

一个消息系统说白了无非就是由三部分组成,不同的消息系统只是这三部分的实现不同,或者会在这三部分之外扩充自己的特性。这三部分分别就是:生产者、消费者、消息队列
这篇文章主要介绍的是 kafka 的生产者。
定义
这里简单的对 kafka 的生产者做个介绍,kafka 主要应用于 iot 设备、网页 or App 用户行为收集、日志采集、系统指标采集。
例如,在一个 App 里,这里假设是抖音,需要收集用户的行为。每当用户点击一个小视频,生产者就会将小视频对应的信息(各种tag:所属领域、年龄段、行业)发送到 kafka。然后有个应用程序从 kafka 读取这些消息做用户行为分析,另一个应用程序从 kafka 读取这些消息做推荐算法分析。
在大多数公司中,由于中间件开发人员都帮我们封装好了各种细节,使用起来很简单,无非就是 xxx.send() ,就可以把消息发送出去,然后就不操心了。但是作为使用者,我们还是有必要了解一下一些更深层次的东西,以便出现问题的时候知道是哪里出现问题然后和中间件研发人员一起解决。
消息发送过程
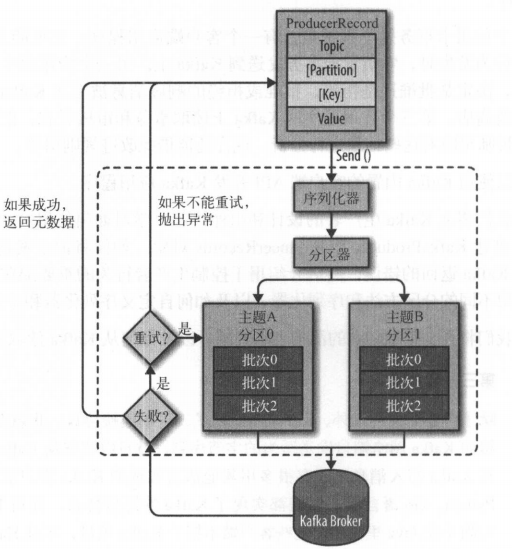

图片来源:kafka 权威指南
如上图,一个消息记录是一个 ProducerRecord 对象,对象包含了四个属性:Topic(主题)、partition(分区)、key(key)、value(我们要发送的内容)。其中 topic 和 value 是必须的,key 和 partition 是可选的。构建好一个消息对象后,就要准备发送了,在发送的时候,生产者需要将 key 和 value 序列化成 byte 数组,发送会经过分区器,如果指定了 key,那么相同 key 的消息会发往同一个分区,如果实现了自定义分区器,那么就会走自定义分区器进行分区路由,否则就是根据 kafka 客户端 api 的 hash 算法将消息发送到计算出来的分区。发送的时候并不是来一个消息就发送一个消息,这样的话吞吐量比较低,并且频繁的进行网络请求。消息是按照批次来发送的,这个批次里的消息会发送到相同的主题分区。如果消息发送成功,那么 kafka 会返回一个包含了主题和分区信息以及记录在分区里偏移量。如果发送失败会返回一个失败信息,生产者客户端会自动重试,多次重试失败会返回错误信息。
发送消息到 kafka
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++)
producer.send(new ProducerRecord("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
这里有三个必须指定的发送配置
- bootstrap.servers(kafka 服务器地址以及ip)
- key.serializer(key 序列化器)
- value.serializer(value 序列化器)
如上代码,消息是以 ProducerRecord 对象为单位的。首先要创建一个发送者对象 KafkaProducer,然后构造一个 ProducerRecord 对象封装消息内容,然后 send 就可以了。在发送完毕后要 close 掉生产者对象,否则可能会进行消息丢失(一般来说是一个应用系统要结束的时候关闭即可,不用发送一条关闭一次)。因为 close 会将发送缓冲里还没发送的消息发送出去。
以上代码是针对那些不关心发送结果的场景比较适用的,发送出去就发送出去了,由生产者配置来保证消息可靠性。
如果需要关心发送结果的话可以使用同步发送消息和异步发送消息
同步发送
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++) {
RecordMetadata result = producer
.send(new ProducerRecord("my-topic", Integer.toString(i), Integer.toString(i)))
.get();
}
producer.close();
send() 方法返回的其实是一个 future 对象,因此可以调用 get() 方法阻塞住,直到受到消息发送结果的响应消息,然后再发送下一条。
这种发送方式吞吐量是很慢的,相当于是一条消息一条消息的进行发送,如果发送一条消息需要 10 ms,那么100条消息就需要 1s 了。所以几乎没有场景会使用这种发送方式
异步发送
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++) {
