



点击关注,桓峰基因
桓峰基因
生物信息分析,SCI文章撰写及生物信息基础知识学习:R语言学习,perl基础编程,linux系统命令,Python遇见更好的你
92篇原创内容
公众号
; 桓峰基因的教程不但教您怎么使用,还会定期分析一些相关的文章,学会教程只是基础,但是如果把分析结果整合到文章里面才是目的,觉得我们这些教程还不错,并且您按照我们的教程分析出来不错的结果发了文章记得告知我们,并在文章中感谢一下我们哦!
公司英文名称:Kyoho Gene Technology (Beijing) Co.,Ltd.
机器学习方法中的K-邻近算法,这种方法在做肿瘤诊断中,尤其是乳腺癌表现强健,有几篇文章都是利用这种方法,另外在CT images这方面也是应用广泛,下面就说说KNN这种算法在生物医学方面的应用!
前 言
什么是k近邻?一种机器学习对数据分类算法。算法驱动着机器学习的世界。他们经常因其预测能力而受到赞扬,被认为是消耗大量数据来产生即时结果的勤奋工作者。其中,有一种算法经常被贴上懒惰的标签。但在对数据点进行分类时,它是一个出色的执行者。它被称为k近邻算法,经常被认为是最重要的机器学习算法之一。k-近邻(KNN k-nearest neighbors)算法是一种数据分类方法,它根据与某个数据点最接近的数据点所属的组来估计该数据点成为某一组成员的可能性。k近邻算法是一种用于解决分类和回归问题的监督机器学习算法。然而,它主要用于分类问题。KNN是一种懒惰学习的非参数算法。它被称为懒惰学习算法或懒惰学习者因为当你提供训练数据时,它不执行任何训练。相反,它只是在训练期间存储数据,而不执行任何计算。在对数据集执行查询之前,它不会构建模型。这使得KNN成为数据挖掘的理想选择。

; 基本原理
K-邻近算法是一种非参数方法,因为它对底层数据分布不做任何假设。简单地说,KNN试图通过查看周围的数据点来确定一个数据点属于哪个组。假设有两组,A和B。为了确定一个数据点是在A组还是在B组,算法会查看它附近数据点的状态。如果大多数数据点在A组,那么很有可能问题中的数据点在A组,反之亦然。简而言之,KNN通过查看最近的带注释的数据点(也称为最近的邻居)对数据点进行分类。不要混淆K-NN分类和K-means聚类。KNN是一种监督分类算法,它基于最近的数据点对新的数据点进行分类。另一方面,K-means聚类是一种无监督聚类算法,它将数据分组成K个簇。
KNN是如何工作的?
如前所述,KNN算法主要用作分类器。让我们看看KNN是如何对不可见的输入数据点进行分类的。与人工神经网络分类不同,k近邻分类易于理解和实现。在数据点定义明确或非线性的情况下,它是理想的。本质上,KNN执行一种投票机制来确定一个不可见观察的类别。这意味着获得多数投票的类将成为所讨论数据点的类。如果K的值等于1,那么我们将只使用最近的邻居来确定一个数据点的类别。如果K的值等于10,那么我们就用10个最近的邻居,以此类推。k近邻算法伪代码使用Python和R等编程语言实现KNN算法。下面是KNN的伪代码:
- 加载数据选择K值对于数据中的每个数据点;
- 计算到所有训练数据样本的欧氏距离将距离存储在一个有序列表中并对其排序从排序列表中选择前K个条目根据所选点中存在的大多数类给测试点标号结束。
为了验证KNN分类的准确性,使用了混淆矩阵。其他统计方法如似然比检验也被用于验证。在KNN回归的情况下,大部分步骤是相同的。将计算邻居值的平均值并将其分配给未知数据点,而不是分配投票数最高的类。
为什么使用KNN算法?
