

文章目录
单目相机标定(基于Python OpenCV)
1.上期填坑
在开始本篇博客之前,先填一下上一篇博客【计算机视觉】基于ORB角点+RANSAC算法实现图像全景拼接的坑(不算填吧,算做一个记录,因为并没有解决问题,留着看以后有没有空解决👀),不想看的可以直接跳到下一节。
首先解决如何拼接多张图像(上篇博客只能拼接两张图像,多张图像需要保存两张图像的匹配结果,再重新读取计算角点)
改进的方法的基本思路是,仅计算当前两张图像的单应变换M_current,通过先前的单应矩阵M_before再计算一个累积变换,最终通过矩阵乘法得到的M的变换就延续了当前变换的累积变换矩阵:
M_before = np.eye(3,3)
result = cv2.imread('datas/1.jpg')
result,_,_ = utils.auto_reshape(result, 1080)
img2 = result
cors2, desc2= extraORBfromImg(orb, img2)
for i in range(1,6):
print(i)
img1 = cv2.imread('datas/'+str(i+1)+'.jpg')
img1,_,_ = utils.auto_reshape(img1, 1080)
cors1, desc1= extraORBfromImg(orb, img1)
match_dist, match_idx = ORBMatch(match, desc1, desc2)
match_pts = findMatchCord(match_idx, cors1, cors2)
update_match_pts = RANSAC(match_pts)
M = calc_homography(update_match_pts)
result, M = homography_trans(M, M_before, img1, result)
M_before = M
img2 = img1
cors2, desc2 = cors1, desc1
值得注意的是,代码采用的匹配顺序是从右至左,为了保证每次只提取最左侧图像的角点,img1对于图像的拍摄时序应该要在img2的左侧。
相应的,函数 homography_trans也要做修改:
def homography_trans(M, M_before, img1, img2):
M = M_before @ M
x_min, x_max, y_min, y_max, M2 = calc_border(M, img1.shape)
M = M2 @ M
w, h = int(round(x_max)-round(x_min)), int(round(y_max)-round(y_min))
out_img = cv2.warpPerspective(img1, M, (w, h))
out_img_blank_x = np.zeros((out_img.shape[0], abs(round(x_min)), 3)).astype(np.uint8)
img2_blank_x = np.zeros((img2.shape[0], abs(round(x_min)), 3)).astype(np.uint8)
if(x_min>0):
out_img = cv2.hconcat((out_img_blank_x, out_img))
if(x_min<0):
img2 = cv2.hconcat((img2_blank_x, img2))
out_img_blank_y = np.zeros((abs(round(y_min)), out_img.shape[1], 3)).astype(np.uint8)
img2_blank_y = np.zeros((abs(round(y_min)), img2.shape[1], 3)).astype(np.uint8)
if(y_min>0):
out_img = cv2.vconcat((out_img, out_img_blank_y))
if(y_min<0):
img2 = cv2.vconcat((img2_blank_y, img2))
if(img2.shape[0]<out_img.shape[0]):
blank_y = np.zeros((out_img.shape[0]-img2.shape[0], img2.shape[1], 3)).astype(np.uint8)
img2 = cv2.vconcat((img2, blank_y))
else:
blank_y = np.zeros((img2.shape[0]-out_img.shape[0], out_img.shape[1], 3)).astype(np.uint8)
out_img = cv2.vconcat((out_img, blank_y))
if(img2.shape[1]<out_img.shape[1]):
blank_x = np.zeros((img2.shape[0], out_img.shape[1]-img2.shape[1], 3)).astype(np.uint8)
img2 = cv2.hconcat((img2, blank_x))
else:
blank_x = np.zeros((out_img.shape[0], img2.shape[1]-out_img.shape[1], 3)).astype(np.uint8)
out_img = cv2.hconcat((out_img, blank_x))
result = addMatches(out_img, img2)
mask = 255*np.ones(result.shape).astype(np.uint8)
gray_res = cv2.cvtColor(result, cv2.COLOR_BGR2GRAY)
mask[gray_res==0]=0
cv2.imwrite('mask.jpg',mask)
cv2.imwrite('result.jpg',result)
return result, M
重点是改了这里(实现单应变换的传递):
... ...
M = M_before @ M
... ...
