



Abstract
图神经网络 (GNN) 是小样本学习的上升趋势。 GNN 中的一个关键组成部分是 亲和力。通常,GNN 中的亲和力主要在特征空间中计算,例如成对特征,并且没有充分利用与这些特征相关的语义标签。在本文中,我们提出了一种新颖的 Mutual CRF-GNN (MCGN)。在这个 MCGN 中, 支持数据的 标签和特征被 CRF 用于以有原则和概率的方式推断 GNN 亲和力。具体来说,我们构建了一个 以标签和支持数据的特征为条件的条件随机场 (CRF),以推断标签空间中的亲和力。这种亲和性作为节点亲和性被馈送到 GNN。 GNN和CRF在MCGN中相互促进。
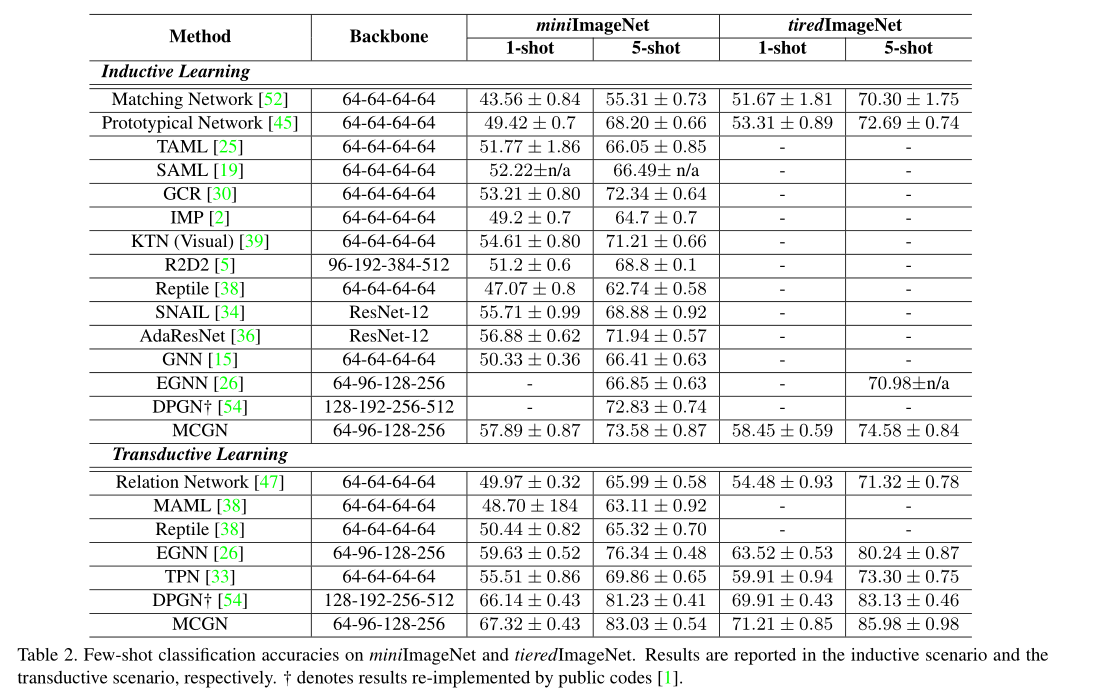
对于GNN,CRF提供了有价值的关联信息。对于CRF,GNN为推断亲和力提供了更好的特性。 实验结果表明,我们的方法在数据miniImageNet、tieredImageNet和CIFAR-FS上,在5向1-shot和5向5-shot设置上都优于最新技术。
Introduction
衡量两个样本/节点之间相似性的 亲和力是 GNN 中的关键组成部分。因此,提出了许多具有更好亲和力表示的方法。 EGNN [26] 提出利用标签进行 GNN 亲和力初始化,并传播边缘标签以显式建模集群内相似性和集群间相异性。DPGN [53] 建议将分布传播与 GCN 结合起来,并将分布级关系与实例级关系结合起来。
在这方面,我们利用 CRF,这是一个强大的概率图形模型,来操纵变量之间的依赖关系,与 GNN 协作。 我们将标签建模为 CRF 中的随机变量。在我们的方法中,统一CRF模型中的边缘分布具有两个功能。首先,单变量的边缘分布反映了被标注的预测可能性。其次,成对变量的边缘概率定义了两个样本的相似度,即GNN的亲和度。我们设计的MCGN是基于以下两种对CRF和GNN的观测。
首先, 对于CRF, 通过融合特征信息和标签信息,得到单变量和成对变量的边缘概率;每个变量的一元相容性项用于对变量/样本与相应观察到的标签信息之间的关系进行建模。二元兼容性术语利用特征信息。具体来说,它对两个随机变量/样本之间的关系进行建模,并由两个对应的随机变量/样本的特征相似性直观地定义。由于在 CRF 中边缘化变量的状态需要乘以一元和二元兼容性项,因此边缘分布以有原则和概率的方式融合了特征信息和标签信息。
其次,对于 GNN,它的亲和力应该由标签空间中的概率来定义,反映两个样本属于同一类的可能性。与确定特征空间中成对亲和力的典型 GNN 不同,例如使用特征的相似性, 通过标签空间中的概率确定亲和力有两个优点。
