

还是搬运来给自己学习啊 多谢体谅拉~~
这里分享混合精度训练的时候遇到的各种问题:1.forward期间nan,2.训练过程中loss scale一泻千里最终导致训练崩溃,以及如何debug。
简介
FP16(半精度浮点数)表示能够提升拥有TensorCore架构的GPU的计算速度(V100)。有很多相关介绍对其运作原理和使用方法进行了说明,本文就不再赘述。其优点可以概括为2点:
1)FP16只占用通常使用的FP32一半的显存。
2)NVIDIA V系列GPU在对FP16计算速度比FP32快上许多(实际加速比根据混合精度使用策略的不同存在差异)。
但是由于FP16的精度远不如FP32,FP16 (6e−8∼65504)(6e-8\sim65504)(6e-8\sim65504) ,FP32 (1.4e−45∼1.7e38)(1.4e-45\sim1.7e38)(1.4e-45\sim1.7e38) ,FP16需要结合 混合精度(Mixed Precision)机制。即使用FP32保存模型参数和完成梯度更新,并且进行一些求和累加的操作(Normalization层)。同时还有另一个非常重要的机制,即 损失放大(Loss Scaling)。通过将loss放大X倍避免backward计算梯度的时候发生下溢(Underflow)。针对损失放大问题,NVIDIA官网中[1]的下图介绍非常形象
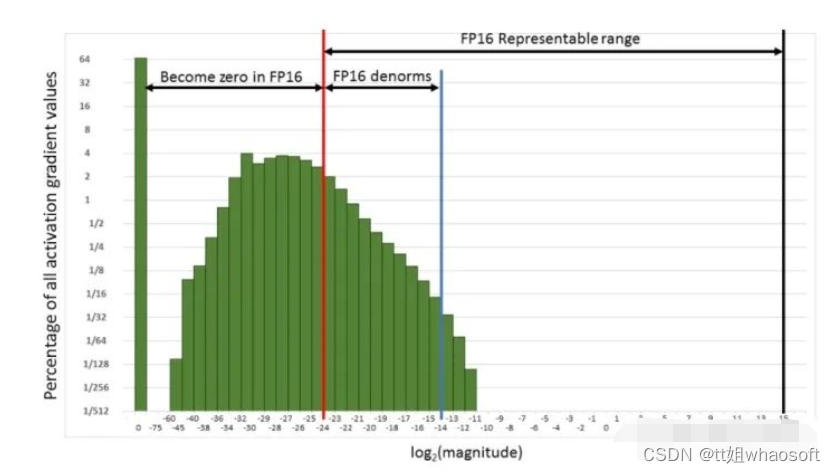

因此需要对loss乘一个loss scale,将其传递到FP16 representable range的安全区域中,这样backward能够享受FP16带来的加速,且对精度的影响控制到最小(计算完梯度后转回FP32除以loss scale再加到同样FP32的模型参数上)。那么这个loss scale自然是越大越能低效下溢问题,但是注意loss scale也不能太大,因为太大的loss sclae会造成grad超出FP16的上限65504从而造成上溢问题。NVIDIA官方推荐的scale阈值是128,换言之小于128阈值的训练通常会造成无法忽视的下溢问题。