分类是数据科学和机器学习中的一个关键问题。KNN是用于模式分类和回归模型的最古老而精确的算法之一。
信用评级: KNN算法通过与具有相似特征的人进行比较,帮助确定个人的信用评级。
贷款审批: 与信用评级类似,k近邻算法有利于通过比较相似个体的特征来识别更有可能拖欠贷款的个体。
数据预处理: 数据集可能有许多缺失的值。KNN算法用于一种称为缺失数据估算的过程,用来估计缺失值。
模式识别: KNN算法识别模式的能力创造了广泛的应用。例如,它帮助检测信用卡使用模式和发现不寻常的模式。模式检测在识别客户购买行为中的模式方面也很有用。
股票价格预测: 由于KNN算法具有预测未知实体的价值的能力,它在根据历史数据预测股票未来价值方面很有用。
推荐系统: 由于KNN可以帮助寻找具有相似特征的用户,所以可以用于推荐系统。例如,它可以用于在线视频流平台,通过分析类似用户观看的内容,建议用户更可能观看的内容。
计算机视觉:使用KNN算法对图像进行分类。由于它能够对相似的数据点进行分组,例如将猫归为一类,而将狗归为不同的一类,因此它在一些计算机视觉应用中很有用。
如何选择K的最优值?
没有具体的方法来确定最佳K值,也就是KNN中邻居的数量。这意味着在决定使用哪个值之前,您可能需要对一些值进行试验。一种方法是考虑(或假装)训练样本的一部分是”未知的”。然后,您可以使用k近邻算法对测试集中的未知数据进行分类,并通过与训练数据中已有的信息进行比较来分析新的分类有多好。当处理两个类的问题时,最好为k选择一个奇数值,否则,可能会出现每个类的邻居数量相同的情况。同样,K的值不能是当前类数量的倍数。选择K的最优值的另一种方法是计算根号N,其中N表示训练数据集中的样本个数。然而,K值较低,如K=1或K=2,可能是有噪声的,并受到异常值的影响。在这种情况下,过拟合的可能性也很高。另一方面,K值越大,在大多数情况下会产生更平滑的决策边界,但它不应该太大。否则,数据点较少的组总是会被其他组击败。另外,更大的K在计算上很昂贵。使用KNN算法最显著的优点之一是不需要建立模型或调整多个参数。由于这是一个懒惰的学习算法,而不是一个渴望学习的算法,所以不需要对模型进行训练;相反,所有的数据点都是在预测时使用的。当然,这在计算上是非常昂贵和耗时的。但是如果你有必要的计算资源,你可以使用KNN来解决回归和分类问题。尽管如此,有一些更快的算法可以产生准确的预测。
KNN回归的优势和局限性
与KNN分类(或任何对此的预测算法)一样,KNN回归既有优势也有劣势。
优点: k近邻回归是一种简单、直观的算法,不需要对数据必须是什么样子进行假设,并且适用于非线性关系(即,如果关系不是直线)。
缺点: k近邻回归会随着训练数据的增大而变得非常缓慢,在大量的预测因子下可能表现不佳,在你的训练数据中输入的值范围之外可能无法很好地预测。
实例解析
本文叙述了线性规划在医学上的两个应用。具体来说,利用基于线性规划的机器学习技术,提高乳腺癌诊断和预后的准确性和客观性。首次应用于乳腺癌诊断利用单个细胞的特征,从微创细针抽吸获得,以区分乳腺肿块的良恶性。这使得不需要手术活检就能做出准确的诊断。威康森大学医院目前运行的诊断系统对569例患者的样本进行了培训,对131例后续患者的诊断具有100%的时间正确性。第二个应用,最近已经投入临床实践,是一种构建一个表面的方法,可以预测肿瘤切除后乳腺癌何时可能复发。这为医生和患者提供了更好的信息来计划治疗,并可能消除对预后外科手术的需要。预测方法的新特点是能够处理癌症没有复发的病例(审查数据)以及癌症在特定时间复发的病例。该预后系统的预期误差为13.9 ~ 18.3个月,优于其他可用技术的预后准确性。

; 1. 软件安装
这里我们主要使用kknn和class两个软件包,其他都为数据处理过程中需要使用软件包,如下:
if (!require(caret)) install.packages("caret")
if (!require(sampling)) install.packages("sampling")
if (!require(tidyverse)) install.packages("tidyverse")
if (!require(class)) install.packages("class")
if (!require(kknn)) install.packages("kknn")
library(class)
library(caret)
library(sampling)
library(ggplot2)
library(tidyverse)
library(kknn)
2. 数据读取
数据来源《机器学习与R语言》书中,具体来自UCI机器学习仓库。地址:http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/ 下载wbdc.data和wbdc.names这两个数据集,数据经过整理,成为面板数据。查看数据结构,其中第一列为id列,无特征意义,需要删除。第二列diagnosis为响应变量,字符型,一般在R语言中分类任务都要求响应变量为因子类型,因此需要做数据类型转换。剩余的为预测变量,数值类型。查看数据维度,568个样本,32个特征(包括响应特征)。