producer.send(new ProducerRecord("my-topic", Integer.toString(i), Integer.toString(i)), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
}
});
}
producer.close();
异步发送不会阻塞发送流程,但是可以通过回调获取响应信息,无论成功还是失败,这种发送方式是使用最多的。
在吞吐量方面,不关心发送结果,也就是直接 send 是吞吐量最高的,其次是异步发送回调获取结果,最差是同步发送。
发送缓冲
前面也说过了,通常情况下消息不是一条一条发送的,而是一个批次一个批次的发,最大程度的提高吞吐量。
在发送方,会有一个发送缓冲,一个分区对应一个缓冲区,该缓冲区的消息只往该分区发送。缓冲区里的消息又是以批次为单位的,一个批次满了发送一波,但是也不是必须满了才能发,最极限情况下还是有可能一个批次只有一条消息。为什么这么设计呢,我们都知道吞吐量和实时性是有点互斥的,你想提高吞吐就得降低实时性,想提高实时性就得降低吞吐。缓冲区和批次是为了提高吞吐量而设计的,但是在消息量少的情况下,可能很久才会由一条消息,这样要等一个批次满的话实时性就太低了,如果是对时效性有要求的系统,那么这条消息相当于废了。因此,有时候不一定会等批次满了才发送,这里有个配置会在后面介绍到。
发送缓冲也会有问题,就是当往缓冲里发送的速度大于缓冲往kafka发送的速度时,这时候缓冲区就会满,这时候生产者会阻塞一会儿,如果阻塞的时间大于配置的时间,就会返回超时错误,这个配置时间后面配置部分也会介绍到。
发送保证
针对不同的应用场景,有不同的发送保证,有些场景必须要求严格的要求kafka消息写入成功,不允许消息丢失、重复,如支付系统,信用卡交易系统。有些系统可以允许消息有少量的丢失,重复,如前面的 APP 用户行为收集,消息丢失重复了并不会产生太大影响。
这里有个配置可以进行消息的发送保证。
acks 参数:acks,参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息是写入成功的,这个参数对消息丢失的可能性有重要影响。
- acks = 0:不关心服务器是否写入成功,发送就发送了,副本写没写成功是副本的事,成功就成功,失败就是失败,由于这种佛性行为,导致他的吞吐量是最高的,疯狂发送,不关心结果。当然,这种也是保证性最低的配置
- acks = 1:分区 leader 副本写入成功就认为成功,然后收到来自服务器的一个写入成功的响应。这时候如果 leader 挂了,并且新 leader 没有同步到该条消息,那么这条消息也就丢失了。
- acks = all:所有分区副本写入成功才算写入成功,才会收到来自服务器的一个写入成功的响应。这种模式是最安全的,因为只要有一个副本是存活的,那么整个系统就是可用的。
发送失败
消息不是一直都会发送成功的,发送失败也分为可重试恢复错误和不可重试恢复错误。当然不管是什么错误,只要发送失败了,客户端就会自动的进行失败重试。
可重试恢复错误
- 找不到 leader
- 找不到目标分区
这种情况往往重试一下就能发送成功
不可重试恢复错误
- 消息体过大
- 缓冲区满了
这种情况即使你再重试也是会失败的,因为消息体过大除非你减少消息量,或者采用压缩算法,重试是没用的。
生产者配置
以下参数都可以通过代码方式设置:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++)
producer.send(new ProducerRecord("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
acks
前面介绍过了
buffer.memory
该参数用来设置生产者内存缓冲区的大小,生产者用它来缓冲要发送到服务器的消息,如果应用程序发送消息的速度大于缓冲区往服务器发送的速度,那么就会导致缓冲区空间不足,这时候 send() 方法要么阻塞要么抛出异常,取决于 max.block.ms 参数,表示在抛出异常之前可用阻塞一段时间。
compression.type
消息压缩算法,可以指定为:snappy、gzip、lz4,使用压缩可以降低网络传输开销和存储开销,这往往是 kafka 发送消息的瓶颈所在。默认情况下不会压缩。
retries
