

(pytorch版本:1.2)
文章目录
*
– Dataset取子集、拆分
–
+ 打乱Dataset内数据的顺序
– 随机拆分Dataset
我们在使用Dataset定义好数据集后,在处理数据集时经常会碰到这些问题:如何把Dataset拆分成两个子集(如用于指定训练集和测试集、k折交叉验证等)?如何进行随机拆分?如何打乱一个Dataset内数据的顺序?
Dataset取子集、拆分
使用 torch.utils.data.Subset() 可对数据集取子集。
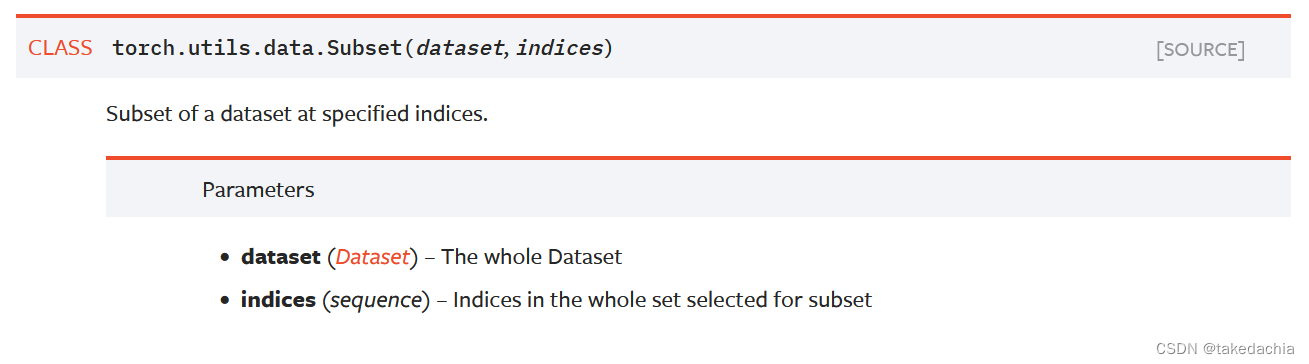

传入一个Dataset,一个序列切片indices,即可得到一个子集。
1.我们可以传入一个range():
indices = range(18353)
sub_imgs = torch.utils.data.Subset(imgs, indices)
len(imgs), len(sub_imgs)

2.可以取区间:
indices = range(18353, 27153)
sub_imgs = torch.utils.data.Subset(imgs, indices)
len(imgs), len(sub_imgs)

3.可以传入一个List。有List就可以用列表生成式:
indices = [x for x in range(1234)]
sub_imgs = torch.utils.data.Subset(imgs, indices)
len(imgs), len(sub_imgs)

打乱Dataset内数据的顺序
我们可以直接传入一个乱序的index就可以达到数据集乱序的目的:
from torch import randperm
lenth = randperm(len(Leaf_dataset_train)).tolist()
rand_train = torch.utils.data.Subset(imgs, lenth)
X = rand_train[0]
plt.imshow(torch.transpose(X[0],0,2)), lenth[0]
我们在打乱顺序后就可以取子集对数据集进行k折交叉验证等行为。
随机拆分Dataset
使用 torch.utils.data.random_split() 可直接对数据集进行拆分,随机分成多份。

可以传入一个List,注意传入的List序列中包含每个子集的大小(数量),且这几个数的和必须 等于传入Dataset的长度。
示例:
train_set, test_set = torch.utils.data.random_split(Leaf_dataset_train, [17000, 1353])
print(len(train_set), len(test_set))

Original: https://blog.csdn.net/takedachia/article/details/125866456
Author: takedachia
Title: 【Pytorch学习笔记】11.取Dataset的子集、给Dataset打乱顺序的方法(使用Subset、random_split)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/708933/
转载文章受原作者版权保护。转载请注明原作者出处!