

【Stacking改进】基于随机采样与精度加权的Stacking算法
摘要
近年来,人工智能的强势崛起让我们领略到人工智能技术的巨大潜力,机器学习也被广泛应用于各个领域,并取得不错的成果。本文以Kaggle竞赛House Prices的房价数据为实验样本,借鉴Bagging的自助采样法和k折交叉验证法,构建一种基于伪随机采样的Stacking集成模型,用于房价预测。首先利用GBDT对数据集进行简单训练,并得到各个特征重要性。接着对数据集进行多次随机采样,然后根据特征重要性进行属性扰动,组成多个训练数据子集和验证数据子集。用这些数据子集训练基模型,并计算验证集的均方根误差和预测结果,根据误差分配权重。根据各个基模型预测结果组成第二层的元模型,最后在测试数据集上进行房价预测。实验结果表明,基于随机采样和精度加权的Stacking集成模型的均方根误差小于所有基分类器和同结构的经典Stacking集成方法。
Stacking算法理论基础
Stacking是一种分层模型集成框架,在1992年被Wolpert提出。Stacking集成可以有多层的情况,但通常会设计两层,第一层由多种基模型组成,输入为原始训练集,而输出为各种基模型的预测值,而第二层只有一个元模型,对第一层的各种模型的预测值和真实值进行训练,从而得到完成的集成模型。同理,预测测试集的过程也要先经过所有基模型的预测,组成第二层的特征,再用第二层的元模型预测出最终的结果。为了防止模型过拟合的情况,一般Stacking算法在第一层训练基模型时会结合k折交叉验证法。以五折交叉验证法为例,Stacking算法的过程如下图所示。
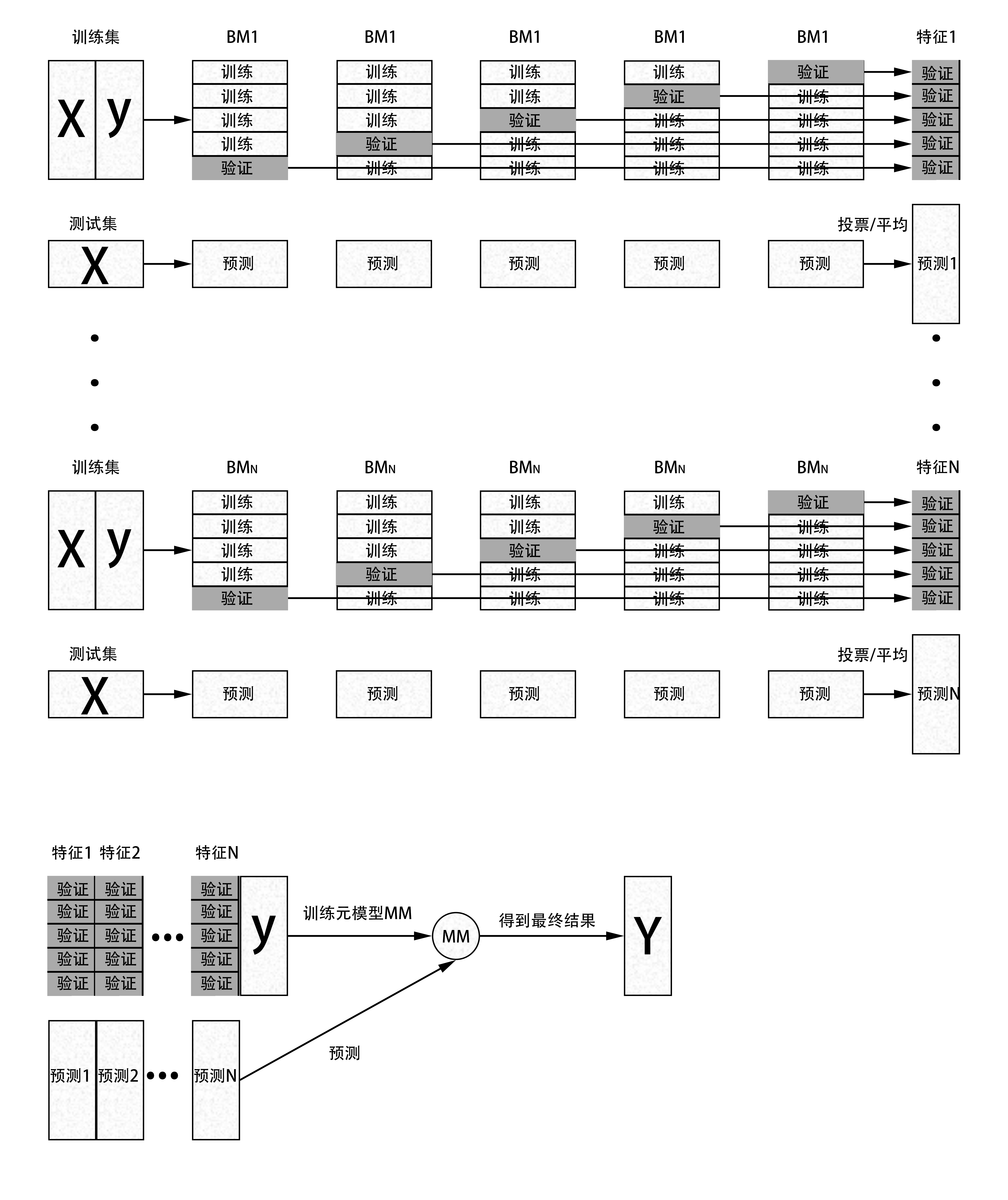

; 传统Stacking代码
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values)
rmse= np.sqrt(-cross_val_score(model, train.values, target_variable, scoring="neg_mean_squared_error", cv = kf))
return(rmse)
class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model)
kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156)
out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X, y):
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
out_of_fold_predictions[holdout_index, i] = y_pred
self.meta_model_.fit(out_of_fold_predictions, y)
return self
