

1. 穷举法和分治法
传统的穷举法和分治法都面临着搜索空间太大或者容易陷入局部最优的问题。
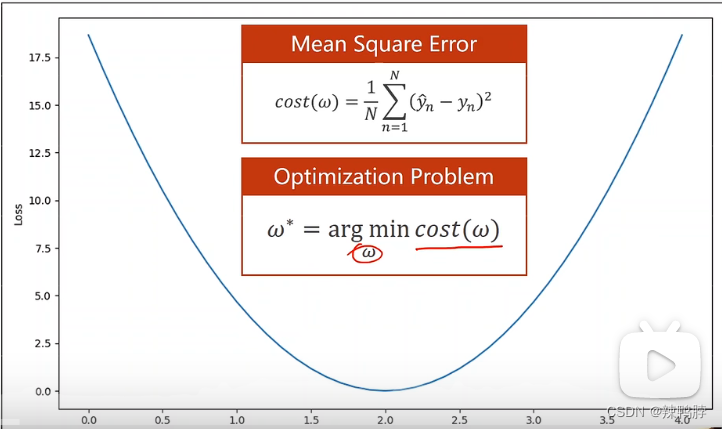

; 2. 梯度下降算法
优化问题就是指找使得w w w最小值的问题。
用目标函数对权重求导数,再用权重加上它导数乘以学习率(学习率就是它从那个方向走多远),就求得了它的上升方向。为什么上升是因为,假设Δ x > 0 \Delta x >0 Δx >0,当导数大于0时,说明随着x x x的增加,它是逐渐上升的。当导数小于0时,说明随着x x x的减少,他是逐渐上升的。 而这里我们要的是逐渐下降,所以导数的负方向,就是确定它下降的方向,所以取负号。
G r a d i e n t = ∂ c o s t ∂ w Gradient = \frac{\partial cost}{\partial w} \G r a d i e n t =∂w ∂cos t
如果用w = w + α G r a d i e n t w = w+\alpha Gradient w =w +αG r a d i e n t,这里对参数w w w的更新就是沿着使它函数上升的方向。因此要w = w − α G r a d i e n t w = w-\alpha Gradient w =w −αG r a d i e n t,这里就求得使函数值下降的方向更新w w w。
导数是函数的局部性质。一个函数在某一点的导数描述了这个函数在这一点附近的变化率。如果函数的自变量和取值都是实数的话,函数在某一点的导数就是该函数所代表的曲线在这一点上的切线斜率。导数的本质是通过极限的概念对函数进行局部的线性逼近。例如在运动学中,物体的位移对于时间的导数就是物体的瞬时速度。导数大于0单调递增,导数小于0单调递减。
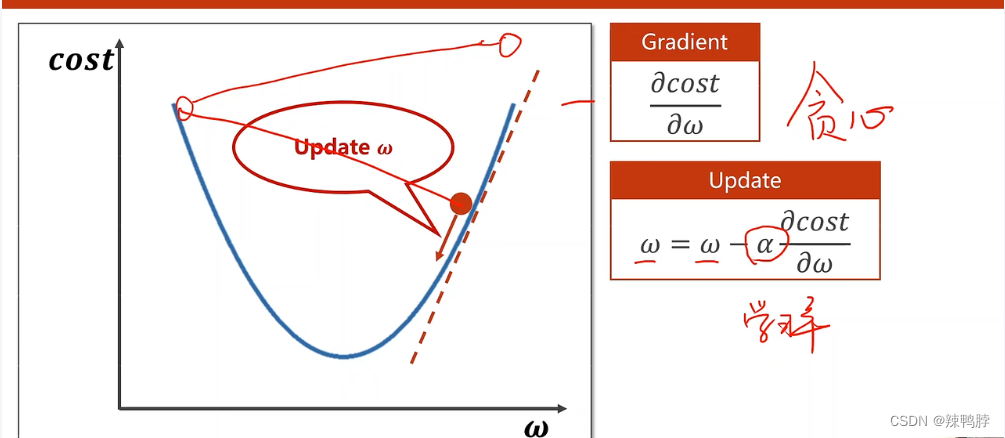
梯度下降算法同样求得是非凸函数的局部最优。那为什么会在深度学习中使用梯度下降算法呢,是因为深度学习的损失函数中,并没有很多的局部最优点。但深度学习中有很多的鞍点(梯度=0,当在高维空间时,有可能从一个维度看去是最低点,从另一个维度看去是最高点),当在鞍点时,参数就没法更新了。

2.1 梯度下降算法具体推理:

import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w=1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x,y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost/len(xs)
def gradient(xs, ys):
grad = 0
for x,y in zip(xs,ys):
grad += 2 * x * (x * w - y)
return grad/len(xs)
cost_list=[]
for epoch in range(100):
cost_val = cost(x_data, y_data)
cost_list.append(cost_val)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