M = M2 @ M
(Ps:如果从左至右拼接,好像有点问题…)
然后另一个问题是:往后的拼接图像计算出的单应矩阵就会越扭曲:整一个视觉效果就会像这样
五张图像的拼接效果:


事实上,当前拼的结果还不完整,但一整个图像的像素已经非常大了,由于单应变换导致的图像扭曲占据了较大的图像空间,因此到后面系统直接报了内存分配不足的错误:
numpy.core._exceptions.MemoryError: Unable to allocate 7.71 GiB for an array with shape (17705, 19486, 3) and data type float64
还记得的上一篇博客提出的解决方案是,利用相机矩阵的畸变矩阵对图像进行一个径向畸变扭曲,目前本人已经初略了解了相机矩阵以及畸变参数,对图像做一个畸变处理(需要自己相机的内参)并不是很大问题,但是发现仍然不能很好的解决问题:
def CalcUndistort(img, mtx, dist):
return cv2.undistort(img, mtx, dist*12, dst=None, newCameraMatrix=None)
少量图片下,问题不大,但是拼接图像一多,仍然会有明显的透视效果:

原以为是畸变得不够,增加畸变系数后,拼接效果反而变差,(可能是因为图像畸变破坏了单应变换的基本假设):

所以,OpenCV, 还得是你
OpenCV为图像拼接专门封装了一个stitching类,最终能够实现可以看的效果的拼接大致需要经过以下流程:
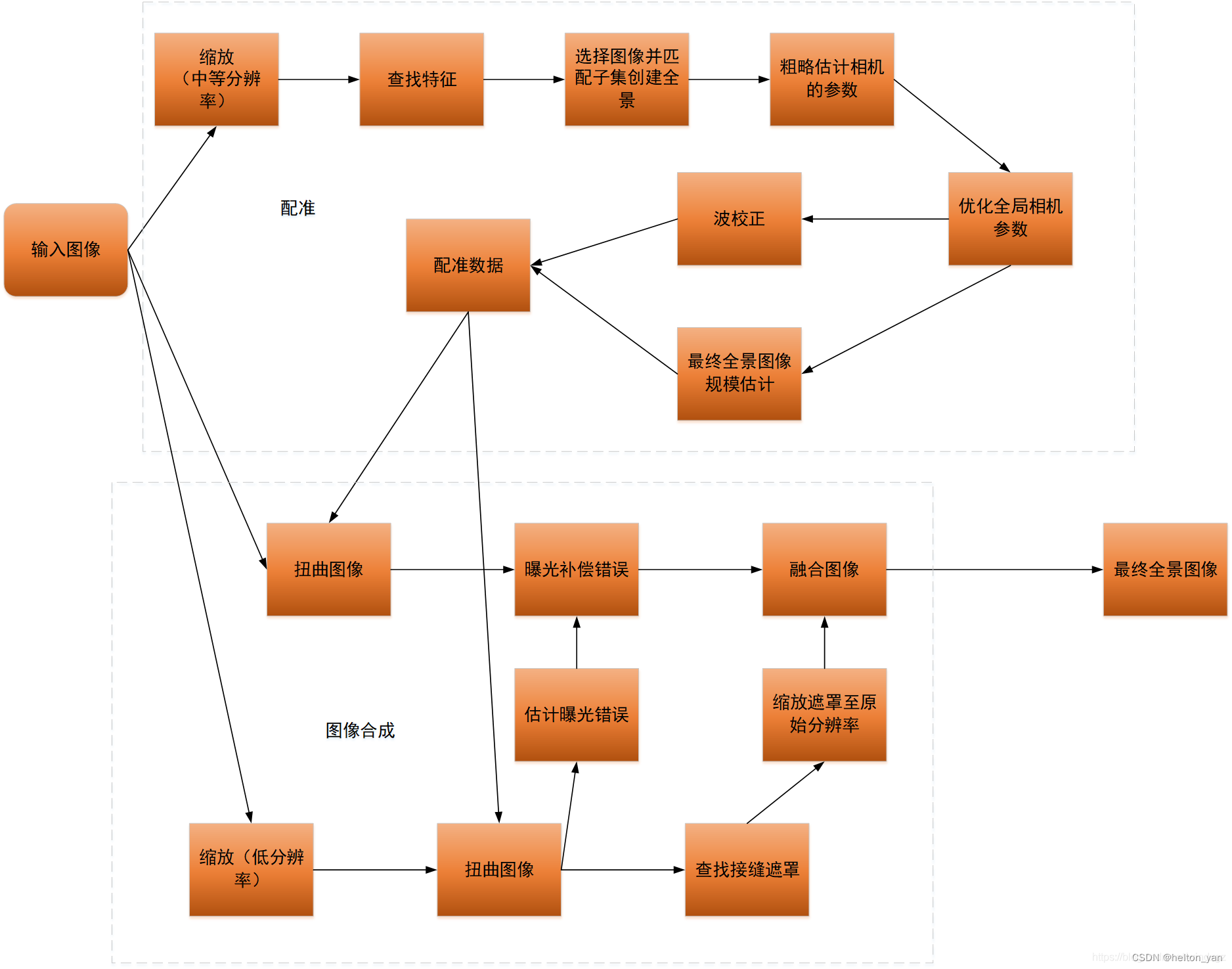
(上次博客中提到的论文中的rectangling矩形化方法就是解决整个图像拼接中扭曲图像这一小步)
(记得课上蔡老师说过,这学期学了计算机视觉这门课程,就可以去网上接项目赚钱,现在看起来,和小时候我看个宇宙纪录片,就想成为物理学家有点类似。当然,如果是单纯只学了课上的内容)
对于计算机视觉而言,实践是必要的,如果没有亲手实现,单纯的被动输入或许永远也不会知道某种看似可行的方法会存在的缺陷。
关于具体实现或者相关函数的API,可以观摩这位大佬的博客OpenCV总结3——图像拼接Stitching,我上面那张图也是从他那偷的,respect!
