

我是蝉沐风。
这一篇文章来聊一聊如何用好MySQL索引。

为了更好地进行解释,我创建了一个存储引擎为InnoDB的表 user_innodb,并批量初始化了500W+条数据。包含主键 id、姓名字段( name)、性别字段( gender,用0,1表示不同性别)、手机号字段( phone),并为 name和 phone字段创建了联合索引。
CREATE TABLE user_innodb (
id int NOT NULL AUTO_INCREMENT,
name varchar(255) DEFAULT NULL,
gender tinyint(1) DEFAULT NULL,
phone varchar(11) DEFAULT NULL,
PRIMARY KEY (id),
INDEX IDX_NAME_PHONE (name, phone)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
1. 索引的代价
索引可以非常有效地提升查询效率,既然这么好,我给每个字段都创建一个索引行不行?我劝你不要冲动。

任何事情都有两面,索引也不例外。过度使用索引,我们在空间和时间上都会付出相应的代价。
1.1 空间上的代价
索引就是一棵B+数,每创建一个索引都需要创建一棵B+树,每一棵B+树的节点都是一个数据页,每一个数据页默认会占用16KB的磁盘空间,每一棵B+树又会包含许许多多的数据页。所以,大量创建索引,你的磁盘空间会被迅速消耗。
1.2 时间上的代价
空间上的代价你可以使用”钞能力”来解决,但时间上的代价我们可能就束手无策了。
链表的维护
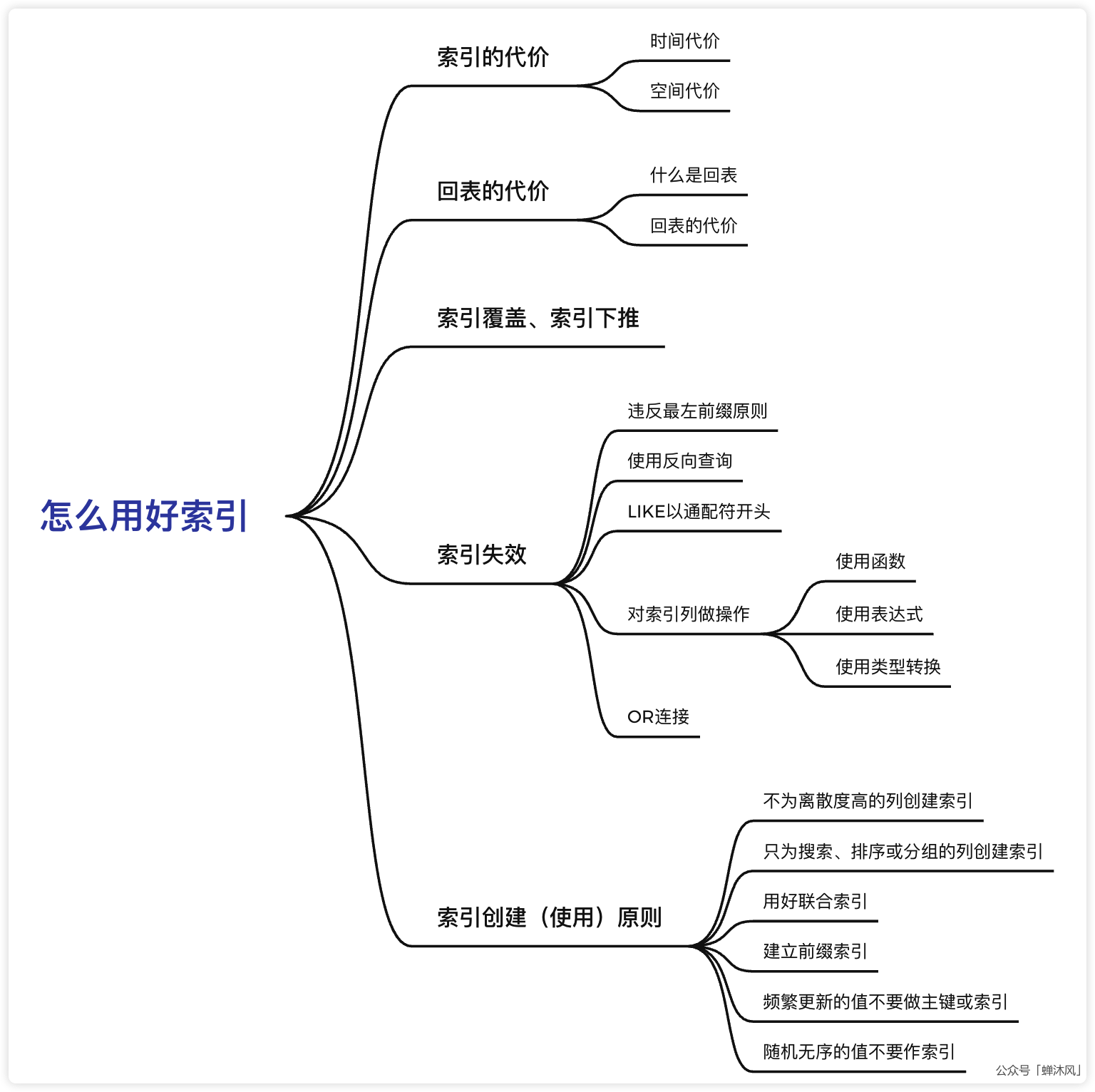
我以主键索引为例举个例子,主键索引的B+树的每一个节点内的记录都是按照主键值由小到大的顺序,采用单向链表的方式进行连接的。如下图所示:
如果我现在要删除主键 id为1的记录,会破坏3个数据页内的记录排序,需要对这3个数据页内的记录进行重排列,插入和修改操作也是同理。
注:这里给大家提一嘴,其实删除操作并不会立即进行数据页内记录的重排列,而是会给被删除的记录打上一个删除的标识,等到合适的时候,再把记录从链表中移除,但是总归需要涉及到排序的维护,势必要消耗性能。
假如这张表有12个字段,我们为这张表的12个字段都设置了索引,我们删除1条记录,需要涉及到12棵B+树的N个数据页内记录的排序维护。
更糟糕的是,你增删改记录的时候,还可能会触发数据页的回收和分裂。还是以上图为例,假如我删除了 id为13的记录,那么 数据页124就没有存在的必要了,会被InnoDB存储引擎回收;我插入一条 id为12的记录,如果 数据页32的空间不足以存储该记录,InnoDB又需要进行页面分裂。我们不需要知道页面回收和页面分裂的细节,但是能够想象到这个操作会有多复杂。
如果每个字段都创建索引,所有这些索引的维护操作带来的性能损耗,你能想象了吧。
