

本文以CWRU轴承故障的振动信号数据库作为模型的训练集和测试集
并根据现有论文的思路和模型框架,用pytorch复现了论文的模型结构和性能,在二分类问题中准确率高达100%
本文在理论方面不再过多赘述,详细可看博主之前的博客或观看论文原文
数据连接: https://csegroups.case.edu/bearingdatacenter/pages/download-data-file
论文链接: https://www.sci-hub.ren/10.1109/tie.2017.2774777
代码链接: https://github.com/XD-onmyway/cnn_for_fault_diagnosis
博客链接: https://blog.csdn.net/weixin_42036144/article/details/110780890
思路讲解:
原始数据是连续的一维时序数据,文章为了利用二维CNN的特征提取和降噪能力,将一维数据堆叠成二维数据
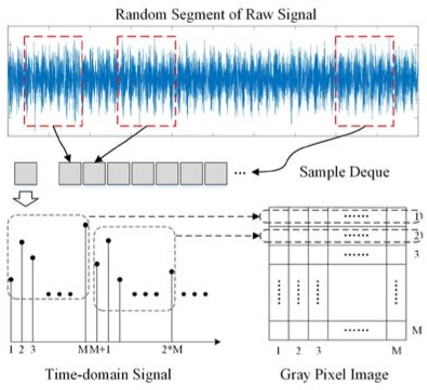

数据处理好过后,给数据打上标签,并转出成文件,方便模型读取
用pytorch构建模型,读取数据,训练模型,最后测试
代码讲解:
generate.py
normal
normal_0 = io.loadmat("./data/normal/normal_0")["X097_DE_time"].tolist()
normal_1 = io.loadmat("./data/normal/normal_1")["X098_DE_time"].tolist()
normal_2 = io.loadmat("./data/normal/normal_2")["X099_DE_time"].tolist()
normal_3 = io.loadmat("./data/normal/normal_3")["X100_DE_time"].tolist()
normal = [normal_0, normal_1, normal_2, normal_3]
all_data
all_data = [
normal,
ball_18,
ball_36,
ball_54,
inner_18,
inner_36,
inner_54,
outer_18,
outer_36,
outer_54,
]
加载mat文件中特定的表,并转换成一维数组,存入数据库,此处用二分类为例
normal数据标签为0,其余数据标签均为1,打上标签
二类
if data_type == 0:
the_type = 0
else:
the_type = 1
每份数据都是64×64的图片,需要用到4096个一维数据点
load_data = data[load_type]
max_start = len(load_data) - 4096
starts = []
for i in range(500):
# 随机一个start,不在starts里,就加入
while True:
start = random.randint(0, max_start)
if start not in starts:
starts.append(start)
break
# 将4096个数据点转化成64×64的二维图
temp = load_data[start : start + 4096]
temp = np.array(temp)
train_pics.append(temp.reshape(64, 64))
train_labels.append(the_type)
生成测试集:
用max_start存储最大起始取值点,starts保存用过的起始点,避免数据重复
获取一个起始点,从起始点往后取4096个数据点,把数据转化成64×64的二维图片
存入图片,存入标签
for i in range(100):
while True:
start = random.randint(0, max_start)
if start not in starts:
starts.append(start)
break
temp = load_data[start : start + 4096]
temp = np.array(temp)
test_pics.append(temp.reshape(64, 64))
test_labels.append(the_type)
测试集生成原理类似
109cnn.py
用GPU跑代码的时候需要加上下面一行,并且在读取模型和数据的时候加上.cuda(),本文以CPU为例
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
数字2代表,使用编号为2的GPU
根据需求构造模型,设置卷积层,池化层,激活函数和全连接层
pytorch具体使用可到官网学习:https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 5, padding=2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.conv4 = nn.Conv2d(128, 256, 3, padding=1)
self.pool = nn.MaxPool2d(2)
self.fc1 = nn.Linear(4 * 4 * 256, 2560)
self.fc2 = nn.Linear(2560, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.pool(F.relu(self.conv4(x)))
x = x.view(-1, 4 * 4 * 256)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
读取模型和数据,设置损失函数和优化方法
第一次跑的时候,需要把net.load_stat_dict()注释掉,因为此时没有cnn_net.pth文件
PATH = "cnn_net.pth"
net = Net()
net.load_state_dict(torch.load(PATH, map_location="cpu"))
net = Net().cuda()
net.load_state_dict(torch.load(PATH))
print("load success")
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
train_pics_dict = np.load("train_pics.npz")
train_labels_dict = np.load("train_labels.npz")
test_pics_dict = np.load("test_pics.npz")
test_labels_dict = np.load("test_labels.npz")
转化成list
train_pics = []
train_labels = []
test_pics = []
test_labels = []
for i in train_pics_dict.files:
train_pics.append(train_pics_dict[i])
train_labels.append(int(train_labels_dict[i]))
for i in test_pics_dict.files:
test_pics.append(test_pics_dict[i])
test_labels.append(int(test_labels_dict[i]))
自定义dataset,制作数据库必不可少的一步
init:初始化数据集
getitem:返回编号index的数据
len:返回数据集总长度
class MyData(Dataset):
def __init__(self, pics, labels):
self.pics = pics
self.labels = labels
# print(len(self.pics.files))
# print(len(self.labels.files))
def __getitem__(self, index):