BreastCancer <- 0 1 2 3 4 5 25 32 94 130 211 357 386 477 568 742 1203 1297 1326 1575 1709 1956 8670 842517 843786 844359 844981 845636 869222 906157 8825022 30423820 84300903 84348301 84358402 84458202 84501001 read.csv("wisc_bc_data.csv", stringsasfactors="FALSE)" summary(breastcancer)[, 1:4] ## id diagnosis radius_mean texture_mean min. : length:568 6.981 9.71 1st qu.: class :character qu.:11.697 qu.:16.18 median mode :13.355 :18.86 mean :14.120 :19.31 3rd qu.:15.780 qu.:21.80 max. :911320502 :28.110 :39.28 str(breastcancer) 'data.frame': obs. of variables: $ int ... chr "m" num 20.6 19.7 11.4 20.3 12.4 17.8 21.2 20.4 14.3 15.7 perimeter_mean 132.9 77.6 135.1 82.6 area_mean smoothness_mean 0.0847 0.1096 0.1425 0.1003 0.1278 compactne_mean 0.0786 0.1599 0.2839 0.1328 0.17 concavity_mean 0.0869 0.1974 0.2414 0.198 0.1578 concave_points_mean 0.0702 0.1279 0.1052 0.1043 0.0809 symmetry_mean 0.181 0.207 0.26 0.209 fractal_dimension_mean 0.0567 0.06 0.0974 0.0588 0.0761 radius_se 0.543 0.746 0.496 0.757 0.335 texture_se 0.734 0.787 1.156 0.781 0.89 perimeter_se 3.4 4.58 3.44 5.44 2.22 area_se 74.1 27.2 94.4 smoothness_se 0.00522 0.00615 0.00911 0.01149 0.00751 compactne_se 0.0131 0.0401 0.0746 0.0246 0.0335 concavity_se 0.0186 0.0383 0.0566 0.0569 0.0367 concave_points_se 0.0134 0.0206 0.0187 0.0188 0.0114 symmetry_se 0.0139 0.0225 0.0596 0.0176 0.0216 fractal_dimension_se 0.00353 0.00457 0.00921 0.00511 0.00508 radius_worst 23.6 14.9 22.5 15.5 texture_worst 23.4 25.5 26.5 16.7 23.8 perimeter_worst 158.8 152.5 98.9 152.2 103.4 area_worst smoothness_worst 0.124 0.144 0.21 0.137 0.179 compactne_worst 0.187 0.424 0.866 0.205 0.525 concavity_worst 0.242 0.45 0.687 0.4 0.535 concave_points_worst 0.186 0.243 0.258 0.163 0.174 symmetry_worst 0.275 0.361 0.664 0.236 0.399 fractal_dimension_worst: 0.089 0.0876 0.173 0.0768 0.1244 breastcancer[1:5, 1:5] m 20.57 17.77 132.90 19.69 21.25 130.00 11.42 20.38 77.58 20.29 14.34 135.10 12.45 15.70 82.57 dim(breastcancer) #查看数据维度,568个样本,32个特征(包括响应特征)。 [1] table(breastcancer$diagnosis) b sum(is.na(data)) #查看数据缺失情况,发现无数据缺失,不需要做缺失值填补。 < code></->