print('Epoch:',epoch, 'w=', w, 'loss=', cost_val, 'grad=', grad_val)
plt.plot(range(100),cost_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
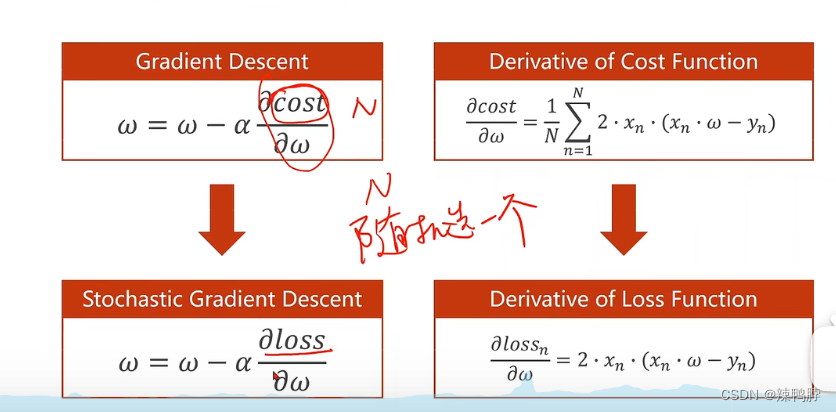
在深度学习中,更多使用的是随机梯度下降算法,因为梯度下降算法每次都是使用所有的样本计算后更新参数,容易陷入到鞍点。而最原始的随机梯度下降算法是使用一个样本去计算梯度并更新参数,这样将随机噪声引入进来容易推动梯度走出鞍点。【使用全部样本计算梯度的时间复杂度低,它可以并行计算。使用单个样本计算梯度的时间复杂度高,因为每个样本的参数都来源于上个样本,但是它的精度高。这样就引入了Batch的概念,两者择中。】
2.2 随机梯度下降算法
计算损失函数不需要所有的样本,一个样本即可。
计算梯度是,也同样一个样本即可。
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w=1.0
def forward(x):
return x * w
def cost(x, y):
y_pred = forward(x)
cost = (y_pred - y) ** 2
return cost
def gradient(x, y):
grad = 2 * x * (x * w - y)
return grad
cost_list=[]
for epoch in range(100):
for x,y in zip(x_data, y_data):
cost_val = cost(x, y)
cost_list.append(cost_val)
grad_val = gradient(x, y)
w -= 0.01 * grad_val
print('Epoch:',epoch, 'w=', w, 'loss=', cost_val, 'grad=', grad_val)
plt.plot(range(300),cost_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
一个一个算,得到的最优值更好。
计算的是损失函数对权重的导数,不是模型计算公式对权重的导数 ,因为我们的目标是使得损失函数最小。
简单的模型可以用解析式来做,复杂的就没法定义解析式了。
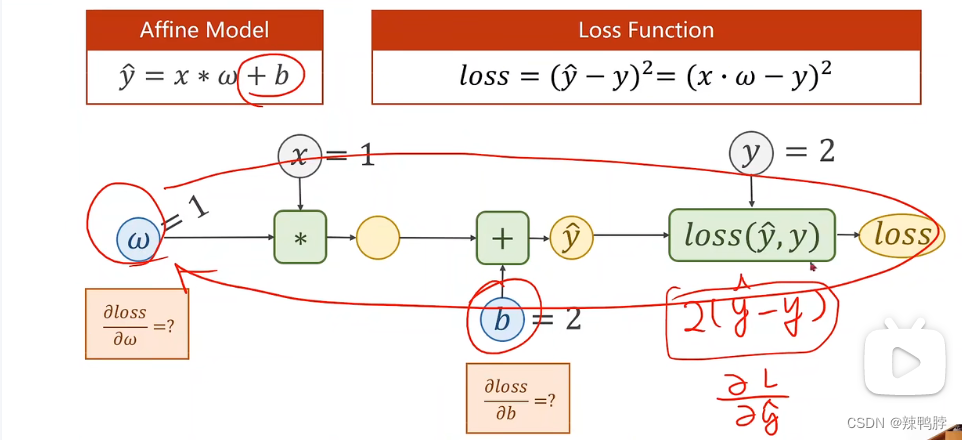
上图是计算图,最主要的两个部分,前馈传播和反向传播。只对权重参数求导数。
2.3使用PyTorch计算梯度
在PyTorch中进行前馈和反向传播,利用到Tensor,Tensor中主要的两个部分是Data和Grad。Data用来存储参数值,Grad用来存储导数。这样就相当于建立起来了计算图。(省去了以前的梯度函数定义,和梯度计算过程)

在pytorch中建立模型时,就是在建立起这样的计算图。
