

2021年全国电赛题目如下:

一:主要思路
基于opencv,树莓派,以及网络交换机组成的摄像测量系统。由测量摄像
系统与网络传输系统组成。支持开机自启动,一键测量,声光提示结束测量,高帧率显
示图像的系统。其中摄像系统包括两组树莓派与摄像头组合,网络传输系统由网线,以
太网交换机,以及终端树莓派及其树莓派组成。通过测量目标物体的像素位置,将坐标通
过网络交换机传递给终端服务器进行绳长的计算。并且通过记录激光头在图像的最大位
置与稳态位置的x 坐标差值之比进行对摆动角的计算。最终做到了测量绳长度误差小于
2cm、测量角度误差小于5°。
二:主要原理
1.视频流的处理
将树莓派得到的图像上载到局域网下,通过交换机进行局域网的数据传输:即三个树莓派全部插在交换机接口上,得到一个局域网,每个树莓派将获得一个ip地址,将树莓派摄像头采集到的视频流传输上局域网下,图像处理即opencv只需直接从局域网下直接读取视频转化为图像进行处理,终端树莓派即显示双图像树莓派也可从局域网下下载图像。
使用的方法:python的requests(从局域网下下载图像)、socket(局域网下的数据传输)、opencv(图像处理)。
局域网下的视频流上传:
opencv-python——使用mjpg-streamer实现实时视频流获取并进行远程图像处理操作_Irving.Gao的博客-CSDN博客
需要注意的是

只需到subversion即可
按照流程进行下载和开启,就可以从局域网http://localhost:8080/得到图像(localhost是测量的树莓派的ip地址)
以下代码即可得到图像信息即返回值img_cv
url = "http://localhost:8080/?action=snapshot"
def downloadImg():
global url
with request.urlopen(url) as f:
data = f.read()
img1 = np.frombuffer(data, np.uint8)
#print("img1 shape ", img1.shape) # (83653,)
img_cv = cv2.imdecode(img1, cv2.IMREAD_ANYCOLOR)
return img_cv
2.局域网下的数据传输
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
ip_port = (("host", 27830)) #host主机地址即终端 27830随机设置即端口号
传输:
trans = '1 ' + str(box[0][0]) + ' ' + str(box[0][1]) + ' ' + str(box[1][0]) + ' ' + str(box[1][1]) + ' ' + str(
box[2][0]) + ' ' + str(box[2][1]) + ' ' + str(box[3][0]) + ' ' + str(box[3][1]) + ' ' + str(bias_x) + ' ' + str(
long)
try:
client.send(trans.encode('utf-8')) # 设置编码为utf-8
except:
print('transport error')
这是我的数据传输端:trans是传输的数据,其中包括从机序号 ‘1/2’+目标矩形框的坐标和本机树莓派测量得到的长度和x/y方向的偏差值(用于主机整合信息测量角度)
下面是主机的连接和获取
连接:
def link_ip():
server.bind(("192.168.1.3", 27830)) # 地址与端口
server.listen(10)
print("等待连接..")
