

文章目录
*
– 制作自己的VOC数据集
– 生成数据集名称文件
– .xml文件转.txt文件
– 完善自己的YOLO数据集
制作自己的VOC数据集
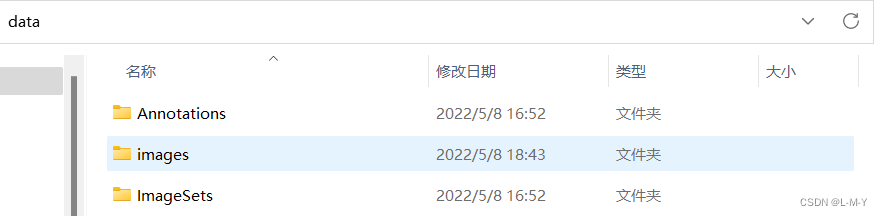
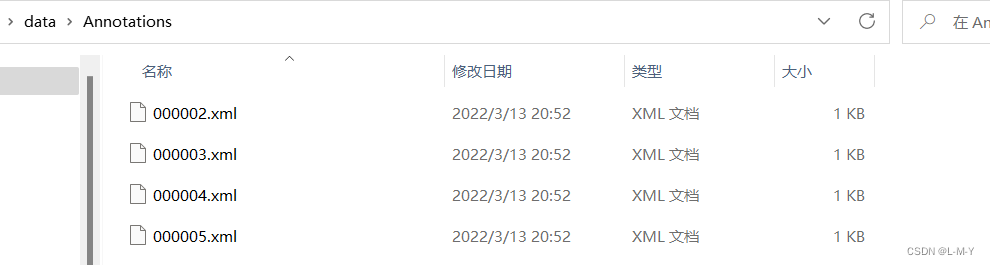
首先,把VOC数据集里的图片和.xml文件按照如下文件夹格式存放


我的数据集各级文件夹如图所示:

; 生成数据集名称文件
train.txt里面存的是所有数据集图片的名称(注意, 是不含后缀名的名称!!!)