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model in base_models]).mean(axis=1)
for base_models in self.base_models_ ])
return self.meta_model_.predict(meta_features)
from sklearn.linear_model import LinearRegression
meta_model = KRR
stacked_averaged_models = StackingAveragedModels(base_models = (ENet, GBoost, KRR, lasso),
meta_model = meta_model,
n_folds=10)
score = rmsle_cv(stacked_averaged_models)
print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std()))
Stacking Averaged models score: 0.1087 (0.0061)
Stacking改进
改进思路
本文对传统的Stacking算法进行研究改进,以Kaggle竞赛House Prices的房价数据为实验样本,通过Kaggle测试得分验证改进方法的可行性。本文以以下的方式对传统Stacking算法进行改进:
- 使用无放回抽样得到数据子集。目前传统的Stacking算法是采用五折交叉验证法,将训练数据分成5等份,依次选择其中一份作为验证子集,而其他四份作为训练子集用于模型训练,用训练好的基模型去预测验证子集,预测结果作为第二层的特征。而本文的模型则选择随机不放回抽样,比如连续20次随机抽取80%的样本,组成20个独立的数据子集。
- 根据概率随机选取特征。数据集经过数据处理和特征工厂后会产生很多特征,尤其是对离散特征进行独热编码,使得特征空间会变得非常大,而且存在很多冗余特征。因此本文利用GBDT对数据集进行简单训练,并得到各个特征重要性,组成总和为1的概率列表。利用这个概率列表随机选取特征,可过滤冗余特征,构造效率更高、消耗更低的独立的预测模型。
- 根据训练集的测试精度进行测试集的权重分配。传统的Stacking算法是采用五折交叉验证法,将数据集划分成五等份,由五组数据子集构成5个基模型,在第一层预测测试集时,取5个基模型的预测结果的平均值作为第二层的特征。这里可能存在数据划分不均,而导致预测效果不佳的情况。因此本文根据基模型的测试精度对预测结果进行加权平均,得到结果作为第二层的特征。
改进Stacking代码
subsample函数是对数据集进行样本与特征的采样,并记录采样情况,因为预测的时候需要对测试集的特征进行相同的采样。
.
改进的算法有三个超参数:
- n_tree:基模型个数T
- ratio_sample:样本采样比例a
- ratio_feature:特征采样比例b
.
首先先用GBoost进行简单训练,得到特征重要性列表
.
