

使用pandas库进行数据分析教学
文章目录
1、pandas介绍
Pandas 是python的一个数据分析包
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。
Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
pandas可以读取/写入txt、dox、excal、csv等文件,原理都一样,深度学习通常使用csv文件。
2、csv文件介绍
其文件以纯文本形式存储表格数据(数字和文本)。
纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。
即csv可以用txt编写,在txt中每一行输入若干数据,每个数据用逗号隔开,一行数据结束后换行写下一行,转成csv文件后打开后风格和excal一样。
效果如图:
txt文件数据:
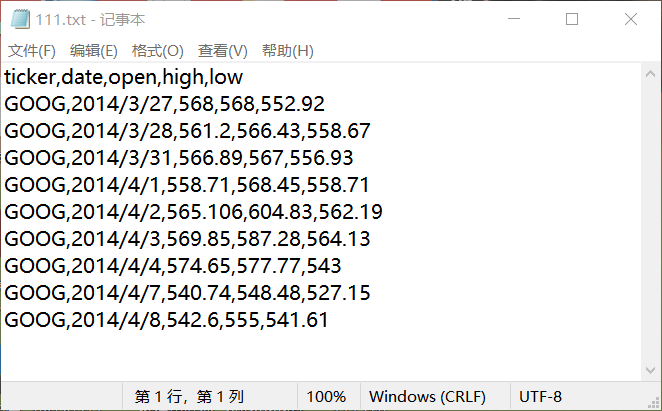

csv文件数据:
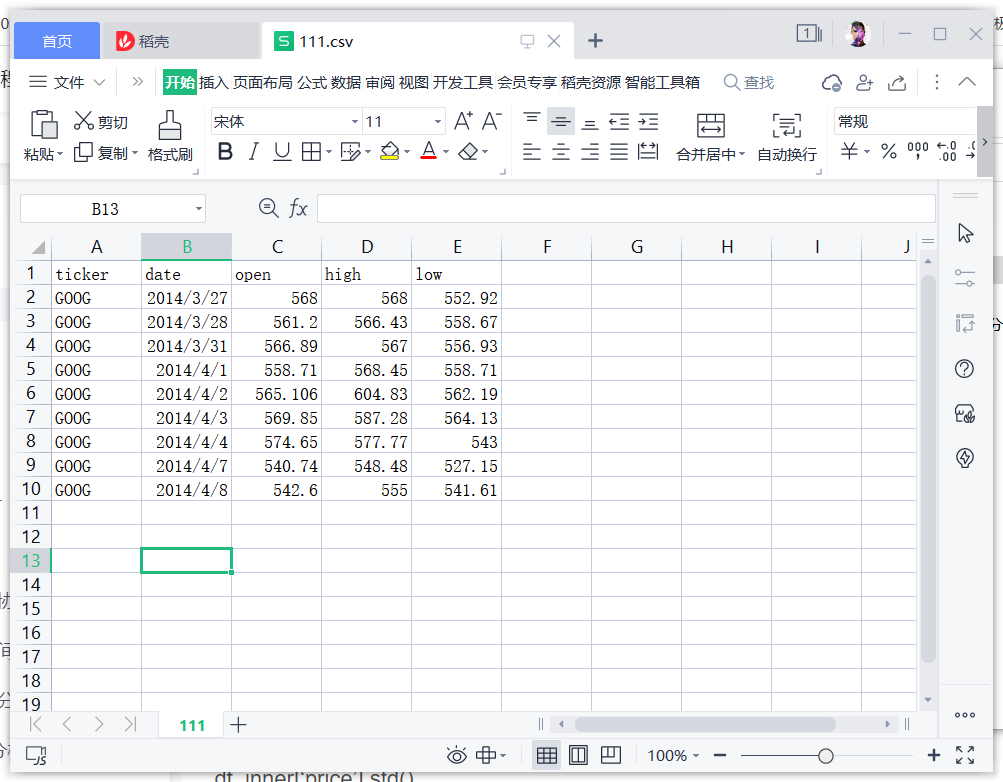
; 3、pandas常用操作csv
(1)pandas读入csv操作
就一个函数:pandas.read_csv(…)
将 CSV 文件读入 pandas DataFrame
import pandas
df = pandas.read_csv(r'C:\Users\zhaohaobing\Desktop\pythond的pandas数据分析\111.csv',
index_col='Employee',
parse_dates=['Hired'],
sep = ',',
header=0,
encoding="utf-8",
names=['Employee', 'Hired','Salary', 'Sick Days'])
df.to_csv('hrdata_modified.csv')
print(df)
重要:
1)header第一行的设置:
header=0(将首行设为列名);header=None,则首行最为数据,那么names第一行标题必须制定!
