

一、数据集准备
SSD代码:GitHub – amdegroot/ssd.pytorch: A PyTorch Implementation of Single Shot MultiBox Detector
采用的VOC格式的数据集,在data文件夹下新建文件夹VOCdevkit/VOC2007,数据集放在该路径下。数据集包括Annotations(放xml文件)、ImageSets、JPEGImages(放图片),ImageSets下又Main,包含test.txt、train.txt、val.txt、trainval.txt,用于划分数据集。
yolo格式数据集转VOC格式的代码如下:
24行:更改类别名,顺序要按yolo标注的顺序写
67、101行:更改图片格式
107行:更改图片的路径
216、218、220行:更改文件夹路径地址
-*- coding: utf-8 -*-
import os
import xml.etree.ElementTree as ET
from xml.dom.minidom import Document
import cv2
'''
import xml
xml.dom.minidom.Document().writexml()
def writexml(self,
writer: Any,
indent: str = "",
addindent: str = "",
newl: str = "",
encoding: Any = None) -> None
'''
class YOLO2VOCConvert:
def __init__(self, txts_path, xmls_path, imgs_path):
self.txts_path = txts_path # 标注的yolo格式标签文件路径
self.xmls_path = xmls_path # 转化为voc格式标签之后保存路径
self.imgs_path = imgs_path # 读取读片的路径各图片名字,存储到xml标签文件中
self.classes = ['pedestrian', 'cyclist', 'car', 'large vehicle']
# 从所有的txt文件中提取出所有的类别, yolo格式的标签格式类别为数字 0,1,...
# writer为True时,把提取的类别保存到'./Annotations/classes.txt'文件中
def search_all_classes(self, writer=False):
# 读取每一个txt标签文件,取出每个目标的标注信息
all_names = set()
txts = os.listdir(self.txts_path)
# 使用列表生成式过滤出只有后缀名为txt的标签文件
txts = [txt for txt in txts if txt.split('.')[-1] == 'txt']
print(len(txts), txts)
# 11 ['0002030.txt', '0002031.txt', ... '0002039.txt', '0002040.txt']
for txt in txts:
txt_file = os.path.join(self.txts_path, txt)
with open(txt_file, 'r') as f:
objects = f.readlines()
for object in objects:
object = object.strip().split(' ')
print(object) # ['2', '0.506667', '0.553333', '0.490667', '0.658667']
all_names.add(int(object[0]))
# print(objects) # ['2 0.506667 0.553333 0.490667 0.658667\n', '0 0.496000 0.285333 0.133333 0.096000\n', '8 0.501333 0.412000 0.074667 0.237333\n']
print("所有的类别标签:", all_names, "共标注数据集:%d张" % len(txts))
return list(all_names)
def yolo2voc(self):
# 创建一个保存xml标签文件的文件夹
if not os.path.exists(self.xmls_path):
os.mkdir(self.xmls_path)
# 把上面的两个循环改写成为一个循环:
imgs = os.listdir(self.imgs_path)
txts = os.listdir(self.txts_path)
txts = [txt for txt in txts if not txt.split('.')[0] == "classes"] # 过滤掉classes.txt文件
print(txts)
# 注意,这里保持图片的数量和标签txt文件数量相等,且要保证名字是一一对应的 (后面改进,通过判断txt文件名是否在imgs中即可)
if len(imgs) == len(txts): # 注意:./Annotation_txt 不要把classes.txt文件放进去
map_imgs_txts = [(img, txt) for img, txt in zip(imgs, txts)]
txts = [txt for txt in txts if txt.split('.')[-1] == 'txt']
print(len(txts), txts)
for img_name, txt_name in map_imgs_txts:
# 读取图片的尺度信息
img_name=txt_name.split('.')[0] + '.jpg'
print("读取图片:", img_name)
img = cv2.imread(os.path.join(self.imgs_path, img_name))
height_img, width_img, depth_img = img.shape
print(height_img, width_img, depth_img) # h 就是多少行(对应图片的高度), w就是多少列(对应图片的宽度)
