

复杂度
复杂度分析是数据结构与算法的核心精髓,指在不依赖硬件、宿主环境、数据集的情况下,粗略推导,考究出算法的效率和资源消耗情况, 包括时间复杂度和空间复杂度
时间复杂度
首先从CPU的角度看待程序,每行代码执行的操作都包括: 读程序, 写程序, 运算。这里粗略估计,忽略每行代码读程序和写程序的时间
假设 每行代码执行(运算)的时间都是一样的,为 单位时间(即假设程序执行一次均消耗单位时间)
大 (O) 记号
[T(n)=O(f(n)) ]
其中:
- (T(n)): 程序执行总时间
- (n): 数据规模大小
- (f(n)): 程序执行的总次数
- (O):程序执行总时间(T(n))与(f(n))成正比
大(O)记号按最坏的情况来估计程序执行时间;大(\Omega)记号按最好情况估计程序执行时间;大(\Theta)记号按平均情况来估计程序执行时间。后文只分析大(O)记号。
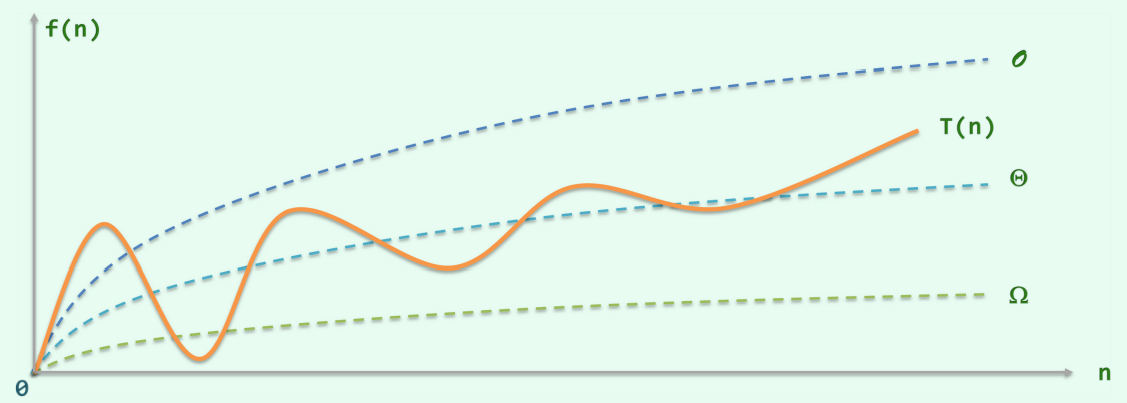

大(O)记号的性质:
- 对任意常数(c>0),(O(f(n))=O(cf(n)))
- 对任意常数(a>b>0),(O(n^a+n^b)=O(n^a))
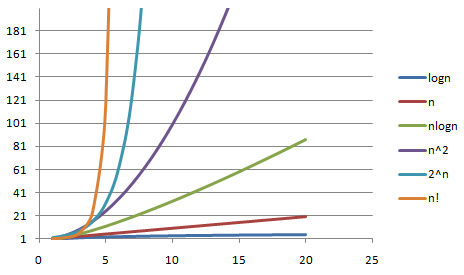
常见时间复杂度
- 常数阶(O(1))
public void sum(int n) {
int sum = 0; // 执行一次
sum = n*2; // 执行一次
System.out.println(sum); // 执行一次
}
程序执行常数次,与问题规模(n)无关,复杂度记为(O(1))
- 对数阶(O(logn))
public void logarithm(int n) {
int count = 1; // 执行一次
while (count <= n) { 执行logn次 count="count*2;" } < code></=>
该段代码什么时候会停止执行呢?是当count大于n时。也就是说多少个2相乘后其结果值会大于(n),即(2^x=n)。由(2^x=n)可以得到(x=logn),所以这段代码时间复杂度是(O(logn))。
- 线性阶(O(n))
public void circle(int n) {
for(int i = 0; i < n; i++) { // 执行n次
System.out.println(i); // 执行n次
}
}
- 线性对数阶(O(nlogn))
线性对数阶(O(nlogn))就是将一段时间复杂度为(O(logn))的代码执行(n)次
public void logarithm(int n) {
int count = 1;
for(int i = 0; i < n; i++) { // 执行n次
while (count <= n) { 执行logn次 count="count*2;" 执行nlogn次 } < code></=>
- 平方阶(O(n^2))
双重for循环
public void square(int n) {
for(int i = 0; i < n; i++){ // 执行n次
for(int j = 0; j <n; j++) { 执行n次 system.out.println(i+j); 执行n方次 } < code></n;>
复杂度分析
示例如下(限定条件: (0
public int Function(int n, int x)
{
int sum = 0;
for (int i = 1; i <= n; ++i) { if (i="=" x) break; sum +="i;" } return sum; < code></=>
- 当(x>n)时,此代码的时间复杂度是(O(n))
- 当(1
- 当(x=1)时,时间复杂度是(O(1))
这段代码在不同情况下,其时间复杂度是不一样的。所以为了描述代码在不同情况下的不同时间复杂度,我们引入了最好、最坏、平均时间复杂度。
- 最好情况时间复杂度(best case)
最好情况时间复杂度,表示在最理想的情况下,执行这段代码的时间复杂度。