查询计划
执行查询语句之前,MySQL查询优化器会基于cost成本对一条查询语句进行优化,并生成一个执行计划。如果创建的索引太多,优化器会计算每个索引的搜索成本,导致在分析过程中耗时太多,最终影响查询语句的执行效率。
2. 回表的代价
2.1 什么是回表
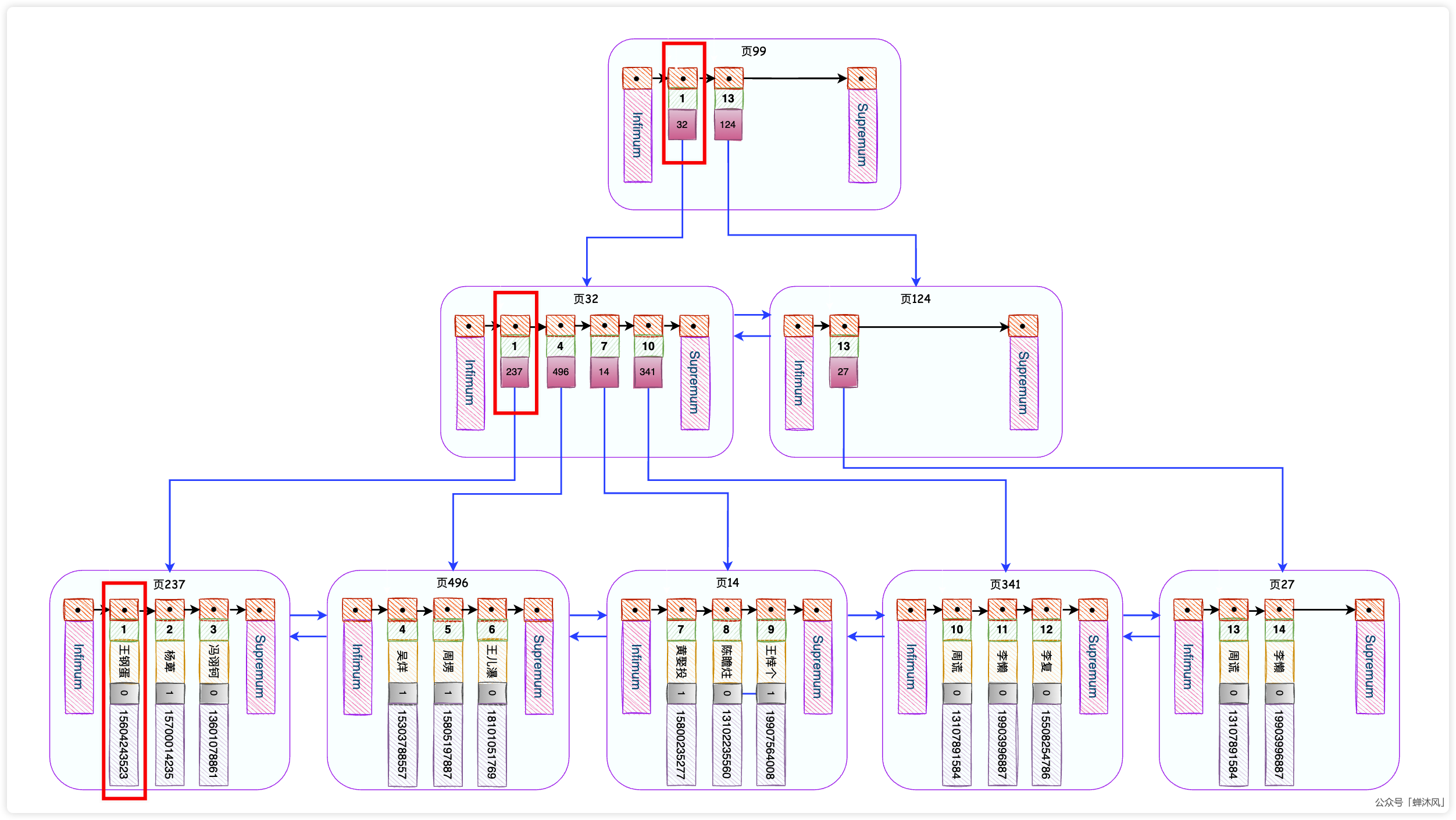
我再啰嗦一遍什么是回表,我们可以通过二级索引找到B+树中的叶子结点,但是二级索引的叶子节点的内容并不全,只有索引列的值和主键值。我们需要拿着主键值再去聚簇索引(主键索引)的叶子节点中去拿到完整的用户记录,这个过程叫做回表。
上图中我以 name二级索引为例,并且只画出了二级索引的叶子节点和聚簇索引的叶子节点,省略了两棵B+树的非叶子节点。
从二级索引的叶子节点延伸出的3条线表示的就是回表操作。
2.2 回表的代价
我们根据 name字段查找二级索引的叶子节点的代价还是比较小的,原因有二:
- 叶子节点所在的页通过双向链表进行关联,遍历的速度比较快;
- MySQL会尽量让同一个索引的叶子节点的数据页在磁盘空间中相邻,尽力避免随机IO。
但是二级索引叶子节点中的主键id的排布就没有任何规律了,毕竟 name索引是对 name字段进行排序的。进行回表的时候,极有可能出现主键 id所在的记录在聚簇索引叶子节点中反复横跳的情况(正如上图中回表的3条线表示的那样),也就是随机IO。如果目标数据页恰好在内存中的话效果倒也不会太差,但如果不在内存中,还要从磁盘中加载一个数据页的内容(16KB)到内存中,这个速度可就太慢了。
