

目录
2、数据挖掘主要研究什么内容?它和数据库、数据查询、专家系统、数理统计有什么不同?
1、请简要解释全连接前馈神经网络的”全连接”和”前馈”的含义
第一章 认识数据挖掘
1、什么是数据中”隐含”的信息
数据中”隐含”的信息就是不能直接得到,而是要通过各种技术或方法,从数据中分析、挖掘出来的被隐藏起来的信息。
2、数据挖掘主要研究什么内容?它和数据库、数据查询、专家系统、数理统计有什么不同?
数据挖掘从大型数据库中提取有趣的(非平凡的、蕴涵的、先前未知的并且是潜在有用的)信息或模式。
数据库中的信息是非平凡的、智能的。
数据查询不能获得潜在、隐藏信息或知识。
专家系统用规则表示领域专家的知识经验。
一般的简单统计不获取潜在、隐藏信息或知识。
3、辨析:数据、信息、知识
数据:最原始的记录,是未被加工过的。
信息:利用计算机技术对数据进行加工处理后,使数据间建立联系。
知识:信息经人脑处理并存于人脑中。
4、有指导和无指导学习的联系和区别是什么
有指导学习也叫有监督学习,无指导学习也叫无监督学习。它们是机器学习领域的两大类学习算法,它们的主要区别在哪里?如何根据数据集特点来选择相应学习算法?
1.联系:都是机器学习
2.区别:
(1)有指导学习的训练集要求包括输入输出;无指导学习输入数据没有被标记,也没有确定的结果。
(2)有指导学习通过大量已知分类和输出结果的实例进行训练,得到一个模型;无指导学习没有分类模型,只能从原先没有标记的样本开始学习分类器设计,按照相似性度量方法,计算相似程度,进行聚类。
(3)有指导学习的目标往往是让计算机去学习已经创造好的分了哦模型;无指导学习的目标是不告诉计算机怎么做,而是让计算机自己学习怎样做。3.若数据集有已知分类和明确的输出结果,则使用有指导学习;若数据集无预先定义好的分类,则使用无指导学习。
5、如何理解数据挖掘的不同角度的定义
-
技术角度:利用一种或多种计算机学习技术,从数据中自动分析并提取信息的处理过程。目的是寻找和发现数据中潜在的有价值的信息、知识、规律、联系和模式。
-
学科角度:一门交叉学科,涉及数据库技术、人工智能技术、统计学、可视化技术、并行计算等多种技术。
-
商业角度:商业智能信息处理技术,围绕商业目标展开,对大量商业数据进行抽取、转换、分析和处理,从中提取商业决策的关键性数据,揭示隐藏的、未知的或验证已知的规律性,是一种深层次的商业数据分析方法。
6、数据挖掘与专家系统的联系和区别是什么?
-
联系:专家系统和数据挖掘都是从一堆数据中找出有用的信息,都需要收集大量的原始数据后才能进行处理,它们创建的知识系统,是一样的模型系统。让专家系统和数据挖掘进行协作,可以共同解决较为困难的问题。
-
区别:
(1)数据挖掘是利用一种或多种计算机学习技术,从数据中自动分析并提取信息;而专家系统是知识工程师接受培训,获取专家的知识,获取知识后,使用自动化工具创建新知识的计算机模型。
(2)专家系统一般面向特定的主题;数据挖掘无特定主题。
- 专家系统:一种具有”智能”的计算机软件系统,它能够模拟某个领域的人类专家的决策过程,解决那些需要人类专家处理的复杂问题。
7、数据挖掘工作的基本流程是什么?


8、数据挖掘的作用

作业1
1、对于以下问题,考虑使用有指导的学习方法、无指导的聚类方法和数据查询方法中的哪一种更为合适。若使用有指导的学习方法,请确定可能的输入属性和输出属性。
(1) 决定放假是否回老家。
(2) 当顾客访问购物网站时,哪些商品会同时购买?
(3) 一年中,职业为教师的驾车者走公交车道而接受违章处罚的情况。
(4) 找出年龄、职业、受教育程度、收入、工作时间、婚姻状况、家庭成员人数等与一个人是否会投资股票之间是否存在联系。
答案及分析:
(1)有指导学习,输出属性:回老家;输入属性:是否有时间、身体状况、车票是否买到,等等
理由:这个题目不能通过数据查询来完成,属于预测的问题。在建立数据集时,"放假是否回家"可以作为一个实例的分类结果而作为一个分类的输出属性(标签)进行训练。
(2)无指导学习,(如果说无指导聚类、关联规则的也可以)
理由:由题意,关联规则最合适,反映购买商品的关联关系;聚类也可以考虑使用,把同一个顾客的商品聚类在一起。而本题不适合进行有指导的训练,不好确定分类的标签。
(3)数据查询
本题的数据是可以在数据库中来直接查询的。公交车道而接受违章处罚的情况,在交管局等部门的系统中应该是有数据库的记录可查的。
(4)有指导学习,输出属性:是否投资股票;输入属性:年龄、职业、受教育程度、收入、工作时间、婚姻状况、家庭成员人数等
理由:构建训练数据集时,"是否购买股票"可以作为一个已知实例分类结果的输出属性。本题是由多个输入属性来共同确定输出结果的
第二章 基本数据挖掘技术
1、决策树算法的关键技术