在stacking框架第一层,对每一个基模型进行T次拷贝,根据样本采样比例a对样本进行T次随机采样,然后再根据特征采样比例b和特征重要性列表进行特征选择,得到T个训练子集和T个验证子集。用训练子集分别对基模型进行训练,然后将对相应的验证子集的预测结果作为第二层元模型的输入特征。同时根据验证集的预测值与真实值的误差,给T个基模型分配权重。误差越大,权重越低。
权重计算公式:
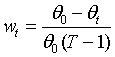
import random
from numpy import median
def subsample(dataset_x, ratio_sample, ratio_feature, i, list_fearure):
"""random_forest(评估算法性能,返回模型得分)
Args:
dataset 训练数据集
ratio 训练数据集的样本比例,特征比例
Returns:
sample 随机抽样的训练样本序列号
test_list 随机抽样后的剩下的测试样本序列号
feature 随机抽样的特征序列号
"""
random.seed(i)
sample = list()
n_sample = round(len(dataset_x) * ratio_sample)
n_feature = round(dataset_x.shape[1] * ratio_feature)
sample = random.sample(range(len(dataset_x)), n_sample)
feature = np.random.choice(a=range(dataset_x.shape[1]), size=n_feature, replace=False, p=list_fearure)
test_list = list(set(range(len(dataset_x))) - set(sample))
return sample, test_list, feature
class RfStackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_tree=20, ratio_sample=1, ratio_feature=1,list_fearure=[]):
self.base_models = base_models
self.meta_model = meta_model
self.n_tree = n_tree
self.ratio_sample = ratio_sample
self.ratio_feature = ratio_feature
self.list_fearure = list_fearure
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model)
self.list_weight = [list() for x in self.base_models]
self.list_feature = [list() for x in self.base_models]
n_tree = self.n_tree
ratio_sample = self.ratio_sample
ratio_feature = self.ratio_feature
list_fearure = self.list_fearure
rf_predictions = [list() for x in self.base_models]
rf_y = []
rf_x0 = []
rf_x1 = []
for i, model in enumerate(self.base_models):
out__predictions = np.zeros((X.shape[0], n_tree))
for j in range(n_tree):
train_list, test_list, feature = subsample(X, ratio_sample, ratio_feature, j, list_fearure)
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[np.ix_(train_list, feature)], y[train_list])
y_pred = instance.predict(X[np.ix_(test_list, feature)])
rf_predictions[i].extend(y_pred)
if i == 0:
rf_x0.extend(test_list)
rf_x1.extend(feature)
rf_y.extend(y[test_list])
mse = mean_squared_error(y_pred, y[test_list])
self.list_weight[i].append(mse)
out__predictions[:, j] = instance.predict(X[np.ix_(range(X.shape[0]), feature)])
self.list_feature[i].append(feature)
sum_weight = sum(self.list_weight[i])
num_weight = len(self.list_weight[i])
mid_weight = median(self.list_weight[i])
for j in range(num_weight):
self.list_weight[i][j] = (sum_weight - self.list_weight[i][j]) / sum_weight / (num_weight-1)
rf_x = pd.DataFrame(rf_predictions)
rf_x = rf_x.T
self.meta_model_.fit(rf_x, rf_y)
return self
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X[np.ix_(range(X.shape[0]), self.list_feature[i][j])])*self.list_weight[i][j] for j, model in enumerate(base_models)]).sum(axis=1)
for i, base_models in enumerate(self.base_models_) ])
return self.meta_model_.predict(meta_features)
GBoost.fit(train,target_variable)
list_fearure = GBoost.feature_importances_
list_non = list(np.nonzero(list_fearure)[0])
meta_model = GBoost
rf_stacked_averaged_models = RfStackingAveragedModels(base_models = (ENet, KRR, lasso),
meta_model = meta_model,
n_tree=20, ratio_sample=0.8,
ratio_feature=0.6,
list_fearure=list_fearure)
score = rmsle_cv(rf_stacked_averaged_models)
print("RF Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std()))
RF Averaged models score: 0.1158 (0.0048)
基模型参数设置如下
lasso = make_pipeline(RobustScaler(), Lasso(alpha =0.0005, random_state=1))
score = rmsle_cv(lasso)
print("\nLasso score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
KRR = make_pipeline(RobustScaler(), KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5))
score = rmsle_cv(KRR)
print("\nLasso score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3))
score = rmsle_cv(ENet)
print("\nLasso score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
GBoost = GradientBoostingRegressor(n_estimators=300, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state=5)
score = rmsle_cv(GBoost)
print("\nLasso score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
结果
模型均方根误差岭回归0.13666LASSO回归0.13181弹性网络回归0.13174梯度提升树0.13278传统stacking集成模型0.12254改进stacking集成模型0.12060
引用
本文数据来源于Kaggle竞赛House Prices的房价数据,测试结果通过Kaggle竞赛上传数据得到。
本次数据处理主要源于https://my.oschina.net/Kanonpy/blog/3076731
[1]: House Prices – Advanced Regression Techniques[EB/OL]. https://www.kaggle.com/c/house-prices-advanced-regression-techniques,2016-8-30.
[3]: 鲁莹, 郑少智.Stacking 学习与一般集成方法的比较研究[D].暨南大学,2017.
[4]: 覃智全. Stacking集成分类器优化算法研究[D].国防科学技术大学,2016.
[6]: 徐慧丽. Stacking算法的研究及改进[D].华南理工大学,2018.
[7]: 陈宇韶. 基于特征选择与改进Stacking算法的股价预测研究[D].南华大学,2018.
Original: https://blog.csdn.net/you_just_look/article/details/117486255
Author: 圈外人
Title: 【Stacking改进】基于随机采样与精度加权的Stacking算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/698524/
转载文章受原作者版权保护。转载请注明原作者出处!