

题目4:一般食物所含成分可分为水分、能量、碳水化合物、膳食纤维、脂肪、蛋白质、维生 素、矿物质和胆固醇等九大类,你认为 哪类成分对食物寒热性起到主要作用?这种作用对开发 以寒热性为原理的功能性食品有什么帮助?
思路:首先利用主成分分析方法分析主要的变量,再根据单因素分析方法看它们对因变量食物寒热性的影响。
简单介绍:
主成分分析法(Principal Component Analysis,PCA)是一种常用的多变量分析方法,
其主要主要是降维处理,并得出自变量的影响权重,主要步骤如下:
a.初始数据标准化处理,使得每个数据属性的均值为 0,方差为 1.
b.推导得出相关系数矩阵
c.计算相关系数矩阵的特征值及特征向量
d.计算主成分的 贡献率/ 累计贡献率
e.得出主要成分的自变量
ANOVA方差分析的基本思想就是分析不同类别数据的差异对最终结果的影响大小,它确定
该数据对实验结果的重要性。它可 用于检验食物成分对食物寒热性是否有显著影响。
1、 数据预处理。由于数据分成了9类,对于维生素B1,B2,烟酸等划为维生素族和钙铁等元素划为矿物质族,数据标准化后,重新构建的能量、水分、维生素、矿物质等 9类食物成分数据进行建模分析。
2、采用 主成分分析模型,探究出主要自变量及其贡献度排序。
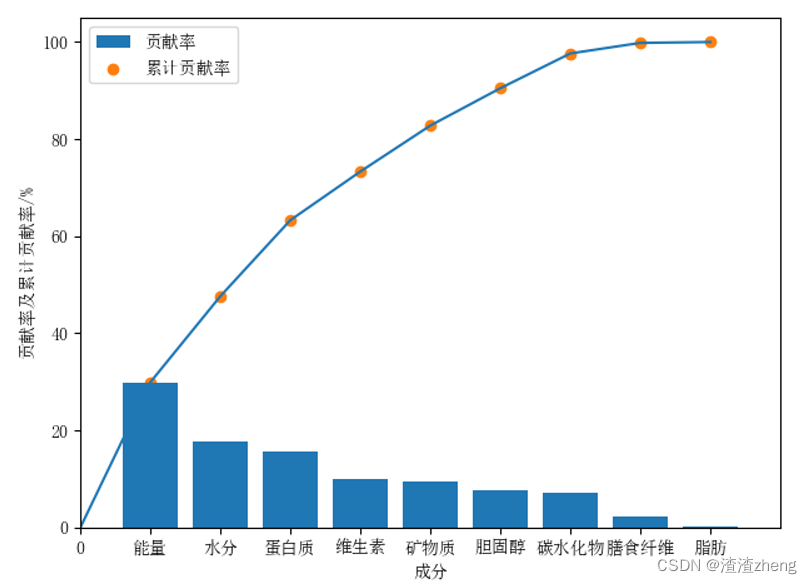

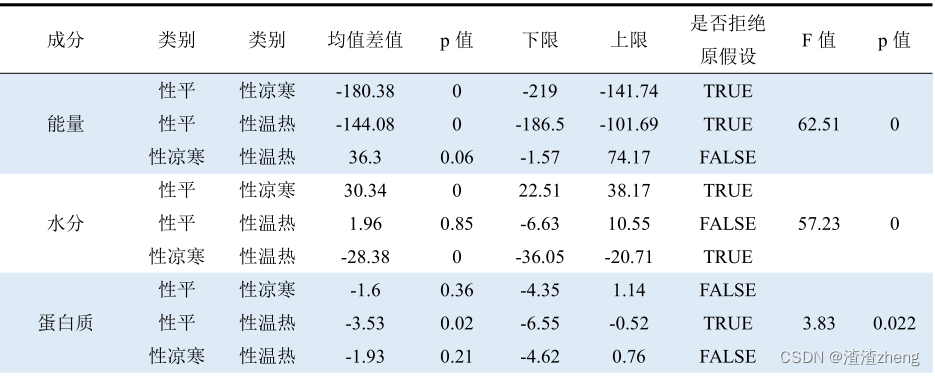
3、采用 单因素方差分析来检验自变量对因变量寒热属性的分类是否具有显著性影响。原假设:性平,性寒和性热的各个食物成分无显著差异可得 能量、水分、碳水化合物和脂肪的 p值都接近 0,远小于 0.05水平,它们对食物寒热性起到主要作用。结合 多重比较的田口法来判断两两类别之间的显著性差异。
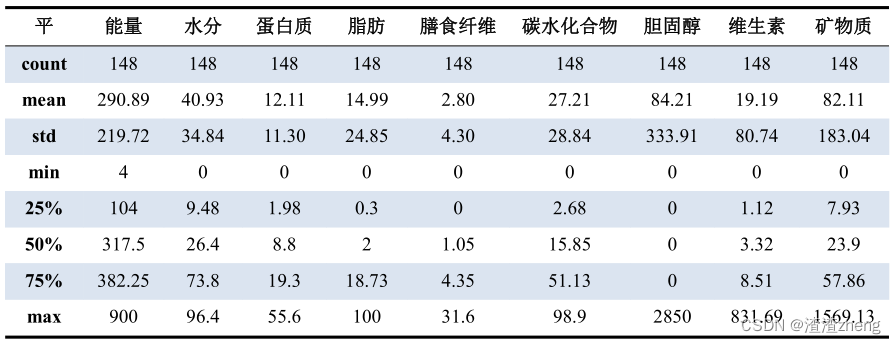
4、性平、性凉寒和性温热分类中的食物成分 描述性统计。
5、 得出结论。能量、碳水化合物和脂肪的含量越高,食物属性越趋向于性平,当水分含量越大,食物属性越趋向于性凉寒。
python源代码:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing
import re
from scipy import stats
##------------读取数据----------
df1 = pd.read_excel(r'食物成分表.xlsx', index_col=0).reset_index(drop=True)
df4 = df1.drop(['可食部分(%)'], axis=1)#去掉不重要变量
df_origin = df4[df4.columns[1:]]#中间变量,保存原始数据
df44 = preprocessing.scale(df4[df4.columns[1:]])#标准化数据
##------------数据处理----------
ytick=['x1','x2','x3','x4','x5','x6','x7','x8','x9','x10','x11','x12','x13','x14','x15','x16']
df44 = pd.DataFrame(df44,columns=ytick)#数据类型转换
df_origin.columns=ytick#换列标签
WeiShengSu=pd.Series(len(df44))#创建维生素的列
KuangWuZhi=pd.Series(len(df44))#创建矿物质的列
WeiShengSu1=pd.Series(len(df_origin))#原始未标准化数据
KuangWuZhi1=pd.Series(len(df_origin))
#把维生素族和矿物质族整合到一类
for i in range(len(df44)):
WeiShengSu[i] = (df44['x7'][i]+df44['x8'][i]+df44['x9'][i]+df44['x10'][i]+df44['x11'][i]+df44['x15'][i])/6
KuangWuZhi[i] = (df44['x12'][i] + df44['x13'][i] + df44['x14'][i]) / 3