# 获取标注文件txt中的标注信息
all_objects = []
txt_file = os.path.join(self.txts_path, txt_name)
with open(txt_file, 'r') as f:
objects = f.readlines()
for object in objects:
object = object.strip().split(' ')
all_objects.append(object)
print(object) # ['2', '0.506667', '0.553333', '0.490667', '0.658667']
# 创建xml标签文件中的标签
xmlBuilder = Document()
# 创建annotation标签,也是根标签
annotation = xmlBuilder.createElement("annotation")
# 给标签annotation添加一个子标签
xmlBuilder.appendChild(annotation)
# 创建子标签folder
folder = xmlBuilder.createElement("folder")
# 给子标签folder中存入内容,folder标签中的内容是存放图片的文件夹,例如:JPEGImages
folderContent = xmlBuilder.createTextNode(self.imgs_path.split('/')[-1]) # 标签内存
folder.appendChild(folderContent) # 把内容存入标签
annotation.appendChild(folder) # 把存好内容的folder标签放到 annotation根标签下
# 创建子标签filename
filename = xmlBuilder.createElement("filename")
# 给子标签filename中存入内容,filename标签中的内容是图片的名字,例如:000250.jpg
filenameContent = xmlBuilder.createTextNode(txt_name.split('.')[0] + '.jpg') # 标签内容
filename.appendChild(filenameContent)
annotation.appendChild(filename)
#path
path = xmlBuilder.createElement("path")
pathContent = xmlBuilder.createTextNode('/home/seucar/Sunyx/ssd.pytorch-master/data/VOCdevkit/VOC2007/JPEGImages/'+txt_name.split('.')[0] + '.jpg')
path.appendChild(pathContent)
annotation.appendChild(path)
#source
source=xmlBuilder.createElement("source")
database = xmlBuilder.createElement("database")
databaseContent = xmlBuilder.createTextNode('Unknown')
database.appendChild(databaseContent)
source.appendChild(database)
annotation.appendChild(source)
# 把图片的shape存入xml标签中
size = xmlBuilder.createElement("size")
# 给size标签创建子标签width
width = xmlBuilder.createElement("width") # size子标签width
widthContent = xmlBuilder.createTextNode(str(width_img))
width.appendChild(widthContent)
size.appendChild(width) # 把width添加为size的子标签
# 给size标签创建子标签height
height = xmlBuilder.createElement("height") # size子标签height
heightContent = xmlBuilder.createTextNode(str(height_img)) # xml标签中存入的内容都是字符串
height.appendChild(heightContent)
size.appendChild(height) # 把width添加为size的子标签
# 给size标签创建子标签depth
depth = xmlBuilder.createElement("depth") # size子标签width
depthContent = xmlBuilder.createTextNode(str(depth_img))
depth.appendChild(depthContent)
size.appendChild(depth) # 把width添加为size的子标签
annotation.appendChild(size) # 把size添加为annotation的子标签
#segmented
segmented=xmlBuilder.createElement("segmented")
segmentedContent = xmlBuilder.createTextNode('0')
segmented.appendChild(segmentedContent)
annotation.appendChild(segmented)
# 每一个object中存储的都是['2', '0.506667', '0.553333', '0.490667', '0.658667']一个标注目标
for object_info in all_objects:
# 开始创建标注目标的label信息的标签
object = xmlBuilder.createElement("object") # 创建object标签