- 首先,标签空间中定义的亲和力对异常值不太敏感。以两个视觉上相似但属于不同类别的样本为例。当使用特征相似度来确定亲和力时,它们的亲和力可能很大,这会导致两个样本之间的特征聚合不当。然而,这种亲和力可以在标签空间中减少,因为它额外受到提供的语义标签的引导,即两个样本具有不同的类标签。
- 其次, 支持集中给出的标签可以以概率而不是确定的方式指导亲和力。与根据相应标签将亲和度初始化为零或一的 EGNN 和 DPGN 不同, CRF 中的一元兼容性项可以为错误标记的样本设置容差,这使得我们的分类比原始的基于 GNN 的模型更稳健。
考虑到上述观察结果,我们提出了一个名为 Mutual CRF-GNN (MCGN) 的统一模型,其中 GNN 和 CRF 相互关联并且可以相互贡献。该网络由多个层组成,每一层交替实现基于 CRF 的亲和推理和基于 GNN 的特征聚合。
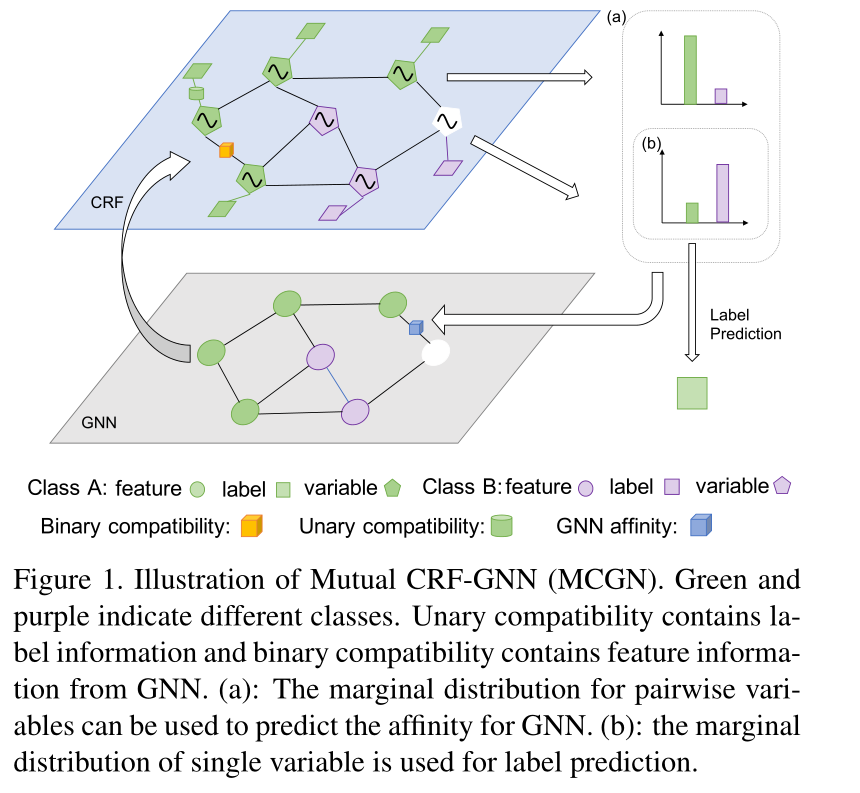
如图 1 所示,我们使用 GNN 中的特征来定义 CRF 中的二元兼容性。接下来,通过一元和二元兼容性,我们估计每个变量的边际分布。之后,获得的每个变量的边际分布推断 GNN 中的亲和力。最后,通过 GNN 中的聚合获得更鲁棒的特征,这进一步导致在下一个 CRF 层中具有更好的兼容性。 在这样的前馈过程中, CRF 产生更好的亲和力,具有由 GNN 中的稳健特征定义的兼容性,而 GNN 通过采用 CRF 推断的亲和力来产生稳健的特征。
Contributions
- 首先,我们提出将 CRF 引入 GNN,其中 CRF 有助于实现预测之间的依赖关系并定义 GNN 在标签空间中的亲和力。
- 其次,我们提出了一种新颖的 Mutual CRF-GNN,其中特征聚合和关系推理可以相互促进。
- 在三个流行的数据集上进行的大量实验证明了 Mutual CRF-GNN 的有效性,因为它显着提高了小样本分类精度。
Method
1、GNN
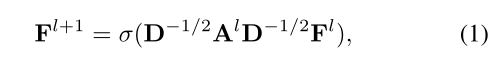
通常,亲和力 A 通常由节点特征计算,因此可能不是最优的,原因有两个:
(1) 它只对成对信息进行建模,而忽略了 GNN 中的相邻信息。
(2) 在计算 A 时,它仅利用特征信息,但不包含语义信息,即标签。
2、将CRF引入GNN
条件随机场(CRF)是一类常用于结构化预测的统计建模方法。为了产生考虑上下文的亲和力 𝐴𝑙,我们利用 CRF 中每个随机变量的边际分布来计算所有 GNN 层中的亲和力。与利用特征估计亲和力的传统 GNN 相比,使用随机变量的边际分布带来了三个优势:
- 首先,边际分布考虑了上下文,而特征只描述了个人信息。
