

transformer模型起初被提出于2017年google的《Attention ls All you Need》中。论文路径:[pdf]
transformer完全抛弃了CNN,RNN模型结构。起初主要应用在自然语言处理中,后面逐渐应用到了计算机视觉中。
仅仅通过注意力机制(self-attention)和前向神经网络(Feed Forward Neural Network),不需要使用序列对齐的循环架构就实现了较好的performance 。
(1)摒弃了RNN的网络结构模式,其能够很好的并行运算;
(2)其注意力机制能够帮助当前词获取较好的上下文信息。
本文主要用于弥补Transformer在时间序列数据预测案例较为缺失,通过小样本数字预测,给后续Transformer研究人员提供时序数据研究思路。
算法主要实现,数数功能,例如给出序列1,2,3,4 预期希望机器应答5,6,7。
数据样本 (shu.csv)


训练代码
#!/usr/bin/env python3
encoding: utf-8
"""
@Time : 2021/7/7 20:03
@Author : Xie Cheng
@File : train_transformer.py
@Software: PyCharm
@desc: transformer训练
"""
import sys
sys.path.append("../")
import torch
from torch import nn
from torch.utils.data import DataLoader
import numpy as np
from torch.autograd import Variable
from myfunction import MyDataset
from Transformer.transformer import TransformerTS
device GPU or CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print('You are using: ' + str(device))
batch size
batch_size_train = 7
out_put_size = 3
data_bound = batch_size_train - out_put_size
total epoch(总共训练多少轮)
total_epoch = 1000
1. 导入训练数据
filename = '../data/shu.csv'
dataset_train = MyDataset(filename)
train_loader = DataLoader(dataset_train, batch_size=batch_size_train, shuffle=False, drop_last=True)
2. 构建模型,优化器
tf = TransformerTS(input_dim=1,
dec_seq_len=batch_size_train-out_put_size,
out_seq_len=out_put_size,
d_model=32, # 编码器/解码器输入中预期特性的数量
nhead=8,
num_encoder_layers=3,
num_decoder_layers=3,
dim_feedforward=32,
dropout=0.1,
activation='relu',
custom_encoder=None,
custom_decoder=None).to(device)
optimizer = torch.optim.Adam(tf.parameters(), lr=0.001)
#scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2000, gamma=0.1) # Learning Rate Decay
criterion = nn.MSELoss() # mean square error
train_loss_list = [] # 每次epoch的loss保存起来
total_loss = 31433357277 # 网络训练过程中最大的loss
3. 模型训练
def train_transformer(epoch):
global total_loss
mode = True
tf.train(mode=mode) # 模型设置为训练模式
loss_epoch = 0 # 一次epoch的loss总和
for idx, (sin_input, _) in enumerate(train_loader):
sin_input_np = sin_input.numpy()[:data_bound] # 1D
cos_output = sin_input[data_bound:]
sin_input_torch = Variable(torch.from_numpy(sin_input_np[np.newaxis, :, np.newaxis])) # 3D
prediction = tf(sin_input_torch.to(device)) # torch.Size([batch size])
loss = criterion(prediction, cos_output.to(device)) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # back propagation, compute gradients
optimizer.step() # apply gradients
#scheduler.step()
#print(scheduler.get_lr())
loss_epoch += loss.item() # 将每个batch的loss累加,直到所有数据都计算完毕
if idx == len(train_loader) - 1:
print('Train Epoch:{}\tLoss:{:.9f}'.format(epoch, loss_epoch))
train_loss_list.append(loss_epoch)
if loss_epoch < total_loss:
total_loss = loss_epoch
torch.save(tf, '..\\model\\tf_model2.pkl') # save model
if __name__ == '__main__':
# 模型训练
print("Start Training...")
for i in range(total_epoch): # 模型训练1000轮
train_transformer(i)
print("Stop Training!")
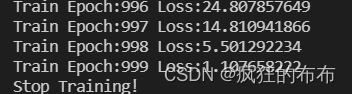
训练后1000轮,LOSS函数选用MSE 训练误差从1000多降低到大概1左右的误差率

预测代码
#!/usr/bin/env python3
encoding: utf-8
"""
@Time : 2021/7/7 20:45
@Author : Xie Cheng
@File : test_transformer.py
@Software: PyCharm
@desc: transformer 测试
"""
import sys
sys.path.append("../")
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from myfunction import MyDataset
device GPU or CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print('You are using: ' + str(device))
batch size
batch_size_test = 7
out_put_size = 3
data_bound = batch_size_test - out_put_size
导入数据
filename = '../data/shu.csv'
dataset_test = MyDataset(filename)
test_loader = DataLoader(dataset_test, batch_size=batch_size_test, shuffle=False, drop_last=True)
criterion = nn.MSELoss() # mean square error
rnn 测试
def test_rnn():
net_test = torch.load('..\\model\\tf_model2.pkl') # load model
test_loss = 0
net_test.eval()
with torch.no_grad():
for idx, (sin_input, _) in enumerate(test_loader):
sin_input_np = sin_input.numpy()[:data_bound] # 1D
cos_output = sin_input[data_bound:]
sin_input_torch = torch.from_numpy(sin_input_np[np.newaxis, :, np.newaxis]) # 3D
prediction = net_test(sin_input_torch.to(device)) # torch.Size([batch size])
print("-------------------------------------------------")
print("输入:", sin_input_np)
print("预期输出:", cos_output)
print("实际输出:", prediction)
print("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~")
if idx == 0:
predict_value = prediction
real_value = cos_output
else:
predict_value = torch.cat([predict_value, prediction], dim=0)
real_value = torch.cat([real_value, cos_output], dim=0)
loss = criterion(prediction, cos_output.to(device))
test_loss += loss.item()
print('Test set: Avg. loss: {:.9f}'.format(test_loss))
return predict_value, real_value
if __name__ == '__main__':
# 模型测试
print("testing...")
p_v, r_v = test_rnn()
# 对比图
plt.plot(p_v.cpu(), c='green')
plt.plot(r_v.cpu(), c='orange', linestyle='--')
plt.show()
print("stop testing!")

从实际输出看,结果接近预期输出。
预测与实际输出对比曲线:

宗上所述,Transformer完成了简单的数数功能。
训练精度可以随训练次数,和学习率的修改,进一步提高,这里笔者不一一尝试
完整代码 github:https://github.com/fengjun321/Transformer_count.git
Original: https://blog.csdn.net/u013177138/article/details/124695450
Author: 疯狂的布布
Title: Transformer多头注意力机制实现数字预测(pytorch)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/708567/
转载文章受原作者版权保护。转载请注明原作者出处!