2.单目相机标定
进入正题
在图像测量过程以及机器视觉应用中,为确定空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系,必须建立相机成像的几何模型,这些几何模型参数就是相机参数。在大多数条件下这些参数必须通过实验与计算才能得到,这个求解参数(内参、外参、畸变参数)的过程就称之为相机标定(或摄像机标定)。无论是在图像测量或者机器视觉应用中,相机参数的标定都是非常关键的环节,其标定结果的精度及算法的稳定性直接影响相机工作产生结果的准确性。因此,做好相机标定是做好后续工作的前提,提高标定精度是科研工作的重点所在。
OpenCV封装了单目相机标定所需的各种方法。本篇博客的实现将基于这些封装好的函数。
本次单目相机的标定方法基于张正友博士于1998年提出的棋盘格标定方法,
论文链接:A Flexible New Technique for Camera Calibration,收录于2000年PAMI期刊。
具体的数学原理以及公式的推导可以参考网络上各类详细的博客以及教程,本篇博客不再赘述。
2.1 数据采集
标定板规格: GP340 12×9 25mm
相机: HUAWEI MATE 30 PRO(LIO AL00)
焦距: 27mm
分辨率: 3648×2736
拍摄数量: 20

; 2.2 角点提取
(获取角点两个坐标系下的坐标,作为求解方程中的已知量)
首先,基于 cv2.findChessboardCorners 寻找棋盘格角点:
def find_chessboard_cor(img):
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
is_success, corner = cv2.findChessboardCorners(gray_img, (11,8), None)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.001)
corner = cv2.cornerSubPix(gray_img, corner, (7, 7), (-1, -1), criteria)
return is_success, corner
值得注意的是,这里我们必须使用 cv2.cornerSubPix再进行一次迭代定位亚像素角点,使得角点的定位更为精确。
基于 cv2.drawChessboardCorners 可视化棋盘格角点:
def draw_chessboard_cor(img, cor, is_success):
cv2.drawChessboardCorners(img, (11,8), cor, is_success)
cv2.imshow('cor', img)
cv2.waitKey(50)

OpenCV提取棋盘角点可视化:

别忘了我们提取了棋盘格角点坐标的目的:这一步是为了获取角点在图像坐标系中的坐标。为了求解相机内外参矩阵,紧接着我们还需要获取棋盘格在原始世界坐标系中的坐标。
值得一提的是,无论是固定相机移动棋盘格进行拍摄,还是固定棋盘格移动相机进行拍摄,在 张正友标定法的假设中,棋盘格永远处在世界坐标系Z=0的平面上,棋盘格最左上角的角点为世界坐标系原点,往右为x轴正方向,往下为y轴正方向:

由于同一张标定板的规格不会改变,因此,世界坐标系通过人为定义即可:
world_coord = np.zeros((w * h, 3), np.float32)
world_coord[:, :2] = np.mgrid[0:w, 0:h].T.reshape(-1, 2)
世界坐标(单位化):
[[ 0. 0. 0.]
[ 1. 0. 0.]
[ 2. 0. 0.]
[ 3. 0. 0.]
[ 4. 0. 0.]
[ 5. 0. 0.]
[ 6. 0. 0.]
[ 7. 0. 0.]