- 其次,边际分布将特征相似性(二元兼容性)和支持样本的语义标签(一元兼容性)合并为一个统一的量。
- 最后,边缘分布的空间受到标签空间的限制。当用于估计亲和力时, 边际分布可以帮助明确说明两个样本是否属于同一类,而不是在典型的 GNN 中两个特征是否相似。

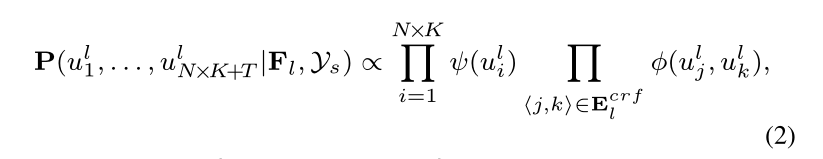
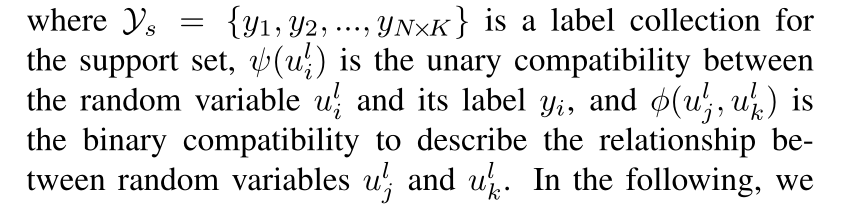
下面,我们首先介绍 CRF 中的两个兼容性函数,然后描述估计下一层 GNN 的边际分布 𝑃(𝑢𝑖𝑙|𝐹𝑙,𝑦𝑠) 和亲和度 𝐴𝑙 的细节。
2.1 一元兼容性 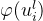
一元相容性是描述支持样本的变量𝑢𝑖𝑙与其对应观察值之间的关系:
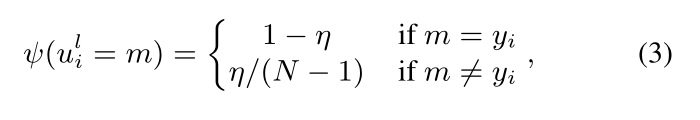
其中η = 0.3是一个小的正值,它是 随机变量取错误标签时的概率容差。
2.2 二元兼容性 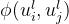
描述连接的随机变量 ulj 和 ulk 之间的关系:
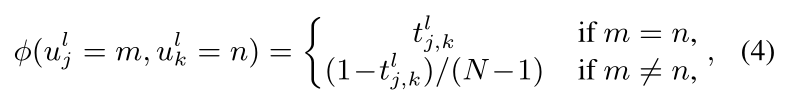
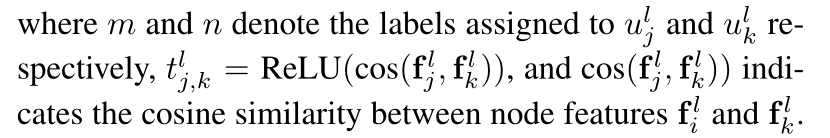
2.3 边缘分布 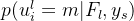
为了合并其他变量的状态,我们在 Eq.2 中边缘化除 uli 之外的所有随机变量,并通过下式推导出边际分布:
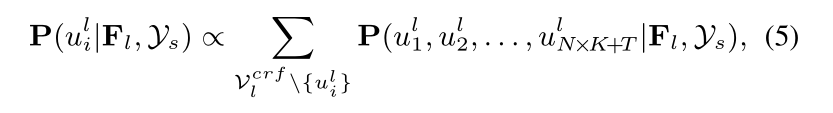
其中 P(uli = m|Fl, Ys) 描述了在考虑除 uil 之外的随机变量的所有可能状态后, 样本 i 被分配标签 m 的概率。
2.4 亲和矩阵A
由于边际分布 P(uli|Fl, Ys) 整合了 CRF 中的上下文信息和支持样本的标签信息,我们可以使用边际分布来估计语义亲和度矩阵 Al。更具体地说,𝑓𝑖𝑙 和 𝑓𝑗𝑙之间的关系 _^_𝑎𝑖𝑗𝑙 可以定义为样本 i 和 j 属于同一类的可能性。在数学上,它可以通过概率加法定理计算:
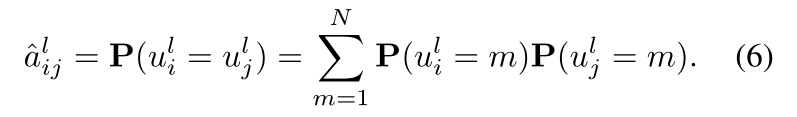
在EGNN[26]中实现后,我们将关系ˆalij通过其邻近关系聚合,得到GNN的最终亲和力:k是i的邻居。
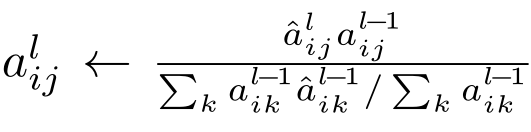
3、相互CRF-GNN
3.1 初始化