time.sleep(10)
num = 0
while num<2: if num="=1:" conn, addr="server.accept()" # 等待连接 print("conn:", "\naddr:", addr) conn连接实例 else: conn1, num+="1" return [conn, conn1]< code></2:>
获取与解码:
def get_data(cnn, image, image1):
long = 0
get_n = 0
msg = cnn[0].recv(1024).decode('utf-8') # 接受数据并按照utf-8解码
msg1 = cnn[1].recv(1024).decode('utf-8') # 接受数据并按照utf-8解码
get_r = msg.split(' ')
get_r1 = msg1.split(' ')
将得到的数据变换后得到框图信息和长度、偏差信息,得到需要的数据并对应每一张图片进行框图和计算。
3.opencv识别激光笔
可以将激光笔换成其他易识别颜色,通过色域的划分和图像滤波处理,排除其他干扰,得到目标位置框图并画框:
确定色域的值:
-*- coding:utf-8 -*-
import cv2
import numpy as np
from urllib import request
url = "http://:8080/?action=snapshot"
def downloadImg():
global url
with request.urlopen(url) as f:
data = f.read()
img1 = np.frombuffer(data, np.uint8)
#print("img1 shape ", img1.shape) # (83653,)
img_cv = cv2.imdecode(img1, cv2.IMREAD_ANYCOLOR)
return img_cv
def mouse_click(event, x, y, flags, para):
