

import pandas as pd
import numpy as np
import json,math
import random
from tqdm import tqdm
from collections import Counter ,defaultdict
import re,nltk
import re
import pandas as pd
import csv
df=pd.read_csv("导出印地语数据1000条.csv")
df.title
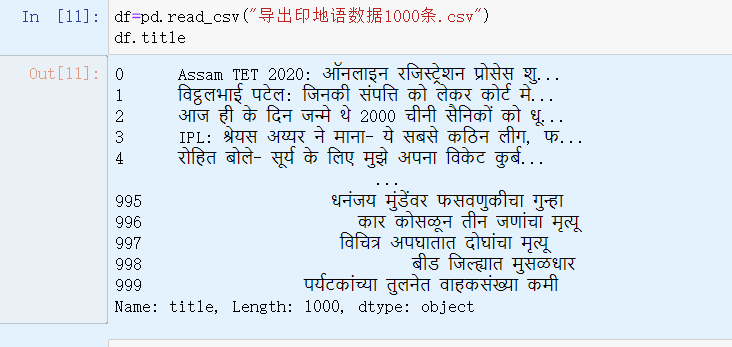

df
df.columns

for x in range(32,128):
print(f'{chr(x)}:{ord(chr(x))}',end=' ')
<!--
print()
<!--
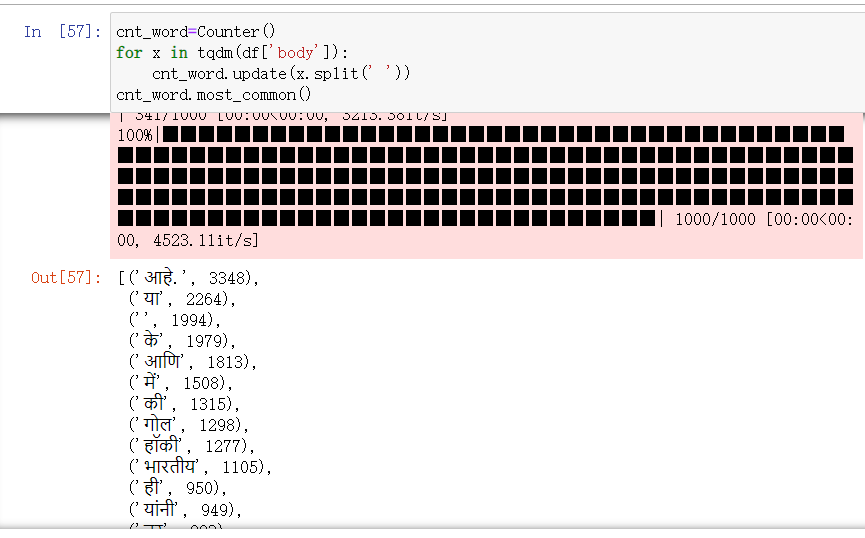
//统计词频
cnt_word=Counter()
for x in tqdm(df['body']):
cnt_word.update(x.split(' '))
cnt_word.most_common()
cnt_word=Counter()
for x in tqdm(df['body']):
cnt_word.update(x.split(' '))
cnt_word.most_common()
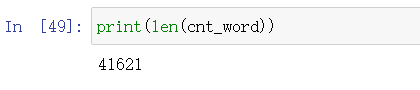
print(len(cnt_word))
去除特殊符号
def sub_specialspecial1(s):
pattern1=re.compile('[\x8b-\xbd]')
pattern2=re.compile('[\u2002-\uffff]')
pattern3=re.compile(r'🇷🇺🌟🌸🎀🎥🏆👉💜💪😉😍🙃🙌🙏🦄')
s=pattern3.sub(' ',pattern2.sub(' ',pattern1.sub(' ',s)))
s=re.sub(r'([\u0021-\u0040]|[\u007b-\u007e])',r' \1 ',s)
s=re.sub('( ){2,}|\t|\n',' ',s)
s=re.sub('( ){2,}|\t|\n',' ',s)
return s
df['body']= df['body'].apply(sub_specialspecial1)
cot=Counter()
for x in tqdm(df['body']):
for s in x:
cot.update(s)
dd=sorted(cot.keys())
dd
for x in dd:
print(f'{x}:{ord(x)}',end=' ')
print(hex(int.from_bytes(x.encode('utf-8'),byteorder='big')))
a='a'
print(a.encode('utf-8'))
decode与encode问题:python中的encode()和decode()函数
import sys
sys.getdefaultencoding()
ord('a')
chr(2409)
s=' !"#$%&\'()*+,-./:;?@[\\]中文^_`da da k;'
re.sub(r'([\u0021-\u0040]|[\u007b-\u007e])',r' \1 ',s)