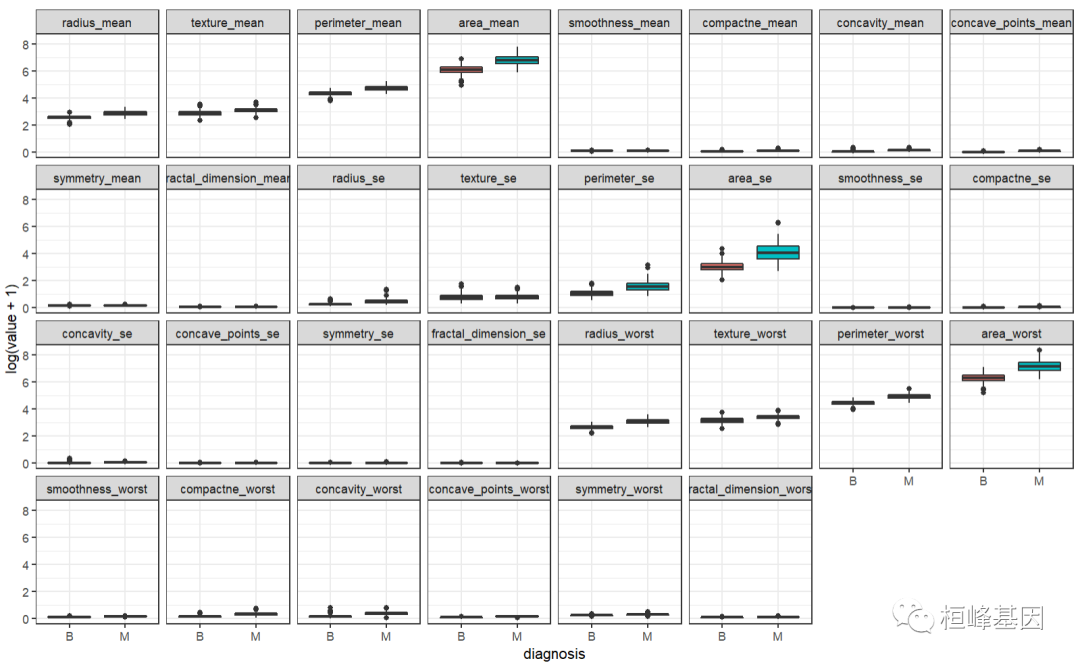
数据分布比较恶性和良性之间的差距,如下:
library(reshape2)
bc <- 1 2 3 4 5 6 breastcancer[, -1] bc.melt <- melt(bc, id.var="diagnosis" ) head(bc.melt) ## diagnosis variable value m radius_mean 20.57 19.69 11.42 20.29 12.45 18.25 ggplot(data="bc.melt," aes(x="diagnosis," y="log(value" + 1), fill="diagnosis))" geom_boxplot() theme_bw() facet_wrap(~variable, ncol="8)" < code></->
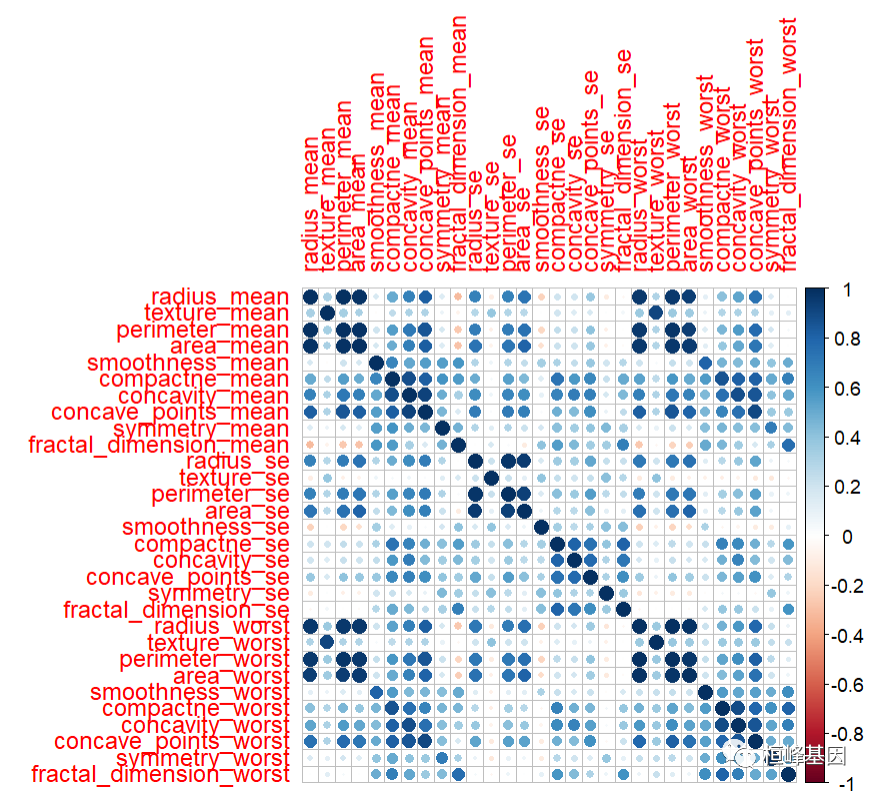
数据变量之间的相关性,如下:
library(tidyverse)
data <- select(breastcancer, -1) %>%
mutate_at("diagnosis", as.factor)
data[1:5, 1:5]
## diagnosis radius_mean texture_mean perimeter_mean area_mean
## 1 M 20.57 17.77 132.90 1326.0
## 2 M 19.69 21.25 130.00 1203.0
## 3 M 11.42 20.38 77.58 386.1
## 4 M 20.29 14.34 135.10 1297.0
## 5 M 12.45 15.70 82.57 477.1
corrplot::corrplot(cor(data[, -1]))
</->
将原始数据分割成训练数据和测试数据,测试数据不参与训练建模,将根据模型在测试数据中的表现来选择最优模型参数。
一般做数据分割会留70%的训练数据和30%的测试数据,当然这个比例可以更改,但是一般是训练数据要大于测试数据,用来保证模型学习的充分性。
此外,在做分类任务时,有一个需要额外考虑的问题就是需要尽可能保证训练数据和测试数据中正负样本的比例相近。这里采用「分层抽样」来完成这个任务。
数据分割
library(sampling)
set.seed(123)
每层抽取70%的数据
train_id <- strata(data, "diagnosis", size="rev(round(table(data$diagnosis)" * 0.7)))$id_unit # 训练数据 train_data <- data[train_id, ] 测试数据 test_data data[-train_id, < code></->
可以检查一下数据分割后是否保证了训练数据和测试数据中正负样本比例相同
查看训练、测试数据中正负样本比例
prop.table(table(train_data$diagnosis))
##
## B M
## 0.6281407 0.3718593
prop.table(table(test_data$diagnosis))
##
## B M
## 0.6294118 0.3705882
3. K-邻近法
在R语言中,knn建模有多个包可以选择,常用的机器学习包是caret,集成了很多常用的机器学习算法。参数选择,如下:
- 通过trainControl函数设置10折交叉训练,并传入到trControl参数中;
- 通过preProcess参数设置训练数据标准化处理;
- 通过tuneLength参数设置k取值个数,模型以此进行参数网格搜索调优。
- 模型训练评价指标,分类问题默认为准确率。
基于数据训练模型
library(class)
k = ceiling(sqrt(568)) # 参数取24是因为训练的样本有568个,开根后是24
k
## [1] 24
knn.pred = knn(train = train_data[, -1], test = test_data[, -1], cl = train_data$diagnosis,
k = k)
评估模型的性能
library(gmodels)
CrossTable(x = test_data$diagnosis, y = knn.pred, dnn = c("Actual", "Predicted"),
prop.chisq = FALSE)
