

文章目录
*
– Log
* 一、Dataset
*
– 1. 在控制台进行操作
–
+ ①获取图片的基本信息
+ ②获取文件的基本信息
– 2. 编写一个继承 Dataset 的类加载数据
–
+ ①定义 MyData类
+ ②创建类的实例并调用
* 二、DataLoader
Log
2022.08.31八月最后一日,继续学习
2022.10.03九月事情还算可以吧,十月归来学习。后面应该还会回来完善
一、Dataset
- D a t a s e t \rm Dataset Dataset 类提供一种方式去获取数据及其标签
- 主要有两个目的:
- 获取每一个数据及其标签
- 获取数据的总量大小
1. 在控制台进行操作
- H y m e n o p t e r a \rm Hymenoptera Hymenoptera (膜翅目昆虫)数据集下载
- 这是一个蚂蚁蜜蜂二分类的数据集,通常数据集有以下三种组织形式(上面的数据集属于第一种):
- 不同的类别以文件夹的形式存在,文件夹中是该类别的图片
- 图片与标签分别存储,图片在一个文件夹下,
label信息在另一个文件夹下 label直接写在图片名称里
①获取图片的基本信息
- 在P y c h a r m \rm Pycharm Pycharm 中,点击下方的P y t h o n C o n s o l e \rm Python Console PythonConsole 进入控制台进行操作(通过控制台可以看到变量的详细信息)
- 首先加载图片,逐行输入下方代码:
from PIL import Image
img_path = "./dataset/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
- 此时我们就可以在右侧看到相关变量的信息:


- 点击
img变量,可以查看图片的详细信息。通过控制台执行程序能够直观地获取后续操作所需的数据:
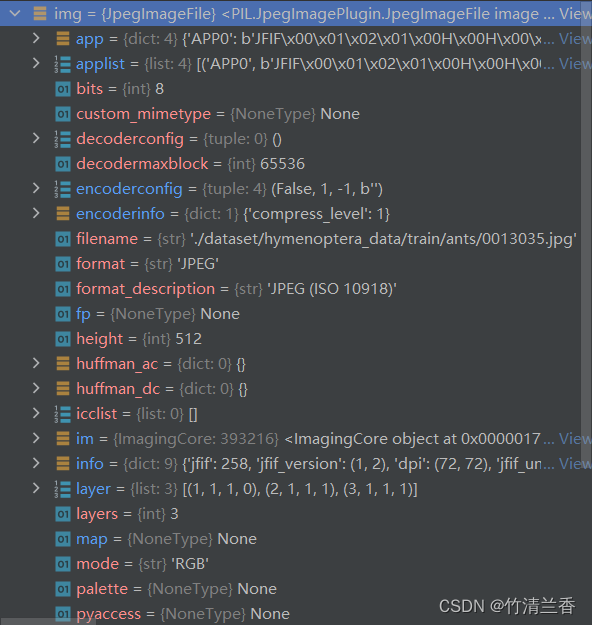
- 最后可以通过
img.show()打开图片查看:
②获取文件的基本信息
- 同样还是在控制台逐行输入以下代码:
dir_path = "dataset/hymenoptera_data/train/ants"
import os
img_path_list = os.listdir(dir_path)
img_path_list[0]
- 我们就可以获取到文件夹下的文件名称,由于是使用控制台,我们还可以在右侧查看列表的详细信息:
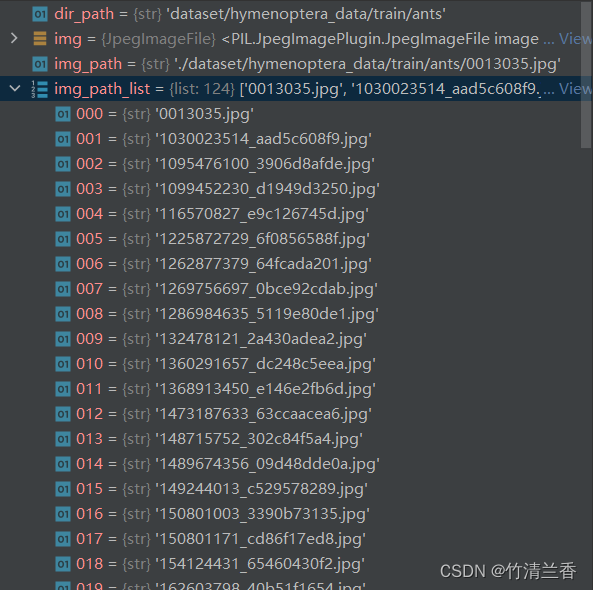
- 因此在控制台操作是有很大的优点的,我们可以在控制台逐行执行已经编写好的文件中的语句,通过查看右侧变量的值来判断程序写的是否有问题
2. 编写一个继承 Dataset 的类加载数据
- 下面的代码也可以在控制台运行(可以多行复制粘贴)来检验程序是否有误
①定义 MyData类
- 导入所需头文件:
from torch.utils.data import Dataset
from PIL import Image
import os
- 定义
MyData类: __init__:初始化函数__getitem__:返回指定下标的图片和标签__len__:返回数据集的大小
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
- 其中
os.path.join()可以实现多个路径的合并且不出错
②创建类的实例并调用
- 创建
MyData类的实例:
if __name__ == "__main__":
root_dir = "../dataset/hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
- 调用类中写好的函数:
img, label = ants_dataset.__getitem__(3)
print(ants_dataset.__len__(), label)
img.show()
- 同时我们也可以通过下面这种方式用已有的数据集来创造数据集:
train_dataset = ants_dataset + bees_dataset
二、DataLoader
- D a t a L o a d e r \rm DataLoader DataLoader 类是为后面的网络提供不同的数据形式
- D a t a L o a d e r \rm DataLoader DataLoader 会根据
batch_size的值对数据进行打包 - 导入所需的包
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
- 加载数据:
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
- 测试:
img, target = test_data[0]
print(img.shape)
print(target)
- 进行日志记录,开始训练:
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
Original: https://blog.csdn.net/weixin_53312629/article/details/126616169
Author: 竹清兰香
Title: PyTorch(二)Dataset 与 DataLoader
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/708455/
转载文章受原作者版权保护。转载请注明原作者出处!