2、选择最能区别数据集中实例属性的方法
信息熵:信息不确定程度的度量
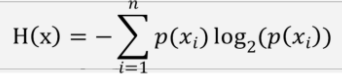
信息增益:

3、请比较weka提供的4种不同检验方法
① using training set是使用在训练集实例上的预测效果进行检验,也就是训练集和测试集都是同一个;
② supplied test set使用另外提供的检验集实例进行检验。
③ cross-validation是使用交叉验证来检验分类器,也就是说每次选一些实例作为训练集建立模型,另外的实例作为验证集;
④ percent split是百分比检验,从数据集中按一定的百分比取出部分数据作为检验集实例用,根据分类器在这些实例上的预测效果来检验分类器的质量。
4、C4.5算法使用什么参数来选择属性
增益率
5、产生式规则和关联规则有什么不同?
(1)在某条关联规则中以前提条件出现的属性可以出现在下一条关联规则的结果中。
(2)传统的用于分类的产生式规则的结果中仅能有一个属性,而关联规则中则允许其结果包含一个或多个属性。
6、决策树的优缺点

7、Apriori关联分析的算法效率怎样?
Apriori关联分析算法采用逐层搜索,对数据扫描次数过多,可能产生大量的候选项集。在频繁项目集长度变大的情况下,运算时间显著增加,算法效率较低。
8、K-means算法的结束条件是什么?
每个簇的簇中心不再改变。
9、C4.5算法的结束条件是什么?如何理解
(1)该子类中的实例满足预定义的标准;
理解:选择的属性达到了预先定义的效果即可输出,如全部分到一个输出类。
(2)没有剩余属性;
理解:剩余的属性都被创建为了树节点,没有剩余节点。
10、信息熵的含义是什么?如何计算?
信息熵是信息的不确定程度的度量。
计算公式如下:

其中:H(x)表示随机事件x的熵;p表示xi出现的概率;xi表示某个随机事件x的所有可能结果。
作业2



1、基于教材的表2.1,计算使用Partner 作为根节点的增益率值。
2、对以下三项条目,列出三条规则(规则中if条件采用两项组合),使用表2.3中的数据确定这些规则的置信度和支持度的值。
Book =1 & Sneaker = 0 & DVD = 1
1. 计算使用Partner作为根节点的增益率值。
(1) Info(I)= -(7/15log2(7/15)+8/15log2(8/15))= 0.996792≈0.9968
(2) Info(I,Partner)= 11/15Info(Yes)+4/15Info(No)= 0.9453
其中:Info(Yes)= - (6/11log2(6/11) + 5/11log2(5/11)) = 0.9940
Info(No)=-(1/4log2(1/4) + 3/4log2(3/4)) = 0.8113
(3) SplitsInfo(Partner)= - (11/15log2(11/15) + 4/15log2(4/15)) = 0.8366
(4) Gain(Partner) = Info(I)- Info(I,Partner)≈0.9968-0.9453 =0.0515
(5) GainRatio(Partner) =Gain ( Partner) /SplitsInfo(Partner)
=0.0515 / 0.8366 = 0.0616
2. 对以下三项条目,列出三条规则,使用表2.3 中的数据确定这些规则的置信度和支持度的值。
Book =1 & Sneaker = 0 & DVD = 1
三条规则为:
(1)IF Book = 1 & Sneaker = 0 THEN DVD =1
置信度= 2/3=66.7%
支持度=2/10=20%
(2)IF Book = 1 & DVD =1 THEN Sneaker = 0
置信度= 2/4=50% 支持度=2/10=20%
(3)IF Sneaker = 0 & DVD =1 THEN Book = 1
置信度= 2/4=50% 支持度=2/10=20%
第三章 KDD
1、请分析数据挖掘和知识发现的关系
数据库知识发现 (KDD) 是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。它由九个步骤组成,从开发与理解应用领域开始到知识发现的行动。 数据挖掘是其中的一个步骤 ,而数据库知识发现 (KDD) 过程主要是在一种特定的表现形式或一套这种表征中寻找有趣的模式。

