

主要目标
有的时候想看一下设置了优化器和学习率之后是否按照我设置的样子去进行更新,所以想查看一下网络参数中的及各相关变量:
- 更新前的值
- 优化器中的学习率
- 计算出loss之后的梯度值
- 更新后的值
有了这几个值,可能在之后我调试网络结构的过程当中能确保代码没有问题,或者检查中间的结果
实验代码1:查看梯度以及参数更新的问题
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torchsummary import summary
import os
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
class TrainDataset(Dataset):
def __init__(self):
super(TrainDataset, self).__init__()
self.data = []
for i in range(1,1000):
for j in range(1,1000):
self.data.append([i,j])
def __getitem__(self, index):
input_data = self.data[index]
label = input_data[0] + input_data[1]
return torch.Tensor(input_data),torch.Tensor([label])
def __len__(self):
return len(self.data)
class TestNet(nn.Module):
def __init__(self):
super(TestNet, self).__init__()
self.net1 = nn.Linear(2,1)
def forward(self, x):
x = self.net1(x)
return x
def train():
traindataset = TrainDataset()
traindataloader = DataLoader(dataset = traindataset,batch_size=1,shuffle=False)
testnet = TestNet().cuda()
myloss = nn.MSELoss().cuda()
optimizer = optim.SGD(testnet.parameters(), lr=0.001 )
for epoch in range(100):
for data,label in traindataloader :
print("\n=====迭代开始=====")
data = data.cuda()
label = label.cuda()
output = testnet(data)
print("输入数据:",data)
print("输出数据:",output)
print("标签:",label)
loss = myloss(output,label)
optimizer.zero_grad()
for name, parms in testnet.named_parameters():
print('-->name:', name)
print('-->para:', parms)
print('-->grad_requirs:',parms.requires_grad)
print('-->grad_value:',parms.grad)
print("===")
loss.backward()
optimizer.step()
print("=============更新之后===========")
for name, parms in testnet.named_parameters():
print('-->name:', name)
print('-->para:', parms)
print('-->grad_requirs:',parms.requires_grad)
print('-->grad_value:',parms.grad)
print("===")
print(optimizer)
input("=====迭代结束=====")
if __name__ == '__main__':
os.environ["CUDA_VISIBLE_DEVICES"] = "{}".format(3)
train()
代码结果1
结果说明
网络前传公式
w e i g h t 1 ∗ i n p u t 1 + w e i g h t 2 ∗ i n p u t 2 + b i a s = o u t p u t weight1input1+weight2input2+bias = output w e i g h t 1 ∗i n p u t 1 +w e i g h t 2 ∗i n p u t 2 +b i a s =o u t p u t
MSEloss的计算公式