前馈过程只需要计算loss就可以,得到Tensor,调用张量的backward方法,会自动的在这条计算图上,把所有需要求梯度的地方都求出。求得值都会存储到这些变量里(参数w)。此时的计算图就会被释放掉,下一次计算时再创建。更新变量时,要使用w.data和w.grad.data来操作。如果不希望创建计算图时,取值时要用w.item()或者w.grad.item()取值。一定不要再次操作tensor,不然会构建计算图。
对梯度进行清零
第一步先算损失,第二步backward(),第三步根据梯度更新参数。
import torch
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0])
w.requires_grad = True
def forward(x):
return x * w
def loss(x,y):
return (y - forward(x)) ** 2
for epoch in range(100):
for x,y in zip(x_data,y_data):
l_loss = loss(x,y)
l_loss.backward()
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_()
print('progress:',epoch, l_loss.item())
完成下面的作业:

import torch
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w_1 = torch.Tensor([1.0])
w_2 = torch.Tensor([0.5])
b = torch.Tensor([1.0])
w_1.requires_grad = True
w_2.requires_grad = True
b.requires_grad = True
def forward(x):
return w_1 * x * x + w_2 * x + b
def loss(x,y):
y_predict = forward(x)
return (y_predict - y) **2
print("before training:", 4, forward(4).item())
loss_list=[]
for epoch in range(100):
for x,y in zip(x_data, y_data):
l = loss(x,y)
l.backward()
loss_list.append(l.item())
w_1.data -= 0.001 * w_1.grad.data
w_2.data -= 0.001 * w_2.grad.data
b.data -= 0.001 * b.grad.data
w_1.grad.data.zero_()
w_2.grad.data.zero_()
b.grad.data.zero_()
print('progress:', epoch, l.item())
print("after training:", 4, forward(4).item())
plt.plot(range(300),loss_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