2、如何处理噪声数据和缺失数据
1.处理噪声数据
(1)分箱方法;
(2)聚类;
(3)计算机和人工检查相结合;
(4)回归。
2.处理缺失数据
(1)忽略含有缺失值的记录;
(2)手工补缺缺失值;
(3)利用均值代替缺失值;
(4)利用同类均值填补缺失属性值;
(5)使用全部常量填补缺失值;
(6)利用最大可能的值补缺失值。
3、建模的典型步骤有些哪些
(1)从准备好的数据集实例中选择训练和检验数据;
(2)选择一组输入属性;
(3)如果学习是有指导的,选择一个或多个输出属性;
(4)选择学习参数的值;
(5)调用数据挖掘工具建立模型;
(6)数据挖掘完成,对模型进行评估。如果结果不够理想,可以多次重复上述步骤。
作业3
使用Min-Max标准化方法将45岁年龄值,变换为[0,1]区间的值,年龄的取值范围为[18,100];假设通过神经网络计算得到一个年龄值为0.6,将这个[0,1]区间内的输出值还原为正常年龄值。

第四章 数据仓库
1、数据库和数据仓库有哪些异同点?
1.设计目的不同
数据库是面向事务而设计,数据仓库是面向主题而设计的。
2.存储数据内容不同
数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
3.结构设计原则不同
面向数据库的设计主要是为日常事务处理,对数据访问效率要求较高,在时间和空间效率方面进行权衡考虑,一般通过范式约束,尽量消除冗余数据和冗余联系。
数据仓库的设计主要是为了进行数据分析,要求有大量的集成数据作为基础,所以往往采用反范式设计,将具有直接或间接联系的数据尽可能的连接起来。
2、什么是反向规范化?它和数据库中的关系规范化有什么不同?
一、规范化
常见的规范化有数据库设计的三范式。
1NF 是最低的规范化要求。如果关系 R 中所有属性的值域都是简单域,属性不可再分。
2NF 非主属性完全函数依赖于码。
3NF 非主属性不传递依赖于任何一个候选码。
二、反规范化
数据库中的数据规范化的优点是减少了数据冗余,节约了存储空间,相应逻辑和物理的I/O 次数减少,同时加快了增、删、改的速度,但是对完全规范的数据库查询,通常需要更多的连接操作,从而影响查询速度。因此,有时为了提高某些查询或应用的性能而破坏规范规则,即反规范化(非规范化处理)。
常见的反规范化技术包括:
(1)增加冗余列
(2)增加派生列
(3)重新组表
(4)分割表
(5)垂直分割
3、数据仓库有哪些常见模型?
星型模型,雪花模型和星座模型
雪花模型是特殊形式的星型模式。
星型模型中有两个或两个以上的事实表形成星座模型。
4、什么是ETL?
数据抽取、转换和加载 Extraction ,Transformation. Loading, 简称ETL
从一个或多个输入源中抽取数据,如果有必要,清洗和转换提取的数据,并将数据加载到数据仓库中。
5、请解释OLAP?它有什么特点?
联机分析处理(On-line Analytical Processing, OLAP)
基于查询和报告的面向特定问题的多维环境下的数据分析方法和工具。
对多维数据采取不同观察角度,进行全方位、快速、稳定和交互性查询和分析。
由E-F-Codd 1993年提出的。
特点
(1)快速性
(2)多维性
(3)可分析性
(4)信息量大
第五章 评估技术
1、请简要分析评估技术在数据挖掘中的作用和意义
模型的性能评估是数据挖掘过程中重要的步骤,是模型能否投入到实际使用当中的一个重要环节。
2、请说明采用无指导聚类来评价有指导学习模型的步骤
( 1)将有指导建模使用的训练集作为无指导聚类的数据集,删除有指导学习中作为输出的属性;
(2)度量聚类形成的簇的质量。如果簇质量良好,则证明使用这个训练集训练的有指导模型的质量良好。反之,证明用于有指导学习的训练集数据不是最好的选择,需要在有指导学习训练之前,对训练集中的实例和属性进行重新评估和选择。
3、请分析机器学习中TP,FP,TN,FN的含义
FN:False Negative,被判定为负样本,但事实上是正样本。
FP:False Positive,被判定为正样本,但事实上是负样本。
TN:True Negative,被判定为负样本,事实上也是负样本。
TP:True Positive,被判定为正样本,事实上也是正样本。
作业四
设分类模型M的混淆矩阵如下所示,计算M的分类正确率和错误率
C1 C2 C3
C1 55 3 2
C2 2 57 1
C3 4 54 2

