

AdaBoost算法(Adaptive Boosting)是一种有效而实用的Boosting算法,它以一种高度自适应的方式按顺序训练弱学习器。
针对分类问题,AdaBoost算法根据前一次的分类效果调整数据的权重,在上一个弱学习器中 分类错误的样本的权重会在下一个弱学习器中增加,分类正确的样本的权重则相应减少,并且在每一轮迭代时会向模型加入一个新的弱学习器。不断重复调整权重和训练弱学习器,直到误分类数低于预设值或迭代次数达到指定最大值,最终得到一个强学习器。
简单来说, AdaBoost算法的核心思想就是调整错误样本的权重,进而迭代升级。
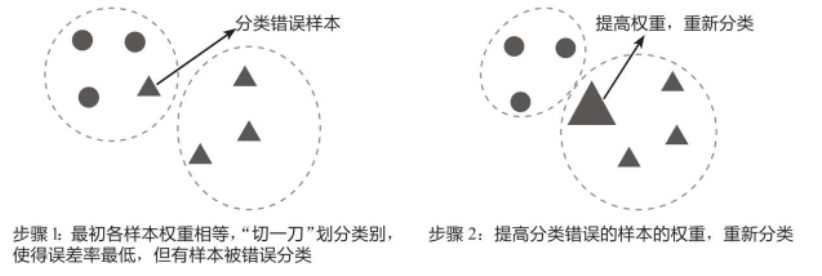
可以借助下图来理解调整权重的概念:在步骤1中先对数据进行分类,此时将小三角形错误地划分到了圆形类别中;在步骤2中调整分类错误的小三角形的权重,使它变成一个大三角形,这样它和三角形类型的数据就更加接近了,在重新分类时,它就能被准确地划分到三角形类别中。

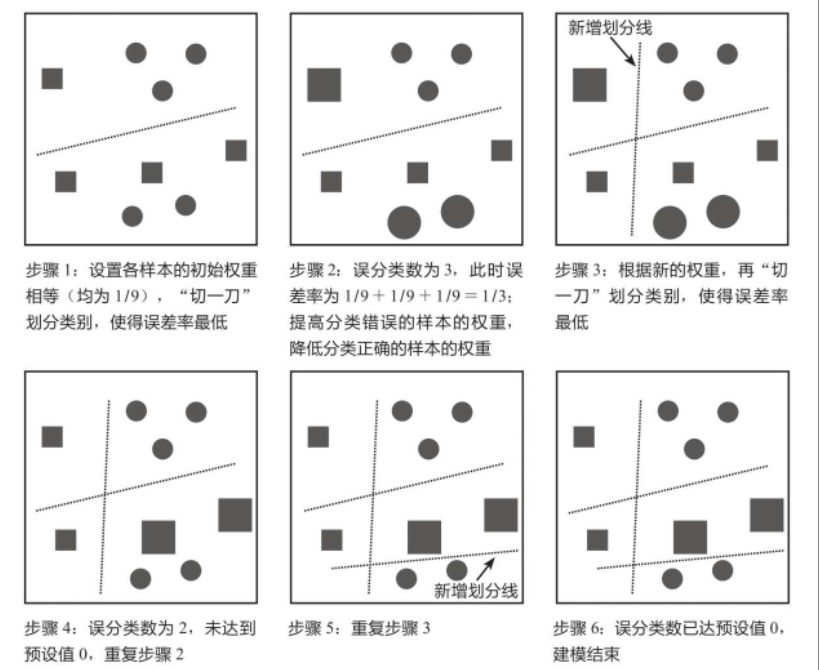
如下图所示为更复杂的AdaBoost算法示例,其核心思想和上图一致。预先设置AdaBoost算法在误分类数为0(即误差率为0)时终止迭代,误差率等于分类错误的样本的权重之和,例如,对于9个样本,每个样本的权重为1/9,若有2个样本分类错误,那么此时的误差率为1/9+1/9=2/9。
AdaBoost分类算法的流程图如下图所示。
AdaBoost算法既能做分类分析,也能做回归分析,对应的模型分别为AdaBoost分类模型(AdaBoostClassifier)和AdaBoost回归模型(AdaBoostRegressor)。
AdaBoost分类模型的弱学习器是分类决策树模型,AdaBoost回归模型的弱学习器则是回归决策树模型。
使用sklearn的基本代码如下。
from sklearn.ensemble import AdaBoostClassifier
X = [[1,2],[3,4],[5,6],[7,8],[9,10]]
y = [0,0,0,1,1]
model = AdaBoostClassifier(random_state=123)
model.fit(X,y)
model.predict([[5,5]])
输出
array([0])
4.1 模型搭建
通过如下代码读取1000条信用卡营销的客户数据,特征变量有客户的年龄、性别、月收入、月消费及月消费与月收入之比,目标变量是精准营销后客户是否响应(即客户在营销后是否办了信用卡),取值为1代表营销有效,取值为0代表营销失败。其中有400个客户响应,600个客户没有响应。
这里只是简单使用,只选取了5个特征变量,在商业实战中用到的特征变量会变得更多。
4.2 模型预测及评估
得到预测结果:y_pred是一个一维的数组。
对比预测值与实际值:
可以看到,前5行数据的预测准确度为100%。
通过如下代码可以查看所有测试集数据的预测准确度:
计算得到的score为0.85,也就是说,模型的预测准确度达85%。
表示为DataFrame展示:
绘制ROC曲线来评估模型的预测效果,代码如下。
通过如下代码计算模型的AUC值。
计算得到的AUC值为0.9559,说明预测效果很好。
为了更好地对客户进行精准营销,可以通过计算各个特征变量的特征重要性来筛选出精准营销中最重要的特征变量,代码如下。
可以看到,特征重要性最高的特征变量是”月消费”,其次是”月消费/月收入”和”月收入”,”年龄”和”性别”的特征重要性排在最后。
AdaBoost分类模型的一些参数:
《Python大数据分析与机器学习商业案例实战》
Original: https://blog.csdn.net/qq_42433311/article/details/124403452
Author: QYiRen
Title: AdaBoost模型及案例(Python)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/699008/
转载文章受原作者版权保护。转载请注明原作者出处!