

只要业务逻辑代码写正确,处理好业务状态在多线程的并发问题,很少会有调优方面的需求。最多就是在性能监控平台发现某些接口的调用耗时偏高,然后再发现某一SQL或第三方接口执行超时之类的。如果你是负责中间件或IM通讯相关项目开发,或许就需要偏向CPU、磁盘、网络及内存方面的问题排查及调优技能
- CPU过高,怎么排查问题
- linux内存
- 磁盘IO
- 网络IO
- java 应用内存泄漏和频繁 GC
- java 线程问题排查
- 常用 jvm 启动参数调优
关注公众号,一起交流,微信搜一搜: 潜行前行
linux CPU 过高,怎么排查问题
CPU 指标解析
- 平均负载
- 平均负载等于逻辑 CPU 个数,表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,则负载比较重
- 进程上下文切换
- 无法获取资源而导致的自愿上下文切换
- 被系统强制调度导致的非自愿上下文切换
- CPU 使用率
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断),系统 CPU 使用率高,说明内核比较繁忙
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,说明系统与硬件设备的 I/O 交互时间比较长
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,表明系统发生了大量的中断
查看系统的平均负载
$ uptime
10:54:52 up 1124 days, 16:31, 6 users, load average: 3.67, 2.13, 1.79
- 10:54:52 是当前时间;up 1124 days, 16:31 是系统运行时间; 6 users 则是正在登录用户数。而最后三个数字依次是过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)。平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数
- 当平均负载高于 CPU 数量 70% 的时候,就应该分析排查负载高的问题。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能
- 平均负载与 CPU 使用率关系
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高
CPU 上下文切换
- 进程上下文切换:
- 进程的运行空间可以分为内核空间和用户空间,当代码发生系统调用时(访问受限制的资源),CPU 会发生上下文切换,系统调用结束时,CPU 则再从内核空间换回用户空间。一次系统调用,两次 CPU 上下文切换
- 系统平时会按一定的策略调用进程,会导致进程上下文切换
- 进程在阻塞等到访问资源时,也会发生上下文切换
- 进程通过睡眠函数挂起,会发生上下文切换
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起
- 线程上下文切换:
- 同一进程里的线程,它们共享相同的虚拟内存和全局变量资源,线程上下文切换时,这些资源不变
- 线程自己的私有数据,比如栈和寄存器等,需要在上下文切换时保存切换
- 中断上下文切换:
- 为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件
查看系统的上下文切换情况:
vmstat 和 pidstat。vmvmstat 可查看系统总体的指标,pidstat则详细到每一个进程服务的指标
$ vmstat 2 1
procs --------memory--------- --swap-- --io--- -system-- ----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 3498472 315836 3819540 0 0 0 1 2 0 3 1 96 0 0
PID 进程id
Cswch/s 每秒主动任务上下文切换数量
Nvcswch/s 每秒被动任务上下文切换数量。大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换
Command 进程执行命令
怎么排查 CPU 过高问题
- 先使用 top 命令,查看系统相关指标。如需要按某指标排序则 使用
top -o 字段名如:top -o %CPU。-o可以指定排序字段,顺序从大到小
top -o %MEM
top - 18:20:27 up 26 days, 8:30, 2 users, load average: 0.04, 0.09, 0.13
Tasks: 168 total, 1 running, 167 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.5 sy, 0.0 ni, 99.1 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem: 32762356 total, 14675196 used, 18087160 free, 884 buffers
KiB Swap: 2103292 total, 0 used, 2103292 free. 6580028 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2323 mysql 20 0 19.918g 4.538g 9404 S 0.333 14.52 352:51.44 mysqld
1260 root 20 0 7933492 1.173g 14004 S 0.333 3.753 58:20.74 java