# print(index)
# print(len(self.pics))
assert index < len(self.pics)
return torch.Tensor([self.pics[index]]), self.labels[index]
def __len__(self):
return len(self.pics)
用loader装载数据集
trainset = MyData(train_pics, train_labels)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=4, shuffle=True, num_workers=2
)
testset = MyData(test_pics, test_labels)
testloader = torch.utils.data.DataLoader(
testset, batch_size=4, shuffle=True, num_workers=2
)
传入数据,得到输出,根据公式计算损失值并输出,模型根据梯度和策略学习,保存模型参数到文件
running_loss = 0
for i, data in enumerate(trainloader):
inputs, labels = data
# inputs = inputs.cuda()
# labels = labels.cuda()
outputs = net(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss
if i % 2000 == 1999:
print(
"epoch:",
epoch,
"[",
i - 1999,
":",
i,
"] loss:",
running_loss.item() / 2000,
)
running_loss = 0
PATH = "cnn_net.pth"
torch.save(net.state_dict(), PATH)
print("save success")
测试的时候,将模型输出和实际标签逐个比对,记录正确的总数,最后输出测试结果
test
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in testloader:
# inputs = inputs.cuda()
# labels = labels.cuda()
outputs = net(inputs)
_, predicts = torch.max(outputs, 1)
total += 4
correct += (predicts == labels).sum().item()
print(correct / total * 100)
多次训练模型,可以修改训练代码里的epoch,每次跑代码多跑几次数据
# train
for epoch in range(10):
经过反复训练,模型训练完成,二分类问题下准确率达到100%
load success
100.0
完整代码
generate.py
import os
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from PIL import Image
from torch.utils.data import Dataset
import scipy.io as io
import random
from datetime import datetime
random.seed(datetime.now())
ball_18
ball_18_0 = io.loadmat("./data/ball_18/ball_18_0")["X118_DE_time"].tolist()
ball_18_1 = io.loadmat("./data/ball_18/ball_18_1")["X119_DE_time"].tolist()
ball_18_2 = io.loadmat("./data/ball_18/ball_18_2")["X120_DE_time"].tolist()
ball_18_3 = io.loadmat("./data/ball_18/ball_18_3")["X121_DE_time"].tolist()
ball_18 = [ball_18_0, ball_18_1, ball_18_2, ball_18_3]
ball_36
ball_36_0 = io.loadmat("./data/ball_36/ball_36_0")["X185_DE_time"].tolist()
ball_36_1 = io.loadmat("./data/ball_36/ball_36_1")["X186_DE_time"].tolist()
ball_36_2 = io.loadmat("./data/ball_36/ball_36_2")["X187_DE_time"].tolist()
ball_36_3 = io.loadmat("./data/ball_36/ball_36_3")["X188_DE_time"].tolist()
ball_36 = [ball_36_0, ball_36_1, ball_36_2, ball_36_3]
ball_54
ball_54_0 = io.loadmat("./data/ball_54/ball_54_0")["X222_DE_time"].tolist()
ball_54_1 = io.loadmat("./data/ball_54/ball_54_1")["X223_DE_time"].tolist()
ball_54_2 = io.loadmat("./data/ball_54/ball_54_2")["X224_DE_time"].tolist()
ball_54_3 = io.loadmat("./data/ball_54/ball_54_3")["X225_DE_time"].tolist()
ball_54 = [ball_54_0, ball_54_1, ball_54_2, ball_54_3]
inner_18
inner_18_0 = io.loadmat("./data/inner_18/inner_18_0")["X105_DE_time"].tolist()
inner_18_1 = io.loadmat("./data/inner_18/inner_18_1")["X106_DE_time"].tolist()
inner_18_2 = io.loadmat("./data/inner_18/inner_18_2")["X107_DE_time"].tolist()
inner_18_3 = io.loadmat("./data/inner_18/inner_18_3")["X108_DE_time"].tolist()
inner_18 = [inner_18_0, inner_18_1, inner_18_2, inner_18_3]
inner_36
inner_36_0 = io.loadmat("./data/inner_36/inner_36_0")["X169_DE_time"].tolist()
inner_36_1 = io.loadmat("./data/inner_36/inner_36_1")["X170_DE_time"].tolist()
inner_36_2 = io.loadmat("./data/inner_36/inner_36_2")["X171_DE_time"].tolist()
inner_36_3 = io.loadmat("./data/inner_36/inner_36_3")["X172_DE_time"].tolist()
inner_36 = [inner_36_0, inner_36_1, inner_36_2, inner_36_3]
inner_54
inner_54_0 = io.loadmat("./data/inner_54/inner_54_0")["X209_DE_time"].tolist()