##
##
## Cell Contents
## |-------------------------|
## | N |
## | N / Row Total |
## | N / Col Total |
## | N / Table Total |
## |-------------------------|
##
##
## Total Observations in Table: 170
##
##
## | Predicted
## Actual | B | M | Row Total |
## -------------|-----------|-----------|-----------|
## B | 105 | 2 | 107 |
## | 0.981 | 0.019 | 0.629 |
## | 0.921 | 0.036 | |
## | 0.618 | 0.012 | |
## -------------|-----------|-----------|-----------|
## M | 9 | 54 | 63 |
## | 0.143 | 0.857 | 0.371 |
## | 0.079 | 0.964 | |
## | 0.053 | 0.318 | |
## -------------|-----------|-----------|-----------|
## Column Total | 114 | 56 | 170 |
## | 0.671 | 0.329 | |
## -------------|-----------|-----------|-----------|
##
##
4.K值选择
查看训练好的模型,可知模型的准确率都超过了95%,且最优模型的k值为4。
library(caret)
## knn模型训练
control <- 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 30 398 traincontrol(method="cv" , number="10)" grid1 <- expand.grid(.k="seq(2," 24, by="1))" model train(diagnosis ~ ., train_data, method="knn" trcontrol="control," preprocess="c("center"," "scale"), tunelength="5," tunegrid="grid1)" ## k-nearest neighbors samples predictor classes: 'b', 'm' pre-processing: centered (30), scaled (30) resampling: cross-validated (10 fold) summary of sample sizes: 358, ... resampling results across tuning parameters: k accuracy kappa 0.9321795 0.8544397 0.9599359 0.9129545 0.9574359 0.9078316 0.9648718 0.9239508 0.9673718 0.9293581 0.9698718 0.9346212 0.9624359 0.9182138 0.9598718 0.9125553 0.9182157 0.9124011 0.9573718 0.9065325 was used to select the optimal using largest value. final value for < code></->
无论从结果,还是图形上都可以看出,当K=4时,准确率最高,如下:
plot(model$results$k, model$results$Accuracy, type = "l", xlab = "K", ylab = "Accuracy",
lwd = 2)
points(model$results$k, model$results$Accuracy, col = "red", pch = 20, cex = 2)
abline(v = 4, col = "grey", lwd = 1.5)
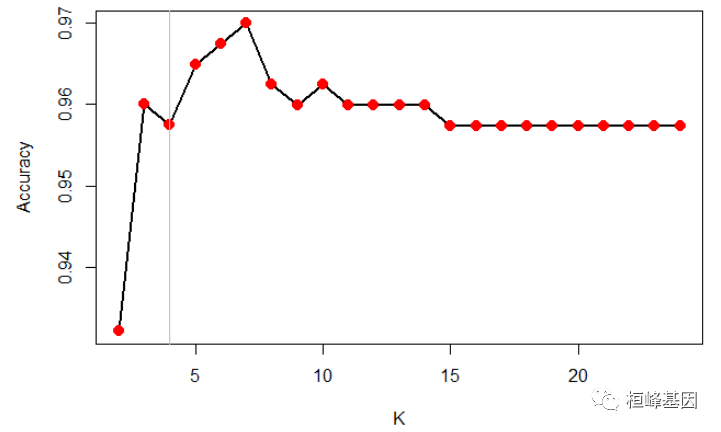
报告显示当k=4时Kappa统计量(用于测量两个分类器对观测值分类的一致性)值最高。
下面我们利用k=4重新训练模型:
library(class)
knn.pred_new = knn(train = train_data[, -1], test = test_data[, -1], cl = train_data$diagnosis,
k = 4)
install.packages('crosstable')
library(gmodels)