# 创建label类别标签
# 创建name标签
imgName = xmlBuilder.createElement("name") # 创建name标签
imgNameContent = xmlBuilder.createTextNode(self.classes[int(object_info[0])])
imgName.appendChild(imgNameContent)
object.appendChild(imgName) # 把name添加为object的子标签
# 创建pose标签
pose = xmlBuilder.createElement("pose")
poseContent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(poseContent)
object.appendChild(pose) # 把pose添加为object的标签
# 创建truncated标签
truncated = xmlBuilder.createElement("truncated")
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated)
# 创建difficult标签
difficult = xmlBuilder.createElement("difficult")
difficultContent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultContent)
object.appendChild(difficult)
# 先转换一下坐标
# (objx_center, objy_center, obj_width, obj_height)->(xmin,ymin, xmax,ymax)
x_center = float(object_info[1])*width_img + 1
y_center = float(object_info[2])*height_img + 1
xminVal = int(x_center - 0.5*float(object_info[3])*width_img) # object_info列表中的元素都是字符串类型
yminVal = int(y_center - 0.5*float(object_info[4])*height_img)
xmaxVal = int(x_center + 0.5*float(object_info[3])*width_img)
ymaxVal = int(y_center + 0.5*float(object_info[4])*height_img)
# 创建bndbox标签(三级标签)
bndbox = xmlBuilder.createElement("bndbox")
# 在bndbox标签下再创建四个子标签(xmin,ymin, xmax,ymax) 即标注物体的坐标和宽高信息
# 在voc格式中,标注信息:左上角坐标(xmin, ymin) (xmax, ymax)右下角坐标
# 1、创建xmin标签
xmin = xmlBuilder.createElement("xmin") # 创建xmin标签(四级标签)
xminContent = xmlBuilder.createTextNode(str(xminVal))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin)
# 2、创建ymin标签
ymin = xmlBuilder.createElement("ymin") # 创建ymin标签(四级标签)
yminContent = xmlBuilder.createTextNode(str(yminVal))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin)
# 3、创建xmax标签
xmax = xmlBuilder.createElement("xmax") # 创建xmax标签(四级标签)
xmaxContent = xmlBuilder.createTextNode(str(xmaxVal))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax)
# 4、创建ymax标签
ymax = xmlBuilder.createElement("ymax") # 创建ymax标签(四级标签)
ymaxContent = xmlBuilder.createTextNode(str(ymaxVal))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object) # 把object添加为annotation的子标签
f = open(os.path.join(self.xmls_path, txt_name.split('.')[0]+'.xml'), 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == '__main__':
# 把yolo的txt标签文件转化为voc格式的xml标签文件
# yolo格式txt标签文件相对路径
txts_path1 = './labels'
# 转化为voc格式xml标签文件存储的相对路径
xmls_path1 = './Annotations'
# 存放图片的相对路径
imgs_path1 = './JPEGImages'
yolo2voc_obj1 = YOLO2VOCConvert(txts_path1, xmls_path1, imgs_path1)
labels = yolo2voc_obj1.search_all_classes()
print('labels: ', labels)
yolo2voc_obj1.yolo2voc()
二、训练
新建文件夹weights,下载预训练权重VGG16_reducedfc_pth。链接:https://pan.baidu.com/s/1c0K1oNly5FUJjTetTQgf_A
提取码:9cfh
data/conifg.py修改voc里的num_classes和max_iter,类别为自己的类别数+1(背景),最大迭代次数可以适当减小。