inner_54_1 = io.loadmat("./data/inner_54/inner_54_1")["X210_DE_time"].tolist()
inner_54_2 = io.loadmat("./data/inner_54/inner_54_2")["X211_DE_time"].tolist()
inner_54_3 = io.loadmat("./data/inner_54/inner_54_3")["X212_DE_time"].tolist()
inner_54 = [inner_54_0, inner_54_1, inner_54_2, inner_54_3]
outer_18
outer_18_0 = io.loadmat("./data/outer_18/outer_18_0")["X130_DE_time"].tolist()
outer_18_1 = io.loadmat("./data/outer_18/outer_18_1")["X131_DE_time"].tolist()
outer_18_2 = io.loadmat("./data/outer_18/outer_18_2")["X132_DE_time"].tolist()
outer_18_3 = io.loadmat("./data/outer_18/outer_18_3")["X133_DE_time"].tolist()
outer_18 = [outer_18_0, outer_18_1, outer_18_2, outer_18_3]
outer_36
outer_36_0 = io.loadmat("./data/outer_36/outer_36_0")["X197_DE_time"].tolist()
outer_36_1 = io.loadmat("./data/outer_36/outer_36_1")["X198_DE_time"].tolist()
outer_36_2 = io.loadmat("./data/outer_36/outer_36_2")["X199_DE_time"].tolist()
outer_36_3 = io.loadmat("./data/outer_36/outer_36_3")["X200_DE_time"].tolist()
outer_36 = [outer_36_0, outer_36_1, outer_36_2, outer_36_3]
outer_54
outer_54_0 = io.loadmat("./data/outer_54/outer_54_0")["X234_DE_time"].tolist()
outer_54_1 = io.loadmat("./data/outer_54/outer_54_1")["X235_DE_time"].tolist()
outer_54_2 = io.loadmat("./data/outer_54/outer_54_2")["X236_DE_time"].tolist()
outer_54_3 = io.loadmat("./data/outer_54/outer_54_3")["X237_DE_time"].tolist()
outer_54 = [outer_54_0, outer_54_1, outer_54_2, outer_54_3]
normal
normal_0 = io.loadmat("./data/normal/normal_0")["X097_DE_time"].tolist()
normal_1 = io.loadmat("./data/normal/normal_1")["X098_DE_time"].tolist()
normal_2 = io.loadmat("./data/normal/normal_2")["X099_DE_time"].tolist()
normal_3 = io.loadmat("./data/normal/normal_3")["X100_DE_time"].tolist()
normal = [normal_0, normal_1, normal_2, normal_3]
all_data
all_data = [
normal,
ball_18,
ball_36,
ball_54,
inner_18,
inner_36,
inner_54,
outer_18,
outer_36,
outer_54,
]
print(len(all_data))
def main(argv=None):
classes = (
"normal",
"ball_18",
"ball_36",
"ball_54",
"inner_18",
"inner_36",
"inner_54",
"outer_18",
"outer_36",
"outer_54",
)
# classes = ("normal", "error")
train_pics = []
train_labels = []
test_pics = []
test_labels = []
for data_type in range(10):
# 二类
if data_type == 0:
the_type = 0
else:
the_type = 1
# 四类
# the_type = (data_type + 2) // 3
# 十类
the_type = data_type
data = all_data[data_type]
for load_type in range(4):
load_data = data[load_type]
max_start = len(load_data) - 4096
starts = []
for i in range(500):
# 随机一个start,不在starts里,就加入
while True:
start = random.randint(0, max_start)
if start not in starts:
starts.append(start)
break
# 将4096个数据点转化成64×64的二维图
temp = load_data[start : start + 4096]
temp = np.array(temp)
train_pics.append(temp.reshape(64, 64))
train_labels.append(the_type)
for i in range(100):
while True:
start = random.randint(0, max_start)
if start not in starts:
starts.append(start)
break
temp = load_data[start : start + 4096]
temp = np.array(temp)
test_pics.append(temp.reshape(64, 64))
test_labels.append(the_type)
print("train_pics", len(train_pics))
print("train_labels", len(train_labels))
print("test_pics", len(test_pics))
print("test_labels", len(test_labels))
np.savez("train_pics", *train_pics)
np.savez("train_labels", *train_labels)
np.savez("test_pics", *test_pics)
np.savez("test_labels", *test_labels)
print("save success")
if __name__ == "__main__":
sys.exit(main())
cnn.py
import os
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from PIL import Image
from torch.utils.data import Dataset
import scipy.io as io
import random
