

目录
一、数据结构
1、创建series
data = pd.Series([5, 4, 3, 2, 1])
data = pd.Series(np.arange(1, 6),index=['a','b','c','d','e'])
dict = {"name": "Jack", "age": 12, "sex": "male"}
data = pd.Series(dict, index=['name', "age", "sex"])
2、获取series以及切片
获取
s1[0] # 通过索引来获取
s1['name'] # 通过字典名来获取
切片获取
s1[['name','age']] # 获取键名为name和age的数据
s1[[1,3]] # 获取索引为1和3的数据
s1[1:3] # 获取范围[1,3)的数据,左闭右开
s1["name":"sex"] # 获取键名为'name'到'sex'的数据,左闭右也是闭区间
布尔索引
s1[(s1>2) | (s12 # 大于二的数据返回True,否则返回False
3、Series的基本属性
属性 说明
Series.name对象名Series.index.name对象索引名
4、读取数据
方法 描述
head()默认为前5行,可传入需要前几行的参数的数字,如head(3)前3行tail()默认为末5行,可传入需要末几行的参数的数字,如tail(3)末3行
5、DataFrame的基本属性
属性 说明
.index查看行索引.column查看列索引.values查看值.T转置矩阵.is_unique判断是否唯一.value_counts()计算每个值出现的次数.isin()
判断是否有该元素
df.isin([8,2])判断是否有8或者2。
.info()查看基本信息
6、创建DataFrame
data = np.arange(12).reshape(3, 4)
frame = pd.DataFrame(data, index=['A', 'B', 'C'], columns=['first', 'second', 'third', 'forth'])
index设置行索引,columns设置列索引
frame = pd.DataFrame({'a': pd.Series(np.arange(3)),'b': pd.Series(np.arange(3, 5))})
data = {
'a': {"apple": 3.6, "banana": 5.6},
'b': {'apple': 3, 'banana': 6},
'c': {"apple": 4.5}
}
frame = pd.DataFrame(data)
7、列的操作
df = pd.DataFrame(np.arange(9).reshape(3, 3), index=['a', 'b', 'c'], columns=['A', 'B', 'C'])
print(df['A']) # 查看列
df['D'] = [1, 2, 3] # 添加列
print(df)
del (df['D']) # 删除列
print(df)
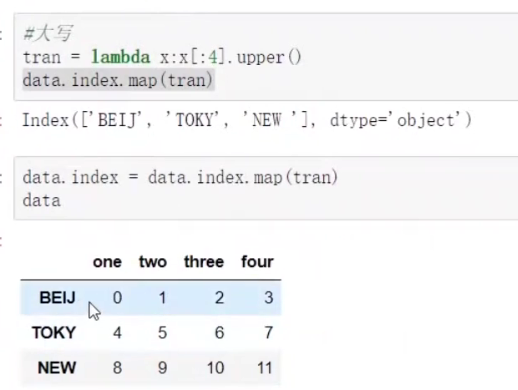
8、索引操作
创建一个符合新索引的新对象:
df2 = df1.reindex(['a','b','c','d']) # 行索引重新创建
df3 = df1.reindex(columns=['A','B','C']) # 列索引重新创建
如果df1里存在对应索引就会赋值为对应的值,若没有则对应位置赋值为NAN


