (subMap.isEmpty()) {//在这里形成一个环形结构 //如果没有比该key的hash值大的,则从第一个node开始 keyNode = virtualMap.firstKey(); } else { //获取第一个key值,也就是顺时针第一个节点 keyNode = subMap.firstKey(); } String virtualNode = virtualMap.get(keyNode);//获取虚拟节点 String realNodeName = virtualNode.substring(0, virtualNode.indexOf("&&")); for (Node node : realNodes) {//根据虚拟节点获取真实节点 if (node.getHost().equals(realNodeName)) { return node; } } return null; } ,>
按数据范围(range based)
按数据范围分片其实也就是基于数据的业务属性进行分片,如唯一编码、时间戳、使用频率等,比如在数据库层面按ID范围、按时间进行分库、分表、分片,按数据被访问频率分为热点库与历史库等方法,都是按数据范围方式的具体应用。基于数据范围的分片模式需要贴合项目实际场景,使用中需要注意以下几点:
1、 分片与扩展实现比较简单,结合ID范围、时间结合业务自行实现即可;
2、较为依赖备份机制,否则某个节点发生异常无法迅速恢复,可用性较难保证;
3、对数据规模要有前瞻性的评估,例如按时间分片,需要考虑单位时间片内数据分布是否均匀;
4、注意各分片数据之间的性能平衡,因为在常规场景下,无论采用哪种基于数据范围的分片模式,都是距离当前时间点较近的数据被访问和操作的几率较大,所以要特别注意随着数据规模与时间的推移,历史数据规模不断膨胀导致的整体性能下降。
综上是对项目开发中我们使用的数据分片模式的一个简单总结,hash与一致性hash有着相对固定的实现方式,按数据范围则需要结合业务数据属性进行分析,我们要意识到数据分片在项目中不是一个孤立的问题,它关系着数据备份、一致性、可用性、负载均衡、数据访问与操作等等一系列问题,所以需要系统性的去学习与思考,本文内容只是一个基础性的阐述与总结,其中如有不足与不正确的地方还望指正与海涵,十分感谢。
关注微信公众号,查看更多技术文章。

Original: https://www.cnblogs.com/dafanjoy/p/15086057.html
Author: DaFanJoy
Title: 架构设计之数据分片
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/714678/
转载文章受原作者版权保护。转载请注明原作者出处!