… …
]]
shape = (88, 3) # 每个棋盘格上提取11*8=88个角点
一个特别值得注意且容易迷惑的地方是,由于相机参数的求解只依赖于角点与角点之间世界坐标的比例关系以及图像的大小(分辨率),而与具体的尺度无关,因此,角点世界坐标系的设置无需严格按照实际的尺度(25mm),只需按照角点之间距离的比例(单位化)(相邻角点的x,y坐标差均为1:1)
如果不信可以试试将角点的世界坐标赋予不同但比例一致的值,最终的求解结果都是完全一致的(len可以表示具体的尺度):
world_coord[:,:2] = np.mgrid[0:w*len:len,0:h*len:len].T.reshape(-1,2)
所以说,后续求得的相机内外参数也并不代表实际的尺度,它的单位是像素,如果要转化为实际的尺度,还需要知道相机每个像素代表现实中的实际尺度大小。
2.3 参数求解
通过 cv2.calibrateCamera 求解相机内外参数
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(world, cam, (img.shape[1], img.shape[0]), None, None)
当然,只基于一张图像的标定结果并不可靠,因此,需要自定义一个函数进行批量操作:
def CamCalibrate(w, h, num, root):
ratio = 1
world, cam = [], []
for i in range(num):
img = cv2.imread(root + str(i+1)+'.jpg')
is_success, cam_coord = find_chessboard_cor(img)
print('第'+str(i+1)+'张角点提取完毕, 角点数 =',cam_coord.shape[0])
world_coord = np.zeros((w * h, 3), np.float32)
world_coord[:, :2] = np.mgrid[0:w, 0:h].T.reshape(-1, 2)
world_coord[:,1] = -world_coord[:,1]
world.append(world_coord)
cam.append(cam_coord)
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(world, cam, (img.shape[1], img.shape[0]), None, None)
rvecs = np.array(rvecs).reshape(-1,3)
tvecs = np.array(tvecs).reshape(-1,3)
print("标定结果 ret:", ret)
print("内参矩阵 mtx:\n", mtx)
print("畸变系数 dist:\n", dist)
print("旋转向量(外参) rvecs:\n", rvecs)
print("平移向量(外参) tvecs:\n", tvecs)
np.save('./param/mtx.npy',mtx)
np.save('./param/dist.npy',dist)
np.save('./param/rvecs.npy',rvecs)
np.save('./param/tvecs.npy',tvecs)
np.save('./param/world.npy',np.array(world))
np.save('./param/cam.npy',np.array(cam))
return ret, mtx, dist, rvecs, tvecs
最终结果:
标定结果 ret: 1.4146770040984205
内参矩阵 mtx:
[[2.88760072e+03 0.00000000e+00 1.82151647e+03]