1520 daemon 20 0 358140 3980 776 S 0.333 0.012 6:19.55 httpd
1503 root 20 0 69172 2240 1412 S 0.333 0.007 0:48.05 httpd
rrqm/s: 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并
wrqm/s: 每秒对该设备的写请求被合并次数
r/s: 每秒完成的读次数
w/s: 每秒完成的写次数
rkB/s: 每秒读数据量(kB为单位)
wkB/s: 每秒写数据量(kB为单位)
avgrq-sz: 平均每次IO操作的数据量(扇区数为单位)
avgqu-sz: 平均等待处理的IO请求队列长度
await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)
svctm: 平均每次IO请求的处理时间(毫秒为单位)
%util: 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率
- 查看进程级别 I/O
pidstat -d
Linux 3.10.0-862.el7.x86_64 (8f57ec39327b) 07/11/2021 _x86_64_ (6 CPU)
06:42:35 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
06:42:35 PM 0 1 1.05 0.00 0.00 java
06:42:35 PM 0 102 0.04 0.05 0.00 bash
FD 表示文件描述符号,TYPE 表示文件类型,NODE NAME 表示文件路径
- lsof 也可以看出进程18940 以每次 300MB 的速度往 /tmp/logtest.txt 写入
linux 网络I/O 问题
当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中;然后通过硬中断,告诉中断处理程序已经收到了网络包。接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中;然后再通过软中断,通知内核收到了新的网络帧。内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧
- 硬中断:与系统相连的外设(比如网卡、硬盘)自动产生的。主要是用来通知操作系统系统外设状态的变化。比如当网卡收到数据包的时候,就会发出一个硬中断
- 软中断:为了满足实时系统的要求,中断处理应该是越快越好。linux为了实现这个特点,当中断发生的时候,硬中断处理那些短时间就可以完成的工作,而将那些处理事件比较长的工作,交给软中断来完成
网络I/O指标
- 带宽,表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)
- 吞吐量,表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率
- 延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)
- PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响
- 网络的连通性
- 并发连接数(TCP 连接数量)
- 丢包率(丢包百分比)
查看网络I/O指标
- 查看网络配置
ifconfig em1
em1 Link encap:Ethernet HWaddr 80:18:44:EB:18:98
inet addr:192.168.0.44 Bcast:192.168.0.255 Mask:255.255.255.0
inet6 addr: fe80::8218:44ff:feeb:1898/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:3098067963 errors:0 dropped:5379363 overruns:0 frame:0
TX packets:2804983784 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1661766458875 (1584783.9 Mb) TX bytes:1356093926505 (1293271.9 Mb)
Interrupt:83
rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒
rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒
rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒
- 宽带
ethtool em1 | grep Speed
Speed: 1000Mb/s
- 连通性和延迟
ping www.baidu.com
PING www.a.shifen.com (14.215.177.38) 56(84) bytes of data.
64 bytes from 14.215.177.38: icmp_seq=1 ttl=56 time=53.9 ms
64 bytes from 14.215.177.38: icmp_seq=2 ttl=56 time=52.3 ms
64 bytes from 14.215.177.38: icmp_seq=3 ttl=56 time=53.8 ms
64 bytes from 14.215.177.38: icmp_seq=4 ttl=56 time=56.0 ms
- 统计 TCP 连接状态工具 ss 和 netstat
