

一、简介
- 损失函数的作用: 主要用于深度学习中predict与True label “距离”度量或者”相似度度量”,并通过反向传播求梯度,进而通过梯度下降算法更新网络参数,周而复始,通过损失值和评估值反映模型的好坏。
- 损失函数的分类: 主要分为回归损失函数和分类损失函数。
- 回归损失函数:
reg_loss(回归预测一个具体的数值,真实的一个具体值),比如我要预测一个矩形框的宽高,一般来说可以使任意值。一般的回归会将预测的值设计到一个较小的范围比如 0~1范围内,这样可以加速模型收敛,要不然模型前期预测的数值”乱跳”,出现波动的情况。一般有L1 Loss、L2 Loss、Smooth L1 Loss,以及在一些任务如目标检测中根据场景设置的loss如,IOU Loss、GIOU Loss、DIOU Loss、CIOU Loss。 - 分类损失函数:
reg_loss(回归预测一个具体的数值,真实的一个具体值),比如我要预测一个矩形框的宽高,一般来说可以使任意值。一般的回归会将预测的值设计到一个较小的范围比如 0~1范围内,这样可以加速模型收敛,要不然模型前期预测的数值”乱跳”,出现波动的情况。一般有CrossEntropy Loss、NLL Loss、KLDiv Loss、BCE Loss、BCE With Logits Loss、Margin Ranking Loss、Hinge Embedding Loss、Huber Loss等。
需要注意的:
pytorch损失函数中一般有 size_average、 size_average、 reduction这三个参数。
这三个参数决定损失函数是1.只求是loss; 2. 对loss求和;3. 对loss求平均。
( deprecated表示此方法已废弃、暂时可用,但以后该方法不会再更新,建议后来人不要调用此方法。)
size_average 和 reduce 是deprecated,两个之间是有关系的。目前使用的 reduction。
Reducesize_averageresultFalse-1. 只是求loss(忽略size_average参数)TrueFalse2. 对loss求和TrueTrue3. 对loss求平均值 Reduceresult’None’1. 只是求loss(忽略size_average参数)’sum’2. 对loss求和’mean’3. 对loss求平均值
二、回归损失函数
回归问题就是预测出具体的数值,比如我要预测电池电压的具体值,具体值不是固定的,分类问题就是我要预测电池电压值处于故障状态类别还是正常状态类别,类别数目是固定的。
1. L1 Loss(绝对值损失)
介绍
L1 Loss即平均绝对误差(Mean Absolute Error, MAE),公式为:
l ( x , y ) = 1 N ∑ i = 1 N ∣ x i − y i ∣ l(x,y) = \frac{1}{N}\sum_{i=1}^{N}|x_i-y_i|l (x ,y )=N 1 i =1 ∑N ∣x i −y i ∣
就是求预测值和真实值误差的绝对值。
代码
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
from torch import nn
loss = nn.L1Loss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()
2. L2 Loss (MSE Loss)(平方损失)
介绍:
L2 Loss即均方差(Mean Squred Error, MSE),公式为:
l ( x , y ) = 1 N ∑ i = 1 N ( x i − y i ) 2 l(x,y) = \frac{1}{N}\sum_{i=1}^{N}(x_i-y_i)^2 l (x ,y )=N 1 i =1 ∑N (x i −y i )2
就是求预测值和真实值误差的绝对值。
代码:
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
from torch import nn
loss = nn.MSELoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()
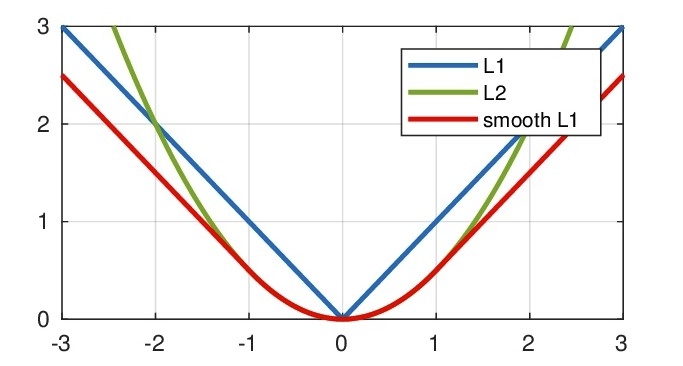
小结: 1. L1 Loss:0处导数不连续,收敛速度慢。 对异常值不敏感,因为是求平均,会忽略掉异常值的作用,一般可用于有少许数据错误的值,这样就可以忽略掉这些错误的离群值。
2. 1. L2 Loss:收敛速度快,对异常值敏感,如果是需要进行异常检测,就不能忽略掉离群值。
假如数据集多数为1000,少数为10,那么L1会偏向1000(因为更偏向于平均),L2则会偏向于10,因为对离群值更敏感,所以实际中这两种都不太可取,所以Smooth L1 Loss可以同时利用两者的优点。
3. Smooth L1 Loss
介绍:
平滑的L1损失(Smooth L1 Loss, SLL),在Faster RCNN中被提出来,公式为:
l ( x , y ) = { 0.5 ( x i − y i ) 2 b e t a , i f ∣ x i − y i ∣ < b e t a ∣ x i − y i ∣ − 0.5 ∗ b e t a , o t h e r w i s e l(x,y)=\left{ \begin{aligned} \frac{0.5(x_i – y_i)^2}{beta}, if |x_i – y_i| < beta \ |x_i-y_i|-0.5*beta, otherwise \end{aligned} \right.l (x ,y )=⎩⎨⎧b e t a 0 .5 (x i −y i )2 ,i f ∣x i −y i ∣<b e t a ∣x i −y i ∣−0 .5 ∗b e t a ,o t h e r w i s e
