

专栏目录:pytorch(图像分割UNet)快速入门与实战——零、前言
pytorch快速入门与实战——一、知识准备(要素简介)
pytorch快速入门与实战——二、深度学习经典网络发展
pytorch快速入门与实战——三、Unet实现
pytorch快速入门与实战——四、网络训练与测试
续上文pytorch快速入门与实战——二、深度学习经典网络发展的8.4章节
Unet实现
1 前期准备
1.1 torch安装
pytorch安装自行解决
1.2 数据集准备
我的是自己模拟的数据,所有数据一共是1600对(inputs,labels),训练集与测试集是9:1抽取的。
我的输入大小为120240,label大小为256256.
1.3 网络结构骨架
backbone是Unet,根据自己需求再变。不是改自己网络,而是自己加个卷积适应自己的输入输出。
先down一个基础的Unet图。基于此来修改。


; 1.4 数据分析、完善网络
【具体的size和channel没所谓的,都是可以直接设置的,怎么设置在实现里面说,这里只说流程】
图中input的size是572x572x1,而我的size是120x240x1,我选择在Unet之前加一个卷积层以让我的输入成为方形120x120x1,为了后续计算方便,通过padding(直接padding或者通过卷积都可以)变成128x128x1。接下来就是常规Unet操作,所以我的网络结构图为:

可以看到整个变化过程: 具体如何变在实现中说明(一张破图一下午,骂骂咧咧ing)
120x240x1--卷积-->120x120x1--卷积-->128x128x1--卷积-->128x128x32
--池化-->64x64x32--卷积-->64x64x64
--池化-->32x32x64--卷积-->32x32x128
--池化-->16x16x128--卷积-->16x16x256
--池化-->8x8x256--卷积-->8x8x512--上采样-->16x16x256
--通道拼接-->16x16x512--反卷积-->16x16x256--上采样-->32x32x128
--通道拼接-->32x32x256--反卷积-->32x32x128--上采样-->64x64x64
--通道拼接-->64x64x128--反卷积-->64x64x64--上采样-->128x128x32
--通道拼接-->128x128x64--反卷积-->128x128x32--上采样-->256x256x16
(注意我左边是128开始的,所以没法拼接了,网络结构并不是严格对称的)
--1x1卷积核代替全连接-->256x256x1
2.网络实现
2.1 相关知识
- 首先我们要知道卷积的计算公式:
O = (I − K + 2P )/S+1
O(output)是输出图像、I(input)为原始图像、K(kernel)为卷积核尺寸、P为padding、S(stride)是步长
- 以及反卷积的计算公式:
output = (input-1)stride+output_padding -2padding+kernel_size
O = (I-1)S + OP – 2P + K
O(output)是输出图像、I(input)为原始图像、K(kernel)为卷积核尺寸、P为padding、S(stride)是步长,OP为output_padding
- 通道channel
说一下我的理解:
现实意义上是特征(我用分类来举例子:比如西瓜的根蒂,颜色,花纹等)
在图片中,色彩是一种特征,但特征不只是色彩。
比如我的灰度图,那channel就是1,如果是其他彩色图(RGB,BGR,CMY)的channel都是3
那可能就要问了,那图中channel为64,难道是64种色彩?
参照上面那句话”特征不只是色彩”,其他特征,我也不懂,猜测是分布什么的吧。
2.2 代码实现:
emmmm还是由浅入深地讲解吧:网络的整体代码放在文章最后。
首先导入torch包:
import torch
import torch.nn as nn
然后设计我的网络AdUNet,编写成类,该类继承nn.module。
主要重写两个方法: 初始化__init__和 参数回传forward
在此之前,为了提高代码复用性,将 重复出现的双层卷积设计成一个函数,方便代码复用:

def double_conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
OK,开始。
2.2.1 初始化方法__init__():
- 输入适配层
首先自主设计让输入适应网络的卷积层adnet放入网络AdUNet的类里, 将输入1x120x240卷积为方形1x120x120,利用pytorch自带的卷积核方法 Conv2d来实现:

设置输入的通道in_channels和输出的通道out_channels,选择2×1的卷积核,padding设为0,步长设置为(2,1)即行方向上步长为2,列方向上步长为1。这样设置步长才能让行方向的size缩小一倍。 size调整为120×120
然后再绑定一个BN层和ReLu层,作用与原因参照上一篇文章。
然后再用一个padding=5的3×3卷积核将size 从120×120调整为128×128
self.adnet = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(2, 1), padding=0, stride=(2, 1)),
nn.BatchNorm2d(1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=5, stride=1),
nn.BatchNorm2d(1),
nn.ReLU(inplace=True)
)
- 4个下采样时的卷积层+一个底层的卷积层

self.dconv_down0 = double_conv(1, 32)
self.dconv_down1 = double_conv(32, 64)
self.dconv_down2 = double_conv(64, 128)
self.dconv_down3 = double_conv(128, 256)
self.dconv_down4 = double_conv(256, 512)
- 最大池化层

self.maxpool = nn.MaxPool2d(2)
- 4个上采样时的卷积层


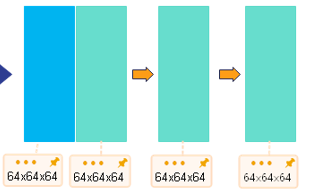

self.dconv_up3 = double_conv(256 + 256, 256)
self.dconv_up2 = double_conv(128 + 128, 128)
self.dconv_up1 = double_conv(64 + 64, 64)
self.dconv_up0 = double_conv(64, 32)
- 5个上采样

self.upsample4 = nn.ConvTranspose2d(512, 256, 3, stride=2, padding=1, output_padding=1)
self.upsample3 = nn.ConvTranspose2d(256, 128, 3, stride=2, padding=1, output_padding=1)
self.upsample2 = nn.ConvTranspose2d(128, 64, 3, stride=2, padding=1, output_padding=1)
self.upsample1 = nn.ConvTranspose2d(64, 32, 3, stride=2, padding=1, output_padding=1)
self.upsample0 = nn.ConvTranspose2d(32, 16, 3, stride=2, padding=1, output_padding=1)
- 代替全连接层的1×1卷积层