[0.00000000e+00 2.88741538e+03 1.37233666e+03]
[0.00000000e+00 0.00000000e+00 1.00000000e+00]]
畸变系数 dist:
[[ 0.01488259 0.03388964 -0.00044845 -0.00178608 0.03024054]]
旋转向量(外参) rvecs:
[[ 2.77705978 -0.46989843 0.1686412 ]
[-2.8145649 -0.91512141 -0.43737601]
… …
[ 2.67447733 0.66658815 -0.11254641]
[ 2.818184 -0.02291704 0.51413859]]
平移向量(外参) tvecs:
[[-5.06957615 -2.43006408 16.33928058]
[ 0.29829902 -4.17287918 13.05665933]
… …
[-3.8811355 -4.39040007 19.95916291]
[-4.53034049 -4.16521408 14.12011733]]
当然,单目相机标定的流程到这里就可以结束了
但是,评估求得的相机矩阵是否可靠也同样重要。一个方法是计算重投影误差,将角点的世界坐标通过已经求得的外参矩阵和相机内参矩阵重新转化到像素坐标下,与原始提取的图像角点坐标计算RMSE,得到的结果作为 重投影误差,误差越小,结果越可靠。
2.4 参数评估(重投影误差)
我们可以使用OpenCV内置的 cv2.projectPoints()直接计算重投影误差
当然,也可以自己实现:
def CalcProjectPoints(world, rvecs, tvecs, mtx, dist):
M = Rodriguez(rvecs)
R_t = (M @ world.T).T + tvecs
plain_pts = (mtx @ R_t.T)
plain_pts = (plain_pts / plain_pts[2,:]).T[:,:2]
c_xy = np.array([mtx[0,2], mtx[1,2]])
f_xy = np.array([mtx[0,0], mtx[1,1]])
k1, k2, p1, p2, k3 = dist[0]
x_y = (plain_pts - c_xy) / f_xy
r = np.sum(x_y * x_y, 1)
x_distorted = x_y[:,0] * (1 + k1*r + k2*r*r + k3*r*r*r) + 2*p1*x_y[:,0]*x_y[:,1] + p2*(r + 2*x_y[:,0]*x_y[:,0])
y_distorted = x_y[:,1] * (1 + k1*r + k2*r*r + k3*r*r*r) + 2*p2*x_y[:,0]*x_y[:,1] + p1*(r + 2*x_y[:,1]*x_y[:,1])
u_distorted = f_xy[0]*x_distorted + c_xy[0]
v_distorted = f_xy[1]*y_distorted + c_xy[1]
plain_pts = np.array([u_distorted,v_distorted]).T
return plain_pts
这里面有很多细节需要了解,就比如OpenCV的旋转向量转旋转矩阵基于Rodriguez变换(我之前一直以为是欧拉角,算出来的结果让我迷了一段时间):
def Rodriguez(rvecs):
θ = (rvecs[0] * rvecs[0] + rvecs[1] * rvecs[1] + rvecs[2] * rvecs[2])**(1/2)
r = rvecs / θ
anti_r = np.array([