df4con=pd.concat([df44[df44.columns[0:6]],df44[df44.columns[15]],WeiShengSu,KuangWuZhi],axis=1)
for i in range(len(df_origin)):#未标准化的
WeiShengSu1[i] = (df_origin['x7'][i]+df_origin['x8'][i]+df_origin['x9'][i]+df_origin['x10'][i]+df_origin['x11'][i]+df_origin['x15'][i])/6
KuangWuZhi1[i] = (df_origin['x12'][i] + df_origin['x13'][i] + df_origin['x14'][i]) / 3
df4con_origin=pd.concat([df_origin[df_origin.columns[0:6]],df_origin[df_origin.columns[15]],WeiShengSu1,KuangWuZhi1],axis=1)
#整合的新的9个类别数据
df4=pd.concat([df4['名 称'],df4con], axis=1)
df4.columns=['名 称','能量','水分','蛋白质','脂肪','膳食纤维','碳水化物','胆固醇','维生素','矿物质']
df4['catef'] = ''
df_origin=pd.concat([df4['名 称'],df4con_origin], axis=1)#未标准化
df_origin.columns=['名 称','能量','水分','蛋白质','脂肪','膳食纤维','碳水化物','胆固醇','维生素','矿物质']
#根据附件2分类标注数据
def TagCategory(datastr,f,tap):
for line in f:
a = re.split('。|、|;|(|)|\\n| ', line)#分割字符串保存到a
a = [x.strip() for x in a if x.strip() != '']#去除空字符串
for ss in a:
index0 = datastr.str.find(ss)#找到则返回所要找字符串在指定字符串位置,没有则返回-1
ind = index0[index0.values != -1].index#不为-1的即表示有
df4['catef'][ind] = tap#标注
mingcheng = df4['名 称'].astype(str)#提取名称所在列
f0 = open(r'性平.txt', encoding='utf-8')
f1 = open(r'性凉寒.txt', encoding='utf-8')
f2 = open(r'性温热.txt', encoding='utf-8')
TagCategory(mingcheng,f0,0)#性平标为0
TagCategory(mingcheng,f1,1)#性凉寒标为1
TagCategory(mingcheng,f2,2)#性温热标为2
print(df4.head())#查看前5行
#标注后,数据分为已知分类数据集和未知数据集
NonNulldf = df4[(df4['catef'].notnull()) & (df4['catef'] != "")]
IsNulldf = df4[(df4['catef'] == "")]
NonNulldf_o = df_origin[(df4['catef'].notnull()) & (df4['catef'] != "")]
IsNulldf_o = df_origin[(df4['catef'] == "")]
#找出各个分类数据,标准化数据
c1=NonNulldf[NonNulldf['catef'] == 0]
c2=NonNulldf[NonNulldf['catef'] == 1]
c3=NonNulldf[NonNulldf['catef'] == 2]
c11=c1[c1.columns[1:10]]
c22=c2[c2.columns[1:10]]
c33=c3[c3.columns[1:10]]
#找出各个分类数据,未标准化数据
