

预训练模型加载满足条件部分
预训练模型的使用往往可以涨点,因此是一个非常常见的操作,当我们在改模型或者加载模型的某些层的参数时,并不能像常规那样直接加载进来,因此做一个记录。
这里我是用YOLOX做实验
model = exp.get_model()
加载模型权重:
ckpt = torch.load('xxx/xxx.pt', map_location="cpu")
打印一下保存的pt是啥东西,因为YOLOX保存的pt包含model、ema等等,因此只看我们需要的’model’就OK:
for k,v in ckpt['model'].items():
print(k, 'size is', v.size())
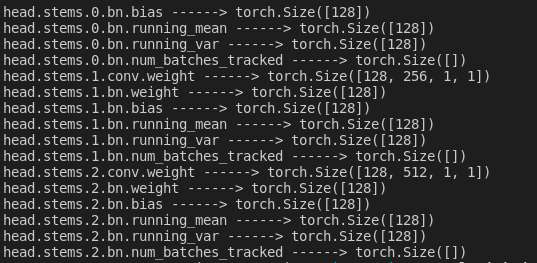

太长只截图部分,可以看到每个op对应一个key和value,感兴趣的可以打印一下value。到此就可以知道预训练权重中有哪些层的参数。接下来在看看修改后的网络有那些层,
model_dict = model.state_dict()
for k,v in model_dict.items():
print(k, '------>', v.size())
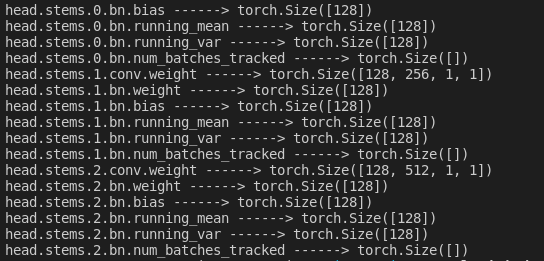
因为预测头没做修改,所以是前后是一致的,实际上load_state_dict()就是把pt的东西根据key赋值到网络中,实现加载数据。
假设在YOLOX中加了一层SE-Attention,那么并不是所有的key都对应的上,因此需要筛选:
ckpt_dict = {k: v for k, v in ckpt['model'].items() if k in model_dict}
更新修改后的网络权重:
model_dict.update(ckpt_dict)
然后再全部加载进加了Attention的网络:
model.load_state_dict(model_dict)
到这里就把预训练权重里面跟修改后的网络的对应部分全部实现了赋值
啰嗦一点,也可以这样获取key和value
for name ,param in model.named_parameters():
print(name)
print(param)
加载主干网络的参数进来,并在训练中不更新
根据前面打印的层的key,可以找到骨干网络的最后一层的信息,这里假设是第150个参数:
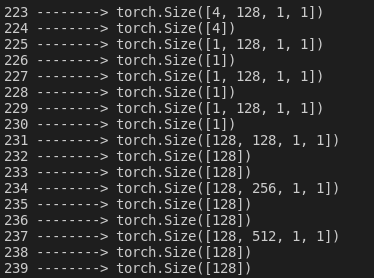
for i, param in enumerate(model.parameters()):
print(i,'-------->',param.size())
if i<150:
param.requires_grad = False
这样训练过程中就不更新主干网络的参数
还有因为类别个数不一样在最后一层需要修改某一层的,以后再做了…
Original: https://blog.csdn.net/weixin_38257276/article/details/123619436
Author: Double-E
Title: 预训练模型使用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/708621/
转载文章受原作者版权保护。转载请注明原作者出处!