

系列文章目录
文章目录
简介
任务介绍:给40个州的前三天的features(以及前两天的label,即新冠确诊)预测第三天的新冠确诊
数据集介绍:40个州(one-hot编码形式)+第一天的features+第一天label+第二天features+第二天label+第三天的features+第三天的label
实验部分
Simple Baseline
运行初始代码,提交

; Medium Baseline
Feature selection: 40 states + 2 tested_positive (TODO in dataset)
用州的信息加上前两天的阳性病例
if not target_only:
feats = list(range(93))
else:
feats=list(range(40))+[57,75]
pass
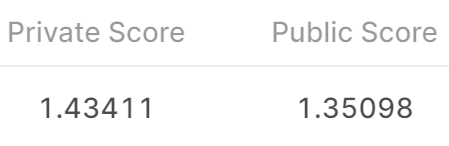
设置target_only=True,重新训练。发现评分有了一定提高。但在dev集上的测试loss变高了(0.7592->0.9582)
下图为kaggle提交评分
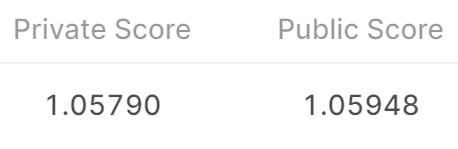
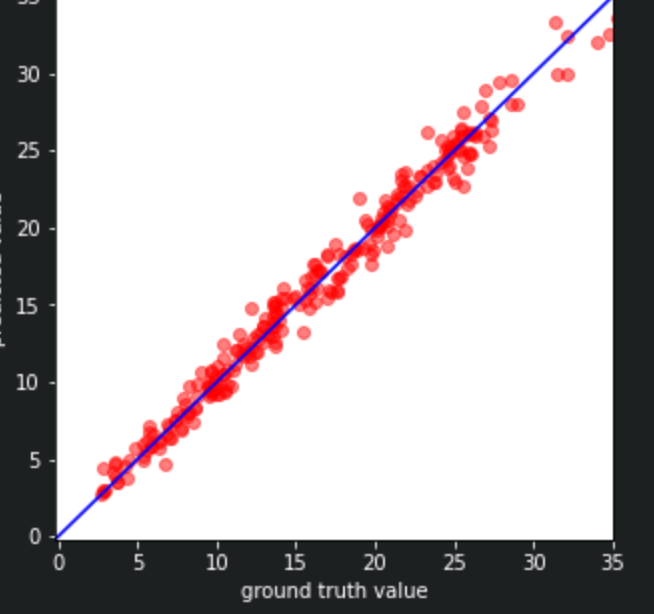
在dev集上的测试结果:如图是dev的预测结果和真实值(红点)之间的关系。
Strong Baseline
模型参数选择(损失函数、激活函数)
Loss由MSE改为RMSE。因为最终Kaggle上的分数就是通过RMSE计算得出
''' Calculate loss '''
def cal_loss(self, pred, target):
return torch.sqrt(self.criterion(pred, target))
但这个感觉区别不大,dev上loss为0.9582,上一种是0.9779。
提交到kaggle上也没有明显变好
激活函数有试过LeakyReLU,但并没有变好(不知道是不是因为调参问题)
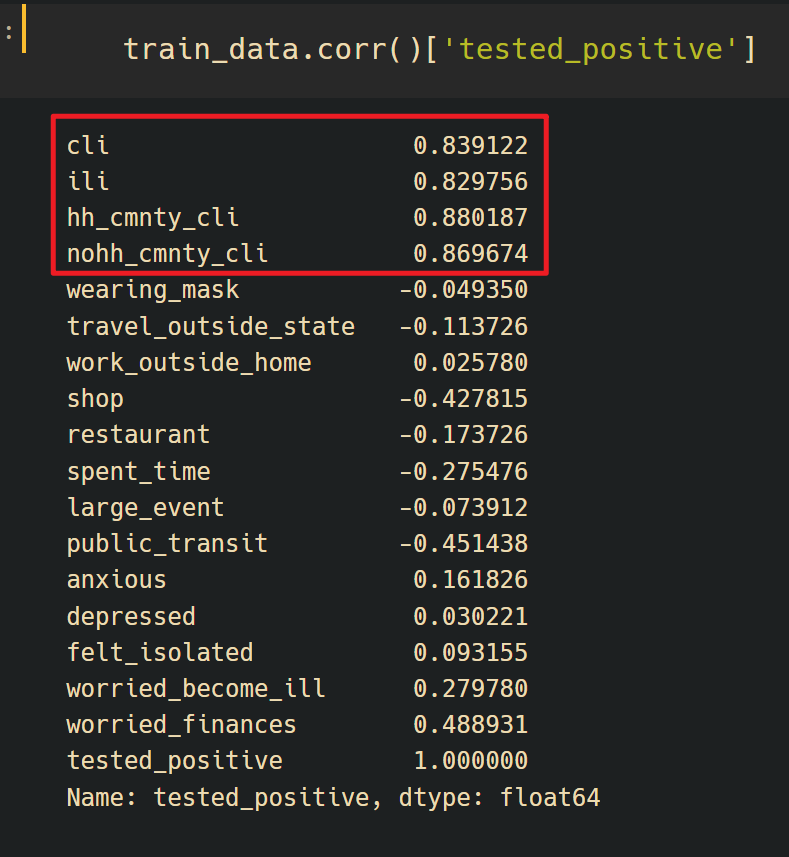
特征选择
又选择了”类Covid-19病例”作为特征
if not target_only:
feats = list(range(93))
else:
feats = list(range(40)) + list(range(40,44)) + [57] + list(range(58,62)) + [75] + list(range(76,80))