代码:
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0)
beta的作用:控制什么范围的误差使用MSE,什么范围内的误差内使用MAE。
Smooth L1 Loss的优点:
- 结合了L1 Loss对离群点、异常值不敏感的优点。
- 结合了L2 Loss在0处可导数,收敛速度快、训练不容易跑飞的优点。

; 4. Huber L1 Loss
介绍:
H u b e r L 1 L o s s = b e t a ∗ S m o o t h L 1 L o s s Huber L1 Loss = betaSmoothL1Loss H u b e r L 1 L o s s =b e t a ∗S m o o t h L 1 L o s s,公式为:
l ( x , y ) = { 0.5 ( x i − y i ) 2 , i f ∣ x i − y i ∣ < b e t a b e t a ∗ ( ∣ x i − y i ∣ − 0.5 ∗ b e t a ) , o t h e r w i s e l(x,y)=\left{ \begin{aligned} {0.5(x_i – y_i)^2}, if |x_i – y_i| < beta \ beta(|x_i-y_i|-0.5*beta), otherwise \end{aligned} \right.l (x ,y )={0 .5 (x i −y i )2 ,i f ∣x i −y i ∣<b e t a b e t a ∗(∣x i −y i ∣−0 .5 ∗b e t a ),o t h e r w i s e
代码:
torch.nn.HuberLoss(reduction='mean', delta=1.0)
SmoothL1Loss和HuberLoss区别:
- 当beta趋于0时,
SmoothL1Loss收敛于L1Loss,HuberLoss收敛于常数0; - 当beta趋于无穷时,
SmoothL1Loss收敛于常数0,HuberLoss收敛于MSELoss - 随着beta的变化,
SmoothL1Loss中平均绝对误差段的斜率恒定为1;而HuberLos中平均绝对误差段的斜率是beta
4. IOU Loss
介绍:
在之前的目标检测中,回归损失都是回归矩形框的四个变量,这样做就默认将四个变量认为是相互独立的,这样”粗暴”的直接回归效果往往不会太好,引入交并比损失(IOU Loss)则可以把四个变量关联起来。
公式:
L ( i o u ) = − l n ( i o u ) L(iou) = -ln(iou)L (i o u )=−l n (i o u )
通常也是用如下公式:
L ( i o u ) = 1 − i o u L(iou) = 1-iou L (i o u )=1 −i o u
代码:
- 先将bbox坐标转换为x 1 y 1 x_1y_1 x 1 y 1 x 2 y 2 x_2y_2 x 2 y 2
- 求出交集区域面积:
宽=两个bbox中最小的x 2 x_2 x 2 – 两个bbox中最大的x 1 x_1 x 1 (需要使用clamp成0,防止越界)
高 = 两个bbox中最小的y 2 y_2 y 2 – 两个bbox中最大的y 1 y_1 y 1 (需要使用clamp成0,防止越界)
然后交集区域面积i n t e r = 宽 ∗ 高 inter=宽*高i n t e r =宽∗高 - 求出并集区域面积:
union = (w1 _h1 + w2_h2) – inter,因为并集union要作为分母,所以要考虑是0的情况,所以需要加一个很小的常数e p s eps e p s - 计算iou,i o u = i n t e r u n i o n iou=\frac{inter}{union}i o u =u n i o n i n t e r
import torch
def bbox_iou(box1, box2, x1y1x2y2=True, eps=1e-7):
"""用计算回归损失
:params box1: 预测框 shape:(4, n)
:params box2: 预测框 shape:(n, 4)
:return box1和box2的IoU shape:(1, n)
"""
box2 = box2.T
if x1y1x2y2:
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else:
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
return iou
5. GIOU Loss(Generalized-IoU Loss)
介绍
IOU Loss的缺点:
- 1 两box无相交,IOU=0,不能反映两者的距离大小(重合度),同时Loss为0,没有梯度回传,无法进行训练。
- 2 IOU在一些情况下无法精确反映两box的重合度大小。比如,IOU相同的情况下,有的效果好,有的效果差,但是使用IOU则无法进行精确的区分哪个更好,因为IOU都一致。
GIOU:
- 公式:
G I O U = I O U − ∣ A c − U ∣ ∣ A c ∣ GIOU = IOU – \frac{|A_c-U|}{|A_c|}G I O U =I O U −∣A c ∣∣A c −U ∣
其中A c A_c A c 为两个框最小闭包区域面积,U = 两 个 框 的 并 集 U=两个框的并集U =两个框的并集。总体来说为:IOU-闭 包 区 域 中 不 属 于 两 个 框 的 区 域 闭 包 区 域 \frac{闭包区域中不属于两个框的区域}{闭包区域}闭包区域闭包区域中不属于两个框的区域