CrossTable(x = test_data$diagnosis, y = knn.pred_new, dnn = c("Actual", "Predicted"),
prop.chisq = FALSE)
##
##
## Cell Contents
## |-------------------------|
## | N |
## | N / Row Total |
## | N / Col Total |
## | N / Table Total |
## |-------------------------|
##
##
## Total Observations in Table: 170
##
##
## | Predicted
## Actual | B | M | Row Total |
## -------------|-----------|-----------|-----------|
## B | 102 | 5 | 107 |
## | 0.953 | 0.047 | 0.629 |
## | 0.936 | 0.082 | |
## | 0.600 | 0.029 | |
## -------------|-----------|-----------|-----------|
## M | 7 | 56 | 63 |
## | 0.111 | 0.889 | 0.371 |
## | 0.064 | 0.918 | |
## | 0.041 | 0.329 | |
## -------------|-----------|-----------|-----------|
## Column Total | 109 | 61 | 170 |
## | 0.641 | 0.359 | |
## -------------|-----------|-----------|-----------|
##
##
5. 模型预测
利用训练好的模型,可以对测试数据进行预测,来检验模型的性能。一般通过混淆矩阵来评估分类模型的性能,通过confusionMatrix函数实现。
测试数据真实值
truth <- 0 8 55 107 test_data$diagnosis # 测试数据预测值 pred <- predict(model, newdata="test_data)" 计算混淆矩阵 confusionmatrix(table(pred, truth)) ## confusion matrix and statistics truth b m accuracy : 0.9529 95% ci (0.9094, 0.9795) no information rate 0.6294 p-value [acc> NIR] : < 2e-16
##
## Kappa : 0.8964
##
## Mcnemar's Test P-Value : 0.01333
##
## Sensitivity : 1.0000
## Specificity : 0.8730
## Pos Pred Value : 0.9304
## Neg Pred Value : 1.0000
## Prevalence : 0.6294
## Detection Rate : 0.6294
## Detection Prevalence : 0.6765
## Balanced Accuracy : 0.9365
##
## 'Positive' Class : B
##
</->
6 .加权KNN
1.样本不平衡容易导致结果错误
如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
改善方法:对此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。2.计算量较大
因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
改善方法:事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
该方法比较适用于样本容量比较大的类域的分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
加权KNN算法:采用Gaussian函数进行不同距离的样本的权重优化,当训练样本与测试样本距离↑,该距离值权重↓。给更近的邻居分配更大的权重(你离我更近,那我就认为你跟我更相似,就给你分配更大的权重),而较远的邻居的权重相应地减少,取其加权平均。那么我们就采用加权KNN,优化模型,如下:
## 加权KNN
library(fmsb)
install.packages('fmsb')
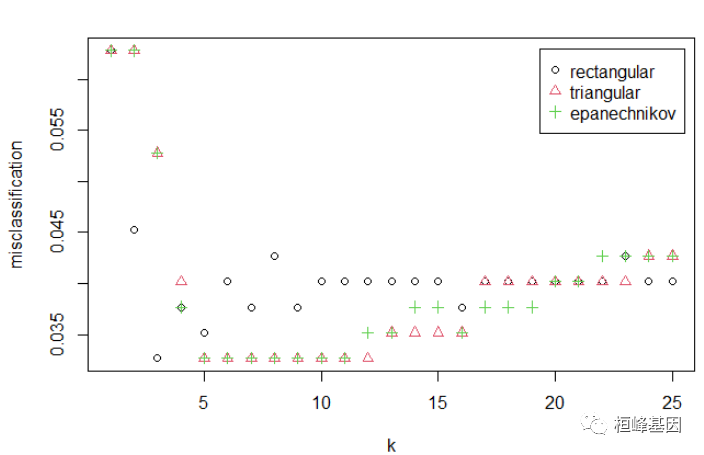