[root@root ~]$>#ss -ant | awk '{++S[$1]} END {for(a in S) print a, S[a]}'
LISTEN 96
CLOSE-WAIT 527
ESTAB 8520
State 1
SYN-SENT 2
TIME-WAIT 660
[root@root ~]$>#netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
CLOSE_WAIT 530
ESTABLISHED 8511
FIN_WAIT2 3
TIME_WAIT 809
网络请求变慢,怎么调优
- 高并发下 TCP 请求变多,会有大量处于 TIME_WAIT 状态的连接,它们会占用大量内存和端口资源。此时可以优化与 TIME_WAIT 状态相关的内核选项
- 增大处于 TIME_WAIT 状态的连接数量 net.ipv4.tcp_max_tw_buckets ,并增大连接跟踪表的大小 net.netfilter.nf_conntrack_max
- 减小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,让系统尽快释放它们所占用的资源
- 开启端口复用 net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中
- 增大本地端口的范围 net.ipv4.ip_local_port_range 。这样就可以支持更多连接,提高整体的并发能力
- 增加最大文件描述符的数量。可以使用 fs.nr_open 和 fs.file-max ,分别增大进程和系统的最大文件描述符数
- SYN FLOOD 攻击,利用 TCP 协议特点进行攻击而引发的性能问题,可以考虑优化与 SYN 状态相关的内核选项
- 增大 TCP 半连接的最大数量 net.ipv4.tcp_max_syn_backlog ,或者开启 TCP SYN Cookies net.ipv4.tcp_syncookies ,来绕开半连接数量限制的问题
- 减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数 net.ipv4.tcp_synack_retries
- 加快 TCP 长连接的回收,优化与 Keepalive 相关的内核选项
- 缩短最后一次数据包到 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_time
- 缩短发送 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_intvl
- 减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数 net.ipv4.tcp_keepalive_probes
java 应用内存泄漏和频繁 GC
区分内存溢出、内存泄漏、内存逃逸
- 内存泄漏:内存被申请后始终无法释放,导致内存无法被回收使用,造成内存空间浪费
- 内存溢出:指内存申请时,内存空间不足
- 1-内存上限过小
- 2-内存加载数据太多
- 3-分配太多内存没有回收,出现内存泄漏
- 内存逃逸:是指程序运行时的数据,本应在栈上分配,但需要在堆上分配,称为内存逃逸
- java中的对象都是在堆上分配的,而垃圾回收机制会回收堆中不再使用的对象,但是筛选可回收对象,回收对象还有整理内存都需要消耗时间。如果能够通过 逃逸分析确定对象不会逃出方法之外,那就可以让这个对象在栈上分配内存,对象所占用的内存就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力
- 线程同步本身比较耗时,如果确定一个变量不会逃逸出线程,无法被其它线程访问到,那这个变量的读写就不会存在竞争,对这个变量的同步措施可以清除
- java 虚拟机中的原始数据类型(int,long及reference类型等) 都不能再进一步分解,它们称为标量。如果一个数据可以继续分解,那它称为聚合量,java 中最典型的聚合量是对象。如果逃逸分析证明一个对象不会被外部访问,并且这个对象是可分解的,那程序运行时可能不创建该对象,而改为直接创建它的若干个被方法使用到的成员变量来代替。拆散后的变量便可以被单独分析与优化,可以各自分别在栈帧或寄存器上分配空间,原本的对象就无需整体分配空间
内存泄漏,该如何定位和处理
- 使用
jmap -histo:live [pid]和jmap -dump:format=b,file=filename [pid]前者可以统计堆内存对象大小和数量,后者可以把堆内存 dump 下来 - 启动参数中指定
-XX:+HeapDumpOnOutOfMemoryError来保存OOM时的dump文件 - 使用 JProfiler 或者 MAT 软件查看 heap 内存对象,可以更直观地发现泄露的对象
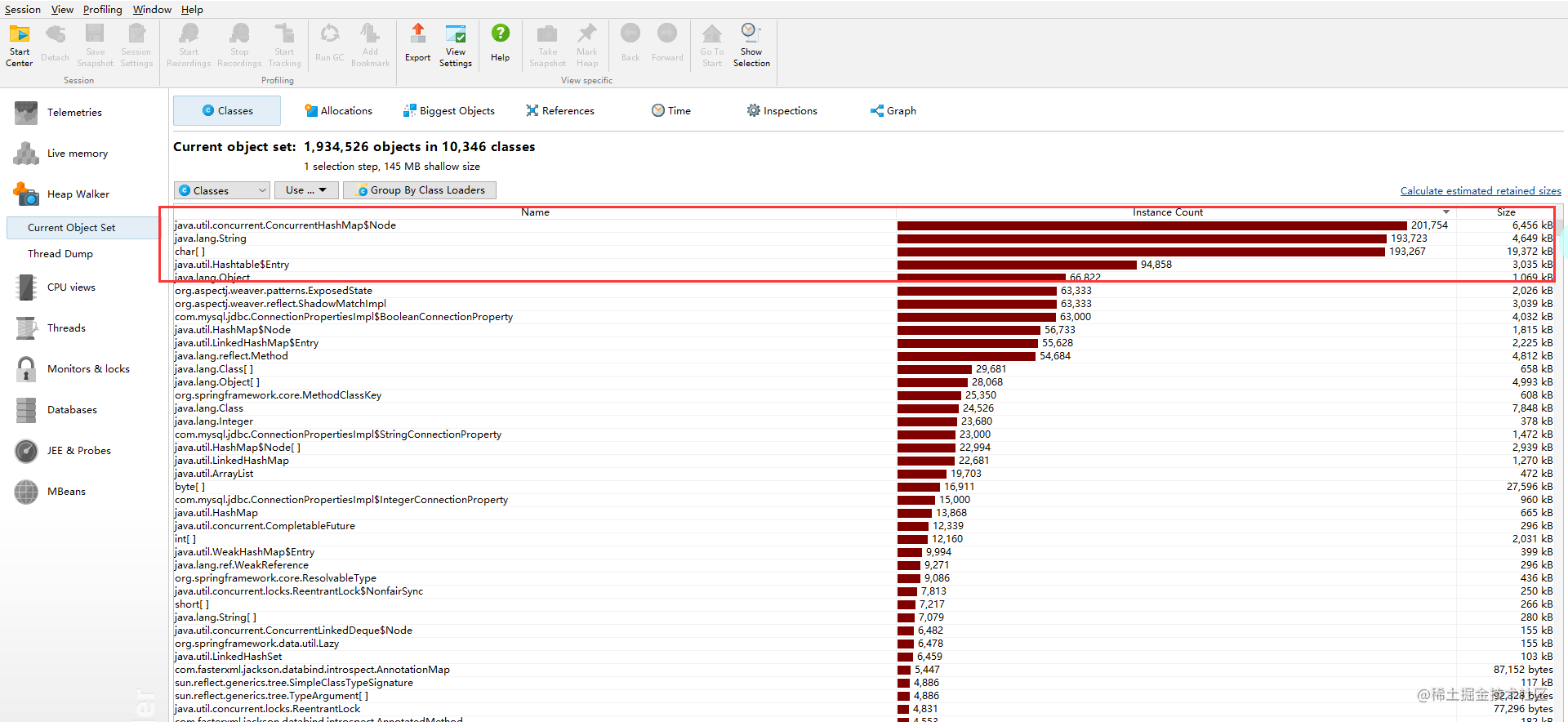

java线程问题排查
java 线程状态
- NEW:对应没有 Started 的线程,对应新生态
- RUNNABLE:对于就绪态和运行态的合称
- BLOCKED,WAITING,TIMED_WAITING:三个都是阻塞态
- sleep 和 join 称为WAITING
- sleep 和 join 方法设置了超时时间的,则是 TIMED_WAITING
- wait 和 IO 流阻塞称为BLOCKED
- TERMINATED: 死亡态
线程出现死锁或者被阻塞
jstack –l pid | grep -i –E 'BLOCKED | deadlock', 加上参数 -l,jstack 命令可以快速打印出造成死锁的代码
jstack -l 28764