2)列名的设置:
names=[‘Employee’, ‘Hired’,’Salary’, ‘Sick Days’] #修改第一行列名
3)索引列的设置:
若不设置,默认最前一列加上0,1,2,3…;index_col=’Employee’ #将Employee列为索引
效果:
(2)常用参数解释:read_csv与read_table常用的参数(更多参数查看官方手册)
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
filepath_or_buffer
sep / delimiter 列分隔符,普通文本文件,应该都是使用结构化的方式来组织,才能使用dataframe
header header=0(将首行设为列名);header=None,则首行最为数据,那么names第一行标题必须制定!
shkiprows= 10
nrows = 10
usecols=[0,1,2,...]
parse_dates = ['col_name']
index_col = None /False /0,重新生成一列成为index值,0表示第一列,用作行索引的列编号或列名。可以是单个名称/数字或由多个名称/数宇组成的列表(层次化索引)
error_bad_lines = False
na_values = 'NULL'
encoding='utf-8'
(3)csv处理操作
列举几个常用的,保证能入门
常用的操作:
df['新一列']='new'
df.fillna(value=0,inplace=True)
df['0']=df['0'].map(str.strip)
df['0']=df['0'].str.lower()
df.drop_duplicates(['0'],inplace=True)
df['0'].replace('111','222',inplace=True)
df_inner.to_excel('excel_to_python.xlsx', sheet_name='bluewhale_cc')
df_inner.to_csv('excel_to_python.csv')
df.to_sql(table_name, connection_object)
df.to_json("filename")
常用查看打印:
print(df.head(3))
print(df.tail(3))
print(df.shape)
print(df.info())
print(df.dtypes)
print(df_inner.groupby('city').count())
print(df_inner.groupby('city')['id'].count())
print(df_inner.groupby(['city','price'])['id'].count())
print(df_inner.groupby('city')['price'].agg([len,np.sum, np.mean]) )
print(df_inner.loc[(df_inner['age'] > 25) & (df_inner['city'] == 'shanghai'), ['id','city','age','category','gender']])
print(df_inner.loc[(df_inner['age'] > 25) | (df_inner['city'] == 'shanghai'), ['id','city','age','category','gender']] )
print(df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']])
print(df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].city.count())
print(df_inner.query('city == ["beijing", "shanghai"]'))
print(df_inner.query('city == ["Shenzhen", "shanghai"]').price.sum())
常用数据统计:
print(df_inner.sample(n=3))
weights = [0, 0, 0, 0.5, 0.5, 0.5]
print(df_inner.sample(n=2, weights=weights))
print(df_inner.sample(n=6, replace=False))
print(df_inner.sample(n=6, replace=True))
print(df_inner.describe().round(2).T)
print(df_inner['price'].std())
print(df_inner['price'].cov(df_inner['m-point']))
print(df_inner.cov())
print(df_inner['price'].corr(df_inner['m-point']))
print(df.describe())
print(df.mean())
print(df.corr())
print(df.count())
print(df.max())
print(df.min())
print(df.median())
print(df.median())
4、搜指令网站
pandas了解后,就跟数据库一样,需要什么操作直接网上搜指令就行了OVER
你学会了吗?
常用指令网站:
https://www.cnblogs.com/zhuminghui/p/9401489.html
Original: https://blog.csdn.net/zhaohaobingniu/article/details/121889105
Author: zhaohaobingSUI
Title: 用python玩转办公软件(pandas数据分析)入门
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/700323/
转载文章受原作者版权保护。转载请注明原作者出处!