因为这几个数据在对全部特征计算皮尔逊相关系数后和相关度较高(也选过0.4几的试了一下但不如只选这几个)
当然也可以用sklearn选出最有效的一些特征:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
import pandas as pd
features = pd.read_csv('../data/ML2021_hw1_COVID-19_Cases_Prediction/covid.train.csv')
x_data, y_data = features.iloc[:, 40:-1], features.iloc[:, -1]
k = 15
selector = SelectKBest(score_func=f_regression, k=k)
result = selector.fit(x_data, y_data)
idx = np.argsort(result.scores_)[::-1]
print(f'Top {k} Best feature score ')
print(result.scores_[idx[:k]])
print(f'\nTop {k} Best feature index ')
print(idx[:k])
print(f'\nTop {k} Best feature name')
print(x_data.columns[idx[:k]])
selected_idx = list(np.sort(idx[:k]))
print(selected_idx)
print(x_data.columns[selected_idx])
运行结果:
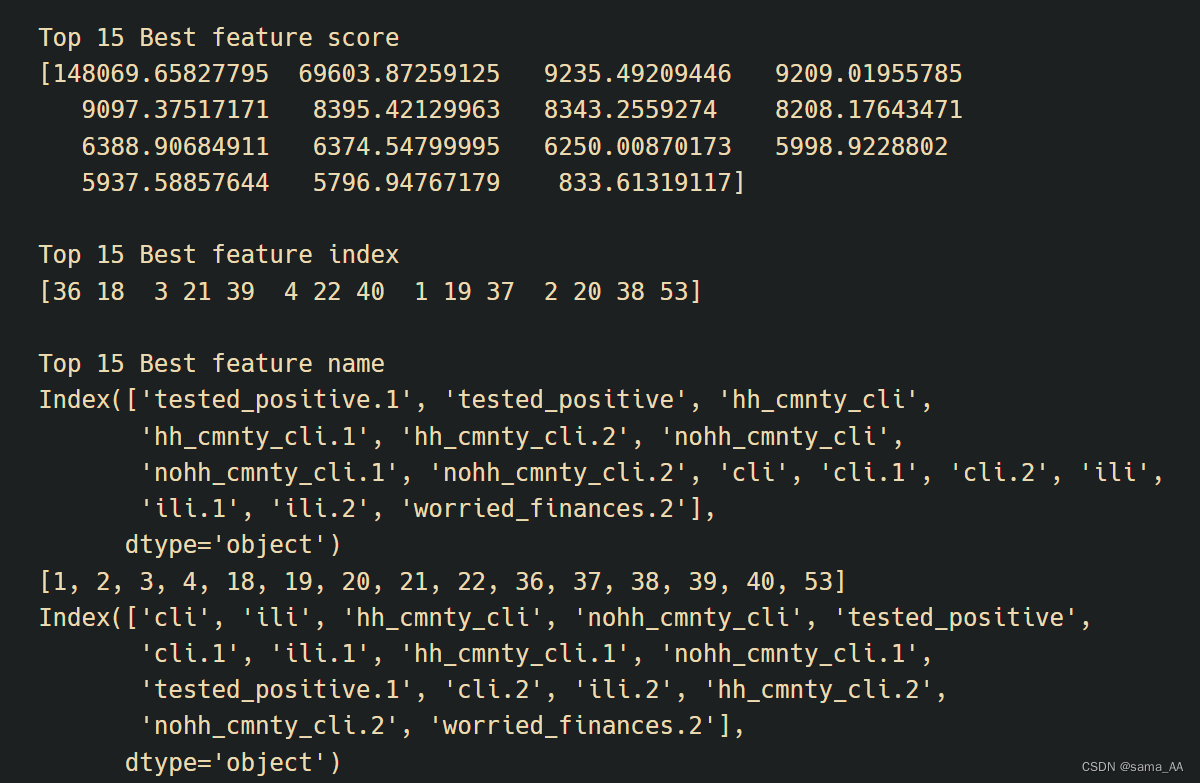
会发现得到的结果和之前手动做相关性系数分析是一样的,这里写成了一个模块,直接输出了下标,方便之后选择特征使用。
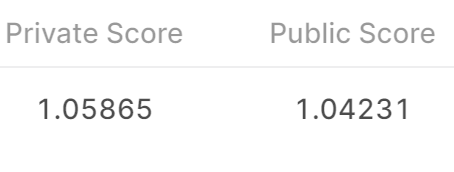
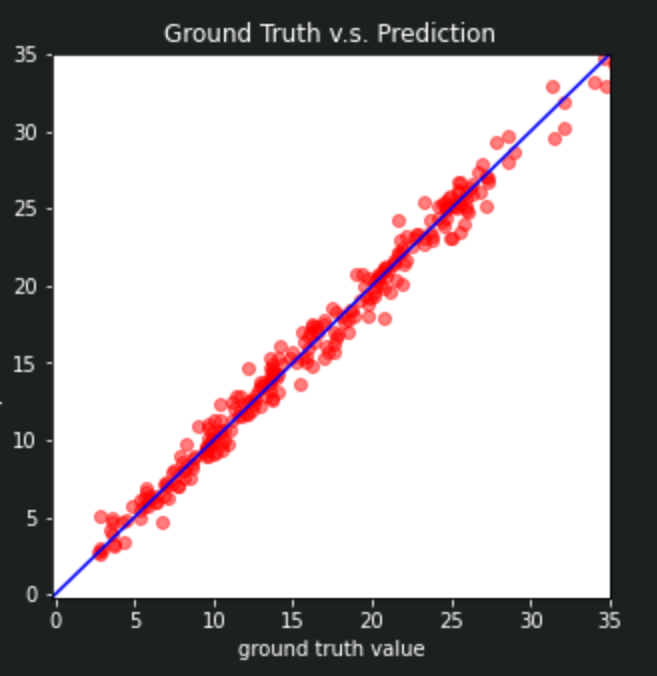
这次在dev上看loss降低的很明显,降为了0.8979.再放个图
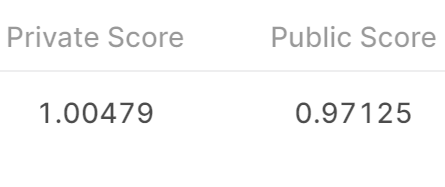
提交结果
L1/L2 Regularization
weight_decay一开始设置为1e-5时,效果反而不好,估计是太大了,于是减小,到1e-8的时候开始有一点点变好(loss:0.9162和0.8977),此事有一个很有意思的的事,设置到1e-9的时候,dev和train的loss都会减小(0.9074和0.8973),我本来以为肯定预测效果更好,但提交上去分数没有比1e-8的时候好.下面是weight_decay=1e-8时的提交结果

