

《联邦学习实战》:从零开始通过联邦学习实现图像分类
最近需要学习联邦学习,参考《联邦学习实战》入门,本文为《联邦学习实战》 第三章的笔记。
可算跑起来了,在重点分析代码之前,因为太久没有用Pytorch,先复习一下Pytorch基础。
首先,在Pycharm命令行通过 pip install jupyter 来安装jupyter,新建一个jupyter notebook文件开始复习Pytorch基础
书中这里写得不好,有几个低级的错误,练习完毕后,开始分析代码
- 目的:用横向联邦来实现对cifar10图像数据集的分类
- 模型:ResNet-18
- 角色:服务端、客户端和配置文件
- 注意:为了方便实现,本章没有采用网络通信的方式来模拟客户端和服务端的通信,而是在本地以循环的方式来模拟
联邦学习在模型训练之前,会将配置信息分别发送到服务端和客户端中保存,如果配置信息发生改变,也会同时对所有参与方进行同步,以保证各参与方的配置信息一致。
配置文件 conf.json信息如下,为便于理解,添加了注释
{
"model_name" : "resnet18",
"no_models" : 10,
"type" : "cifar",
"global_epochs" : 20,
"local_epochs" : 3,
"k" : 5,
"batch_size" : 32,
"lr" : 0.001,
"momentum" : 0.0001,
"lambda" : 0.1
}
按照上述配置文件中的 type字段信息,获取数据集,这里用的是torchvision的datasets模块内置的cifar10数据集
注:CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( a叩lane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练圄片和 10000 张测试图片。
datasets.py代码如下
import torch
from torchvision import datasets, transforms
def get_dataset(dir, name):
if name=='mnist':
train_dataset = datasets.MNIST(dir, train=True, download=True, transform=transforms.ToTensor())
eval_dataset = datasets.MNIST(dir, train=False, transform=transforms.ToTensor())
elif name=='cifar':
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
train_dataset = datasets.CIFAR10(dir, train=True, download=True,
transform=transform_train)
eval_dataset = datasets.CIFAR10(dir, train=False, transform=transform_test)
return train_dataset, eval_dataset
server.py 代码
注: 横向联邦学习的服务端的主要功能是将被选择的客户端上传的本地模型进行模型聚合。但这里需要特别注意的是,事实上,对于一个功能完善的联邦学习框架,比如FATE平台,服务端的功能要复杂得多,比如服务端需要对各个客户端节点进行网络监控、对失败节点发出重连信号等。 本章由于是在本地模拟的,不涉及网络通信细节和失败故障等处理,因此不讨论这些功能细节,仅涉及模型聚合功能。
下面定义一个服务端类Server,类中的主要函数包括以下三种:
- 定义 构造函数
- 将配置信息拷贝到服务端中
- 按照配置中的模型信息获取模型,这里使用的是torchvision的models模块内置的ResNet-18模型
- 模型下载后,令其作为全局初始模型
class Server(object):
def __init__(self, conf, eval_dataset):
self.conf = conf
self.global_model = models.get_model(self.conf["model_name"])
self.eval_loader = torch.utils.data.DataLoader(eval_dataset, batch_size=self.conf["batch_size"], shuffle=True)
- 定义 模型聚合函数
- 在类中定义模型聚合函数,通过接收客户端上传的模型,使用聚合函数更新全局模型
- 聚合方案有很多种,这里采用经典的 FedAvg算法,书中提供的公式如下
def model_aggregate(self, weight_accumulator):
for name, data in self.global_model.state_dict().items():
update_per_layer = weight_accumulator[name] * self.conf["lambda"]
if data.type() != update_per_layer.type():
data.add_(update_per_layer.to(torch.int64))
else:
data.add_(update_per_layer)
- 定义 模型评估函数 对当前的全局模型,利用评估数据评估当前的全局模型性能。通常情况下,服务端的评估函数主要对当前聚合后的全局模型进行分析,用于判断当前的模型训练是需要进行下一轮迭代、还是提前终止,或者模型是否出现发散退化的现象。根据不同的结果,服务端可以采取不同的措施策略。
def model_eval(self):
self.global_model.eval()
total_loss = 0.0
correct = 0
dataset_size = 0
for batch_id, batch in enumerate(self.eval_loader):
data, target = batch
dataset_size += data.size()[0]
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
output = self.global_model(data)