3. 用Pytorch实现线性回归
用Pytorch提供的工具构建模型nn.Module、构建loss函数、构建sgd函数,重现线性模型。
之前在手工构建时,需要先确定模型函数,再确定损失函数,再计算损失函数关于权重的梯度,才可以逐步更新权重。
正向前馈:计算的是这组样本带来的损失
反向传播:将梯度求出来
更新:用梯度下降算法更新权重
; 3.1 Pytorch Fashion
Pytorch中重点是构造计算图。输入的矩阵,w和b矩阵的大小都是根据x和y的维度来的。
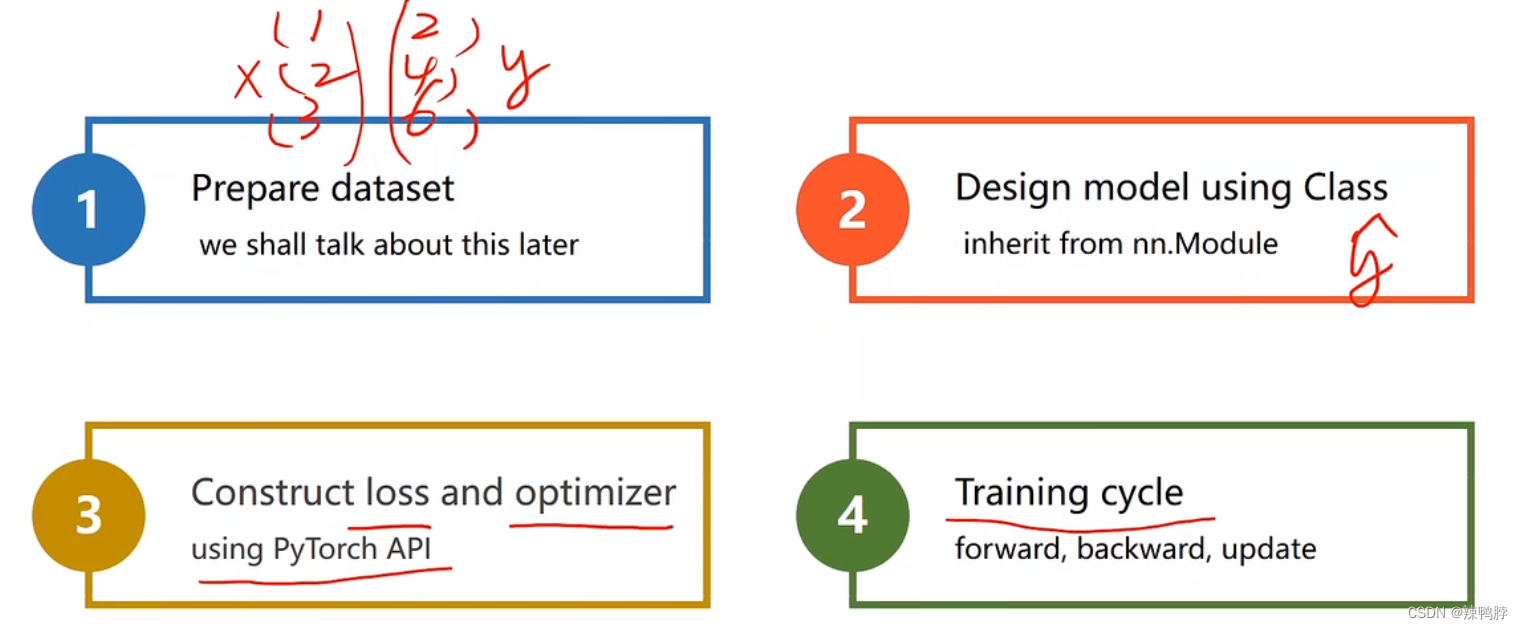
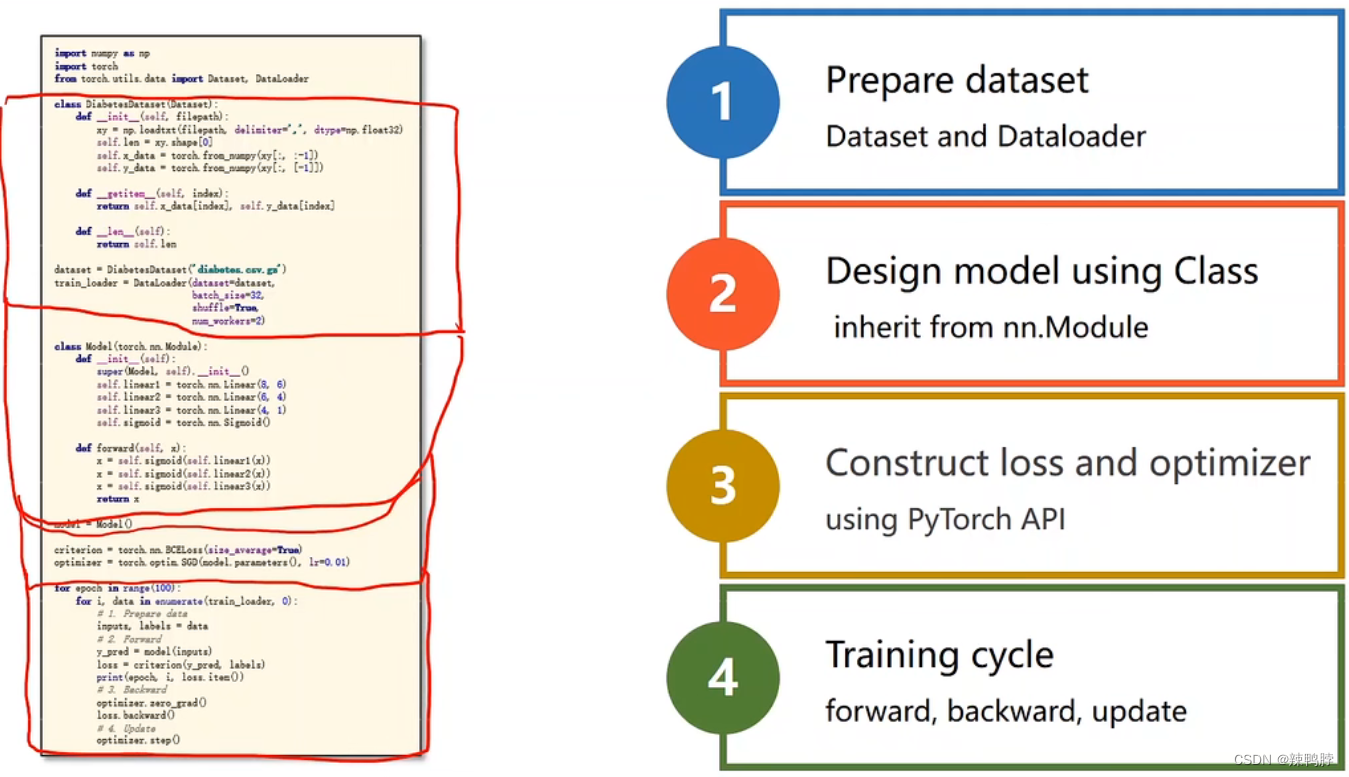
1. Prepare dataset
2. Design model using Class
Inherit form nn.Module(计算y_hat)
把模型定义为一个类,都要继承自(torch.nn.Module),至少要实现两个函数,init()和forward()。没有backward()函数是因为,当你继承自Module模块时,backward会自动根据你构造的计算图计算。
3. Construct loss and optimizer
using Pytorch API
4. Training cycle
forward, backward, update
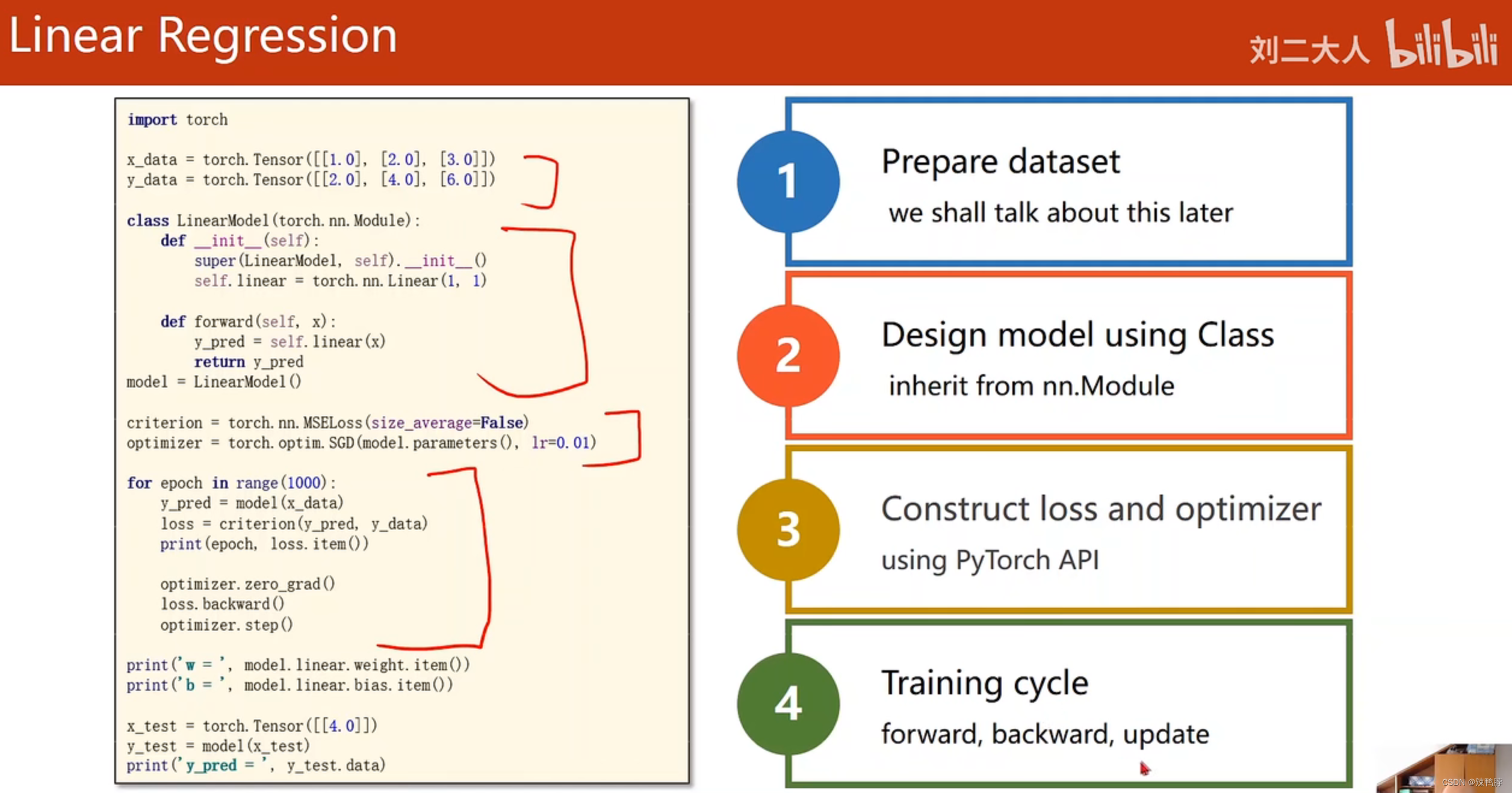
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred',y_test.data)
在MNIST数据集上做分类问题
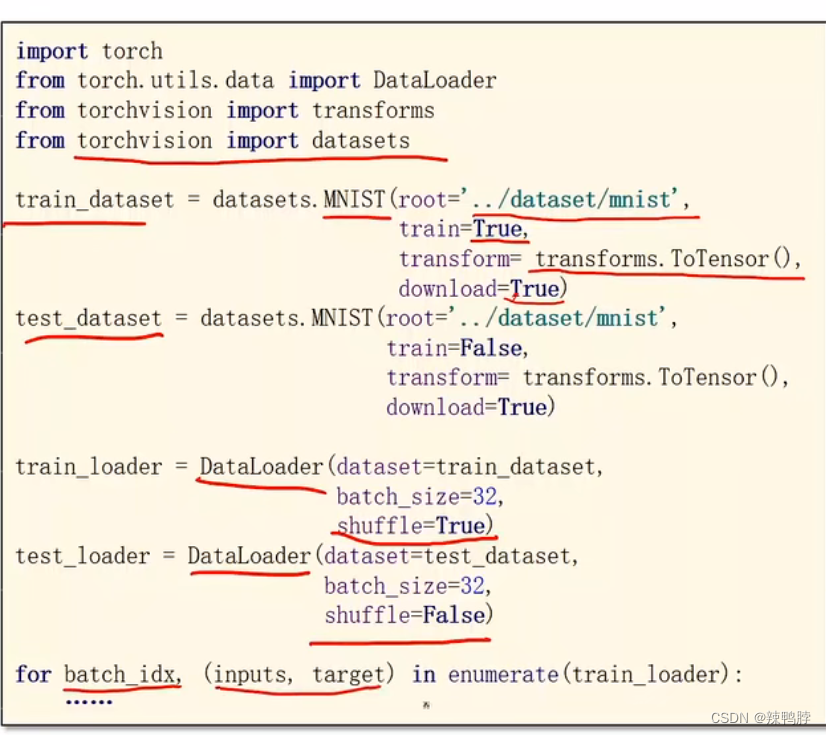
torchvision是Pytorch提供的工具包,里面也包含很多数据集(MNIST、CIFAR-10等)。
常用分类问题的数据集下载:
import torchvision
train_set = torchvision.datasets.MNIST(root=".../dataset/mnist",train=True, download = True)
test_set = torchvision.datasets.MNIST(root=".../dataset/mnist",train=False, download = True)
train_set = torchvision.datasets.CIFAR10(root=".../dataset/cifar10",train=True, download = True)
分类问题的输出是属于某个类别的概率。
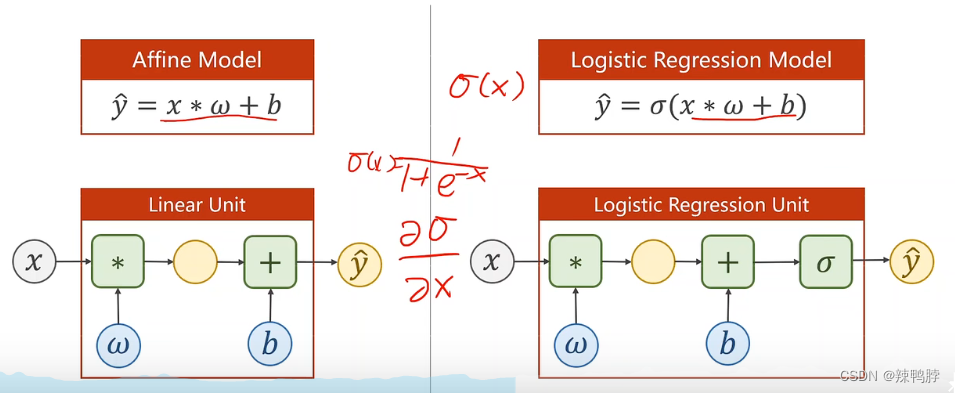
Logistics回归线性模型比原来的线性模型多了一个Logistics函数,确保原来的线性值可以缩放到0-1区间。
模型变量,其相应的损失函数也要变。回归问题输出的是数值,分类问题输出的是分布。计算分布之间的差异有:KL散度、
Logistic 回归单元比线性单元只多一个σ \sigma σ函数,σ \sigma σ没有参数。