c1_o=NonNulldf_o[NonNulldf['catef'] == 0]
c2_o=NonNulldf_o[NonNulldf['catef'] == 1]
c3_o=NonNulldf_o[NonNulldf['catef'] == 2]
c3_o=c3_o[0:108]
c11_o=c1_o[c1_o.columns[1:10]]
c22_o=c2_o[c2_o.columns[1:10]]
c33_o=c3_o[c3_o.columns[1:10]]
#单因素方差分析
from statsmodels.stats.multicomp import MultiComparison
def SingVarA(str):
f, p = stats.f_oneway(c1_o[str],c2_o[str],c3_o[str])#F值和P值
print (str,'F value:', np.around(f,decimals=2))#输出,保留2位小数
print (str,'P value:', np.around(p,decimals=7), '\n')
mc = MultiComparison(NonNulldf_o[str], NonNulldf['catef'])
result = mc.tukeyhsd()#田口方法进一步分析各个类别
print(str,'\n',result)
#调用自定义函数
SingVarA('能量')
SingVarA('水分')
SingVarA('蛋白质')
SingVarA('维生素')
SingVarA('矿物质')
SingVarA('胆固醇')
SingVarA('碳水化物')
SingVarA('膳食纤维')
SingVarA('脂肪')
#9个变量的统计性分析
result1 = c11_o.describe()
result2 = c22_o.describe()
result3 = c33_o.describe()
result1=pd.DataFrame(result1) #格式化成DataFrame
result2=pd.DataFrame(result2) #格式化成DataFrame
result3=pd.DataFrame(result3) #格式化成DataFrame
#求总体的数据的相关性矩阵
c=df4[df4.columns[1:10]]
covC=np.around(np.corrcoef(c.T),decimals=3)
数据格式转换,替换索引字符
label=['能量','水分','蛋白质','脂肪','膳食纤维','碳水化物','胆固醇','维生素','矿物质']
data_df = pd.DataFrame(covC,index=label,columns=label) #关键1,将ndarray格式转换为DataFrame
中文和负号的正常显示
config = {"font.family": 'serif',"mathtext.fontset": 'stix',"font.serif": ['SimSun']}
plt.rcParams.update(config)
plt.rcParams['axes.unicode_minus'] = False
图1,绘制热力图
plt.figure(num=1,figsize=(14, 14))
ax = sns.heatmap(data_df, annot=True, cmap="jet_r")
plt.xticks(fontsize=13)# 设置轴字体大小
plt.yticks(fontsize=13)
plt.title("Correlation analysis", fontsize="xx-large")
plt.show()# 显示图片
#求解特征值和特征向量
featValue, featVec = np.linalg.eig(covC.T) #求解系数相关矩阵的特征值和特征向量
对特征值进行排序并输出
tempt=featValue#中间变量,记录未排序的特征值
featValue = sorted(featValue)[::-1]#排序
featValue1 = np.array(tempt)#类型转换
featIndex=np.argsort(-featValue1)#找到排序后原来的索引