mytable <- 3 5 7 56 95 102 table(knn.pred_new, test_data$diagnosis) mytable ## knn.pred_new b m kappa.test(mytable, conf.level="0.95)" $result estimate cohen's kappa statistics and test the null hypothesis that extent of agreement is same as random (kappa="0)" data: z="10.272," p-value < 2.2e-16 percent confidence interval: 0.7646159 0.9307701 sample estimates: [1] 0.847693 $judgement "almost perfect agreement" set.seed(123) kknn.train <- train.kknn(diagnosis ~ ., train_data, kmax="25," distance="2," kernel="c("rectangular"," "triangular", "epanechnikov")) call: train.kknn(formula="diagnosis" data="train_data," type response variable: nominal minimal misclassification: 0.03266332 best kernel: rectangular k: plot(kknn.train) code></->
模型预测对测试集进行验证,我们加权KNN发现其准确率明显高于KNN,如下:
kknn.pred <- 1 8 55 106 predict(kknn.train, newdata="test_data[," -1]) table(kknn.pred, test_data$diagnosis) ## kknn.pred b m < code></->
结果解读
我们比较未加权和加权之后的两个模型的准确率分别为92.35%和94.71%,我们发现假阳性减少4个,总体上预测的精度还是提高到了94.71%,精度提高2个多百分点。这也就说明在对应乳腺癌的诊断上来说使用加权KNN效果更好些!
References:
-
Cover, Thomas, and Peter Hart. 1967. “Nearest Neighbor Pattern Classification.” IEEE Transactions on Information Theory 13 (1): 21–27.
-
Fix, Evelyn, and Joseph Hodges. 1951. “Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties.” USAF School of Aviation Medicine, Randolph Field, Texas.
-
Newman, D.J. & Hettich, S. & Blake, C.L. & Merz, C.J. (1998). UCI Repository of machine learning databases. Irvine, CA: University of California, Department of Information and Computer Science.
-
Mangasarian OL, Street WN, Wolberg WH. Breast cancer diagnosis and prognosis via linear programming. Operations Research. 1995; 43:570-577。
-
Michael Friendly (2002). Corrgrams: Exploratory displays for correlation matrices. The American Statistician, 56, 316–324.
-
D.J. Murdoch, E.D. Chow (1996). A graphical display of large correlation matrices. The American Statistician, 50, 178–18
Original: https://blog.csdn.net/weixin_41368414/article/details/124589507
Author: 桓峰基因
Title: MachineLearning 4. 癌症诊断方法之 K-邻近算法(KNN)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/699196/
转载文章受原作者版权保护。转载请注明原作者出处!