FP16, loss scale1无法顺利收敛
换言之,如果grad中存在最大值在乘上loss scale后出现上溢,就必须降低loss scale,而过低的loss scale则会造成下溢从而破坏模型。所以现在大多框架的混合精度模块都有对loss scale的动态控制功能。即初始化一个交大的loss scale值(32768),检测到过大的grad会自动降低loss scale (/2),如果一定步数发现没有发生上溢就吧loss scale增大(*2)。
早期pytorch的混合精度训练依赖apex库,不过在1.6更新后,pytorch自带了混合精度模块torch.cuda.amp,具体使用可以参考官网介绍[2]。
Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
scaler.scale(loss).backward()
# scaler.step() first unscales gradients of the optimizer's params.
# If gradients don't contain infs/NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
不过本文就不再赘述怎么使用这些库了,主要来谈谈我们在混合精度训练的时候遇到的各种问题,具体则是1)forward期间nan,2)训练过程中loss scale一泻千里最终导致训练崩溃,以及如何debug。
前向loss=nan,loss scale一路下降最终退化为0,又或是放弃FP16重回FP32(更慢的训练速度,更多的显存占用和OOM风险)
Forward期间出现nan
一般是前向过程中某些步骤蕴含求和求平均的操作导致了上溢,这种问题比较容易debug,在程序中设置断点,凭借断点(二分法)或者经验来判断出问题的区域。虽然pytorch默认采用了混合精度的训练机制,会保留一些中间层计算为FP32(BN,softmax),即模型会自动在这些层计算时切换为FP32来防止上溢。具体哪些操作是FP16,哪些是FP32可以参考apex当年的划分[3]。但是任然有很多操作是落网之鱼。
这里举2个例子,首先是linear attention中的归一化中包含了多个求和einsum,sum的操作,存在严重的上溢风险。
v_length = values.size(1)
values = values / v_length # prevent fp16 overflow
KV = torch.einsum("nshd,nshv->nhdv", K, values) # (S,D)' @ S,V
Z = 1 / (torch.einsum("nlhd,nhd->nlh", Q, K.sum(dim=1)) + self.eps) # 出现NAN
queried_values = torch.einsum("nlhd,nhdv,nlh->nlhv", Q, KV, Z) * v_length
另一个是3D任务中常常出现的相机参数计算。由于相机参数通常数值会很大(1000以上),简单的内外参操作matmul也会造成上溢。
proj = torch.matmul(intrinsic, extrinsic) # intrinsic内参矩阵和extrinsic外参矩阵相乘出现NAN
解决方案很简单,我们在这些部分的前向固定为FP32即可
with torch.cuda.amp.autocast(enable=False): # 禁止amp自动切换精度
# 之前的输出大概率是fp16,调整回fp32
Q = Q.to(torch.float32)
K = K.to(torch.float32)
values = values.to(torch.float32)
v_length = values.size(1)
values = values / v_length # prevent fp16 overflow
KV = torch.einsum("nshd,nshv->nhdv", K, values) # (S,D)' @ S,V
Z = 1 / (torch.einsum("nlhd,nhd->nlh", Q, K.sum(dim=1)) + self.eps) # 没有上溢问题
queried_values = torch.einsum("nlhd,nhdv,nlh->nlhv", Q, KV, Z) * v_length
3D相机矩阵操作也很简单
with torch.cuda.amp.autocast(enable=False): # 禁止amp自动切换精度
proj = torch.matmul(intrinsic.to(torch.float32), extrinsic.to(torch.float32))
由于只有极少的计算被我们切换到了FP32,我们依旧能够享受到大量FP16带来的加速福利。
loss scale一泻千里
相比起训练一开始就出现nan问题,训练到中途才发现loss scale突然在某个节点疯狂下降,最终导致训练崩溃才是真正混合精度训练的拦路虎。
睡了一晚上,第二天发现白训
首先我们在训练过程中要时刻监控loss scale,不要早就挂掉了才后知后觉
scaler = torch.cuda.amp.GradScaler()
current_loss_scale = scaler.get_scale()
if step % log_iter == 0:
print('scale:', current_loss_scale)
loss*loss scale的操作是在scaler.scale(loss).backward()完成的,而unsacle是在scaler.step(optimizer)中完成的。所以我们只要在这2步中间观察每层的梯度数值范围,即可确认是哪里溢出了。
区分params为不同group,以方便定位对应的layer_name
param_groups = []
for n, p in model.named_parameters():
if p.requires_grad:
param_groups.append({'params': [p], 'lr': opt_args['lr'], 'weight_decay': opt_args['weight_decay'], 'layer_name': n})
optimizer = torch.optim.AdamW(param_groups, lr=opt_args['lr'], weight_decay=opt_args['weight_decay'])
...
Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
scaler.scale(loss).backward()
# 检查梯度
with torch.no_grad():
for group in optimizer.param_groups:
for param in group["params"]:
if param.grad is None:
continue
if param.grad.is_sparse:
if param.grad.dtype is torch.float16:
param.grad = param.grad.coalesce()
to_unscale = param.grad._values()
else:
to_unscale = param.grad
v = to_unscale.clone().abs().max()
if torch.isinf(v) or torch.isnan(v):
print('INF in', group['layer_name'], 'of step', global_step, '!!!')
# scaler.step() first unscales gradients of the optimizer's params.
# If gradients don't contain infs/NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
使用这种方式可以很快定位到频繁上溢的层
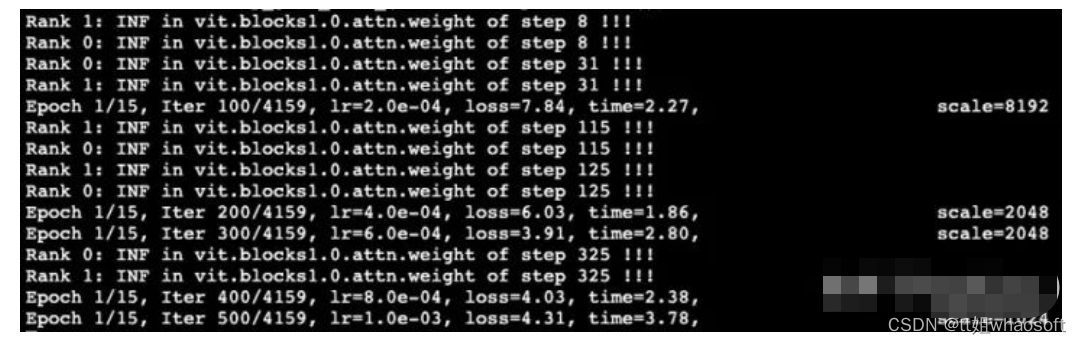
block1.0.attn频繁出现梯度上溢
上述例子中,笔者finetune了一个Vision Transformer (VIT),其block1.0.attn频繁出现梯度上溢导致了最终的崩溃。我查看了其未上溢的最大grad为8~10,确实非常不稳定。因此笔者将这层固定为FP32从而训练可以稳定。方法同上,使用torch.cuda.amp.autocast(enable=False)和to(torch.float32)。由经验而言,很多grad上溢出现在最初输入的几层,也许是梯度反传造成的梯度累计爆炸问题造成的?也许和post norm和pre norm的研究有关。大多这些不稳定的模型都是使用pre norm,而post norm可能训练会更加稳定,但是前期的层反而会出现一些梯度消失的问题。
参考whaosoft aiot http://143ai.com
- ^https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
- ^https://pytorch.org/docs/stable/notes/amp_examples.html
- ^https://github.com/NVIDIA/apex/blob/082f999a6e18a3d02306e27482cc7486dab71a50/apex/amp/lists/functional_overrides.py
Original: https://blog.csdn.net/qq_29788741/article/details/127031596
Author: tt姐whaosoft
Title: Pytorch混合精度训练
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/708575/
转载文章受原作者版权保护。转载请注明原作者出处!