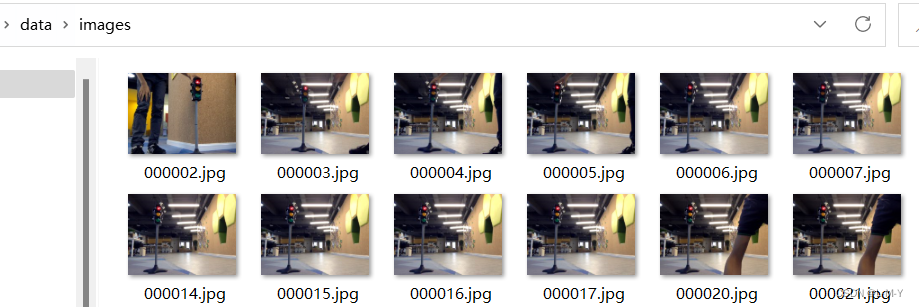
如图,我的images文件夹里有这样几张.jpg文件,在这个images文件夹里建一个.txt文件,内容如图所示:
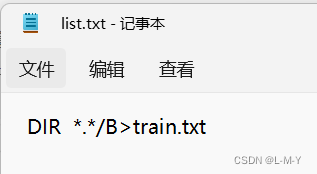
DIR *.*/B>train.txt
修改该.txt文件后缀为.bat,如图:
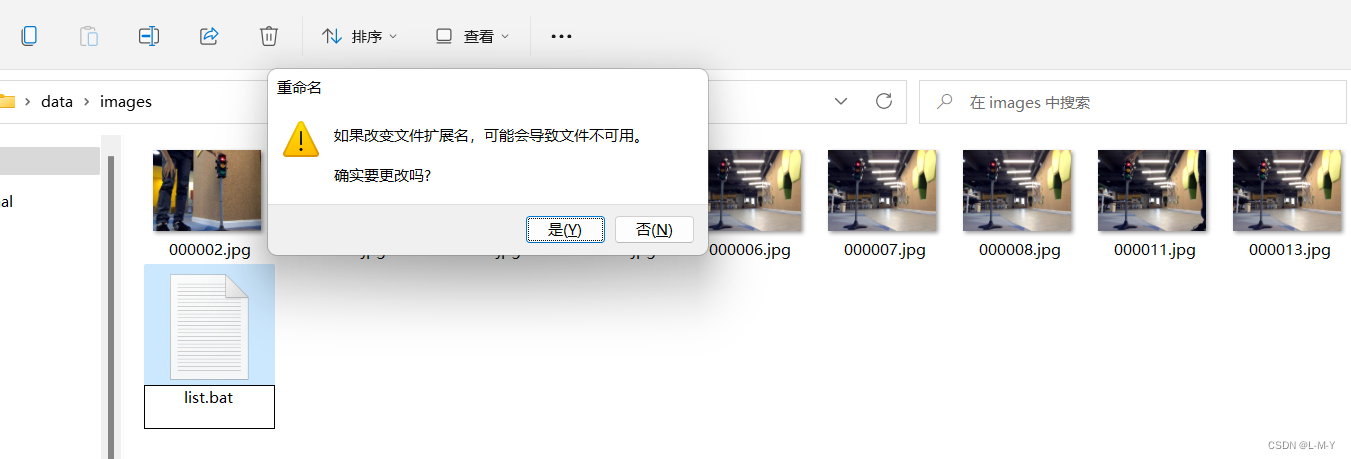
双击这个.bat文件,会看到生成了一个train.txt文件
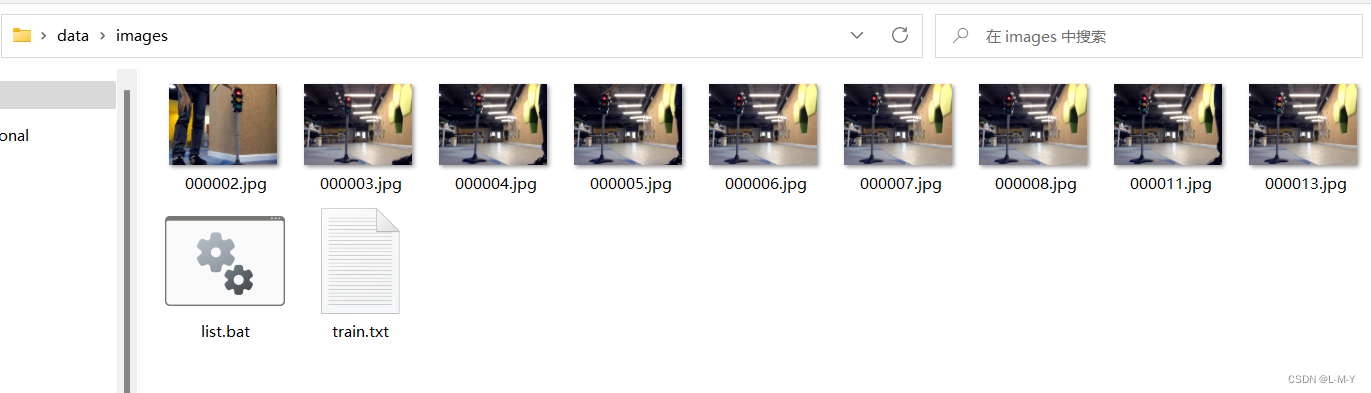
打开train.txt,可以看到里面的内容是images这个文件夹里所有文件的名称。
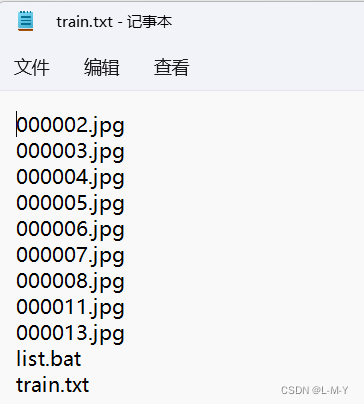
删除list.bat和train.txt这两行,只留下图片的名称
注意:由于最终 train.txt里只能保留图片名称,不含后缀,所以需要把train.txt文件里每一行的”.jpg”删掉,可以手动删除,但如果数据集过大,可使用如下python脚本删除:
import os
filename = r"train.txt"
new_filename = r"train1.txt"
with open(filename,encoding="utf-8") as f1, open(new_filename,"w",encoding="utf-8") as f2:
for line in f1:
new_line = line[:-5]
f2.write(new_line)
f2.write('\n')
f1.close()
f2.close()
运行效果如图所示:
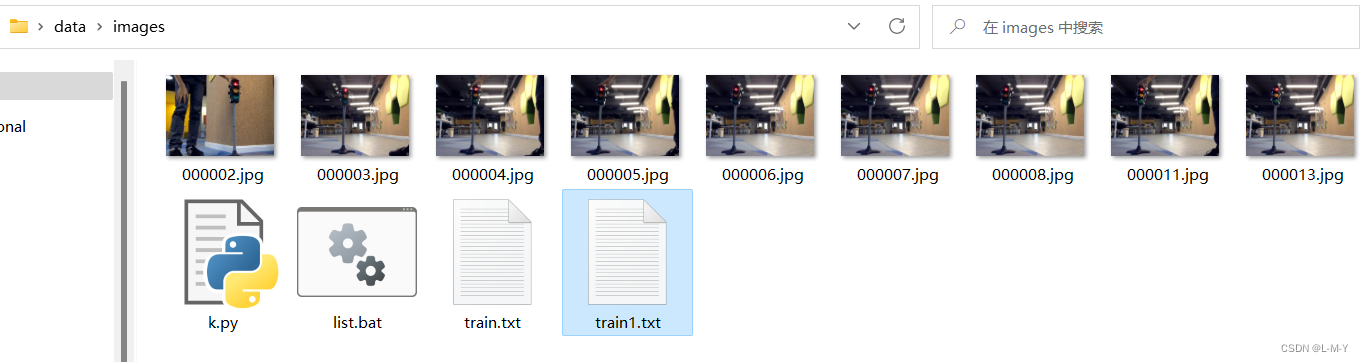
打开新生成的train1.txt可以看到,后缀名都被删掉了