上述示例就是当x=1的时候,循环的第一个判断就跳出,这个时候对应的时间复杂度就是最好情况时间复杂度。
- 最坏情况时间复杂度(worst case)
最坏情况时间复杂度,表示在最糟糕的情况下,执行这段代码的时间复杂度。
上述示例就是(n
- 平均情况时间复杂度(average case)
好和最好情况是极端情况,发生的概率并不大。为了更有效的表示平均情况下的时间复杂度,引入另一个概念: 平均情况时间复杂度。
分析上面的示例代码,判断x在循环中出现的位置,有(n+1)种情况:(1
[\frac{((1+2+3+\cdots+n)+n)}{(n+1)}=\frac{n(n+3)}{2(n+1)} ]
大(O)表示法会省略系数、低阶、常量,所以平均情况时间复杂度是(O(n))。
考虑概率的平均情况复杂度:
(x)要么在(1\sim n)中,要么不在(1\sim n)中,所以它们的概率都是(1/2)。同时数据在(1\sim n)中各个位置的概率都是一样的为1/n。根据概率乘法法则,(x)在(1\sim n)中任意位置的概率是(1/(2n))。因此在前面推导过程的基础上,我们把每种情况发生的概率考虑进去,得到 考虑概率的平均情况复杂度:
[1\dfrac{1}{2n}+2\dfrac{1}{2n}+3\dfrac{1}{2n}+\cdots+n\dfrac{1}{2n})+n\dfrac{1}{n}=\frac{3n+1}{4} ]
引入概率之后,平均复杂度变为(O(\frac{3n+1}{4})),忽略系数及常量后,最终得到加权平均时间复杂度(O(n))。
多数情况下,我们 不需要区分最好、最坏、平均情况时间复杂度。只有同一块代码在不同情况下时间复杂度有量级差距,我们才会区分3种情况,为的是更有效的描述代码的时间复杂度。
- 均摊情况时间复杂度
均摊复杂度是一个更加高级的概念,它是一种特殊的情况,应用的场景也更加特殊和有限。对应的分析方式称为: 摊还分析或 平摊分析。
示例如下(限定条件:(0\leq x\leq n)且(0\leq n)且(n), (x)为整数):
int n;
public int Function2(int x)
{
int count = 0;
if (n == x)
{
for (int i = 0; i < n; i++)
count += i;
}
else
count = x;
return count;
}
共有(n+1)种情况,每种情况的概率均为(\dfrac{1}{n+1})当(0\leq x
[(1+1+\cdots+1)\dfrac{1}{n+1}+n\dfrac{1}{n+1}=\dfrac{2n}{n+1} ]
当省略系数及常量后,平均时间复杂度为(O(1))。
通过分析可以看出,上述示例代码复杂度遵循一定的规律,对应1个(O(n)),和n个(O(1))。针对这样一种特殊场景使用更简单的分析方法: 摊还分析法, 即把耗时多的复杂度均摊到耗时低的复杂度,得到对应的均摊时间复杂度为O(1)。
- 均摊时间复杂度是将高高复杂度均摊到其余低复杂度,故一般均摊时间复杂度就等于最好情况时间复杂度。
- 均摊时间复杂度是一种特殊的平均复杂度(特殊应用场景下使用)
空间复杂度
空间复杂度定性地描述该算法或程序运行所需要的存储空间大小,算法空间复杂度的计算公式记作:(S(n)=O(f(n))),其中(n)为问题的规模,(f(n))为语句关于(n)所占存储空间的函数。
参考:
- https://www.cnblogs.com/jonins/p/9956752.html
- 邓俊辉数据结构(C++语言版)
- https://zhuanlan.zhihu.com/p/361636579
- https://zh.m.wikipedia.org/zh-hans/空间复杂度
Original: https://www.cnblogs.com/CJuncheng/p/16524542.html
Author: CJuncheng
Title: 复杂度分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/711399/
转载文章受原作者版权保护。转载请注明原作者出处!