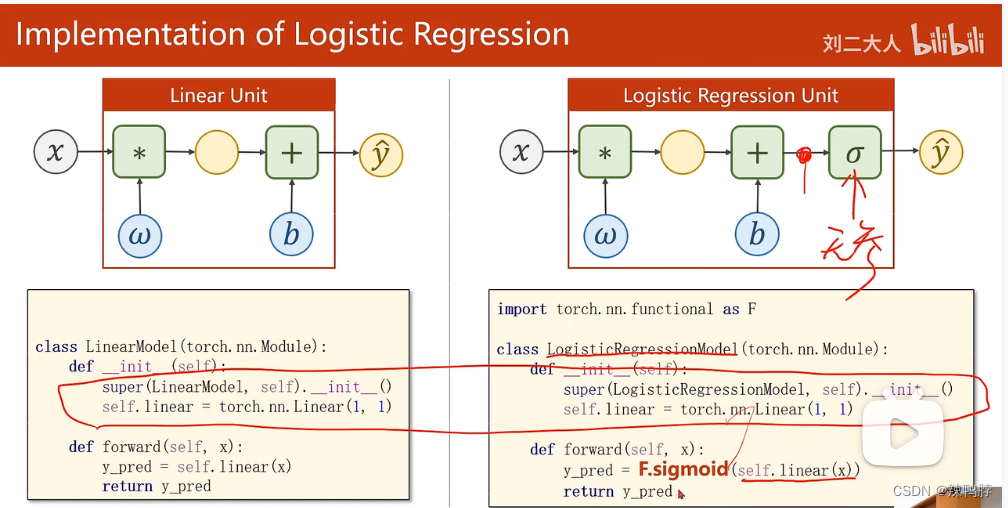

套用上面的模板都可以实现。①将来读数据比较复杂时,就将其封装到一个模块里。之后可以根据需要扩充各个部分。
矩阵是一个空间变换的线性函数。
当激活函数是ReLU时,在最后一层计算y ^ \hat{y}y ^时,此时< 0 的部分会被直接输出为0,因此最好在最后一层改为sigmoid激活函数。
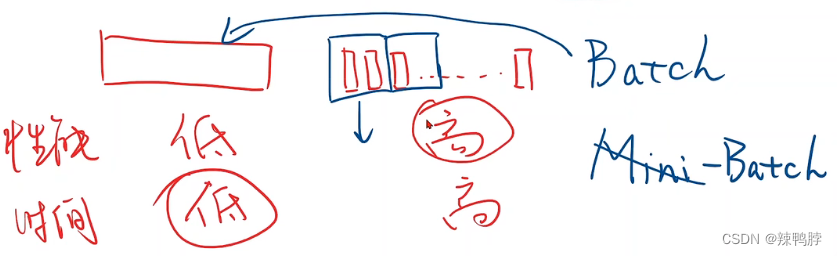
4. Dataset and DataLoader
全部Batch:可以提升计算速度
随机梯度:每次计算一个样本,跳出鞍点
因此使用Mini-Batch来平衡需求。
三个概念:Epoch、Batch-Size、Iterations
嵌套循环。
Epoch:所有的样本都经过了一次前向传播和反向传播,即经过一次训练。
Batch-Size:经过一次前向反向传播过程的训练样本数量。
Iteration:所有的样本数量除以Batchsize。
只要Dataset提供对每个样本的索引和所有样本的数量,就可以使用DataLoader。
定义Dataset

init():用来加载数据集,并对数据集进行处理
getitem():用来返回数据集中每个样本的索引。这里的return返回的是特征和标签,此时就会将其转换为一个元组,则在dataLoader中取用时,也得分开取。
len():返回数据集的长度
完整代码
; 练习
5. 用softmax和Corss Entropy实现多分类问题
使用全连接网络,使用MNIST数据集。
使用神经网络处理图像数据时,最好把矩阵值缩放到[0,1]区间。
transforms是将图像由读取进来的PIL转换为Tensor,并且转换为c _w_h通道,并将值归一化。
P i x e l n o r m = P i x e l o r i g i n − m e a n s t d Pixel_{norm} = \frac{Pixel_{origin} – mean}{std}P i x e l n or m =s t d P i x e l or i g in −m e an
同样按照
- Prepare dataset(Dataset and Dataloader)
- Design model using Class (inherit from nn.Module)
- Construct loss and optimizer (using PyTorch API)
- Training cycle + Test (forward, backward, update)
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root='datasets/mnist/',
train=True,
download=True,
transform= transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size = batch_size)
test_dataset = datasets.MNIST(root='datasets/mnist/',
