

该代码是 python-torch 写的!
请看序列(一、二、三)
一、模型概述
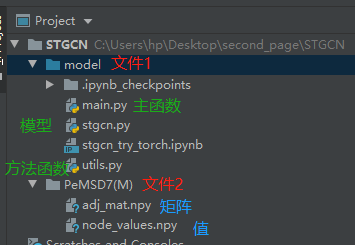
文件分布
首先看文件的内容:STSGCN中包含两个文件夹:model,PeMSD7(M) 。model文件中包含:main.py,stsgcn.py ,utils.py三个文件。PeMSD7(M)中包含:矩阵文件 adj_mat.npy和特征数据node_values.npy两个文件。

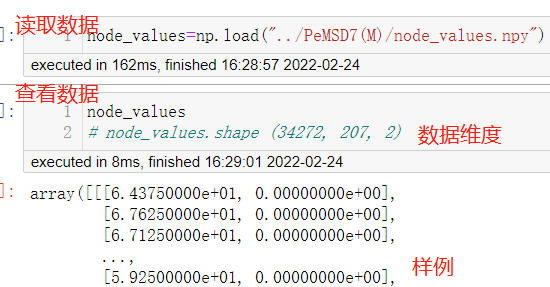
; PeMSD7(M)中的数据
特征数据为:(34722,207,2)
矩阵数据为:(207,207)
表明共有207个节点,每个节点2个特征
二、导入库和参数设置–main.py
import os
import argparse
import pickle as pk
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from stgcn import STGCN
from utils import generate_dataset, load_metr_la_data, get_normalized_adj
use_gpu = False
num_timesteps_input = 12
num_timesteps_output = 3
epochs = 1000
batch_size = 50
parser = argparse.ArgumentParser(description='STGCN')
parser.add_argument('--enable-cuda', action='store_true',
help='Enable CUDA')
args = parser.parse_args()
args.device = None
if args.enable_cuda and torch.cuda.is_available():
args.device = torch.device('cuda')
else:
args.device = torch.device('cpu')
三、查看主函数–main.py
if __name__ == '__main__':
torch.manual_seed(7)
A, X, means, stds = load_metr_la_data()
print("数据加载...")
split_line1 = int(X.shape[2] * 0.6)
split_line2 = int(X.shape[2] * 0.8)
train_original_data = X[:, :, :split_line1]
val_original_data = X[:, :, split_line1:split_line2]
test_original_data = X[:, :, split_line2:]
training_input, training_target = generate_dataset(train_original_data,
num_timesteps_input=num_timesteps_input,
num_timesteps_output=num_timesteps_output)
val_input, val_target = generate_dataset(val_original_data,
num_timesteps_input=num_timesteps_input,
num_timesteps_output=num_timesteps_output)
test_input, test_target = generate_dataset(test_original_data,
num_timesteps_input=num_timesteps_input,
num_timesteps_output=num_timesteps_output)
print("数据生成器")
A_wave = get_normalized_adj(A)
A_wave = torch.from_numpy(A_wave)
A_wave = A_wave.to(device=args.device)
print("矩阵归一化后并存在设备上")
net = STGCN(A_wave.shape[0],
training_input.shape[3],
num_timesteps_input,
num_timesteps_output).to(device=args.device)
print("模型实例化并且存放在设备上")
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
loss_criterion = nn.MSELoss()
print("建立损失函数和优化器")
training_losses = []
validation_losses = []
validation_maes = []
for epoch in range(epochs):
loss = train_epoch(training_input, training_target,
batch_size=batch_size)
training_losses.append(loss)
with torch.no_grad():
net.eval()
val_input = val_input.to(device=args.device)
val_target = val_target.to(device=args.device)
out = net(A_wave, val_input)
val_loss = loss_criterion(out, val_target).to(device="cpu")
validation_losses.append(np.asscalar(val_loss.detach().numpy()))
out_unnormalized = out.detach().cpu().numpy()*stds[0]+means[0]
target_unnormalized = val_target.detach().cpu().numpy()*stds[0]+means[0]
mae = np.mean(np.absolute(out_unnormalized - target_unnormalized))
validation_maes.append(mae)
out = None
val_input = val_input.to(device="cpu")
val_target = val_target.to(device="cpu")
print("Training loss: {}".format(training_losses[-1]))
print("Validation loss: {}".format(validation_losses[-1]))
print("Validation MAE: {}".format(validation_maes[-1]))
plt.plot(training_losses, label="training loss")
plt.plot(validation_losses, label="validation loss")
plt.legend()
plt.show()
checkpoint_path = "checkpoints/"
if not os.path.exists(checkpoint_path):
os.makedirs(checkpoint_path)
with open("checkpoints/losses.pk", "wb") as fd:
pk.dump((training_losses, validation_losses, validation_maes), fd)
注释:
with torch.no_grad():见链接no_grad()net.eval():用于测试或者评估之前。原因见参考博客园链接1和简书链接2。np.absolute=np.abs:对数组内每个元素求绝对值。在其上即求 mae
四、训练函数–main.py
def train_epoch(training_input, training_target, batch_size):
"""
Trains one epoch with the given data.
:param training_input: Training inputs of shape (num_samples, num_nodes,
num_timesteps_train, num_features).
:param training_target: Training targets of shape (num_samples, num_nodes,
num_timesteps_predict).
:param batch_size: Batch size to use during training.
:return: Average loss for this epoch.
"""
permutation = torch.randperm(training_input.shape[0])
epoch_training_losses = []
for i in range(0, training_input.shape[0], batch_size):
net.train()
optimizer.zero_grad()
indices = permutation[i:i + batch_size]
X_batch, y_batch = training_input[indices], training_target[indices]
X_batch = X_batch.to(device=args.device)
y_batch = y_batch.to(device=args.device)
out = net(A_wave, X_batch)
loss = loss_criterion(out, y_batch)
loss.backward()
optimizer.step()
epoch_training_losses.append(loss.detach().cpu().numpy())
return sum(epoch_training_losses)/len(epoch_training_losses)
注释:
torch.randperm:返回一个0到n-1的数组。
torch.randperm(n, out=None, dtype=torch.int64, layout=torch.strided, device=None, requires_grad=False)
torch.randperm(4)
tensor([ 2, 1, 0, 3])
optimizer.zero_grad()的原因:
- 梯度下降的原理和实现步骤
- 参数更新和反向传播
- 梯度清零
Original: https://blog.csdn.net/panbaoran913/article/details/123115022
Author: panbaoran913
Title: 【stgcn】代码解读之主函数(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/712914/
转载文章受原作者版权保护。转载请注明原作者出处!