data/VOC0712.py修改VOC_CLASSES
ssd.py中修改32行num_classes以及改变pull_item函数如下(解决img, boxes, labels = self.transform(img, target[:, :4], target[:, 4])这行报错,target可能为空):
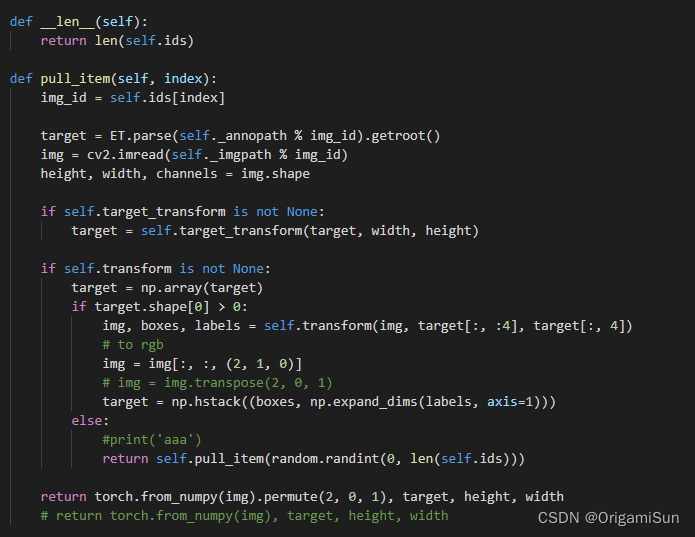

train.py将.data[0]全部替换为.item(),以及如下:

可能还有别的地方需要修改,但我忘了具体位置了,但根据报错直接搜都能解决,就不一一列举了
三、评价
eval.py的do_python_eval函数做如下修改,可以输出Recall、Precision和mAP(f1也有计算但我没输出,有需要可以自己加)。注意修改recs和precs初始时的类别数(不用加背景)
def do_python_eval(output_dir='output', use_07=True):
cachedir = os.path.join(devkit_path, 'annotations_cache')
aps = []
recs = np.zeros((4, 500000)) #4 represent number of classes
precs = np.zeros((4, 500000)) #4 represent number of classes
# The PASCAL VOC metric changed in 2010
use_07_metric = use_07
print('VOC07 metric? ' + ('Yes' if use_07_metric else 'No'))
if not os.path.isdir(output_dir):
os.mkdir(output_dir)
print('1')
for i, cls in enumerate(labelmap):
filename = get_voc_results_file_template(set_type, cls)
rec, prec, ap = voc_eval(
filename, annopath, imgsetpath.format(set_type), cls, cachedir,
ovthresh=0.1, use_07_metric=use_07_metric)
aps += [ap]
#recs += [rec.mean(0)]
#precs += [prec.max(0)]
#print(rec.shape)
rec=rec.reshape(len(rec))
prec=prec.reshape(len(prec))
r=np.pad(rec,(0,500000-len(rec)),'constant',constant_values=(0,0))
p=np.pad(prec,(0,500000-len(prec)),'constant',constant_values=(0,0))
recs[i] = r
precs[i] = p
'''pl.plot(rec, prec, lw=2,
label='{} (AP = {:.4f})'
''.format(cls, ap))'''
print('AP for {} = {:.4f}'.format(cls, ap))
with open(os.path.join(output_dir, cls + '_pr.pkl'), 'wb') as f:
pickle.dump({'rec': rec, 'prec': prec, 'ap': ap}, f)
eps=1e-16
f1 = 2 * precs * recs / (precs + recs + eps)
i = f1.mean(0).argmax()
precs, recs, f1 = precs[:, i], recs[:, i], f1[:, i]
'''pl.xlabel('Recall')
pl.ylabel('Precision')
plt.grid(True)
pl.ylim([0.0, 1.05])
pl.xlim([0.0, 1.0])
pl.title('Precision-Recall')
pl.legend(loc="upper left")
plt.show()'''
print('Mean AP = {:.4f}'.format(np.mean(aps)))
print('recall:',recs)
print('Precision:',precs)
print('recall:',format(np.mean(recs)))
print('Precision:',format(np.mean(precs)))
print('~~~~~~~~')
print('Results:')
for ap in aps:
print('{:.3f}'.format(ap))
print('{:.3f}'.format(np.mean(aps)))
print('~~~~~~~~')
print('')
print('--------------------------------------------------------------')
print('Results computed with the **unofficial** Python eval code.')
print('Results should be very close to the official MATLAB eval code.')
print('--------------------------------------------------------------')
Original: https://blog.csdn.net/OrigamiSun/article/details/124715265
Author: OrigamiSun
Title: SSD(pytorch)自建数据集训练及测试
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/710270/
转载文章受原作者版权保护。转载请注明原作者出处!