是不是说完了回表的代价之后,我会给出一种更高效的搜索方式?不是,回表已经是一种比较高效的搜索方式了,我们需要做的就是尽量地减少回表操作带来的损耗,总结起来就是两点:
- 能不回表就不回;
- 必须回表就减少回表的次数。
接下来先给大家介绍两个与回表相关的重要概念,这两个概念涉及到的方法也是索引使用原则的一部分,因为比较重要,在这里我把这两个概念先解释给大家听。
3. 索引覆盖、索引下推
3.1 索引覆盖
想一下,如果非聚簇索引的叶子节点上有你想要的所有数据,是不是就不需要回表了呢?比如我为 name和 phone字段创建了一个联合索引,如下图:
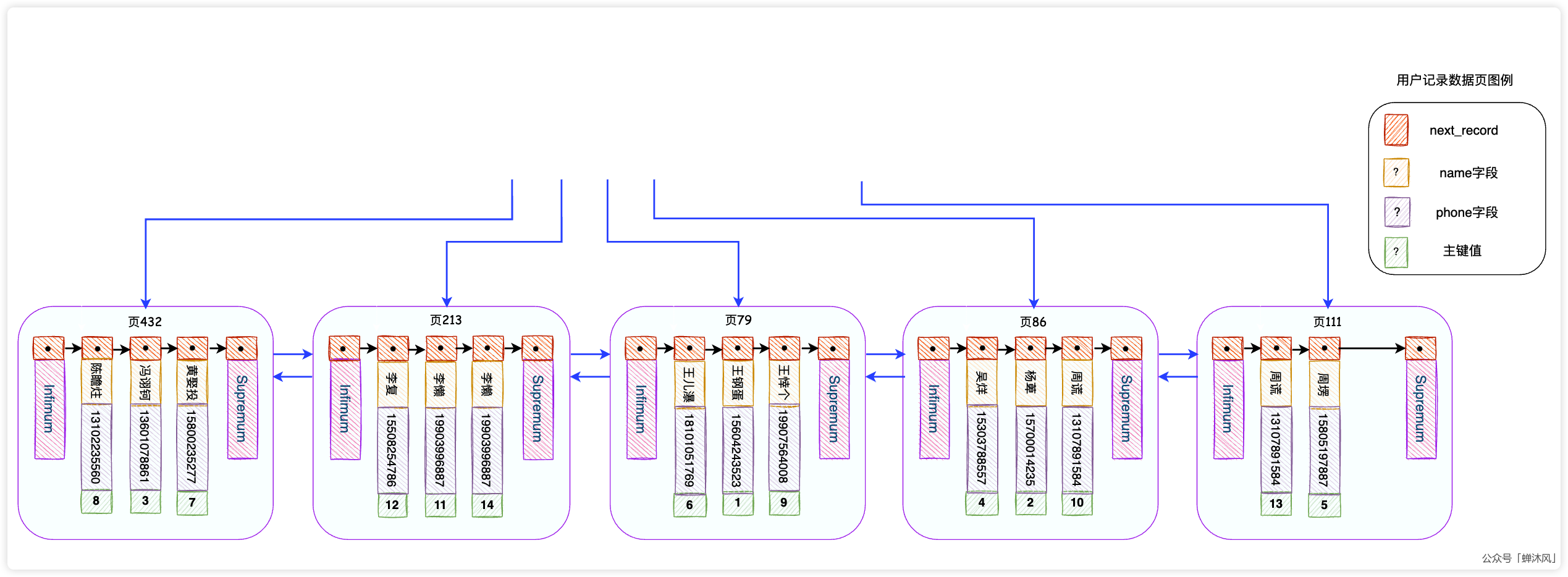
如果我们恰好只想搜索 name、 phone以及主键字段,
SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";
可以直接从叶子节点获取所有数据,根本不需要回表操作。
我们把索引中已经包含了所有需要读取的列数据的查询方式称为 覆盖索引(或 索引覆盖)。
3.2 索引下推
3.2.1 概念
还是拿 name和 phone的联合索引为例,我们要查询所有 name为「蝉沐风」,并且手机尾号为6606的记录,查询SQL如下:
SELECT * FROM user_innodb WHERE name = "蝉沐风" AND phone LIKE "%6606";
由于联合索引的叶子节点的记录是先按照 name字段排序, name字段相同的情况下再按照 phone字段排序,因此把 %加在 phone字段前面的时候,是无法利用索引的顺序性来进行快速比较的,也就是说这条查询语句中只有 name字段可以使用索引进行快速比较和过滤。正常情况下查询过程是这个样子的:
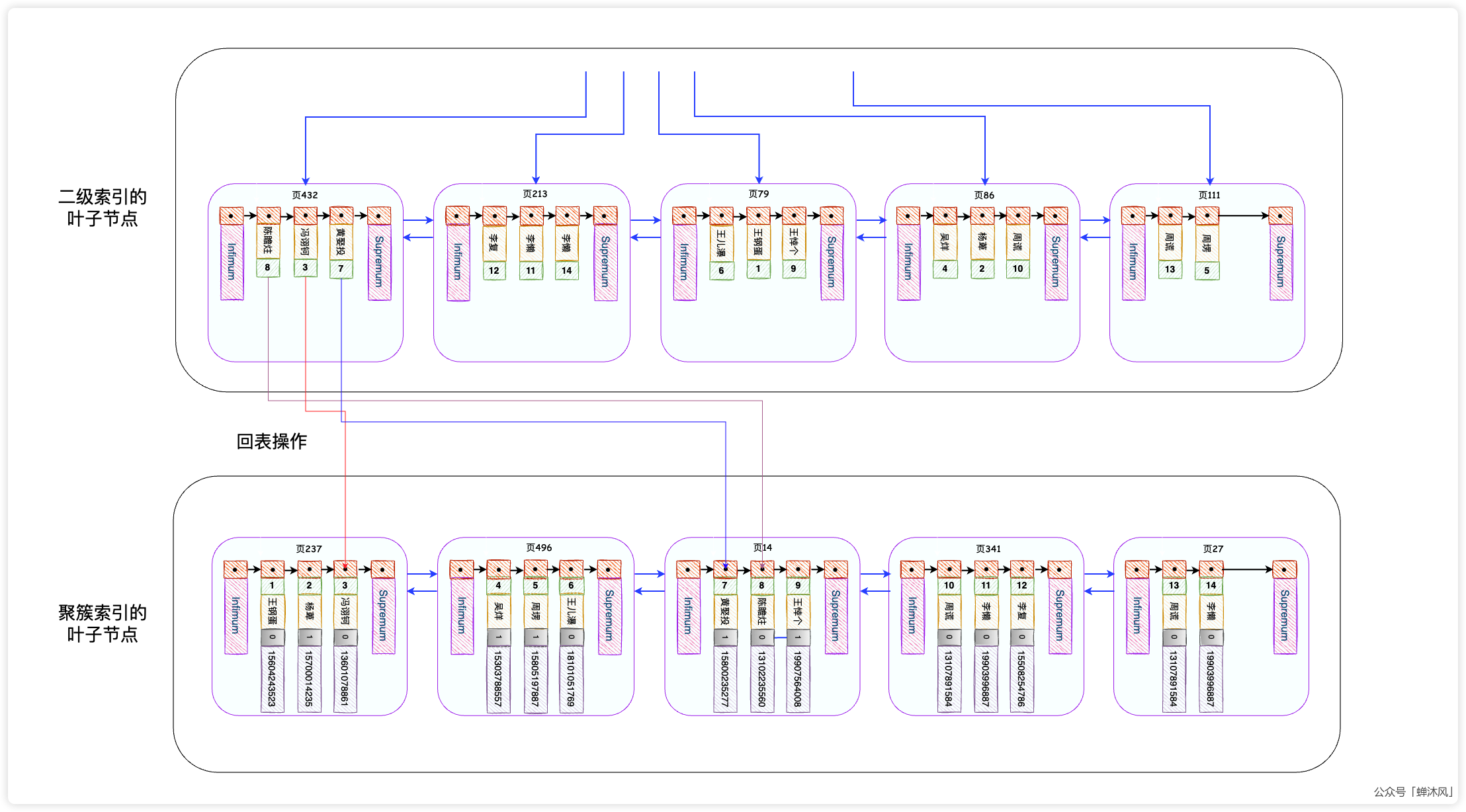
- InnoDB使用联合索引查出所有
name为蝉沐风的二级索引数据,得到3个主键值:3485,78921,423476; - 拿到主键索引进行回表,到聚簇索引中拿到这三条完整的用户记录;
- InnoDB把这3条完整的用户记录返回给MySQL的Server层,在Server层过滤出尾号为6606的用户。
如下面两幅图所示,第一幅图表示InnoDB通过3次回表拿到3条完整的用户记录,交给Server层;第二幅图表示Server层经过 phone LIKE "%6606"条件的过滤之后找到符合搜索条件的记录,返给客户端。
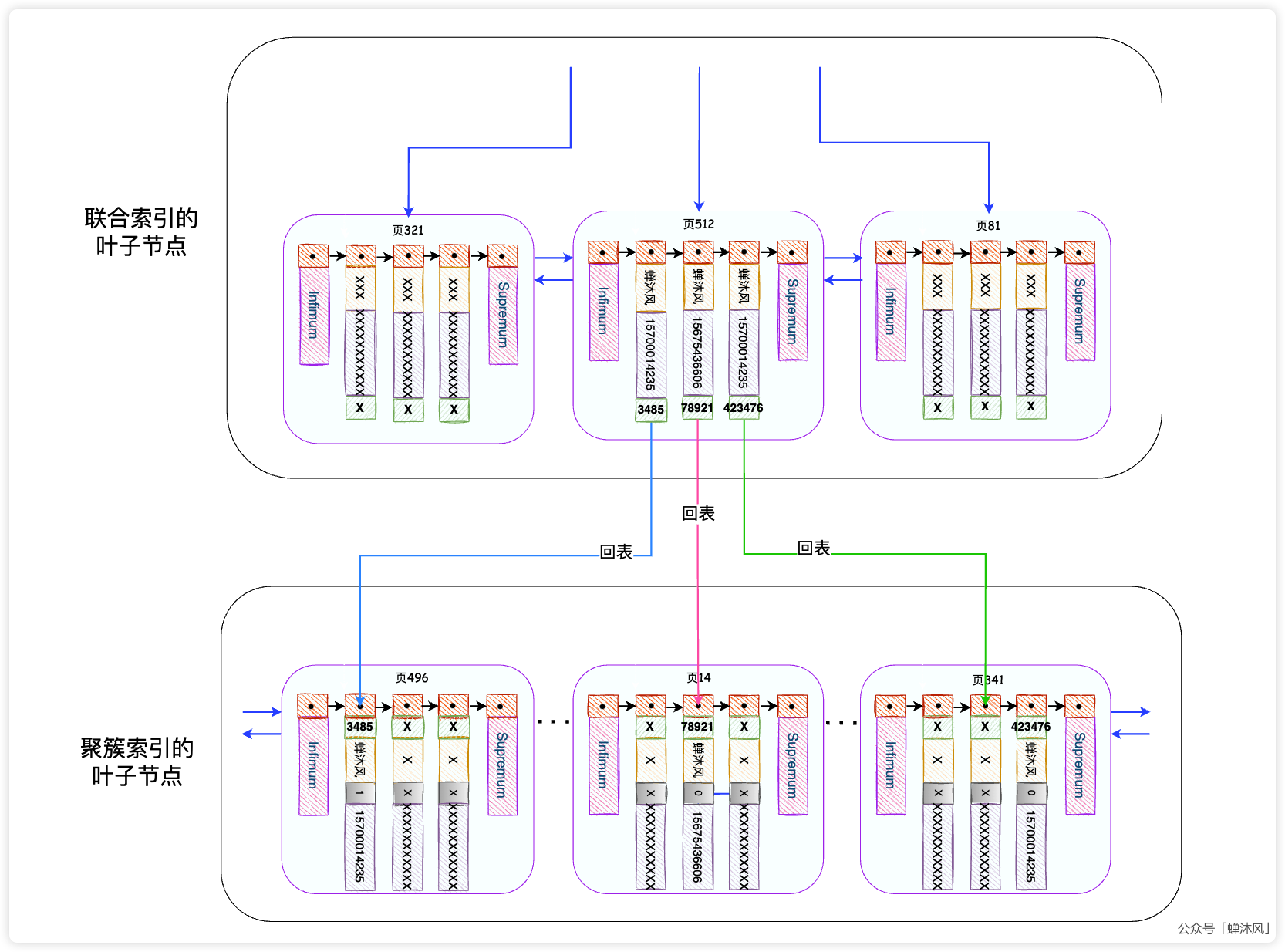
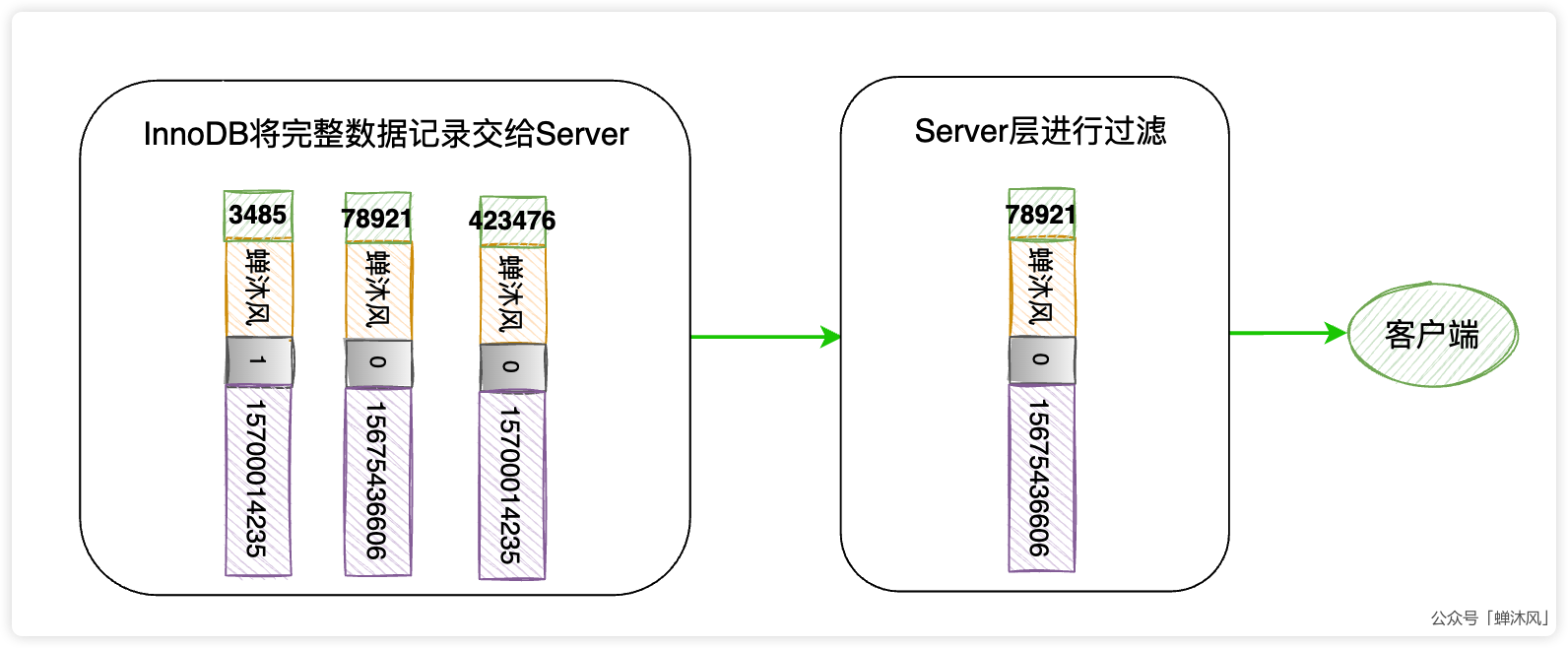