if event == cv2.EVENT_LBUTTONDOWN: # 左边鼠标点击
# print('PIX:', x, y)
# print("BGR:", img[y, x])
# print("GRAY:", gray[y, x])
print("HSV:", hsv[y, x])
if __name__ == '__main__':
cv2.namedWindow("img")
cv2.setMouseCallback("img", mouse_click)
cv2.setMouseCallback("img1", mouse_click)
while True:
image = downloadImg() #cv2.imread('1.jpg') # 根据路径读取一张图片
(grabbed, img) = cap.read()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
cv2.imshow('img', image)
if cv2.waitKey() == ord('q'):
break
cv2.destroyAllWindows()
其中的url是自己的树莓派从机ip即第一步,得到图像,鼠标点击需要识别的位置,即会返回次点的hsv色域值,改变接下来识别的color_dist即可得到hsv的大致范围,接下来即可得到lower和upper,可以作为opencv的色域范围,也方便现场调参
识别和数据处理:
color_dist = {'red': {'Lower': np.array([25, 100, 100]), 'Upper': np.array([55, 185, 185])}}
frame = downloadImg() # cv2.imread('1.jpg') # 根据路径读取一张图片
gs_frame = cv2.GaussianBlur(frame, (5, 5), 0) # 高斯模糊
hsv = cv2.cvtColor(gs_frame, cv2.COLOR_BGR2HSV) # 转化成HSV图像