df_all=pd.read_csv("导出印地语数据.csv",chunksize=10000)
chunksize分块读取,用于大文件的读取
数据处理:1 用pandas处理大型csv文件 2 使用Pandas分块处理大文件 3 分块读取
df_all.title

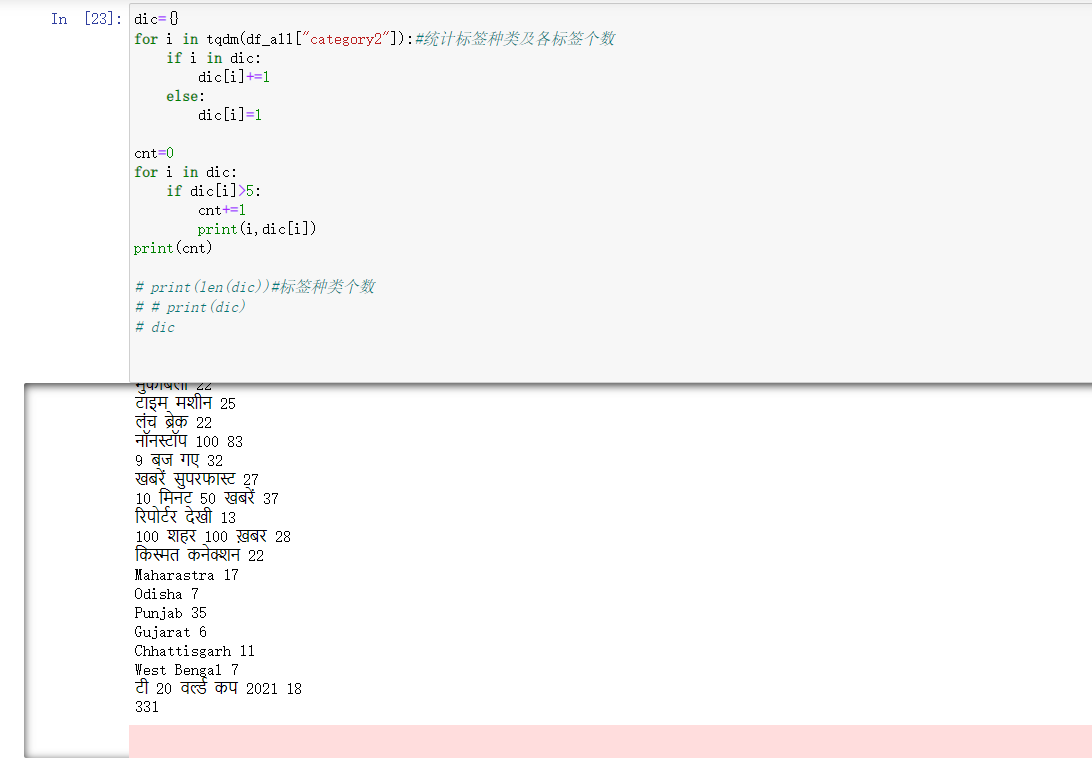
dic={}
for i in tqdm(df_all["category2"]):
if i in dic:
dic[i]+=1
else:
dic[i]=1
cnt=0
for i in dic:
if dic[i]>5:
cnt+=1
print(i,dic[i])
print(cnt)
使用tqdm()可以显示进度条
将category2列中满足条件的数据的对应行,若该行body列数据满足64
Original: https://blog.csdn.net/GCTTTTTT/article/details/121870643
Author: GCTTTTTT
Title: 使用Python中的Pandas库进行语料处理(词频统计、清洗数据、选取满足条件的对应行写入文件等)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/698142/
转载文章受原作者版权保护。转载请注明原作者出处!