[0, -r[2], r[1]],
[r[2], 0, -r[0]],
[-r[1], r[0], 0]
])
M = np.eye(3) * np.cos(θ) + (1 - np.cos(θ)) * np.outer(r, r) + np.sin(θ) * anti_r
return M
还有就是如何重投影时添加畸变,这些网上都可以查阅得到,这里不再赘述。
OpenCV同样内置 cv2.norm()求解RMSE,当然也可以自己实现:
error = original_pts - reprojec_pts
error = np.sum(error*error)**(1/2) / reproj.shape[0]
我们也可以将重投影结果在图像中可视化出来:
def drawReprojCor(img, original_pts, reprojec_pts, idx):
r,g = (0,0,255),(0,255,0)
for i in range(original_pts.shape[0]):
x0, y0 = int(round(original_pts[i,0])), int(round(original_pts[i,1]))
cv2.circle(img, (x0, y0), 10, g, 2, lineType=cv2.LINE_AA)
x1, y1 = int(round(reprojec_pts[i,0])), int(round(reprojec_pts[i,1]))
cv2.circle(img, (x1, y1), 10, r, 2, lineType=cv2.LINE_AA)
cv2.imwrite('./reproject_result/'+ str(idx+1)+'.jpg', img)
红圈表示重投影点,绿圈表示原始提取的角点,来可视化两张误差比较大的:
对应序列第6张: RMSE=0.2501498893076572

对应序列第9张:RMSE=0.32640338317469253

同样,封装成批处理函数:
def CalcReprojError(num, world, cam, mtx, dist, rvecs, tvecs):
errors = []
for i in range(num):
reproj = CalcProjectPoints(world[i], rvecs[i], tvecs[i], mtx, dist)
original_pts = cam[i].reshape(cam[i].shape[0], 2)
reprojec_pts = reproj.reshape(reproj.shape[0], 2)
error = original_pts - reprojec_pts
error = np.sum(error*error)**(1/2) / reproj.shape[0]
errors.append(error)
img = cv2.imread('./0/' + str(i+1)+'.jpg')
drawReprojCor(img, original_pts, reprojec_pts, i)
如果想让可视化更直观些,可以用条形图统计每一张的误差:
plt.bar(range(num), errors, width=0.8, label='reproject error', color='#87cefa')
mean_error = sum(errors) / num
plt.plot([-1,num], [mean_error,mean_error], color='r', linestyle='--',label='overall RMSE:%.3f'%(mean_error))
plt.xticks(range(num), range(1,num+1))