Loss = ( o u t p u t − l a b e l ) 2 \text{Loss} = {(output-label)}^2 Loss =(o u t p u t −l a b e l )2
针对几个参数的偏导数可以用如下的方式计算:
∂ Loss ∂ w e i g h t 1 = ∂ Loss ∂ o u t p u t ∂ o u t p u t ∂ w e i g h t 1 = 2 ( o u t p u t − l a b e l ) i n p u t 1 = 2 ( 1.0098 − 2 ) ∗ 1 = − 1.9805 \frac{\partial\text{Loss}}{\partial weight1} = \frac{\partial\text{Loss}}{\partial output}\frac{\partial output}{\partial weight1} =2(output-label)input1 = 2(1.0098-2)*1=-1.9805 ∂w e i g h t 1 ∂Loss =∂o u t p u t ∂Loss ∂w e i g h t 1 ∂o u t p u t =2 (o u t p u t −l a b e l )i n p u t 1 =2 (1 .0 0 9 8 −2 )∗1 =−1 .9 8 0 5
∂ Loss ∂ w e i g h t 2 = ∂ Loss ∂ o u t p u t ∂ o u t p u t ∂ w e i g h t 2 = 2 ( o u t p u t − l a b e l ) i n p u t 2 = 2 ( 1.0098 − 2 ) ∗ 1 = − 1.9805 \frac{\partial\text{Loss}}{\partial weight2} = \frac{\partial\text{Loss}}{\partial output}\frac{\partial output}{\partial weight2} =2(output-label)input2 = 2(1.0098-2)*1=-1.9805 ∂w e i g h t 2 ∂Loss =∂o u t p u t ∂Loss ∂w e i g h t 2 ∂o u t p u t =2 (o u t p u t −l a b e l )i n p u t 2 =2 (1 .0 0 9 8 −2 )∗1 =−1 .9 8 0 5
∂ Loss ∂ b i a s = ∂ Loss ∂ o u t p u t ∂ o u t p u t ∂ b i a s = 2 ( o u t p u t − l a b e l ) = 2 ( 1.0098 − 2 ) = − 1.9805 \frac{\partial\text{Loss}}{\partial bias} = \frac{\partial\text{Loss}}{\partial output}\frac{\partial output}{\partial bias} =2(output-label) = 2(1.0098-2)=-1.9805 ∂b i a s ∂Loss =∂o u t p u t ∂Loss ∂b i a s ∂o u t p u t =2 (o u t p u t −l a b e l )=2 (1 .0 0 9 8 −2 )=−1 .9 8 0 5
运行一下代码换几个输入输出梯度就不一样了,这里主要是因为输入是两个1所以导致剃度一样。
数据更新
w e i g h t 1 n e w = − 0.0795 − ( − 1.9805 ) ∗ 0.001 = − 0.0776 w e i g h t 2 n e w = 0.625 − ( − 1.9805 ) ∗ 0.001 = 0.627 b i a s = 0.4643 − ( − 1.9805 ) ∗ 0.001 = 0.4663 \begin{aligned} weight1_{new} = -0.0795 – (-1.9805)0.001=-0.0776\ weight2_{new} = 0.625 – (-1.9805)0.001=0.627\ bias = 0.4643 – (-1.9805)*0.001=0.4663 \end{aligned}w e i g h t 1 n e w =−0 .0 7 9 5 −(−1 .9 8 0 5 )∗0 .0 0 1 =−0 .0 7 7 6 w e i g h t 2 n e w =0 .6 2 5 −(−1 .9 8 0 5 )∗0 .0 0 1 =0 .6 2 7 b i a s =0 .4 6 4 3 −(−1 .9 8 0 5 )∗0 .0 0 1 =0 .4 6 6 3


; 实验代码2:不同优化器的验证(Adam)
将实验1中的优化器换为如下的代码
optimizer = optim.Adam(testnet.parameters(), lr=0.001, betas=(0.9, 0.99))