self.conv_last = nn.Conv2d(16, 1, 1)
2.2.2 参数回传方法forward():
按照上图的网络结构将他们拼接起来!就OK了!
哦对,别忘了concat。
为什么不把下采样和上采样的那个重复模块写在一起呢?就是因为我不想传参,因为前面下采样的时候要在pool池之前保留值留给上采样的时候concat,所以就单独写了。concat操作也简单,看看代码就懂了,没什么难点。
def forward(self, x):
x = self.adnet(x)
conv0 = self.dconv_down0(x)
x = self.maxpool(conv0)
conv1 = self.dconv_down1(x)
x = self.maxpool(conv1)
conv2 = self.dconv_down2(x)
x = self.maxpool(conv2)
conv3 = self.dconv_down3(x)
x = self.maxpool(conv3)
x = self.dconv_down4(x)
x = self.upsample4(x)
x = torch.cat([x, conv3], dim=1)
x = self.dconv_up3(x)
x = self.upsample3(x)
x = torch.cat([x, conv2], dim=1)
x = self.dconv_up2(x)
x = self.upsample2(x)
x = torch.cat([x, conv1], dim=1)
x = self.dconv_up1(x)
x = self.upsample1(x)
x = torch.cat([x, conv0], dim=1)
x = self.dconv_up0(x)
x = self.upsample0(x)
out = self.conv_last(x)
return out
2.2.3 语义分割实现流程
很遗憾地说,网络的结构虽然实现了,但是距离我们的目标还有一些路,但是还好,这个网络是确确实实可以用的,只要加载数据训练就可以得出结果,甚至可以随机生成一些矩阵当做图像来进行训练。
这里简单说一下流程,预感细节不少,详细实现下篇再说:pytorch快速入门与实战——四、网络训练与测试
训练:
根据batch size大小,将数据集中的训练样本和标签读入卷积神经网络。根据实际需要,应先对训练图片及标签进行预处理,如裁剪、数据增强等。这有利于深层网络的的训练,加速收敛过程,同时也避免过拟合问题并增强了模型的泛化能力。
验证:
训练一个epoch结束后,将数据集中的验证样本和标签读入卷积神经网络,并载入训练权重。根据编写好的语义分割指标进行验证,得到当前训练过程中的指标分数,保存对应权重。常用一次训练一次验证的方法更好的监督模型表现。
测试:
所有训练结束后,将数据集中的测试样本和标签读入卷积神经网络,并将保存的最好权重值载入模型,进行测试。 测试结果分为两种,一种是根据常用指标分数衡量网络性能,另一种是将网络的预测结果以 图片的形式保存下来,直观感受分割的精确程度。
2.2.4 整合!(网络完整代码)
import torch
import torch.nn as nn
def double_conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class AdUNet(nn.Module):
def __init__(self):
super().__init__()
self.adnet = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(2, 1), padding=0, stride=(2, 1)),
nn.BatchNorm2d(1),
nn.ReLU(inplace=True),
nn.Conv2d(1, 1, kernel_size=3, padding=5, stride=1),
nn.BatchNorm2d(1),
nn.ReLU(inplace=True)
)
self.dconv_down0 = double_conv(1, 32)
self.dconv_down1 = double_conv(32, 64)
self.dconv_down2 = double_conv(64, 128)
self.dconv_down3 = double_conv(128, 256)
self.dconv_down4 = double_conv(256, 512)
self.maxpool = nn.MaxPool2d(2)
self.upsample4 = nn.ConvTranspose2d(512, 256, 3, stride=2, padding=1, output_padding=1)
self.upsample3 = nn.ConvTranspose2d(256, 128, 3, stride=2, padding=1, output_padding=1)
self.upsample2 = nn.ConvTranspose2d(128, 64, 3, stride=2, padding=1, output_padding=1)
self.upsample1 = nn.ConvTranspose2d(64, 32, 3, stride=2, padding=1, output_padding=1)
self.upsample0 = nn.ConvTranspose2d(32, 16, 3, stride=2, padding=1, output_padding=1)
self.dconv_up3 = double_conv(256 + 256, 256)
self.dconv_up2 = double_conv(128 + 128, 128)
self.dconv_up1 = double_conv(64 + 64, 64)
self.dconv_up0 = double_conv(64, 32)
self.conv_last = nn.Conv2d(16, 1, 1)
def forward(self, x):
x = self.adnet(x)
conv0 = self.dconv_down0(x)
x = self.maxpool(conv0)
conv1 = self.dconv_down1(x)
x = self.maxpool(conv1)
conv2 = self.dconv_down2(x)
x = self.maxpool(conv2)
conv3 = self.dconv_down3(x)
x = self.maxpool(conv3)
x = self.dconv_down4(x)
x = self.upsample4(x)
x = torch.cat([x, conv3], dim=1)
x = self.dconv_up3(x)
x = self.upsample3(x)
x = torch.cat([x, conv2], dim=1)
x = self.dconv_up2(x)
x = self.upsample2(x)
x = torch.cat([x, conv1], dim=1)
x = self.dconv_up1(x)
x = self.upsample1(x)
x = torch.cat([x, conv0], dim=1)
x = self.dconv_up0(x)
x = self.upsample0(x)
out = self.conv_last(x)
return out
Original: https://blog.csdn.net/weixin_43938876/article/details/123406484
Author: 无衣°
Title: pytorch快速入门与实战——三、Unet实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/707192/
转载文章受原作者版权保护。转载请注明原作者出处!