train=False,
download=True,
transform= transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size = batch_size)
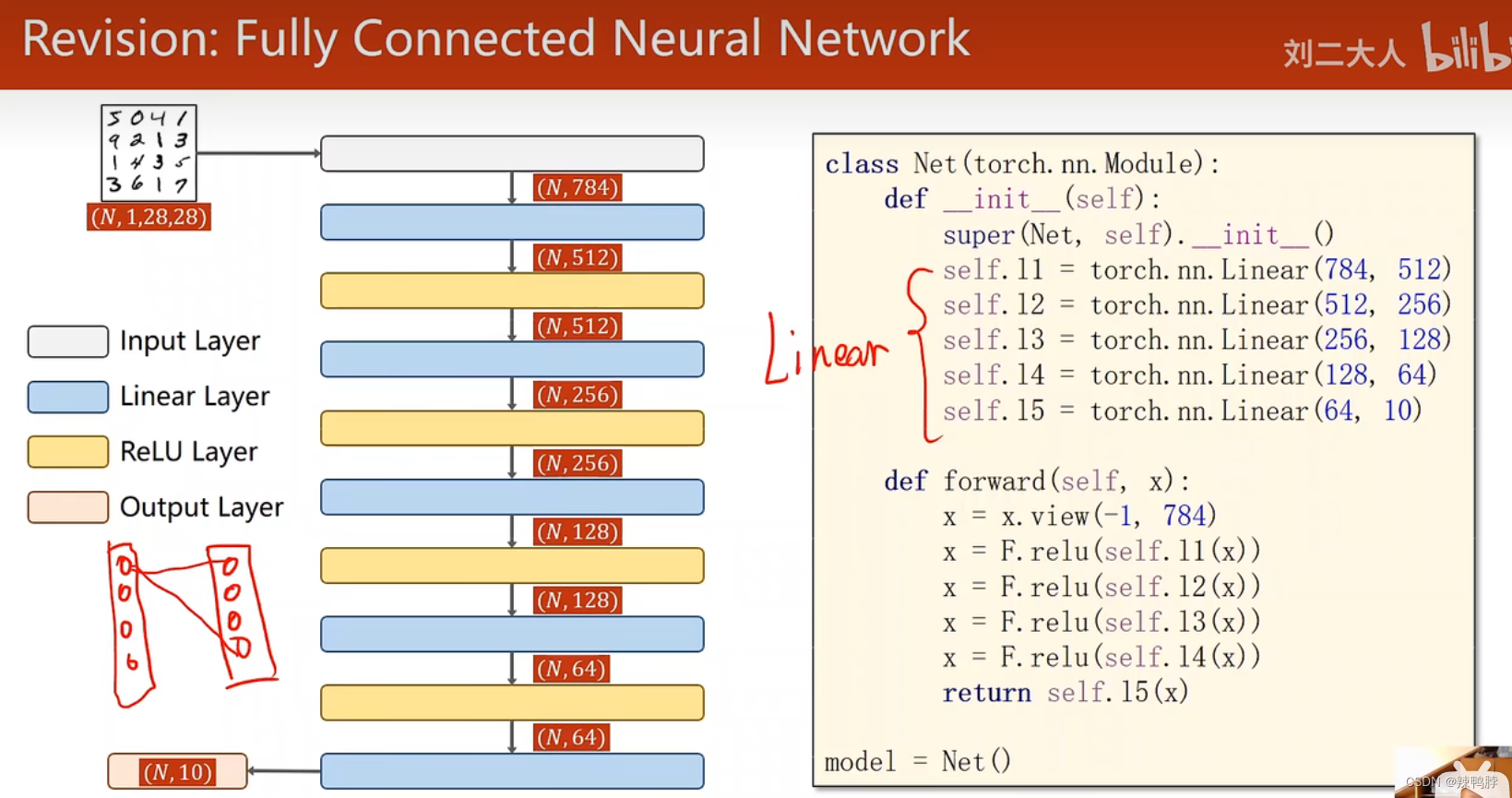
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch +1, batch_idx +1, running_loss /300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ =='__main__':
for epoch in range(50):
train(epoch)
test()
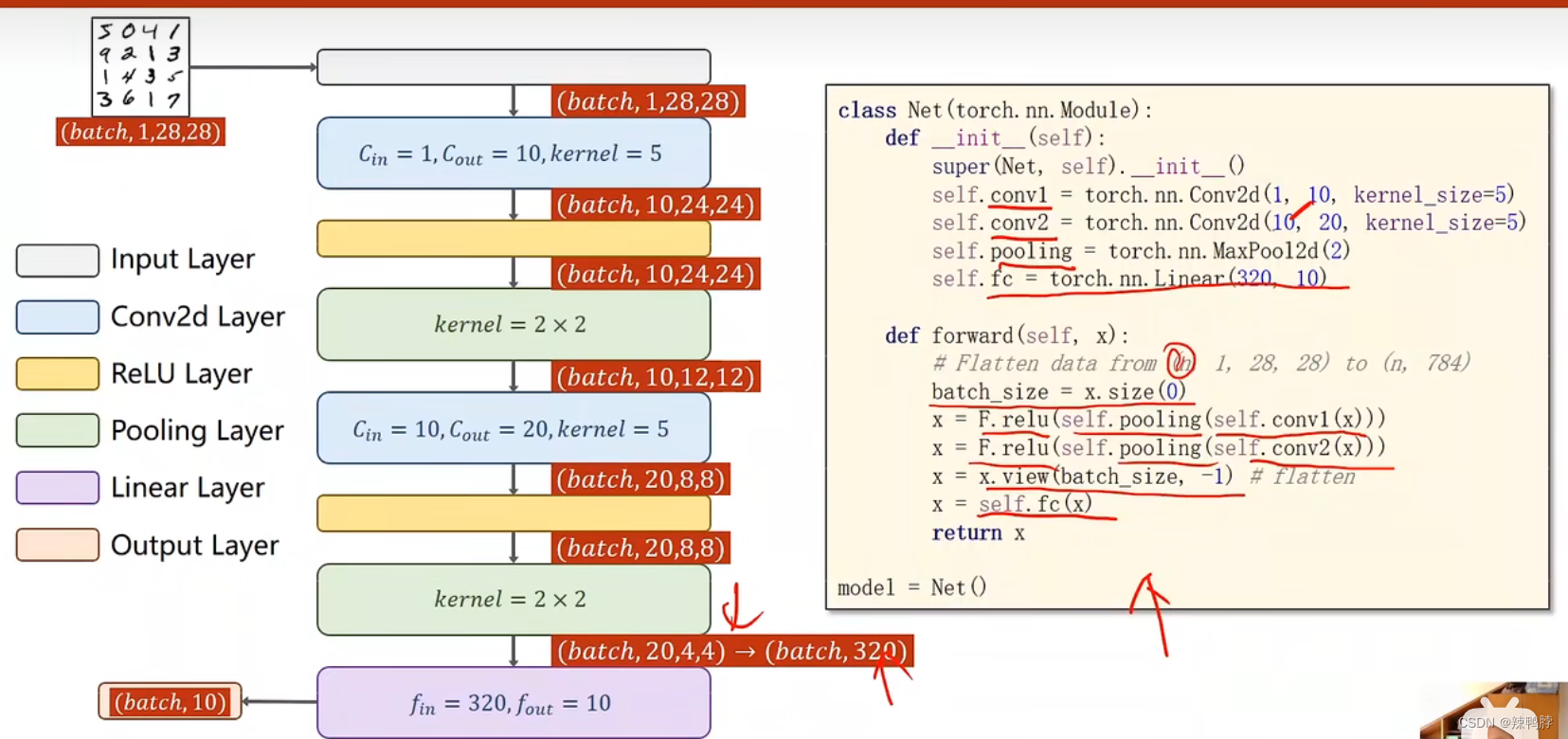
6. 卷积神经网络
卷积层:保留图像的空间特征
全连接层:丢失了图像的空间特征
构建神经网络时,首先要明确,输入的张量维度和输出的张量维度。接下来就是构建各种层,保持维度上的变化。

每一个通道C都要配一个卷积核里的一层,做卷积计算(通道和对应的核相乘,得到后再相加)。每个卷积核的层数和输入的通道数相等,一个卷积核卷积后通道数变为1。因此为了输出m个通道,准备m个卷积核即可。
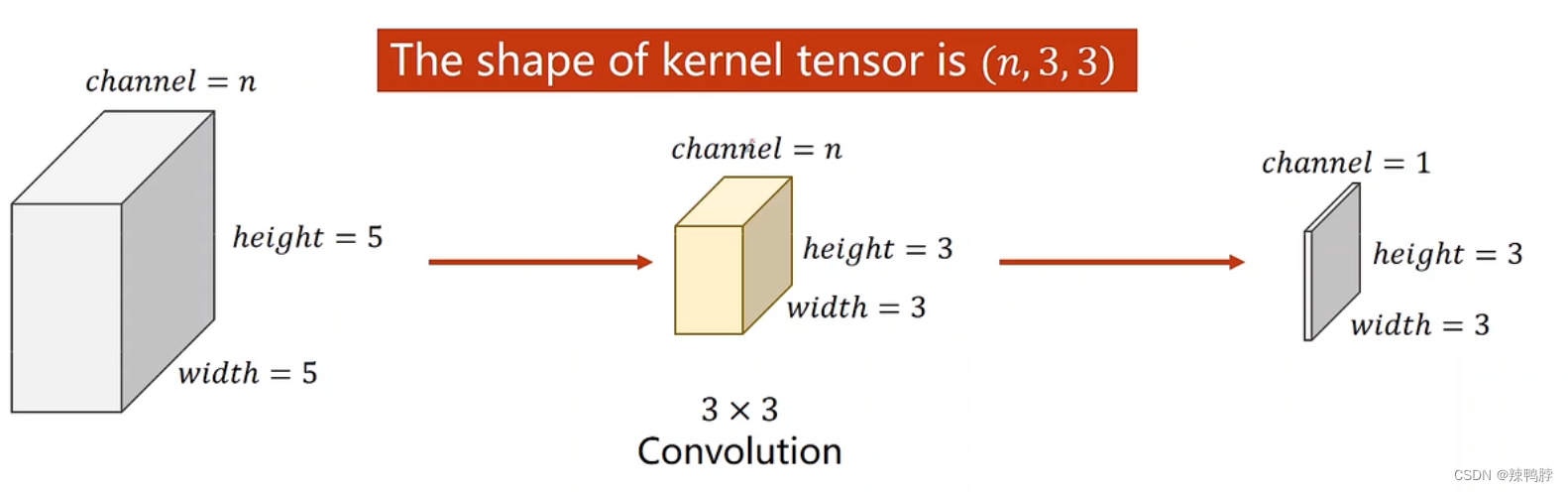
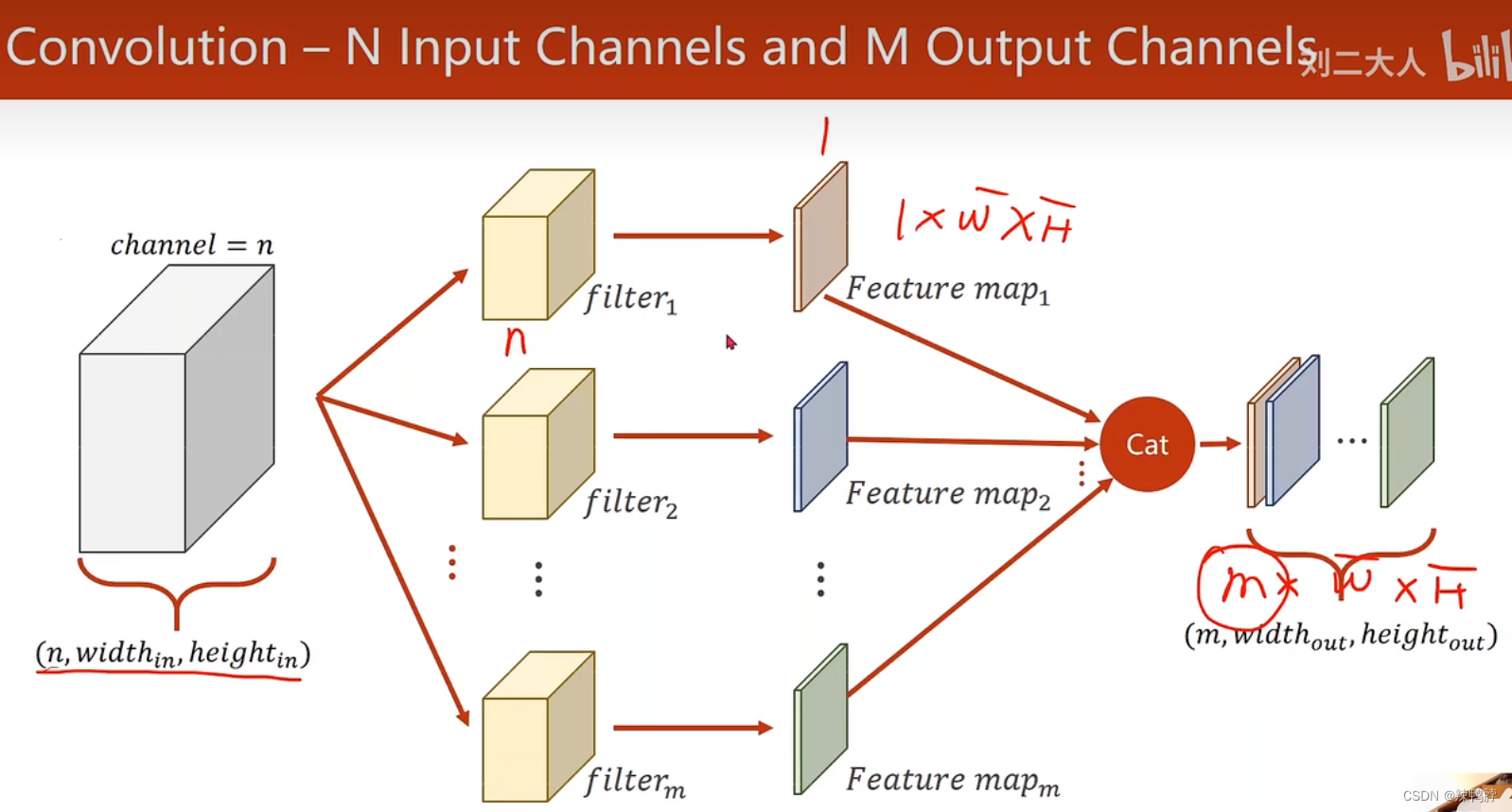
构造一个卷积层关注四个维度:(输入通道数,输出通道数,卷积核的size)m个卷积核,每个核里的n个channel,每个channel 的width和height。(输入通道数则为m,输出通道数则为n)
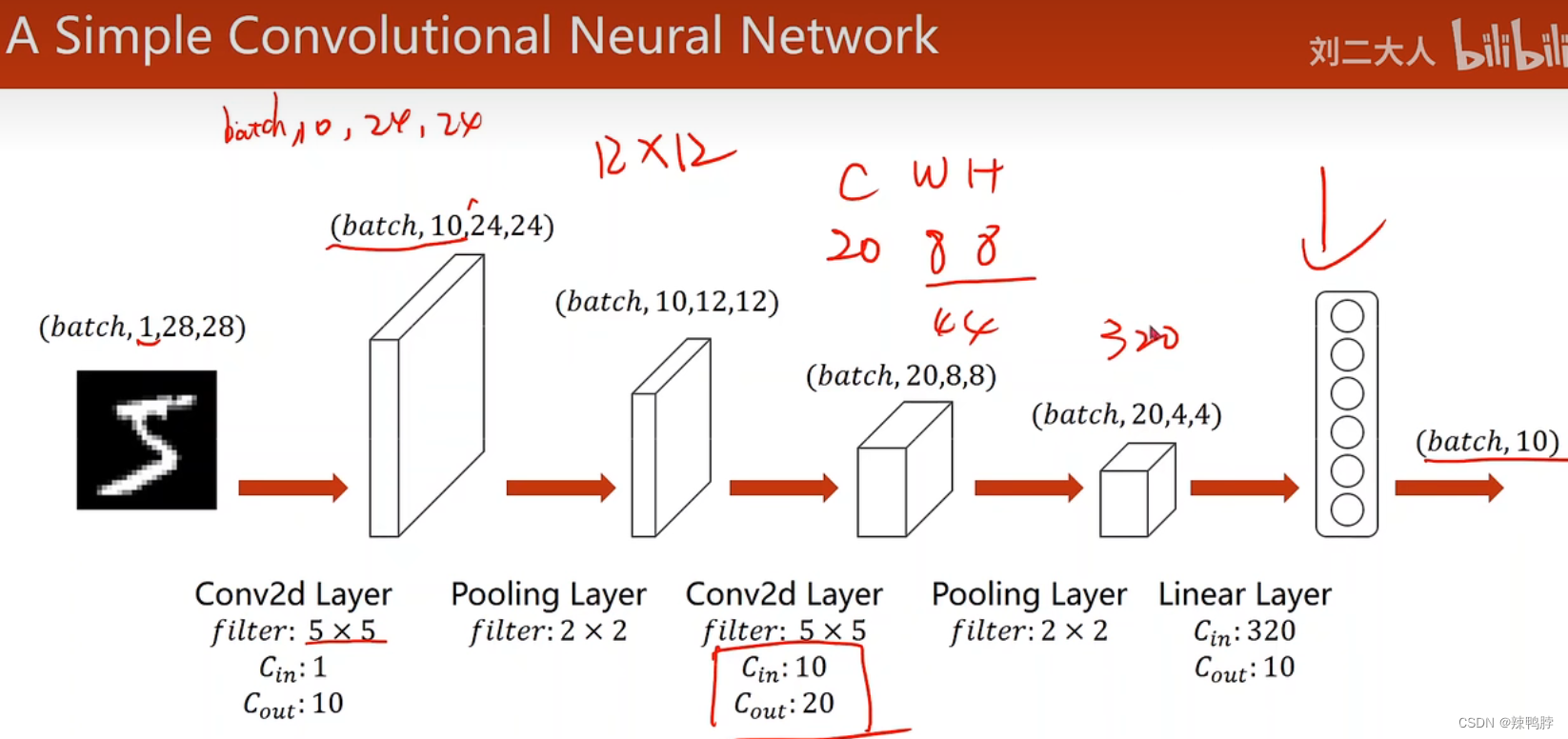
pytorch中的计算是以batch为单位,(b,c,w,h),batch是一直保持不变的。卷积层和池化层不关注图像的size,只有到了全连接才关注。
; Move Model to GPU
需要把模型放到GPU上
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
Move Tensors to GPU
需要把张量也放到GPU上
inputs, target = inputs.to(device), target.to(device)
完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root='datasets/mnist/',
train=True,
download=True,
transform= transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size = batch_size)
test_dataset = datasets.MNIST(root='datasets/mnist/',
train=False,
download=True,