第六章 神经网络技术
1、请简要解释全连接前馈神经网络的”全连接”和”前馈”的含义
全连接:输入层和隐层之间都有两两连接
前馈:传递方向都是由后往前传,数据只会从输入节点通过隐层节点(如果有的话)流动到达输出节点,没有周期或者循环,可用一个有向无环图表示
2、请说明神经网络的输入格式和输出格式的数据类型
输入格式:数值类型且落在【0,1】闭区间内
输出格式:【0,1】区间内的连续值
3、为什么说Kohonen神经网络可以进行无指导聚类?
Kohonen认为,神经网络在接收外界输入时,将会分成不同的区域,不同的区域对不同的模式具有不同的响应特征,即不同的神经元以最佳方式响应不同性质的信号激励,从而形成一种拓扑意义上的有序图,称之为映射图。它表达了一种非线性映射关系,将信号空间中各模式的拓扑关系几乎不变地反应在这张图上,即各神经元的输出响应上。由于这种映射是通过无指导的自主适应过程完成的,所以也称它为自组织映射图。依据这些研究成果,Kohonen又形势化了神经网络的无指导聚类,也形成了著名的Kohonen神经网络。
4、请解释人工神经网络中权重和激励函数的概念
权重:连接间的权值,相当于神经网络的记忆;
激励函数:每个节点的输出由一个输出函数计算所得。
5、什么是全连接前馈神经网络
全连接指相邻层的各个节点之间都有连接线,前馈指的是数据的流向只是由输入流向输出
6、请概括BP算法的基本思路
(1)初始化网络
若有必要,变换输入属性值为[0,1]区间的数值数据,确定输出属性格式。
通过选择输出层、隐层和输出层的节点个数,来创建神经网络结构。
将所有连接的权重初始化为[-1.0,1.0]区间的随机值。
为学习参数选择一个[0,1]区间的值。
选取一个终止条件。
(2)对于所有训练集实例
让训练实例通过神经网络。
确定输出误差。
使用Δ规则更新网络权重。
(3)如果不满足终止条件,重复步骤(2)
(4)在检验数据集上检验网络的准确度,如果准确度是不理想的,改变一个或多个网络参数,从(1)开始。
7、请用自己的话来概括神经网络的优缺点
优点:
(1)更擅长处理包含大量噪声数据的数据集;
(2)不仅可以处理数值型数据,还可以处理分类类型数据;
(3)历史悠久,得到广泛应用;
(4)既可以用于有指导学习,也可以用于无指导聚类;
缺点:
(1)对自身解释能力不强;
(2)不能保证收敛到最理想结果;
(3)容易训练过度。
作业五
对于输入实例[0.3,0.6,0.5],计算图6.1所示的神经网络中节点i的输入值和输出值,初始权值见表6.2,激励函数为sigmoid函数。

第七章 统计技术
1、请谈谈最小二乘法的原理是什么?
y和x的关系拟合为线性关系,所有的样本点都在这条直线周围,每个点都与此直线有一定的距离,所有的距离平方和,求其最小的时候相应的该直线的斜率,即最小二乘估计.
2、请说明非线性回归的基本解决思路是什么?
①选择适当非线性回归方程
②通过变量置换,将非线性回归转换成线性回归,利用线性回归方法进行参数估计
③评估非线性模型
3、请谈谈你对贝叶斯分类器的认识
基于统计学的贝叶斯分类方法以贝叶斯理论为基础,通过求解后验概率分布,预测样本属于某一类别的概率。
贝叶斯公式可写成如下形式:P(y|x)=P(x|y) _P(A)_P(y)/(P(x)
其中,P(y I x)为后验概率分布,P(y)为先验分布,P(x)通常为常数
属于有监督学习,属于生成式模型算法
4、请概括下凝聚聚类的基本思想
采用自底向上策略。
首先将每个对象作为一个簇,根据某种相似度度量方法对这些簇进行合并,直到所有实例都被分别聚类到某一个簇中,或满足某个终止条件时为止。绝大多数分层聚类算法属于凝聚聚类方法,这些算法的区别一-般是在簇之间的相似度度量方法上不同。
Original: https://blog.csdn.net/qq_54510777/article/details/122051162
Author: 山野行者syh
Title: 数据挖掘导论 N个考试常用的问题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/698756/
转载文章受原作者版权保护。转载请注明原作者出处!