total_loss += torch.nn.functional.cross_entropy(output, target,
reduction='sum').item()
pred = output.data.max(1)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
acc = 100.0 * (float(correct) / float(dataset_size))
total_l = total_loss / dataset_size
return acc, total_l
client.py 代码
横向联邦学习的客户端主要功能是接收服务端的下发指令和全局模型,并利用本地数据进行局部模型训练
本节仅考虑客户端本地的模型训练细节, 首先定义客户端类Client,类中的主要函数包括以下两种
- 定义构造函数
- 将配置信息拷贝到客户端中
- 按照配置中的模型信息获取模型,通常由服务端将模型参数传递给客户端,客户端将该全局模型覆盖掉本地模型
- 配置本地训练数据,此处通过torchvision的datasets模块获取cifar10数据集后按客户端ID进行切分,不同的客户端拥有不同的子数据集,相互之间没有交集
import models, torch, copy
class Client(object):
def __init__(self, conf, model, train_dataset, id = -1):
self.conf = conf
self.local_model = models.get_model(self.conf["model_name"])
self.client_id = id
self.train_dataset = train_dataset
all_range = list(range(len(self.train_dataset)))
data_len = int(len(self.train_dataset) / self.conf['no_models'])
train_indices = all_range[id * data_len: (id + 1) * data_len]
self.train_loader = torch.utils.data.DataLoader(self.train_dataset, batch_size=conf["batch_size"], sampler=torch.utils.data.sampler.SubsetRandomSampler(train_indices))
- 定义 模型本地训练函数
- 此处为图像分类的例子,使用交叉熵作为本地模型的损失函数
- 利用梯度下降来求解并更新参数值
def local_train(self, model):
for name, param in model.state_dict().items():
self.local_model.state_dict()[name].copy_(param.clone())
optimizer = torch.optim.SGD(self.local_model.parameters(), lr=self.conf['lr'],
momentum=self.conf['momentum'])
self.local_model.train()
for e in range(self.conf["local_epochs"]):
for batch_id, batch in enumerate(self.train_loader):
data, target = batch
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
optimizer.zero_grad()
output = self.local_model(data)
loss = torch.nn.functional.cross_entropy(output, target)
loss.backward()
optimizer.step()
print("Epoch %d done." % e)
diff = dict()
for name, data in self.local_model.state_dict().items():
diff[name] = (data - model.state_dict()[name])
return diff
4.6 整合 main.py 代码
1. 当配置文件、服务端类和客户端类都定义完毕后,我们将这些信息组合起来
parser = argparse.ArgumentParser(description='Federated Learning')
parser.add_argument('-c', '--conf', dest='conf')
args = parser.parse_args()
with open(args.conf, 'r') as f:
conf = json.load(f)
- 分别定义一个服务端对象和多个客户端对象,用来模拟横向联邦训练场景
train_datasets, eval_datasets = datasets.get_dataset("./data/", conf["type"])
server = Server(conf, eval_datasets)
clients = []
for c in range(conf["no_models"]):
clients.append(Client(conf, server.global_model, train_datasets, c))
- 每一轮的迭代,服务端会从当前的客户端集合中 随机挑选一部分参与本轮迭代训练,被选中的客户端调用本地训练接口local_train进行本地训练,最后服务端调用模型聚合函数model_aggregate来更新全局模型
for e in range(conf["global_epochs"]):
candidates = random.sample(clients, conf["k"])
weight_accumulator = {}
for name, params in server.global_model.state_dict().items():
weight_accumulator[name] = torch.zeros_like(params)