有关weight_decay的调整:这个模型估计是因为比较简单所以不需要太大的weight_decay,正常好像要在1e-4左右。
另外,大型模型中dropout也能缓解过拟合,但这个小模型就算了吧。
; 余弦退火学习率
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,
T_0=2, T_mult=2, eta_min=config['optim_hparas']['lr']/50)
每一次跑完一整个训练集加上
scheduler.step()
提交得到了目前最好的结果(但没好多少就是了)

调整模型
目前加深模型并没有变得很好用,以后有时间再试吧。估计是是数据量太少了加深反而过拟合
优化函数
换过Adam,并没有变好
总结
在本地跑命名train和dev的loss都下降了但提交上去分数低了的原因:过拟合。只有通过测试集才能判断过拟合。验证集说是验证集但本质上还是训练集,测试集是我们不可能知道的,也就是说通过验证集看是否过拟合是不科学的,验证集的主要作用是early_stop。
收获
优化代码思路
主要分三大块:
1.数据
2.模型
3.调优
数据预处理”模板”
有关建立Dataset的两种方法以及dataloader的应用:
具体参考下面文章,讲的很清晰
pytorch中Dataset,TensorDataset和DataLoader用法_鬼道2022的博客-CSDN博客_data.tensordataset
1.利用自带的TensorDataset
dataset=torch.utils.data.TensorDataset(train_features, train_labels)
2.继承Dataset自定义类
注意:需要重载init、getitem和len方法
最后生成DataLoader:按照参数顺序把dataset和其他的传入torch.utils.data.DataLoader即可
Original: https://blog.csdn.net/sama_AA/article/details/124348117
Author: sama_AA
Title: 李宏毅2021ML-hw1 新冠预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/710274/
转载文章受原作者版权保护。转载请注明原作者出处!