值得我们关注的是,索引的使用是在存储引擎中进行的,而数据记录的比较是在Server层中进行的。现在我们把上述搜索考虑地极端一点,假如数据表中10万条记录都符合 name='蝉沐风'的条件,而只有1条符合 phone LIKE "%6606"条件,这就意味着,InnoDB需要将99999条无效的记录传输给Server层让其自己筛选,更严重的是,这99999条数据都是通过回表搜索出来的啊!关于回表的代价你已经知道了。
现在引入 索引下推。准确来说,应该叫做 索引条件下推(Index Condition Pushdown, ICP),就是过滤的动作由下层的存储引擎层通过使用索引来完成,而不需要上推到Server层进行处理。ICP是在MySQL5.6之后完善的功能。
再回顾一下,我们第一步已经通过 name = "蝉沐风"在联合索引的叶子节点中找到了符合条件的3条记录,而且 phone字段也恰好在联合索引的叶子节点的记录中。这个时候可以直接在联合索引的叶子节点中进行遍历,筛选出尾号为6606的记录,找到主键值为78921的记录,最后只需要进行1次回表操作即可找到符合全部条件的1条记录,返回给Server层。
很明显,使用ICP的方式能有效减少回表的次数。
另外,ICP是默认开启的,对于二级索引,只要能把条件甩给下面的存储引擎,存储引擎就会进行过滤,不需要我们干预。
3.2.2 演示
查看一下当前ICP的状态:
SHOW VARIABLES LIKE 'optimizer_switch';