plt.ylabel('RMSE Error in Pixels')
plt.xlabel('Images')
plt.legend()
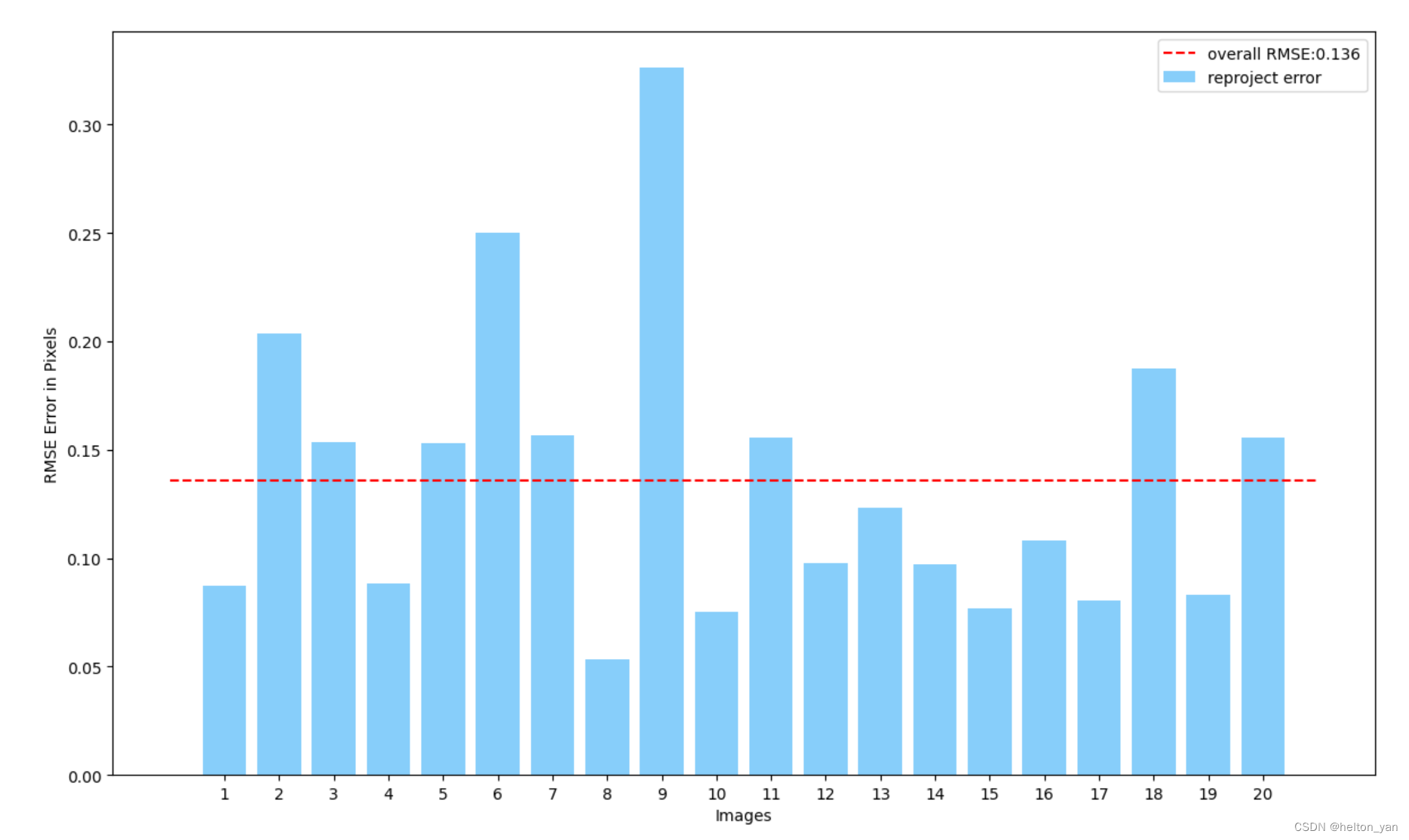
那这样标定的完整流程应该就可以结束了吧
好吧,求解的参数中还有外参数没用,为什么不来可视化看看相机位姿呢👀
2.5 相机位姿(棋盘位姿)可视化
可视化相机位姿的核心思路就是将相机坐标系下的相机坐标通过外参矩阵(旋转+平移)转换到世界坐标系:
def show_cam_pose(rvecs, tvecs):
vec = np.array([
[1,0,0],
[0,1,0],
[0,0,1]
])
cam = (2/3)*np.array([
[ 1, 1, 2],
[-1, 1, 2],
[-1,-1, 2],
[ 1,-1, 2],
[ 1, 1, 2],
])
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for i in range(rvecs.shape[0]):
M = Rodriguez(rvecs[i,:])
x0,y0,z0 = M.T @ (-tvecs[i,:])
c = ['r','g','b']
hex = '0123456789abcdef'
rand_c = '#'+''.join([hex[random.randint(0,15)] for _ in range(6)])
for j in range(3):
x1,y1,z1 = M.T @ (vec[j,:] - tvecs[i,:])
ax.plot([x0,x1],[y0,y1],[z0,z1],color=c[j])
C = (M.T @ (cam - tvecs[i,:]).T).T
for k in range(4):
ax.plot([C[k,0],C[k+1,0]],[C[k,1],C[k+1,1]],[C[k,2],C[k+1,2]], color=rand_c)
ax.plot([x0,C[k+1,0]],[y0,C[k+1,1]],[z0,C[k+1,2]], color=rand_c)
ax.text(x0,y0,z0,i+1)
for i in range(9):
ax.plot([0, 11],[-i, -i],[0,0],color="black")
for i in range(12):
ax.plot([i, i],[-8, 0],[0,0],color="black")
for i in range(3):
ax.plot([0, 3*vec[i,0]],[0, -3*vec[i,1]],[0, 2*vec[i,2]],color=c[i],linewidth=3)
plt.xlim(-3,14)
plt.ylim(-13,4)
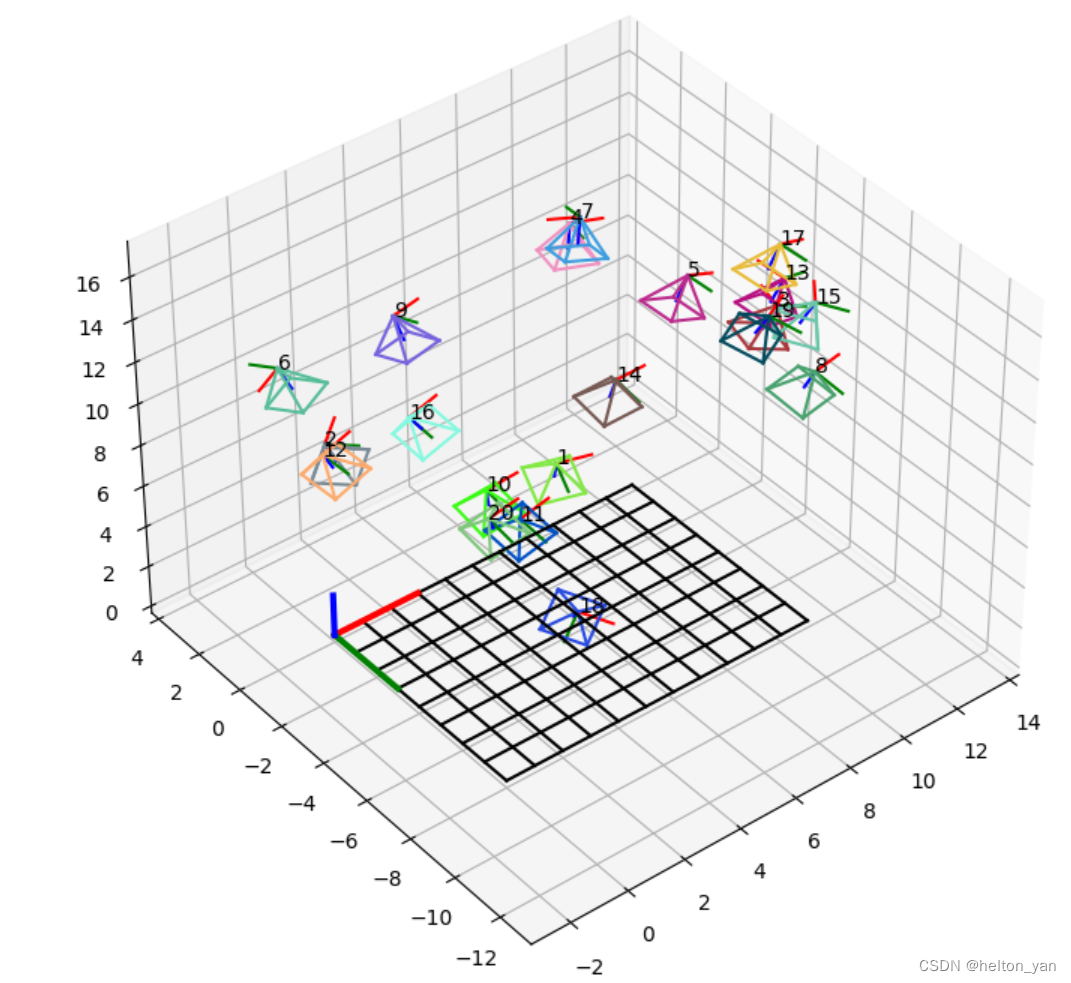
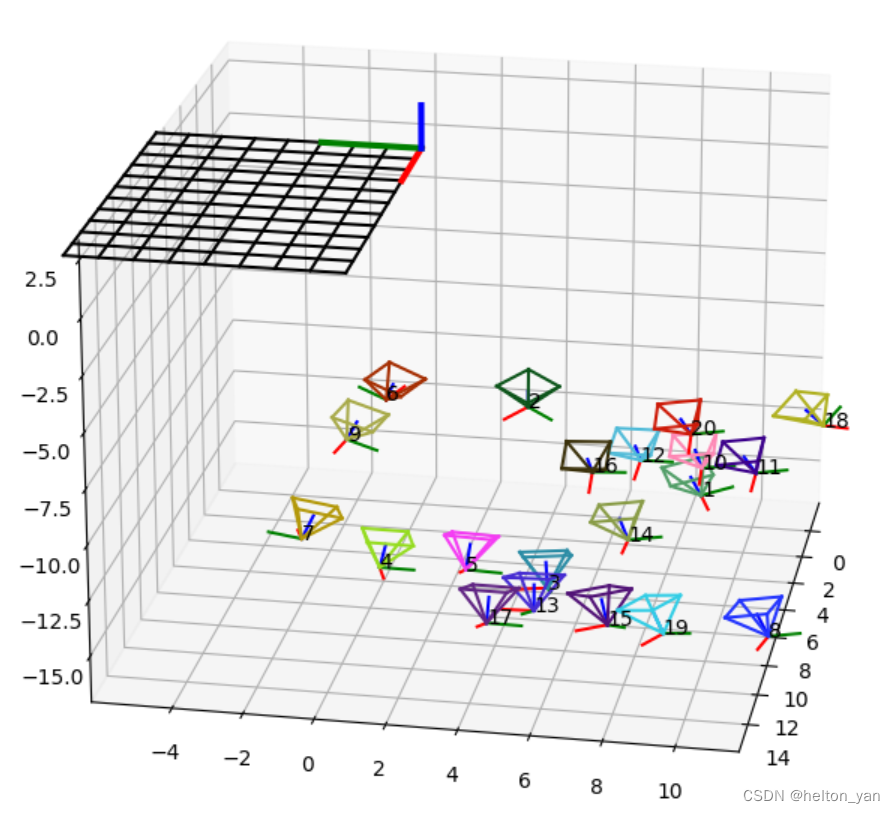
值得注意的是,我们需要在自定义的标定函数中将世界坐标系的y轴改为负的,可视化结果才是正确的,否则可视化的结果是错误的(如下图),原因其实在2.2节就已给出,大家可以想一想这是为什么
同样的, 可视化棋盘格位姿的核心思路就是将世界坐标系下的棋盘坐标通过外参矩阵(旋转+平移)的逆变换转换到相机坐标系:
def show_chessboard_pose(rvecs, tvecs):
vec = np.array([
[1,0,0],
[0,1,0],
[0,0,1]
])
C = np.array([
[ 1, 1, 3],
[-1, 1, 3],
[-1,-1, 3],
[ 1,-1, 3],
[ 1, 1, 3],
])
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