https://www.bbsmax.com/A/xl56kX1kdr/
增加索引
df.loc['d',:] = [1, 2, 3] # 行索引
df.loc['d'] = [1, 2, 3] # 行索引
df2 = df1.insert(0, 'E', [1, 1, 1]) # 在0的列索引前传入名字为E的列数据
df.loc[:,'D'] = [4, 5, 6] # 列索引
会在原有基础上进行添加新的索引行
下面是返回添加后的数据的数组,不会影响原本的值
row={'A':1, 'B':2, 'C':3}
df1 = df1.append(row, ignore_index=True) # 添加行
删除索引
df = pd.DataFrame(np.arange(9).reshape(3, 3), index=['a', 'b', 'c'], columns=['A', 'B', 'C'])
del df['A'] # 删除列
df = df.drop('a') # 删除行
df.drop('B', axis=1, inplace=True) #删除列或者axis="columns",inplace=True时代表会直接修改原数据
print(df)
修改索引
print(df['A']=[9, 8, 7])
或者
print(df.A=[9, 8, 7])
修改列索引
print(df.loc['a']=9)
修改行索引
print(df.loc['a', 'A']=1000)
精准赋值到行和列
查看索引:见前面的切片
9、loc、iloc
df.loc['a':'c'] # a到c的行
df.loc['a':'c','C'] # 第一个是行索引,第二个是列索引,切片方式类似
df.loc[df > 2] # bool条件索引查看,查看到对应的series对象
iloc和loc使用基本一致,不同在于iloc是基于编号来索引的
df.iloc[0:7, 3:7] # 第一个是行索引,第二个是列索引,切片方式类似
df.iloc[df > 2]
ix
二、相关操作
1、算数方法表
函数 描述
add, radd
+
df1.add(df2,fill_value=0)#df1加df2,nan的值填充为0,但不能将都为nan的缺失值填充。radd表示反转相加。
sub, rsub-div, rdiv/floordiv, rflordiv//mul, rmulpow, rpow*apply
自定义方法,
df.apply(lambda x:x.max(),axis=1)
详解见:
pandas中的map()、apply()、applymap()函数的区别 – Data_worker – 博客园
.sum计算和,如:df.sum(axis=1, skipna=False)设置skipna=False后会将有nan的位置计算为nan。.idxmax获取最大值的索引.cumsum累加求和.describe获取计算的各项值
2、pandas里的axis的理解
axis=0代表操作行
axis=1代表操作列
3、排序
函数 描述
sort_index按序号排序,默认按行排,默认升序,ascending=False设置为降序,axis=1按列排序。sort_values
按值排序,缺失值会默认排在最后,
df.sort_values(by=[‘A’, ‘B’])会按照A进行排序,之后按照B进行排序。
.take(indexes)按索引来显示数据
4、处理缺失值
函数 描述
.isnull()判断是否存在缺失值.notnull()判断是否不为缺失值dropna()删除缺失值,默认丢弃行,axis=1丢弃列fillna()填充缺失值,如fillna(-1.)所有nan都会被填充为-1
5、读取文本
深入理解pandas读取excel,txt,csv文件等命令 – 梦想橡皮擦 – 博客园
6、处理重复值
.duplicated()
每行是否重复若之后出现了重复的则返回True否则返回False
如df.duplicated()返回True和False组成的Series对象
.drop_duplicates()
删除重复的数据
如df.drop_duplicates()会返回一个没有重复数据的对象
也可以案例判断重复:
df.drop_duplicates([‘k1’])这样设置就能只删除k1列上重复的数据了,而不影响其他列。
也可以加入属性keep=’last’就会保留最后一个数据。
7、映射
Pandas教程 | 数据处理三板斧——map、apply、applymap详解 – 知乎
8、数据替换
.replace([old],new)
替换数据
多个替换
如:加100替换为0,-999替换为nan
写法1:df.replace([100,-999],[0,np.nan])
写法2:df.replace({100:0,-999:np.nan})
执行效果一样。
返回值。
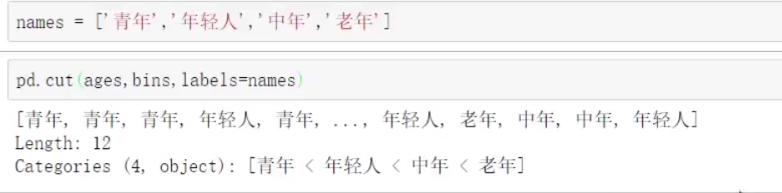
9、离散化和面元划分
.cut(data,bins)
数据分段,data为数据,bins为区间数组。
也可以设置right属性默认为True,设置为False表示左闭右开。
labels可以设置面元名称。
precision=2设置小数位数位后两位。
pd.value_counts(arr)面元计数


10、随机
.random.permutation(6)如果参数为6则会产生[0,6)范围整数的随机数.sample(n=3)从数据中随机抽取n条数据,也可以设置重复抽取设置replace=True。
11、数据连接
pd.merge(left,right)
返回数据连接后的数据,默认以重叠的列为键连接。
也可以手动设置连接键on=[‘key’,’key2′],how=’outer’设置连接方式。
[Python3]pandas.merge用法详解_Asher117的博客-CSDN博客_pandas.merge
left.join(right)
pandas入门: 数据合并之–join – 知乎
pd.concat()
pandas中concat()的用法 – 知乎
12、聚类
df.groupby(by=”key”)
聚类
pandas聚合和分组运算之groupby – wqbin – 博客园
Original: https://blog.csdn.net/qq_50909707/article/details/122628925
Author: Dragon Wu
Title: Pandas 学习总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/698809/
转载文章受原作者版权保护。转载请注明原作者出处!