生产者从服务器收到的消息有可能是临时错误,比如 leader 不存在。这种情况下,该参数指定了可以尝试的次数,如果达到这个次数,那么生产者就会放弃重试,返回错误。默认情况下,每次重试之间会等待 100 ms,不过可以通过 retry.backoff.ms 参数来改变这个时间间隔。
batch.size
当有多个消息需要发送到同一个分区的时候,生产者会将他们放到同一个批次里,该参数指定了一个批次可以使用的内存大小,按照字节计算,当批次被填满,批次里的消息会被发送出去,当然生产者不一定都会等批次被填满才发送,半满的批次甚至只有一个消息的批次也有可能被发送。
linger.ms
该参数指定了生产者在发送批次之前等待更多消息加入批次的时间,生产者会在批次填满或者达到这个时间时把批次发送出去,默认情况下,只要有可用的线程,生产者就会把消息发送出去,就算批次里只有一个消息。把 linger.ms 设置成比 0 大的数,让生产者在发送批次之前等待一会儿,使更多消息加入到这个批次,这样虽然会增加延迟,但是也会提升吞吐量,因为一次性发送更多消息,每个消息的开销就变小了。
max.in.flight.requests.per.connection
该参数指定了生产者在收到服务器响应之前可用发送多少个信息,它的值越高,就会占用越多的内存不过会提升吞吐量,把它设为 1 可以保证消息时按照发送的顺序写入服务器的,即使发生了重试。
timeout.ms
timeout.ms 指定了 broker 等待同步副本返回消息确认的时间,与 acks 的配置配置相匹配,如果在指定时间内没有收到同步副本的确认,那么 broker 就会返回一个错误
request.timeout.ms
指定了生产者在发送数据时等待服务器返回响应的时间,如果等待超时,要么重试发送数据,那么返回一个错误(抛出异常或执行回调)
指定了生产者在获取元数据(比如目标分区的首领是谁)时等待服务器返回相应的事件,如果等待超时,要么重试发送数据,那么返回一个错误(抛出异常或执行回调)
max.block.ms
该参数指定了在调用 send() 方法或者使用 partitionsFor() 方法获取元素据时生产者的阻塞事件。当生产者的发送缓冲已满或者没有可用的元素据的时候,就会阻塞。如果阻塞到达设定的时间,生产者就会抛出超时异常。
max.request.size
该参数指定了一次请求的大小,可以是一个消息就到达了这个大小,也可以是一个批次才到达这个大小,broker 也有一个可接受消息的最大大小,两者最好能够匹配。
顺序保证
kafka 可以保证同一个分区里的消息是有序的,按照生产者发送顺序进行写入分区。消费者也是按照同样的顺序进行读取。某些情况下顺序很重要,比如先存钱再消费和先消费再存钱就是两种性质。
什么情况下会导致顺序不一致呢。如果把 retries 设置非零整数,同时把 max.in.flight.requests.connection 设置为比 1 大的数,那么,如果第一次批次消息写入失败,第二个批次写入成功,然后第一个批次重试后成功,这时候两个批次的顺序就反过来了。
如果有些场景是要求顺序是有序的,那么可以把 retries 设置为 0 ,失败不重试。但是往往消息是否写入成功也是很关键的,因此可以把 max.in.flight.requests.connection 设置为 1。这样生产者在发送第一批消息时,就不会有其他消息发送给 broker。但是这样会严重影响生产者的吞吐量,因此需要仔细评估是否对顺序有严格要求。
序列化器
消息里面的 key 和 value 都需要序列化成 byte 数组才能发送到服务器,序列化器有很多,有默认的字符串序列化器,常见的序列化框架有 Avro、Thrift、Protobuf,kafka 使用的时 Avro。当然,也可以指定为自己自己实现的序列化器 。这里就不详细展开。
总结
kafka 生产者可以根据自己的业务场景,是需要高吞吐还是低延迟,是需要消息的严格不丢失、顺序性、不重复,还是允许消息丢失、无序、重复。使用者可以进行考量从而使用不同的配置参数。
ps
文章为本人学习过程中的一些个人见解,漏洞是必不可少的,希望各位大佬多多指教,帮忙修复修复漏洞!!!
参考资料
《kafka 权威指南》
Original: https://www.cnblogs.com/cyrus-s/p/15550980.html
Author: 三木同学
Title: Kafka 生产者
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/713760/
转载文章受原作者版权保护。转载请注明原作者出处!