Full thread dump Java HotSpot(TM) 64-Bit Server VM (13.0.2+8 mixed mode, sharing):
.....
"Thread-0" #14 prio=5 os_prio=0 cpu=0.00ms elapsed=598.37s tid=0x000001b3c25f7000 nid=0x4abc waiting for monitor entry [0x00000061661fe000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.Test$DieLock.run(Test.java:52)
- waiting to lock (a java.lang.Object)
- locked (a java.lang.Object)
at java.lang.Thread.run(java.base@13.0.2/Thread.java:830)
Locked ownable synchronizers:
- None
"Thread-1" #15 prio=5 os_prio=0 cpu=0.00ms elapsed=598.37s tid=0x000001b3c25f8000 nid=0x1984 waiting for monitor entry [0x00000061662ff000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.Test$DieLock.run(Test.java:63)
- waiting to lock (a java.lang.Object)
- locked (a java.lang.Object)
at java.lang.Thread.run(java.base@13.0.2/Thread.java:830)
.....
Found one Java-level deadlock:
=============================
"Thread-0":
waiting to lock monitor 0x000001b3c1e4c480 (object 0x0000000712d7c230, a java.lang.Object),
which is held by "Thread-1"
"Thread-1":
waiting to lock monitor 0x000001b3c1e4c080 (object 0x0000000712d7c220, a java.lang.Object),
which is held by "Thread-0"
Java stack information for the threads listed above:
===================================================
"Thread-0":
at com.Test$DieLock.run(Test.java:52)
- waiting to lock (a java.lang.Object)
- locked (a java.lang.Object)
at java.lang.Thread.run(java.base@13.0.2/Thread.java:830)
"Thread-1":
at com.Test$DieLock.run(Test.java:63)
- waiting to lock (a java.lang.Object)
- locked (a java.lang.Object)
at java.lang.Thread.run(java.base@13.0.2/Thread.java:830)
Found 1 deadlock.
- 从 jstack 输出的日志可以看出线程阻塞在 Test.java:52 行,发生了死锁
常用 jvm 调优启动参数
- -verbose:gc 输出每次GC的相关情况
- -verbose:jni 输出native方法调用的相关情况,一般用于诊断jni调用错误信息
- -Xms n 指定jvm堆的初始大小,默认为物理内存的1/64,最小为1M;可以指定单位,比如k、m,若不指定,则默认为字节
- -Xmx n 指定jvm堆的最大值,默认为物理内存的1/4或者1G,最小为2M;单位与-Xms一致
- -Xss n 设置单个线程栈的大小,一般默认为512k
- -XX:NewRatio=4 设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
- -Xmn 设置新生代内存大小。整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8
- -XX:SurvivorRatio=4 设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
- -XX:MaxTenuringThreshold=0 设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概率
欢迎指正文中错误
参考文章
- Linux性能优化实践(倪鹏飞)
- JAVA 线上故障排查套路,从 CPU、磁盘、内存、网络到GC 一条龙!
- Java 应用线上问题排查思路、工具小结
- 双十一压测&Java应用性能问题排查总结
- # 一次线上JVM Young GC调优,搞懂了这么多东西!
Original: https://www.cnblogs.com/cscw/p/16087758.html
Author: 潜行前行
Title: 技能篇:linux服务性能问题排查及jvm调优思路
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/714664/
转载文章受原作者版权保护。转载请注明原作者出处!