for c in candidates:
diff = c.local_train(server.global_model)
for name, params in server.global_model.state_dict().items():
weight_accumulator[name].add_(diff[name])
server.model_aggregate(weight_accumulator)
acc, loss = server.model_eval()
print("Epoch %d, acc: %f, loss: %f\n" % (e, acc, loss))
五、对比实验 为了绘制对比曲线,本来想用tensorboard工具,但pytorch用起来好像不是很方便,所以用最笨的方法,将想要对比的情况各自的loss和acc保存起来,然后新建个python文件来对比 保存的过程参考了文章:pytorch训练过程中Loss的保存与读取、绘制Loss图 联邦学习时,参数为上文的参数,在中心化训练时将 no_models 和 k 都设置为 1,再调整 local_epochs 运行程序 下面复现实验效果图:
1. 先在 main.py中增加保存loss和acc值到文件中的语句(此处为中心化训练时保存的语句,联邦学习类似)
Loss_save = np.array(loss_list)
np.save('./result/NON_FL_local_epochs_{}_loss'.format(conf["local_epochs"]), Loss_save)
Acc_save = np.array(acc_list)
np.save('./result/NON_FL_local_epochs_{}_acc'.format(conf["local_epochs"]), Acc_save)
2. 编写新的 compare.py 程序来画图
import numpy as np
from matplotlib import pyplot as plt
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
temp_loss1 = np.load('./result/FL_local_epochs_3_loss.npy')
loss_load1 = list(temp_loss1)
temp_acc1 = np.load('./result/FL_local_epochs_3_acc.npy')
acc_load1 = list(temp_acc1)
temp_loss2 = np.load('./result/NON_FL_local_epochs_1_loss.npy')
loss_load2 = list(temp_loss2)
temp_acc2 = np.load('./result/NON_FL_local_epochs_1_acc.npy')
acc_load2 = list(temp_acc2)
temp_loss3 = np.load('./result/NON_FL_local_epochs_2_loss.npy')
loss_load3 = list(temp_loss3)
temp_acc3 = np.load('./result/NON_FL_local_epochs_2_acc.npy')
acc_load3 = list(temp_acc3)
temp_loss4 = np.load('./result/NON_FL_local_epochs_3_loss.npy')
loss_load4 = list(temp_loss4)
temp_acc4 = np.load('./result/NON_FL_local_epochs_3_acc.npy')
acc_load4 = list(temp_acc4)
epoch_list = list(range(len(loss_load1)))
plt.figure(1)
plt.title('Loss Curve')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.plot(epoch_list, loss_load1, 'bp-', label=u"联邦学习(局部迭代三次)")
plt.plot(epoch_list, loss_load2, 'ro-', label=u"中心化训练(局部迭代一次)")
plt.plot(epoch_list, loss_load3, 'g+-', label=u"中心化训练(局部迭代两次)")
plt.plot(epoch_list, loss_load4, 'mx-', label=u"中心化训练(局部迭代三次)")
plt.xticks(epoch_list)
plt.legend()
plt.show()
plt.figure(2)
plt.title('Acc Curve')
plt.xlabel('Epoch')
plt.ylabel('Acc')
plt.plot(epoch_list, acc_load1, 'bp-', label=u"联邦学习(局部迭代三次)")
plt.plot(epoch_list, acc_load2, 'ro-', label=u"中心化训练(局部迭代一次)")
plt.plot(epoch_list, acc_load3, 'g+-', label=u"中心化训练(局部迭代两次)")
plt.plot(epoch_list, acc_load4, 'mx-', label=u"中心化训练(局部迭代三次)")
plt.xticks(epoch_list)
plt.legend()
plt.show()
3. 我的运行结果如图所示
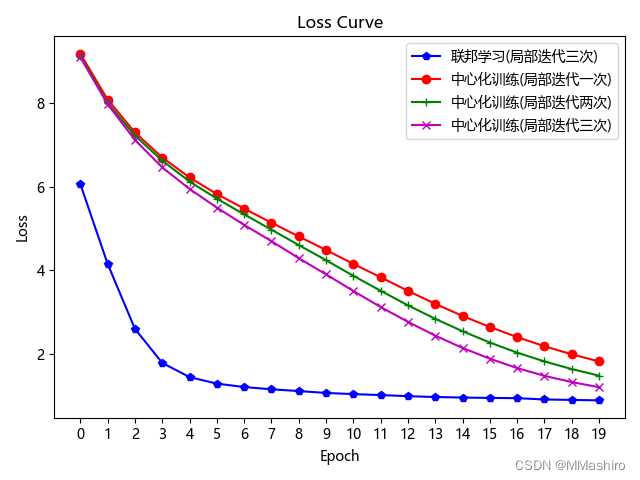

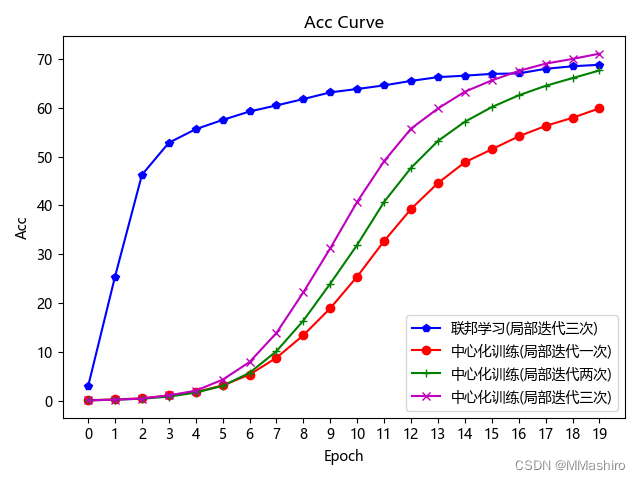
Original: https://blog.csdn.net/weixin_44716083/article/details/124859778
Author: MMashiro
Title: 《联邦学习实战》:从零开始通过联邦学习实现图像分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/705961/
转载文章受原作者版权保护。转载请注明原作者出处!