from datetime import datetime
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 5, padding=2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.conv4 = nn.Conv2d(128, 256, 3, padding=1)
self.pool = nn.MaxPool2d(2)
self.fc1 = nn.Linear(4 * 4 * 256, 2560)
self.fc2 = nn.Linear(2560, 2)
# self.fc2 = nn.Linear(2560, 4)
def forward(self, x):
# print(x.size())
x = self.pool(F.relu(self.conv1(x)))
# print(x.size())
x = self.pool(F.relu(self.conv2(x)))
# print(x.size())
x = self.pool(F.relu(self.conv3(x)))
# print(x.size())
x = self.pool(F.relu(self.conv4(x)))
# print(x.size())
x = x.view(-1, 4 * 4 * 256)
# print(x.size())
x = F.relu(self.fc1(x))
# print(x.size())
x = self.fc2(x)
# print(x.size())
return x
PATH = "cnn_net.pth"
net = Net()
net.load_state_dict(torch.load(PATH, map_location="cpu"))
net = Net().to(device)
net.load_state_dict(torch.load(PATH))
print("load success")
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
train_pics_dict = np.load("train_pics.npz")
train_labels_dict = np.load("train_labels.npz")
test_pics_dict = np.load("test_pics.npz")
test_labels_dict = np.load("test_labels.npz")
print(test_labels_dict["arr_" + str(3000)])
train_pics = []
train_labels = []
test_pics = []
test_labels = []
for i in train_pics_dict.files:
train_pics.append(train_pics_dict[i])
train_labels.append(int(train_labels_dict[i]))
for i in test_pics_dict.files:
test_pics.append(test_pics_dict[i])
test_labels.append(int(test_labels_dict[i]))
print(test_labels)
class MyData(Dataset):
def __init__(self, pics, labels):
self.pics = pics
self.labels = labels
# print(len(self.pics.files))
# print(len(self.labels.files))
def __getitem__(self, index):
# print(index)
# print(len(self.pics))
assert index < len(self.pics)
return torch.Tensor([self.pics[index]]), self.labels[index]
def __len__(self):
return len(self.pics)
def get_tensors(self):
return torch.Tensor([self.pics]), torch.Tensor(self.labels)
def main(argv=None):
# classes = (
# "normal",
# "ball_18",
# "ball_36",
# "ball_54",
# "inner_18",
# "inner_36",
# "inner_54",
# "outer_18",
# "outer_36",
# "outer_54",
# )
classes = ["normal", "error"]
# classes = ["normal", "ball", "inner", "outer"]
# 加载训练数据库
# trainset = MyData(train_pics, train_labels)
# trainloader = torch.utils.data.DataLoader(
# trainset, batch_size=4, shuffle=True, num_workers=2
# )
testset = MyData(test_pics, test_labels)
testloader = torch.utils.data.DataLoader(
testset, batch_size=4, shuffle=True, num_workers=2
)
# train
# for epoch in range(10):
# running_loss = 0
# for i, data in enumerate(trainloader):
# inputs, labels = data
# inputs = inputs.cuda()
# labels = labels.cuda()
# outputs = net(inputs)
# loss = criterion(outputs, labels)
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
# running_loss += loss
# if i % 2000 == 1999:
# print(
# "epoch:",
# epoch,
# "[",
# i - 1999,
# ":",
# i,
# "] loss:",
# running_loss.item() / 2000,
# )
# running_loss = 0
# PATH = "cnn_net.pth"
# torch.save(net.state_dict(), PATH)
# print("save success")
# test
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in testloader:
# inputs = inputs.cuda()
# labels = labels.cuda()
outputs = net(inputs)
_, predicts = torch.max(outputs, 1)
total += 4
correct += (predicts == labels).sum().item()
print(correct / total * 100)
if __name__ == "__main__":
sys.exit(main())
Original: https://blog.csdn.net/weixin_42036144/article/details/116720550
Author: XD_onmyway
Title: 一种基于卷积神经网络的数据驱动故障预测方法(含代码)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/707090/
转载文章受原作者版权保护。转载请注明原作者出处!