erode_hsv = cv2.erode(hsv, None, iterations=2) # 腐蚀 粗的变细
inRange_hsv = cv2.inRange(erode_hsv, color_dist[ball_color]['Lower'], color_dist[ball_color]['Upper'])
cnts = cv2.findContours(inRange_hsv.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]
try:
c = max(cnts, key=cv2.contourArea)
except:
cv2.imshow('camera', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
continue
rect = cv2.minAreaRect(c)
box = cv2.boxPoints(rect)
print(box)
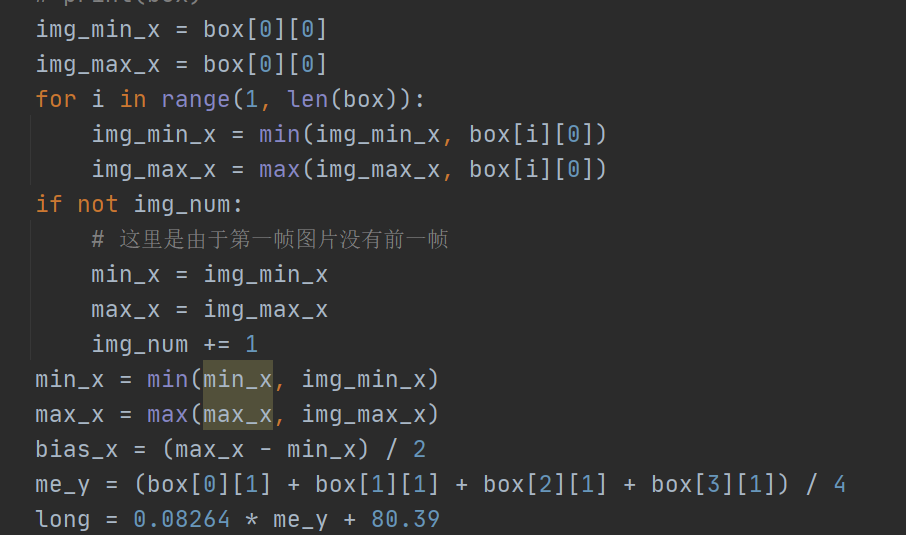
img_min_x = box[0][0]
img_max_x = box[0][0]
for i in range(1, len(box)):
img_min_x = min(img_min_x, box[i][0])
img_max_x = max(img_max_x, box[i][0])
if not img_num:
# 这里是由于第一帧图片没有前一帧
min_x = img_min_x
max_x = img_max_x
img_num += 1
min_x = min(min_x, img_min_x)
max_x = max(max_x, img_max_x)
bias_x = (max_x - min_x) / 2
me_y = (box[0][1] + box[1][1] + box[2][1] + box[3][1]) / 4