执行以下SQL语句,并用 EXPLAIN查看一下执行计划,此时的执行计划是 Using index condition
EXPLAIN SELECT * FROM user_innodb WHERE name = "蝉沐风" AND phone LIKE "%6606";

然后关闭ICP
SET optimizer_switch="index_condition_pushdown=off";
再查看一下ICP的状态

再次执行查询语句,并用EXPLAIN查看一下执行计划,此时的执行计划是 Using where
EXPLAIN SELECT * FROM user_innodb WHERE name = "蝉沐风" AND phone LIKE "%6606";

注:即使满足索引下推的使用条件,查询优化器也未必会使用索引下推,因为可能存在更高效的方式。
由于之前我给name字段创建了索引,导致一直没有使用索引下推,EXPLAIN语句显示使用了name索引,而不是name和phone的联合索引;删除name索引之后,才获得上述截图的效果。大家做实验的时候需要注意。
到目前为止大家应该清楚了索引和回表带来的性能问题,讲这些自然不是为了恐吓大家让大家远离索引,相反,我们要以正确的方式积极拥抱索引,最大限度降低其带来的负面影响,放大其优势。如何用好索引,从两个方面考虑:
- 高效发挥已经创建的索引的作用(避免索引失效)
- 为合适的列创建合适的索引(索引创建原则)
4. 什么时候索引会失效?
4.1 违反最左前缀原则
拿我们文章开始创建的联合索引为例,该联合索引的B+树数据页内的记录首先按照 name字段进行排序, name字段相同的情况下,再按照 phone字段进行排序。
所以,如果我们直接使用 phone字段进行搜索,无法利用索引的顺序性。
EXPLAIN SELECT * FROM user_innodb WHERE phone = "13203398311";

EXPLAIN可以查看搜索语句的执行计划,其中,possible_keys列表示在当前查询中,可能用到的索引有哪一些;key列表示实际用到的索引有哪一些。
但是一旦加上 name的搜索条件,就会使用到联合索引,而且不需要在意 name在 WHERE子句中的位置,因为查询优化器会帮我们优化。
EXPLAIN SELECT * FROM user_innodb WHERE phone = "13203398311" AND name = '蝉沐风';

4.2 使用反向查询(!=, <>,NOT LIKE)
MySQL在使用反向查询(!=, <>, NOT LIKE)的时候无法使用索引,会导致全表扫描,覆盖索引除外。
EXPLAIN SELECT * FROM user_innodb WHERE name != '蝉沐风';

4.3 LIKE以通配符开头
当使用 name LIKE '%沐风'或者 name LIKE '%沐%'这两种方式都会使索引失效,因为联合索引的B+树数据页内的记录首先按照 name字段进行排序,这两种搜索方式不在意 name字段的开头是什么,自然就无法使用索引,只能通过全表扫描的方式进行查询。
EXPLAIN SELECT * FROM user_innodb WHERE name LIKE '%沐风';

但是使用通配符结尾就没有问题
EXPLAIN SELECT * FROM user_innodb WHERE name LIKE '蝉沐%';

4.4 对索引列做任何操作
如果不是单纯使用索引列,而是对索引列做了其他操作,例如数值计算、使用函数、(手动或自动)类型转换等操作,会导致索引失效。
4.4.1 使用函数
EXPLAIN SELECT * FROM user_innodb WHERE LEFT(name,3) = '蝉沐风';

MySQL8.0新增了函数索引的功能,我们可以给函数作用之后的结果创建索引,使用以下语句
ALTER TABLE user_innodb ADD KEY IDX_NAME_LEFT ((left(name,3)));
再次执行 EXPLAIN语句,此时索引生效

4.4.2 使用表达式
EXPLAIN SELECT * FROM user_innodb WHERE id + 1 = 1100000;

换一种方式,单独使用 id,就能高效使用索引:
EXPLAIN SELECT * FROM user_innodb WHERE id = 1100000 - 1;

4.4.3 使用类型转换
例1
user_innodb中的 phone字段为 varchar类型,实验之前我们先给 phone字段创建个索引
ALTER TABLE user_innodb ADD INDEX IDX_PHONE (phone);
随便搜索一个存在的手机号,看一下索引是否成功
EXPLAIN SELECT * FROM user_innodb WHERE phone = '13203398311';

可以看到能使用到索引,现在我们稍微修改一下,把 phone = '13203398311'修改为 phone = 13203398311,这意味着我们将字符串的搜索条件改成了整形的搜索条件,再看一下还会不会使用到索引:
EXPLAIN SELECT * FROM user_innodb WHERE phone = 13203398311;

显示索引失效。
例2
我们再看一个例子,主键 id类型是 bigint,但是在搜索条件中我估计使用字符串类型:
EXPLAIN SELECT * FROM user_innodb WHERE id = '1099999';

总结
稍微总结一下这个问题,当索引字段类型为字符串时,使用数字类型进行搜索不会用到索引;而索引字段类型为数字类型时,使用字符串类型进行搜索会使用到索引。
要搞明白这个问题,我们需要知道MySQL的数据类型转换规则是什么。简单地说就是MySQL会自动将数字转化为字符串,还是将字符串转化为数字。
一个简单的方法是,通过 SELECT '10' > 9的结果来确定MySQL的类型转换规则:
- 结果为1,说明MySQL会自动将字符串类型转化为数字,相当于执行了
SELECT 10 > 9; - 结果为0,说明MySQL会自动将数字转化为字符串,相当于执行了
SELECT '10' > '9'。
mysql> SELECT '10' > 9;
+----------+
| '10' > 9 |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
上面的执行结果为1,说明MySQL遇到类型转换时,会自动将字符串转换为数字类型,因此对于例1:
EXPLAIN SELECT * FROM user_innodb WHERE phone = 13203398311;
就相当于
EXPLAIN SELECT * FROM user_innodb WHERE CAST(phone AS signed int) = 13203398311;
也就是对索引字段使用了函数,按照前文的介绍,对索引使用函数是不会使用到索引的。
对于例2:
EXPLAIN SELECT * FROM user_innodb WHERE id = '1099999';
就相当于
EXPLAIN SELECT * FROM user_innodb WHERE id = CAST('1099999' AS unsigned int);
没有在索引字段添加任何操作,因此能够使用到索引。
4.5 OR连接
使用 OR连接的查询语句,如果 OR之前的条件列是索引列,但是 OR之后的条件列不是索引列,则不会使用索引。举例:
EXPLAIN SELECT * FROM user_innodb WHERE id = 1099999 OR gender = 0;