transform= transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size = batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size = 5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size = 5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320,10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch +1, batch_idx +1, running_loss /300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ =='__main__':
for epoch in range(10):
train(epoch)
test()
为了查看模型每一层输出的shape,可以使用如下代码:
from torchsummary import summary
summary(model, (1, 28, 28))
如果不想去计算卷积层最后输出的shape,可以在前向传播时,把最后一层卷积的输出,或者flatten以后的张量shape打印出来,在填入到模型的架构中。
x = x.view(batch_size, -1)
print(x.shape)
减少代码冗余:函数 / 类,把网络中重复的结构封装成类。
GoogleNet中的Inception Module
出发点是,如果不知道卷积核size多大为好,则每种配置都使用,最后通过训练找到效果最好的路径权重最大。
将两个张量沿着通道channel拼起来,叫做concatenate,因此必须保证四条路输出的张量高度和宽度一致。(b,c,w,h):b肯定一样,c可以不一样,w,h需要保持一致。
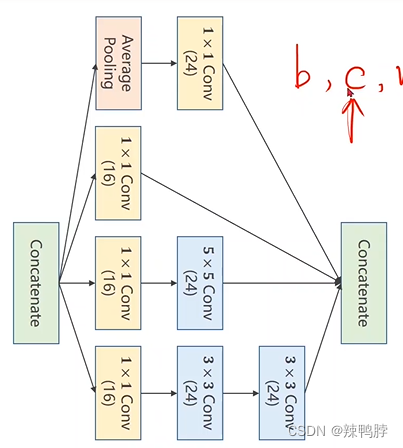
GoogLeNet网络中可以拆分为一个个这样的Inception Module,为了减少代码冗余,把这样的块封装为类。(branch:分支)
class InceptionA(torch.nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size = 1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size = 1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size = 5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size =1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size = 3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size = 3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size = 1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_2(self.branch5x5_1(x))