对于支持集和查询集中的图像,利用基于cnn的特征提取器femb提取原始特征𝐹1,即:
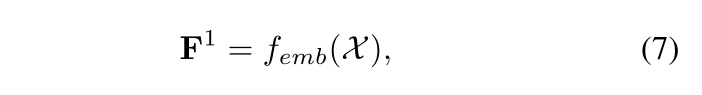
其中X = S∪Q包含了一个任务中的所有样本。GNN中初始的亲和矩阵𝐴0由支持集中的 语义标签初始化,即:

3.2 MCGN前向传播
给定原始特征𝐹1和初始化的亲和矩阵𝐴0,通过MCGN变换最终用于分类的特征𝐹𝐿+1,进行L迭代。我们描述了MCGN的详细过程,其中CRF和GNN可以相互帮助,在小样本学习中提取区别特征。
对于第l层,整个过程可以分为4个步骤:
Step1 :
给定第 (l-1) 次迭代的亲和力 Al−1 和输出特征𝐹𝑙,我们通过等式 3、4估计 CRF 中的一元和二元兼容性。估计的兼容性函数定义了 CRF 中两个连接的随机变量之间的亲和力。
Step2 :
CRF 中随机变量的边际分布(方程 5)是通过循环置信传播 [37] 推断的,使用从步骤 1 获得的兼容性函数和支持集中的样本标签。
Step 3 :
GNN 中的亲和度 𝐴𝑙 是由方程 6 在步骤 2 中获得的边缘分布得出的。
Step4 :
第 l 次迭代的输出特征 𝐹𝑙+1 是通过用 Eq1 聚合它们的相邻特征来计算的,𝐴𝑙 作为它们的权重。
我们逐层重复上述过程进行 L 次迭代,得到最终输出 FL+1 和亲和矩阵 AL 用于网络优化和推理。
4、训练和测试
4.1 训练
我们同时监督 GNN 和 CRF 的输出。特别是,GNN 由亲和力 𝐴𝑙 上的验证损失 𝐿𝑔𝑛𝑛 监督,而 CRF 可以由边缘分布上的交叉熵损失监督。这是因为边际分布 P(uli|Fl, Y0) 表示为 N 维向量 (pli,0, pli,1, …, pli,N ),而 𝑝𝑖𝑗𝑙 表示 𝑢𝑖𝑙 分配给标签 _j_的可能性,本质上是一个分类问题。
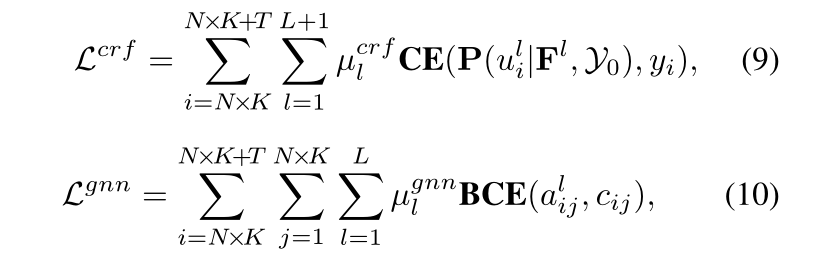

4.2 测试
每个样本的类别可以通过其最终的边际分布来推断。我们取可以最大化边际分布的标签:
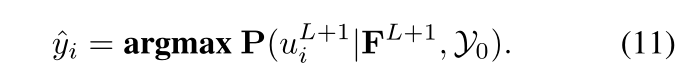
实验
Original: https://blog.csdn.net/qq_29260257/article/details/122406124
Author: 一只瓜皮呀
Title: 【阅读笔记】Mutual CRF-GNN for Few-shot Learning
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/700683/
转载文章受原作者版权保护。转载请注明原作者出处!