c = ['r','g','b']
for i in range(rvecs.shape[0]):
M = Rodriguez(rvecs[i,:])
x0,y0,z0 = tvecs[i,:]
hex = '0123456789abcdef'
rand_c = '#'+''.join([hex[random.randint(0,15)] for _ in range(6)])
for k in range(0,9):
b = np.array([[0, -k, 0],[11, -k, 0]])
b = (M @ b.T + tvecs[i,:].reshape(-1,1)).T
ax.plot([b[0,0], b[1,0]],[b[0,1], b[1,1]],[b[0,2], b[1,2]],color=rand_c)
for k in range(0,12):
b = np.array([[k, -8, 0],[k, 0, 0]])
b = (M @ b.T + tvecs[i,:].reshape(-1,1)).T
ax.plot([b[0,0], b[1,0]],[b[0,1], b[1,1]],[b[0,2], b[1,2]],color=rand_c)
k += 11
for j in range(3):
x1,y1,z1 = M @ vec[j,:] + tvecs[i,:]
ax.plot([x0,x1],[y0,y1],[z0,z1],color=c[j])
ax.text(x0,y0,z0,i+1)
for i in range(3):
ax.plot([0, vec[i,0]],[0, -vec[i,1]],[0, 2*vec[i,2]],color=c[i],linewidth=2)
for i in range(4):
ax.plot([C[i,0],C[i+1,0]],[C[i,1],C[i+1,1]],[C[i,2],C[i+1,2]], color="black")
ax.plot([0,C[i+1,0]],[0,C[i+1,1]],[0,C[i+1,2]], color="black")
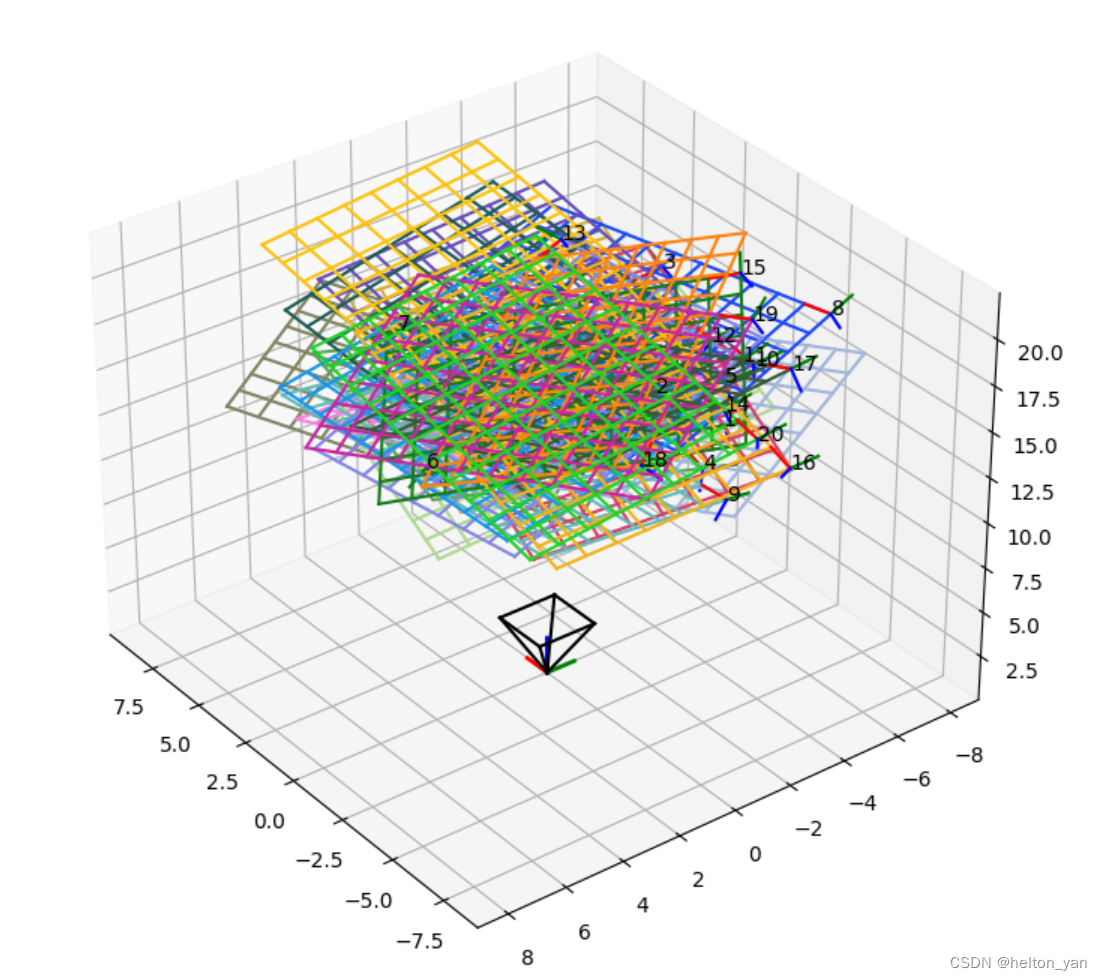
2.6 同Matlab标定结果比较
一般可以认为,Matlab内置算法的标定结果更为精确,因此,我们可以再通过Matlab标定得到一组参数,来验证我们的参数是否靠谱:
基于Matlab的标定:
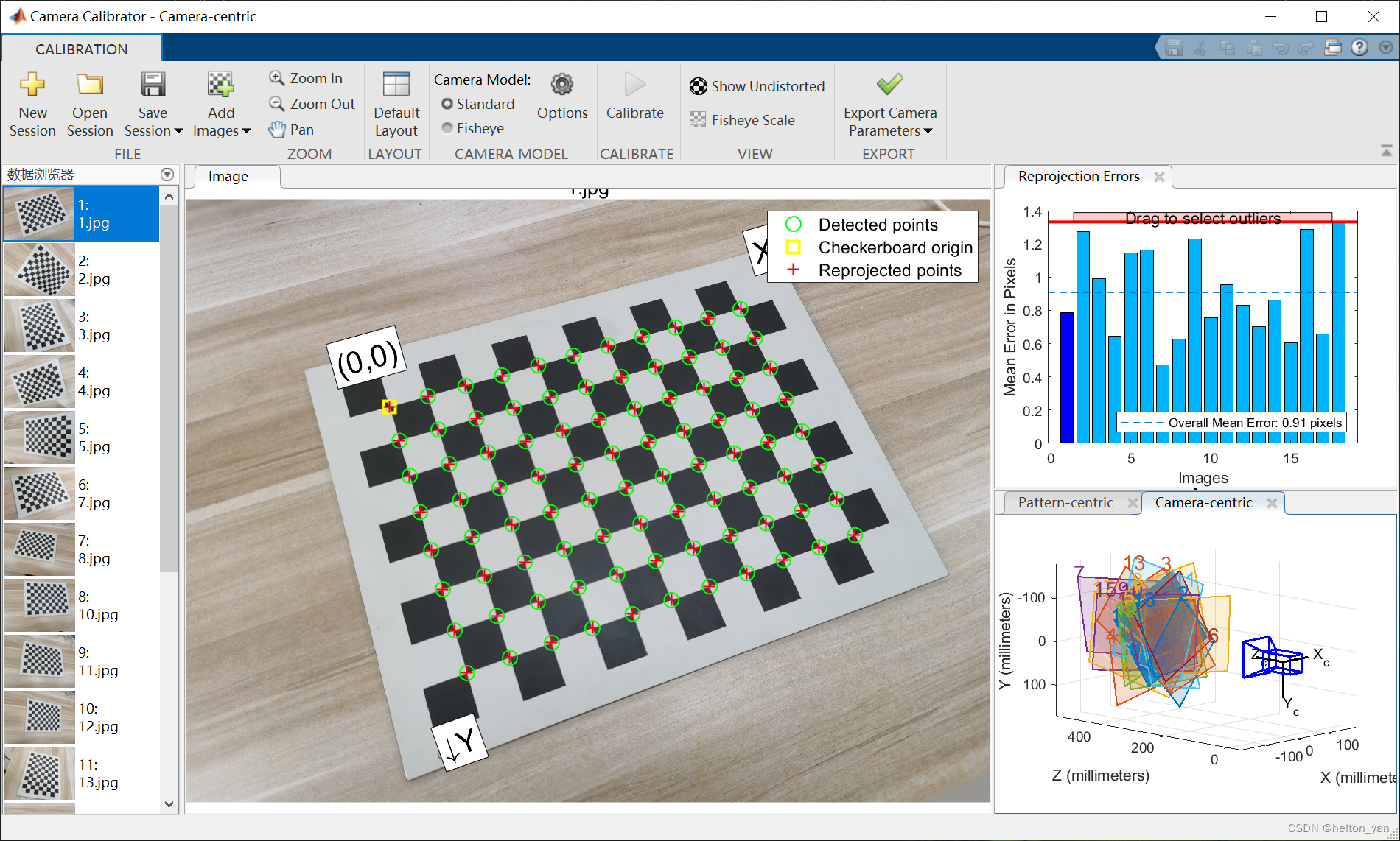
在标定过程中,程序自动舍弃了两张误差较大的图像,正好就是序列第6张和第9张。
注意到Matlab的Reprojection Errors和我们自己标定的重投影误差有些不太一样,这是因为Matlab使用MSE,我们的代码使用RMSE。
Matlab给出的标定内参矩阵(是转置的形式),和:

我们的标定结果:
内参矩阵 mtx:
[[2.88760072e+03 0.00000000e+00 1.82151647e+03]
[0.00000000e+00 2.88741538e+03 1.37233666e+03]
[0.00000000e+00 0.00000000e+00 1.00000000e+00]]
是有一定的误差但也不至于太离谱,至少可以认为结果是相对可靠的。
(完)
Original: https://blog.csdn.net/SESESssss/article/details/124893508
Author: helton_yan
Title: 【计算机视觉】OpenCV实现单目相机标定
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/703550/
转载文章受原作者版权保护。转载请注明原作者出处!