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size =3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch3x3, branch5x5, branch_pool]
return torch.cat(outputs, dim =1)
整个GoogLeNet网络结构:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1,10, kernel_size =5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
Concatenate
将特征map按照某个维度拼接起来
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
torch.cat(outputs, dim=1)
信息融合
1 _1的卷积核,最大的作用是做相应位置像素的信息融合,并且可以便于改变通道数,运算开销减少。每一个1_1的卷积核的channel数与输入张量的channel数相等
Residual Net中的Inception Module
Residual block中需要保证,特征map从输入到输出的channel,高度,宽度都不变。
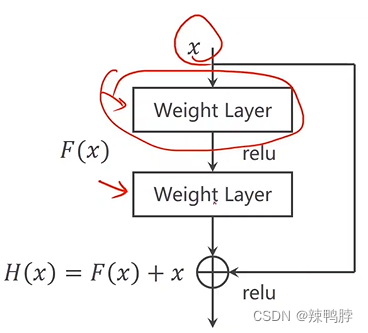
class ResdiualBlock(nn.Module):
def __init__(self, channels):
super(ResdiualBlock, self).__init__()
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(x)
return F.relu(x + y)
7. 循环神经网络
构建RNN Cell
自己创建一个RNN Cell,然后去写循环。(输入的维度和隐藏层的维度), RNN Cell本质上是线性层。
cell = torch.nn.RNNCell(input_size=input_size, hidden_size = hidden_size)
hidden = cell(input, hidden)

直接使用torch中的RNN
这样就不需要写循环了

; Embedding
把高维的稀疏的张量,映射到一个低维的稠密的张量,也就说常说的数据降维。
可以把独热向量变为一个稠密的表示。
Original: https://blog.csdn.net/zhENGHAOSTU/article/details/125291843
Author: 辣鸭脖
Title: Pytorch深度学习实践_刘二大人
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/711966/
转载文章受原作者版权保护。转载请注明原作者出处!