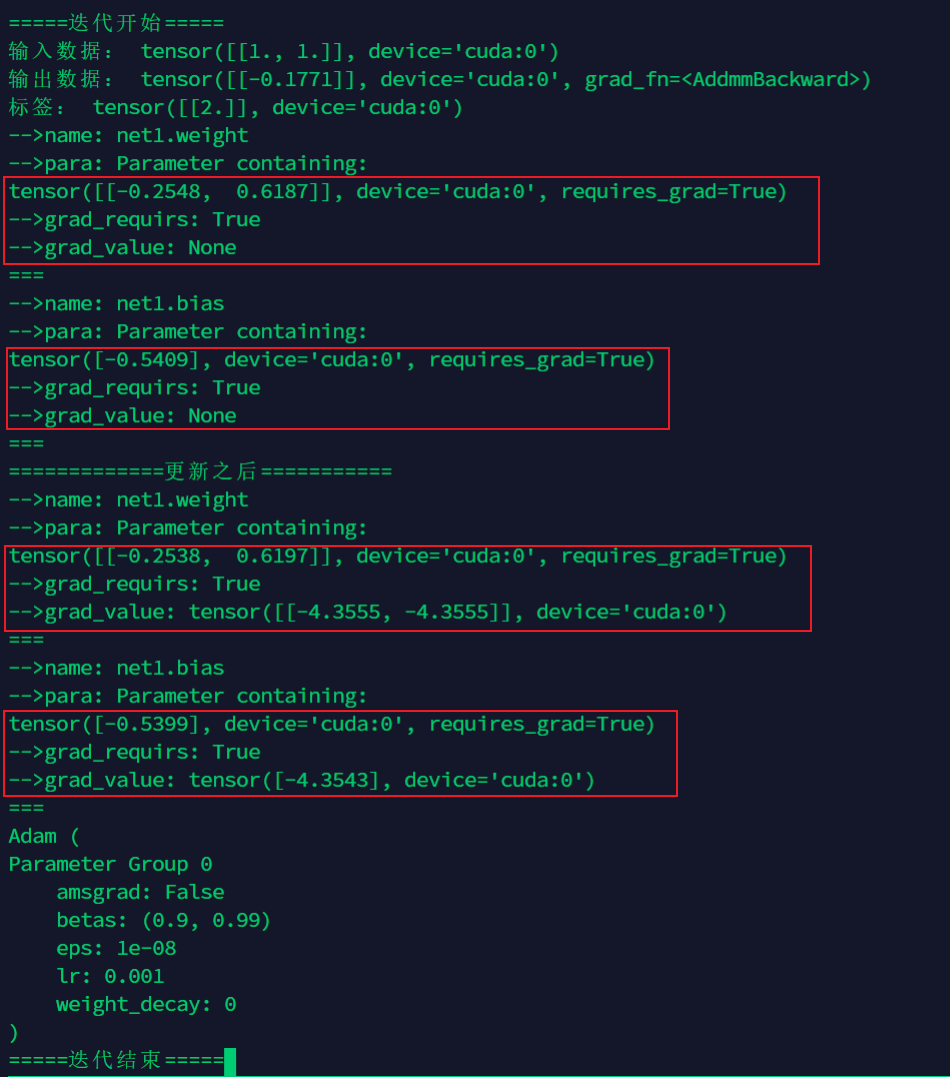
代码结果2
验证一下梯度loss求导公式没变所以针对梯度我们就不验证了
验证一下Adam的更新

算一下实际用于更新的梯度
m t = β 1 ∗ m t − 1 + ( 1 − β 1 ) ∗ g t v t = β 2 ∗ v t − 1 + ( 1 − β 2 ) ∗ g t 2 m t ^ = m t 1 − β 1 t v t ^ = n t 1 − β 2 t θ t = θ t − 1 − m t ^ v t ^ + ϵ ∗ α \begin{aligned} &m_{t}=\beta_1 * m_{t-1}+(1-\beta_1) * g_{t} \ &v_{t}=\beta_2 * v_{t-1}+(1-\beta_2) * g_{t}^{2} \ &\hat{{m}{t}}=\frac{m{t}}{1-\beta_1^{t}} \ &\hat{{v}{t}}=\frac{n{t}}{1-\beta_2^{t}} \ &\theta_{t}=\theta_{t-1}-\frac{\hat{{m}{t}}}{\sqrt{\hat{{v}{t}}}+\epsilon} * \alpha \end{aligned}m t =β1 ∗m t −1 +(1 −β1 )∗g t v t =β2 ∗v t −1 +(1 −β2 )∗g t 2 m t ^=1 −β1 t m t v t ^=1 −β2 t n t θt =θt −1 −v t ^+ϵm t ^∗α
我们验证一个w e i g h t 1 weight1 w e i g h t 1
m t = 0.9 ∗ m 0 + ( 1 − 0.9 ) ∗ − 4.3555 = − 0.43555 n t = 0.99 ∗ n 0 + ( 1 − 0.99 ) ∗ − 4.355 5 2 = 0.1897 m ^ t = − 0.43555 1 − 0. 9 1 = − 4.3555 n ^ t = 0.1897 1 − 0.9 9 1 = 18.97 − 0.2538 = − 0.2548 − − 4.3555 18.97 + ϵ ∗ 0.001 \begin{aligned} &m_{t}=0.9 * m_{0}+(1-0.9) * -4.3555 = -0.43555\ &n_{t}=0.99 * n_{0}+(1-0.99) -4.3555^{2} = 0.1897\ &\hat{m}{t}=\frac{-0.43555}{1-0.9^1} = -4.3555 \ &\hat{n}{t}=\frac{0.1897}{1-0.99^1} =18.97\ &-0.2538=-0.2548-\frac{-4.3555}{\sqrt{18.97}+\epsilon} * 0.001 \end{aligned}m t =0 .9 ∗m 0 +(1 −0 .9 )∗−4 .3 5 5 5 =−0 .4 3 5 5 5 n t =0 .9 9 ∗n 0 +(1 −0 .9 9 )∗−4 .3 5 5 5 2 =0 .1 8 9 7 m ^t =1 −0 .9 1 −0 .4 3 5 5 5 =−4 .3 5 5 5 n ^t =1 −0 .9 9 1 0 .1 8 9 7 =1 8 .9 7 −0 .2 5 3 8 =−0 .2 5 4 8 −1 8 .9 7 +ϵ−4 .3 5 5 5 ∗0 .0 0 1
会发现第一轮的时候最终更新的幅度一定是等于学习率的*,这个结论我们等会在实验代码三种再使用一次
; 实验代码3:优化器对不同层不同参数设置不一样的学习率
比较具体的可以参考之后的一片博客
Pytorch不同层设置不同学习率_呆呆象呆呆的博客-CSDN博客
将实验1中的优化器换为如下的代码
optimizer = optim.Adam(
[
{'params': testnet.net1.weight,'lr': 1e-2},
{'params': testnet.net1.bias, 'lr': 1e-1}
]
)
代码结果3
使用一下实验二的结果Adam优化器第一轮的更新幅度就等于学习率

; 补充说明
好像只能对一个具体的层进行参数的学习率设置,而不能再细化下去对每个层的不同位置的参数进行学习率的精细调整
LAST 参考文献
Pytorch 查看模型参数_happyday_d的博客-CSDN博客_pytorch查看模型参数
Original: https://blog.csdn.net/qq_41554005/article/details/119767740
Author: 呆呆象呆呆
Title: Pytorch 模型 查看网络参数的梯度以及参数更新是否正确,优化器学习率设置固定的学习率,分层设置学习率
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/706851/
转载文章受原作者版权保护。转载请注明原作者出处!