这个时候把train1.txt里的内容复制到\data\ImageSets\Main\train.txt中去。
.xml文件转.txt文件
.xml转.txt文件yolo模型官方有提供转换代码,使用方法下文所示:
创建一个.py文件,内容如下:
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['red', 'yellow','green', 'turn_left', 'turn_right', 'stop']
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('C:/Users/Lenovo/Desktop/data/Annotations/%s.xml' % (image_id),encoding='utf-8')
out_file = open('C:/Users/Lenovo/Desktop/data/labels/%s.txt' % (image_id), 'w',encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('C:/Users/Lenovo/Desktop/data/labels/'):
os.makedirs('C:/Users/Lenovo/Desktop/data/labels/')
image_ids = open('C:/Users/Lenovo/Desktop/data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), mode='w', encoding='utf-8')
for image_id in image_ids:
list_file.write('C:/Users/Lenovo/Desktop/data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
转换代码使用注意事项:
- 把第六行改为’train’, ‘val’, ‘test’
- 第七行classes里的内容改为自己数据集里的类别名称
- 注意各个地址的写法,一定要使用反斜杠
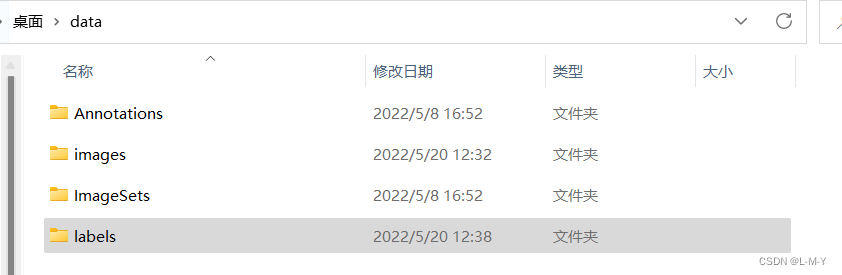
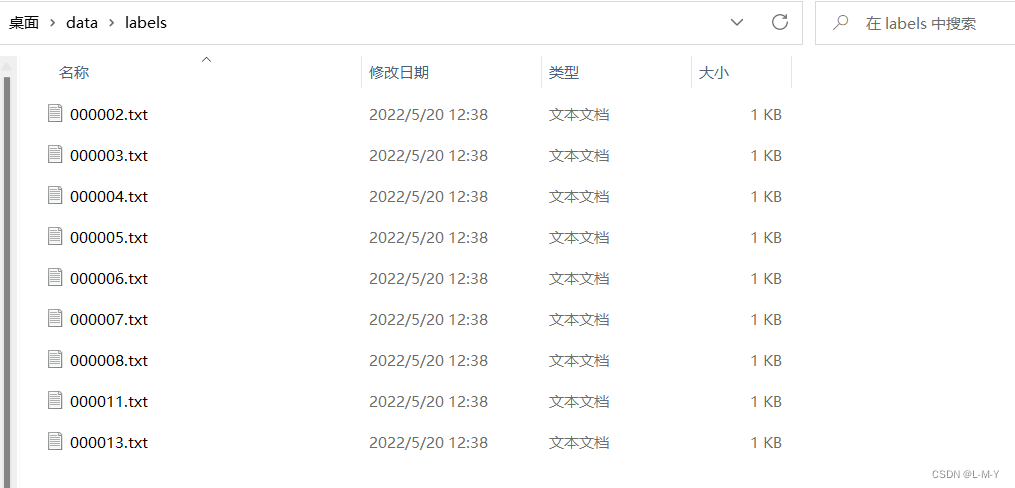
之后运行这段脚本,会发现data里面生成了一个新的lables文件夹,这样便是数据转化成功了
完善自己的YOLO数据集
最后,将labels这个文件夹复制进yolo数据集里即可
Original: https://blog.csdn.net/qq_52109814/article/details/124864143
Author: L-M-Y
Title: VOC数据集转YOLO数据集
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/709095/
转载文章受原作者版权保护。转载请注明原作者出处!