print(featIndex)
图2,绘制散点图和折线图
plt.figure(num=2)
#根据特征值排序后相应的横坐标食物分类
xaxis=['0','能量','水分','蛋白质','维生素','矿物质','胆固醇','碳水化物','膳食纤维','脂肪']
plt.scatter(xaxis[1:], featValue)
plt.plot(xaxis[1:], featValue)
plt.xlabel("成分变量")# 显示图的标题和xy轴的名字,最好使用英文,中文可能乱码
plt.ylabel("特征值")
plt.grid() # 显示网格
plt.tight_layout()
plt.show() # 显示图形
求特征值的贡献度
gx = (featValue / np.sum(featValue))*100#百分比
gx =np.around(gx,decimals=3)#保留3位小数点
print(gx)
求特征值的累计贡献度
lg = np.cumsum(gx)
lg = np.around(lg,decimals=3)
print(lg)
mainVarAna=df4.columns[[featIndex+1]]#排序后对应变量名称
print(mainVarAna)
#第三张图
plt.figure(num=3)
plt.xticks(np.arange(0,len(covC)+1,1),xaxis)#显示全部刻度
plt.xlim(0,10)#x轴范围
bar=plt.bar(xaxis,np.insert(gx, 0, 0),width=0.8,align='center')#柱状图
plt.xlabel('成分')
plt.ylabel('贡献率及累计贡献率/%')
#画点及连线
sca=plt.scatter(range(1, len(gx)+1), lg)
lines=plt.plot(range(0, len(gx)+1), np.insert(lg, 0, 0))
plt.legend([bar, sca], ["贡献率", "累计贡献率"], loc='upper left')
plt.tight_layout()
plt.show()
将文件写入excel表格中
gx=pd.DataFrame(gx)#关键1,转换格式
writer = pd.ExcelWriter('Q4_gongxianlv.xlsx') #关键2,创建名称为gongxianlv的excel表格
gx.to_excel(writer,'page_1',float_format='%.3f') #关键3,贡献率float_format 控制精度,将数据写到工作表中。
lg=pd.DataFrame(lg)#转换格式
lg.to_excel(writer,'page_2',float_format='%.3f')#工作表2写入累计贡献率
featValue=pd.DataFrame(featValue)#特征值写入
featValue.to_excel(writer,'page_3',float_format='%.2f')
#创建一个描述性统计量表
writer1 = pd.ExcelWriter('Q4_DescribeAna.xlsx')
result1.to_excel(writer1,'性平',float_format='%.3f')
result2.to_excel(writer1,'性凉寒',float_format='%.3f')
result3.to_excel(writer1,'性温热',float_format='%.3f')
writer.save() #关键4, 保存
writer1.save()
Original: https://blog.csdn.net/qq_50626322/article/details/125156108
Author: 渣渣zheng
Title: 2022福大数学建模赛题B题-主成分分析和单因素方差分析-附python代码
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/698590/
转载文章受原作者版权保护。转载请注明原作者出处!