上面总结了一些索引失效的场景,这些经验的总结往往对SQL的优化很有益处,但同时需要注意的是这些经验并非金科玉律。
比如使用 <>查询时,在某些时候是可以用到索引的:
EXPLAIN SELECT * FROM user_innodb WHERE id <> 1099999;

最终是否使用索引,完全取决于MySQL的优化器,而优化器的判定依据就是cost开销(Cost Base Optimizer),优化器并非基于具体的规则,也不是基于语义,就是单纯地执行开销小的方案罢了。所以在·EXPLAIN·的结果中你会看到 possible_keys一列,优化器会把这里边的索引都试一遍(是不是又加深了对不能随便创建索引的认识呢?),然后选一个开销最小的,如果都不太行,那就直接全表扫描好了。
而cost开销,和数据库版本、数据量等都有关系,因此如果想更精准地提升索引功能性,拥抱 EXPLAIN吧!
5. 索引创建(使用)原则
之前讲过的 索引覆盖和 索引下推都可以作为索引创建的原则,就是在创建索引的时候,尽量发挥 索引覆盖和 索引下推的优势。
尽量避免上述提及到的索引可能失效的情况的出现,同样是索引的使用原则。
除此之外,再给大家介绍一些。
5.1 不为离散度低的列创建索引
先来看一下列的离散度公式: COUNT(DISTINCT(column_name)) / COUNT(*),列的不重复值的个数与所有数据行的比例。简而言之,如果列的重复值越多,列的离散度越低。重复值越少,离散度就越高。
举个例子, gender(性别)列只有0、1两个值,列的离散度非常低,假如我们为该列创建索引,我们会在二级索引中搜索到大量的重复数据,然后进行大量回表操作。大量回表哈?你懂了吧。
不要为重复值多的列创建索引
5.2 只为用于搜索、排序或分组的列创建索引
我们只为出现在 WHERE子句中的列或者出现在 ORDER BY和 GROUP BY子句中的列创建索引即可。仅出现在查询列表中的列不需要创建索引。
5.3 用好联合索引
用2条SQL语句来说明这个问题:
1. SELECT * FROM user_innodb WHERE name = '蝉沐风' AND phone = '13203398311';
2. SELECT * FROM user_innodb WHERE name = '蝉沐风';
语句1和语句2都能够使用索引,这带给我们的一个索引设计原则就是:
不要为联合索引的第一个索引列单独创建索引
因为联合索引本身就是先按照 name列进行排序,因此联合索引对 name的搜索是有效的,不需要单独为 name再创建索引了。也正因为此
建立联合索引的时候,一定要把最常用的列放在最左边
5.4 对过长的字段,建立前缀索引
如果一个字符串格式的列占用的空间比较大(就是说允许存储比较长的字符串数据),为该列创建索引,就意味着该列的数据会被完整地记录在每个数据页的每条记录中,会占用相当大的存储空间。
对此,我们可以为该列的前几个字符创建索引,也就是在二级索引的记录中只会保留字符串的前几个字符。比如我们可以为 phone列创建索引,索引只保留手机号的前3位:
ALTER TABLE user_innodb ADD INDEX IDX_PHONE_3 (phone(3));
然后执行下面的SQL语句:
EXPLAIN SELECT * FROM user_innodb WHERE phone = '1320';

由于在 IDX_PHONE_3索引中只保留了手机号的前3位数字,所以我们只能定位到以132开头的二级索引记录,然后在遍历所有的这些二级索引记录时再判断它们是否满足第4位数为0的条件。
当列中存储的字符串包含的字符较多时,为该字段建立前缀索引可以有效节省磁盘空间
5.5 频繁更新的值,不要作为主键或索引
因为可能涉及到数据页分裂的情况,会影响性能。
5.6 随机无序的值,不建议作为索引,例如身份证、UUID
具体原因我在图解|12张图解释MySQL主键查询为什么这么快文章中讲过,感兴趣可以阅读一下。
6. 推荐阅读
我是蝉沐风,如果你觉得这篇文章写得不错,请点赞和评论,你们的支持对我非常重要!我们下期见!
Original: https://www.cnblogs.com/chanmufeng/p/16012145.html
Author: 蝉沐风
Title: 图解|用好MySQL索引,你需要知道的一些事情
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/710958/
转载文章受原作者版权保护。转载请注明原作者出处!