L ( G I O U ) = 1 − G I O U L(GIOU) = 1-GIOU L (G I O U )=1 −G I O U
-
特性:
-
GIOU有对称区间,取值范围为[-1, 1]。两者重合时取最大值1,无交集且无限远时候取最小值-1。
- IOU只关注重叠区域,GIOU不仅关注重叠区域,还关注其他非重合区域。
代码
def bbox_GIoU(box1, box2, x1y1x2y2=True, eps=1e-7):
"""用计算回归损失
:params box1: 预测框 shape:(4, n)
:params box2: 预测框 shape:(n, 4)
:return box1和box2的GIoU shape:(1, n)
"""
box2 = box2.T
if x1y1x2y2:
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else:
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1)
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1)
c_area = cw * ch + eps
return iou - (c_area - union) / c_area
6. DIOU Loss(Distance-IoU Loss)
介绍:
DIoU的优点:
- 1 保留了GIoU不重叠时仍能度量的优点。
- 2 DIoU Loss可以直接优化两个目标的距离,因此比GIoU Loss收敛速度更快。
- 3 在GT_Box包含预测框的情况下,DIoU Loss可以收敛的更快,而GIoU Loss退化成IoU Loss收敛速度较慢。
DIOU:
- 公式:
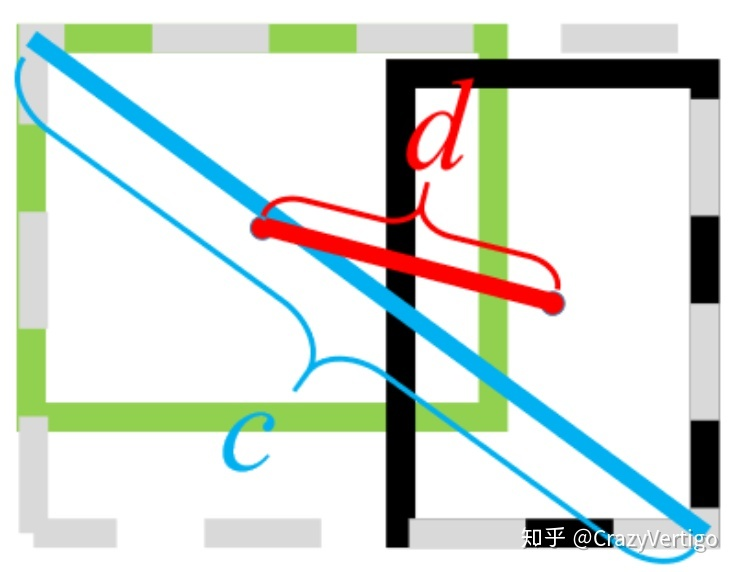
D I o U = I o U − ρ 2 ( b , b g t ) c 2 DIoU = IoU – \frac{\rho^{2}(b, b^{gt})}{c^2}D I o U =I o U −c 2 ρ2 (b ,b g t )
其中b b b和b g t b^{gt}b g t分别代表了预测框和真实框的中心点,ρ \rho ρ为计算欧式距离,c代表最小闭包区域的对角线距离。(PS:减号后面称为惩罚项,可直观的理解为两框的距离与最小闭包区域距离平方的比值)
L ( D I o U ) = 1 − I o U + ρ 2 ( b , b g t ) c 2 L(DIoU) = 1-IoU + \frac{\rho^{2}(b, b^{gt})}{c^2}L (D I o U )=1 −I o U +c 2 ρ2 (b ,b g t )
; 代码:
def bbox_DIoU(box1, box2, x1y1x2y2=True, eps=1e-7):
"""用计算回归损失
:params box1: 预测框 shape:(4, n)
:params box2: 预测框 shape:(n, 4)
:return box1和box2的DIoU shape:(1, n)
"""
box2 = box2.T
if x1y1x2y2:
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else:
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1)
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1)
c2 = cw ** 2 + ch ** 2 + eps
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4
return iou - rho2 / c2
7. C-IoU Loss(Complete-IoU Loss)
介绍:
CIoU的优点:
- 1将长宽比考虑到计算中去
CIoU:
- 公式:

; 代码
def bbox_CIoU(box1, box2, x1y1x2y2=True, eps=1e-7):
"""用计算回归损失
:params box1: 预测框 shape:(4, n)
:params box2: 预测框 shape:(n, 4)
:return box1和box2的CIoU shape:(1, n)
"""
box2 = box2.T
if x1y1x2y2:
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else:
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1)
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1)
c2 = cw ** 2 + ch ** 2 + eps
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4
import math
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha)
小结
目标检测回归框三要素:重叠面积(IoU、GIoU)、中心点距离(DIoU)、长宽比(CIoU)
Original: https://blog.csdn.net/weixin_39263657/article/details/121780642
Author: 要坚持写博客呀
Title: pytorch模型构建(四)——常用的回归损失函数
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/710260/
转载文章受原作者版权保护。转载请注明原作者出处!