long = 0.08264 * me_y + 80.39 #拟合得到的数据,求长度,后面说明,需自己测量
改进思路:
未来防止可能的扰动误差,可以在动态图像的基础上进行处理,通过前后帧的区别找出动态区域,对该区域进行色域识别,可以滤除背景中可能的颜色重叠,这样也可以增加色域的范围大小,报账识别率。
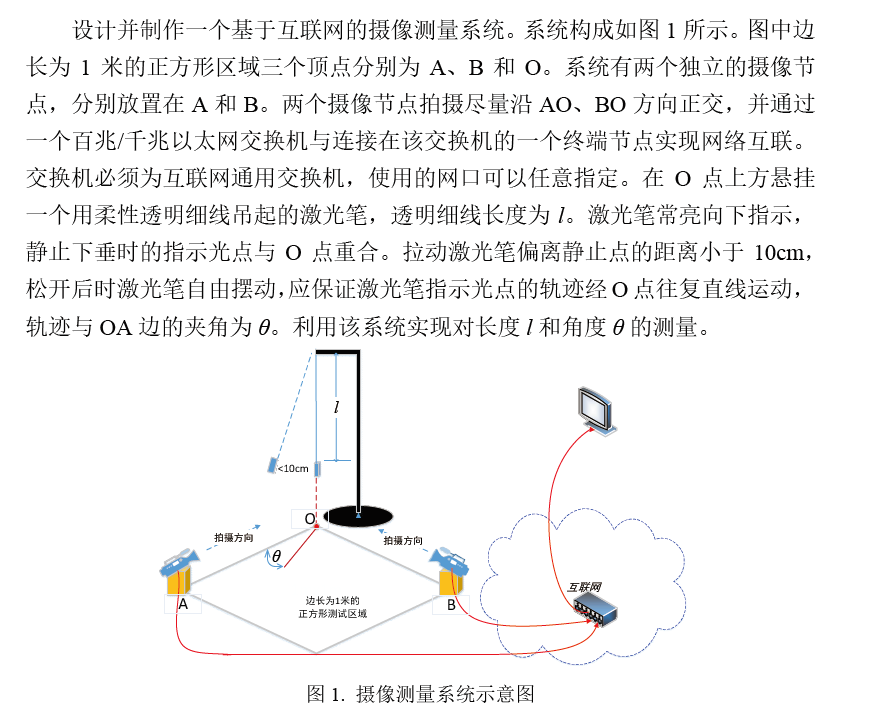
由上一步的数据传输可以在终端主机上看到如下图
4:数据处理
如上部分的opencv中包含了数据处理,以下为讲解:
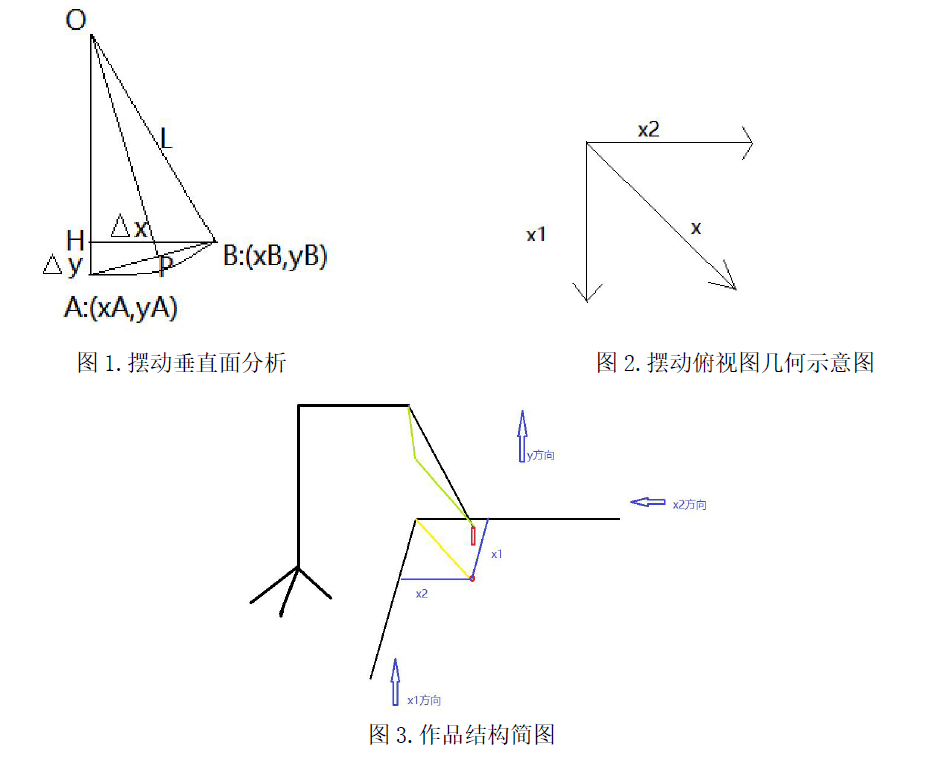
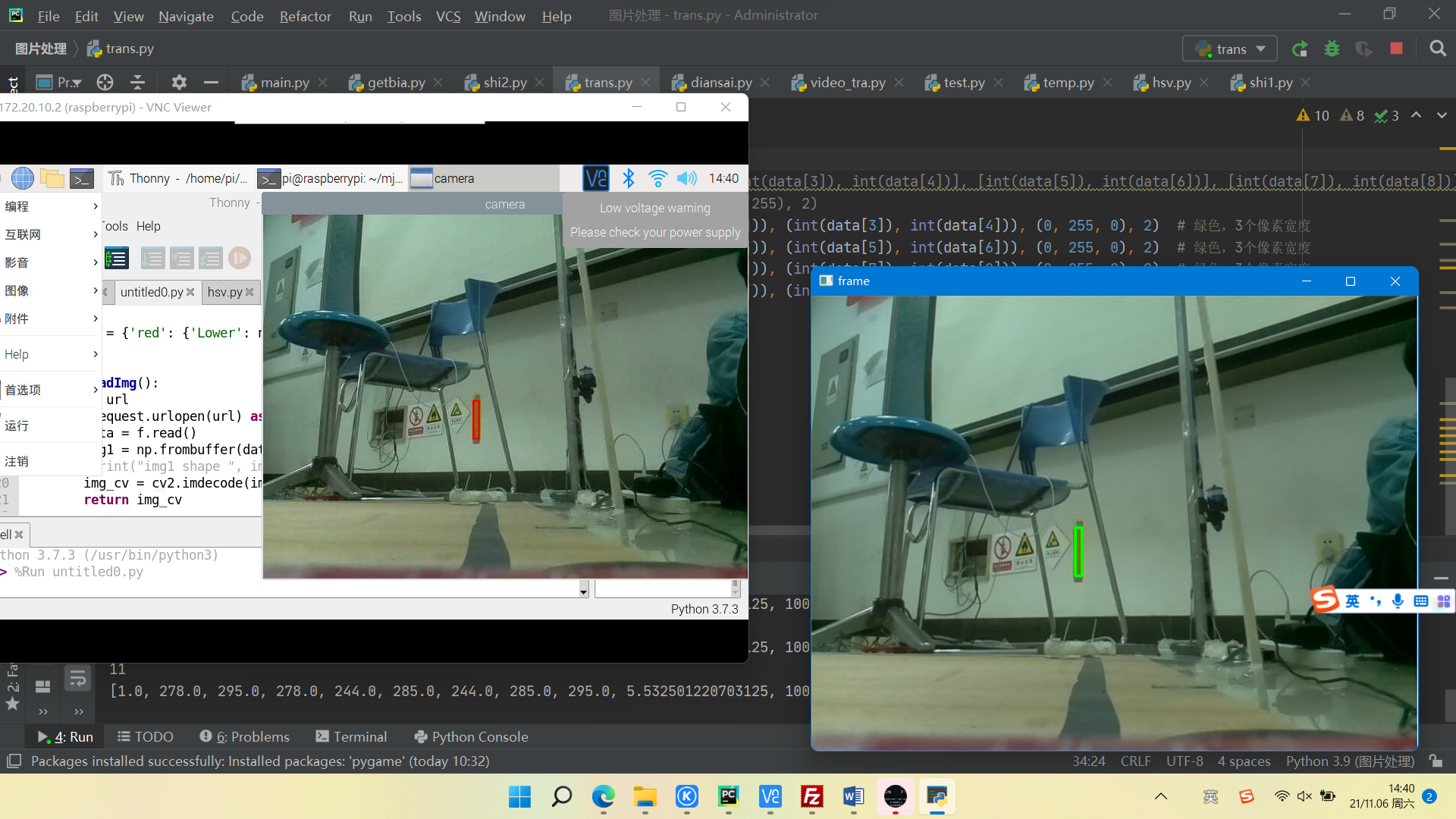
两个从机处理图像时,需要测量的是x范围的偏差值即图中的x1,x2,并传回主机,这样就可以主机对角度的测量,在具体实现中,不考虑上下误差(绳子很长)
对于在实际中的激光笔抖动可以很容易发现,在45°时,抖动对于x的测量没有影响,在0°和90°时,抖动主要是左右,即需在0°除2,45°除1,在中间角度线性除法,即可消除一部分的抖动误差
具体代码实现见上,思路也可参照下面的图
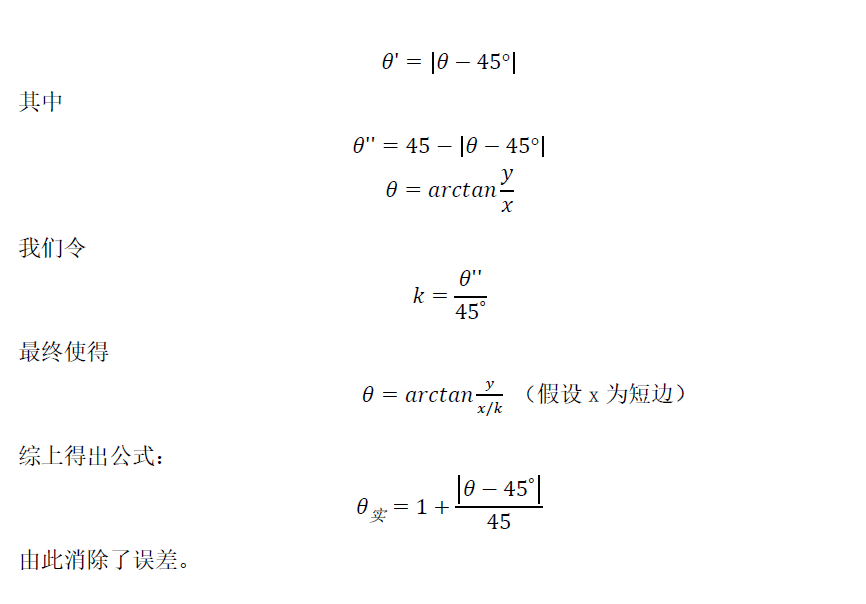
如何得到绳的长度:
采用的是多长度线性拟合,多次测量绳长与当前位置的y像素值(大约5-6组),在matlab中使用曲线拟合工具,拟合为一元二次方程,在拟合过程中可以发现拟合的直线比较好的将大部分点包围左右,最后在终端中进行加权平均,就可以大致获得绳长,效果较佳。
三.最终成品

Original: https://blog.csdn.net/weixin_50569944/article/details/122407999
Author: ZN-ZY
Title: 2021电赛D题:基于互联网的摄像测量系统 思路
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/702800/
转载文章受原作者版权保护。转载请注明原作者出处!